In 2017 my Website was migrated to
the clouds and reduced in size.
Hence some links below are broken.
One thing to try if a “www” link is broken is to substitute “faculty” for “www”
For example a broken link
http://www.trinity.edu/rjensen/Pictures.htm
can be changed to corrected link
http://faculty.trinity.edu/rjensen/Pictures.htm
However in some cases files had to be removed to reduce the size of my Website
Contact me at rjensen@trinity.edu if
you really need to file that is missing
574 Shields Against Validity Challenges in
Plato's Cave
An Appeal for Replication and Other Commentaries/Dialogs in an
Electronic Journal Supplemental Commentaries and Replication Abstracts
Bob Jensen
at Trinity University
With a Rejoinder from the 2010 Senior Editor of The Accounting Review
(TAR), Steven J. Kachelmeier
Accountics is the mathematical science of values.
Charles Sprague [1887] as quoted by McMillan [1998, p. 1]
http://faculty.trinity.edu/rjensen/395wpTAR/Web/TAR395wp.htm#_msocom_1
Excellent, Cross-Disciplinary Overview of Scientific
Reproducibility in the Stanford Encyclopedia of Philosophy ---
https://replicationnetwork.com/2018/12/15/excellent-cross-disciplinary-overview-of-scientific-reproducibility-in-the-stanford-encyclopedia-of-philosophy/
[Researchers] are rewarded for
being productive rather than being right, for building ever upward instead of
checking the foundations.---
Decades of early research on the genetics of depression were built on
nonexistent foundations. How did that happen?
https://www.theatlantic.com/science/archive/2019/05/waste-1000-studies/589684/?utm_source=newsletter&utm_medium=email&utm_campaign=atlantic-daily-newsletter&utm_content=20191022&silverid-ref=NTk4MzY1OTg0MzY5S0
On the Past and Present of Reproducibility and Replicability in Economics ---
https://replicationnetwork.com/2021/01/25/on-the-past-and-present-of-reproducibility-and-replicability-in-economics/
The Atlantic:
Scientific Publishing Is a Joke ---
https://www.theatlantic.com/science/archive/2021/05/xkcd-science-paper-meme-nails-academic-publishing/618810/
Publication metrics have become a sad stand-in for quality in academia, but
maybe there’s a lesson in the fact that even a webcomic can arouse so much
passion and collaboration across the scientific community. Surely there’s a
better way to cultivate knowledge than today’s endless grid of
black-and-white papers.
Bob Jensen: My take on research validation or lack
thereof is at
See below
Three Interesting (albeit
negative) Sites on Peer Review (I highly recommend them even though one is my
own)
The Guardian:
Retracted (peer reviewed) studies may have damaged public trust in science, top
researchers fear ---
https://www.theguardian.com/science/2020/jun/06/retracted-studies-may-have-damaged-public-trust-in-science-top-researchers-fear
Those
who think that peer review is inherently fair and accurate are wrong. Those who
think that peer review necessarily suppresses their brilliant new ideas are
wrong. It is much more than those two simple opposing tendencies ---
http://rodneybrooks.com/peer-review/
The comments are especially interesting
Bob Jensen: 574
Shields Against Validity Challenges in Plato's Cave ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
Prestigious accounting research journals claim they encourage replication. They
just don't encourage replication because
replication studies in academic accounting research are blocked by the peer
review process.
Jensen Comment
This is why I spend such a large part of every day reading blogs. Blog modules
are not formally refereed but in a way they are subjected to widespread peer
review among the entire population of readers of the blog as long as the blogger
publishes their replies to to his or her blog modules.
This is why I think blogs and listservs
are less suppressive of new ideas.
One of the stupid unmentioned results of
peer review in our most prestigious academic accounting research journals is
that they rarely publish articles without equations. Go figure!
Introduction
Why Do Accountics Scientists Get Along So Well?
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
Why Pick on TAR and the Cargo Cult?
Real-Science Versus Pseudo
Science
Why the “Maximizing Shareholder Value”
Theory of Corporate Governance is Bogus
Purpose of Theory:
Prediction Versus Explanation
TAR versus AMR and AMJ and Footnotes of the
American Sociology Association
Introduction to Replication Commentaries
A May 2012 Commentary in TAR
Over Reliance on Public Databases and Failure
to Error Check
Consensus Seeking in Real Science Versus
Accountics Science
Are accountics scientists more honest and ethical than
real scientists?
TAR Versus JEC
Robustness Issues
Accounting Research Versus Social Science Research
The Cult of Statistical Significance: How Standard Error Costs Us Jobs,
Justice, and Lives ---
http://www.cs.trinity.edu/~rjensen/temp/DeirdreMcCloskey/StatisticalSignificance01.htm
Mathematical Analytics in Plato's Cave
TAR Researchers Playing by Themselves in an Isolated Dark Cave That the Sunlight
Cannot Reach
Thank You Dana Hermanson for Putting Accounting Horizons
Back on Track
Increasing Complexity of the World and Its
Mathematical Models
Is Anecdotal Evidence Irrelevant?
Statistical Inference vs Substantive
Inference
High Hopes Dashed for a Change in Policy of TAR Regarding Commentaries on
Previously Published Research
Low Hopes for Less Inbreeding in the Stable of TAR
Referees
Rejoinder from the Current Senior Editor of TAR,
Steven J. Kachelmeier
Do financial incentives improve manuscript quality and
manuscript reviews?
Case Research in Accounting
The Sad State of Accounting Doctoral Programs
in North America
Simpson's Paradox
and Cross-Validation
What
happened to cross-validation in accountics science research?
Citation Fraud: Why are accountics science
journal articles cited in other accountics science research papers so often?
Accountics is the mathematical science of values.
Charles Sprague [1887] as quoted by McMillan [1998, p. 1]
http://faculty.trinity.edu/rjensen/395wpTAR/Web/TAR395wp.htm#_msocom_1
Tom Lehrer on Mathematical Models and Statistics ---
http://www.youtube.com/watch?v=gfZWyUXn3So
You must watch this to the ending to appreciate it.
Strategies to Avoid Data Collection Drudgery and
Responsibilities for Errors in the Data
Obsession With R-Squared
Drawing Inferences From Very Large Data-Sets
The Insignificance of Testing the Null
Zero Testing for Beta Error
Scientific Irreproducibility
Can You Really Test for Multicollinearity?
Models That aren't Robust
Simpson's Paradox and Cross-Validation
Reverse Regression
David Giles' Top Five Econometrics Blog Postings
for 2013
David Giles Blog
A Cautionary Bedtime Story
574 Shields Against Validity Challenges in Plato's Cave ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
Real Science versus Pseudo Science ---
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm#Pseudo-Science
How Accountics Scientists Should Change:
"Frankly, Scarlett, after I get a hit for my resume in The Accounting
Review I just don't give a damn"
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
One more mission in what's left of my life will be to try to change this
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
"How Non-Scientific Granulation Can Improve Scientific
Accountics"
http://www.cs.trinity.edu/~rjensen/temp/AccounticsGranulationCurrentDraft.pdf
Gaming for Tenure as an Accounting Professor ---
http://faculty.trinity.edu/rjensen/TheoryTenure.htm
(with a reply about tenure publication point systems from Linda Kidwell)
The AAA's Pathways Commission Accounting Education
Initiatives Make National News
Accountics Scientists Should Especially Note the First Recommendation
Conclusion and Recommendation for a
Journal Named
Supplemental Commentaries and Replication Abstracts
Appendix 1: Business Firms and Business School
Teachers Largely Ignore TAR Research Articles
Appendix 2: Integrating Academic Research
Into Undergraduate Accounting Courses
Appendix 3: Audit Pricing in the Real World
Appendix 4: Replies from Jagdish Gangolly and
Paul Williams
Appendix 5: Steve Supports My
Idea and Then Douses it in Cold Water
Appendix 6: And to Captain John Harry Evans III, I
salute and say “Welcome Aboard.”
Appendix 7: Science Warriors' Ego Trips
Appendix 8: Publish Poop or Perish
We Must Stop the Avalanche of Low-Quality Research
Appendix 9: Econtics: How Scientists
Helped Cause Financial Crises (across 800 years)
Appendix 10: Academic Worlds (TAR) vs.
Practitioner Worlds (AH)
Appendix 11: Insignificance of Testing the Null
Appendis 12: The BYU Study of Accounting Programs
Ranked by Research Publications
Appendix 13:
What is "the" major difference between medical research and accounting research
published in top research journals?
Appendix 14:
What are two of the most Freakonomish and Simkinish processes in
accounting research and practice?
Appsendix 15: Essays on the
State of Accounting Scholarship
Appendix 16:
Gasp! How could an accountics scientist question such things? This is sacrilege!
Appendix 17:
A Scrapbook on What's Wrong with the Past, Present and Future of Accountics
Science
Acceptance Speech for the August 15, 2002 American
Accounting Association's Outstanding Educator Award --- http://faculty.trinity.edu/rjensen/000aaa/AAAaward_files/AAAaward02.htm
Real Science versus Pseudo Science ---
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm#Pseudo-Science
How Accountics Scientists Should
Change:
"Frankly, Scarlett, after I get a hit for my resume in The Accounting Review
I just don't give a damn"
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
One more mission in what's left of my life will be to try to change this
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
Essays on the State of Accounting Scholarship
---
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm#Essays
The Sad State of Economic Theory and Research ---
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm#EconomicResearch
The Cult of Statistical Significance: How Standard Error Costs Us
Jobs, Justice, and Lives, by Stephen T. Ziliak and Deirdre N. McCloskey
(Ann Arbor:
University of Michigan Press, ISBN-13: 978-472-05007-9, 2007)
http://www.cs.trinity.edu/~rjensen/temp/DeirdreMcCloskey/StatisticalSignificance01.htm
Page 206
Like scientists today in medical and economic and other
sizeless sciences, Pearson mistook a large sample size for the definite,
substantive significance---evidence s Hayek put it, of "wholes." But it was
as Hayek said "just an illusion." Pearson's columns of sparkling asterisks,
though quantitative in appearance and as appealing a is the simple truth of
the sky, signified nothing.
In Accountics Science R2
= 0.0004 = (-.02)(-.02) Can Be Deemed a Statistically Significant Linear
Relationship ---
http://www.cs.trinity.edu/~rjensen/temp/DeirdreMcCloskey/StatisticalSignificance01.htm
"So you want to get a Ph.D.?" by David Wood, BYU ---
http://www.byuaccounting.net/mediawiki/index.php?title=So_you_want_to_get_a_Ph.D.%3F
Do You Want to Teach? ---
http://financialexecutives.blogspot.com/2009/05/do-you-want-to-teach.html
Jensen Comment
Here are some added positives and negatives to consider, especially if you are
currently a practicing accountant considering becoming a professor.
Accountancy Doctoral Program Information from Jim Hasselback ---
http://www.jrhasselback.com/AtgDoctInfo.html
Why must all accounting doctoral programs be social science (particularly
econometrics) "accountics" doctoral programs?
http://faculty.trinity.edu/rjensen/theory01.htm#DoctoralPrograms
What went wrong in accounting/accountics research?
http://faculty.trinity.edu/rjensen/theory01.htm#WhatWentWrong
Bob Jensen's Codec Saga: How I Lost a Big Part of My Life's
Work
Until My Friend Rick Lillie Solved My Problem
http://www.cs.trinity.edu/~rjensen/video/VideoCodecProblems.htm
One of the most popular Excel spreadsheets that Bob Jensen ever provided to his
students ---
www.cs.trinity.edu/~rjensen/Excel/wtdcase2a.xls
John Arnold Made a Fortune at Enron. Now He’s Declared War on Bad Science
---
https://www.wired.com/2017/01/john-arnold-waging-war-on-bad-science/
Tom Lehrer on Mathematical Models and Statistics ---
http://www.youtube.com/watch?v=gfZWyUXn3So
You must watch this to the ending to appreciate it.
Carl Sagan Presents His “Baloney Detection Kit”: 8 Tools for Skeptical
Thinking ---
http://www.openculture.com/2016/04/carl-sagan-presents-his-baloney-detection-kit-8-tools-for-skeptical-thinking.html
"David Ginsberg, chief data scientist at SAP,
said communication skills are critically important in the field, and that a key
player on his big-data team is a “guy who can translate Ph.D. to English. Those
are the hardest people to find.”
James Willhite
The second is the comment that Joan Robinson made
about American Keynsians: that their theories were so flimsy that they had to
put math into them. In accounting academia, the shortest path to respectability
seems to be to use math (and statistics), whether meaningful or not.
Professor Jagdish Gangolly, SUNY
Albany
The methodology does not generate the results’:
Journal corrects accounting study with flawed
methods ---
https://retractionwatch.com/2019/11/13/the-methodology-does-not-generate-the-results-journal-corrects-accounting-study-with-flawed-methods/
What a difference a Yi,t=β0+β1IOˆi,t+β2Xi,t+ωt+εi,t.Yi,t=β0+β1IO^i,t+β2Xi,t+ωt+εi,t.
makes.
The authors of a 2016 paper
on institutional investing have corrected their article — to include the
equation above — in the wake of persistent questions about their
methodology. The move follows the protracted retraction earlier
this year of a similar article in The
Accounting Review by
the duo, Andrew
Bird and Stephen
Karolyi, of
Carnegie Mellon University in Pittsburgh, for related problems.
The bottom line, it seems,
is that Bird and Karolyi appear to be unable adequately to explain their
research methods in ways that stand up to scrutiny.
The
correction involves a paper published in The
Review of Financial Studies,
from Oxford University Press, titled “Do institutional investors demand
public disclosure. According to the statement (the
meat of which is behind a paywall):
. . .
Alex Young,
an accounting researcher at Hofstra University in Hempstead, NY, who raised
questions about Karolyi and Bird’s retracted article and ultimately failed
to replicate it,
was not one of the readers who raised concerns about the other article. But,
he told us:
I would be very interested to see the
authors’ data and code that generate the results presented
in the paper.
Jensen Comment
Because accounting researchers rarely conduct replications and the few
replications that are attempted are almost never published, it's refreshing to
see that Professor Young attempted this replication.
Bob Jensen's threads on professors who cheat ---
http://faculty.trinity.edu/rjensen/Plagiarism.htm#ProfessorsWhoPlagiarize
University of Pennsylvania's Wharton School: Is There a Replication
Crisis in Research?
http://knowledge.wharton.upenn.edu/article/research-replication-crisis/
Recommendations for Change on the American
Accounting Association's
Notable Contributions to Accounting Literature Award
http://faculty.trinity.edu/rjensen/TheoryNotable.htm
Richard Feynman Creates a Simple Method for Telling Science From
Pseudoscience (1966) ---
http://www.openculture.com/2016/04/richard-feynman-creates-a-simple-method-for-telling-science-from-pseudoscience-1966.html
By Feynman's standard standard accountics science is pseudoscience
David Johnstone asked me to write a paper on the following:
"A Scrapbook on What's Wrong with the Past, Present and Future of Accountics
Science"
Bob Jensen
February 19, 2014
SSRN Download:
http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2398296
Abstract
For operational convenience I define accountics science as
research that features equations and/or statistical inference. Historically,
there was a heated debate in the 1920s as to whether the main research
journal of academic accounting, The Accounting Review (TAR) that
commenced in 1926, should be an accountics journal with articles that mostly
featured equations. Practitioners and teachers of college accounting won
that debate.
TAR articles and accountancy doctoral dissertations prior to
the 1970s seldom had equations. For reasons summarized below, doctoral
programs and TAR evolved to where in the 1990s there where having equations
became virtually a necessary condition for a doctoral dissertation and
acceptance of a TAR article. Qualitative normative and case method
methodologies disappeared from doctoral programs.
What’s really meant by “featured
equations” in doctoral programs is merely symbolic of the fact that North
American accounting doctoral programs pushed out most of the accounting to
make way for econometrics and statistics that are now keys to the kingdom
for promotion and tenure in accounting schools ---
http://faculty.trinity.edu/rjensen/Theory01.htm#DoctoralPrograms
The purpose of this paper is to make a case that the accountics science
monopoly of our doctoral programs and published research is seriously
flawed, especially its lack of concern about replication and focus on
simplified artificial worlds that differ too much from reality to creatively
discover findings of greater relevance to teachers of accounting and
practitioners of accounting. Accountics scientists themselves became a Cargo
Cult.
Why Economics is Having a Replication Crisis ---
https://www.bloomberg.com/view/articles/2018-09-17/economics-gets-it-wrong-because-research-is-hard-to-replicate
Replication and Validity Testing: How are things going in political
science? ---
https://replicationnetwork.com/2018/09/12/and-how-are-things-going-in-political-science/
Replication and Validity Testing: How are things going in
psychology? ---
https://replicationnetwork.com/2018/09/14/in-the-news-the-chronicle-of-higher-education-september-11-2018/
Replication and Validity Testing: How are things going in
accountancy?
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
Philosophy of Science Meets the Statistics Wars ---
https://replicationnetwork.com/2018/09/10/philosophy-of-science-meets-the-statistics-wars/
Significant Effects From Low-Powered Studies Will Be Overestimates ---
https://replicationnetwork.com/2018/09/08/significant-effects-from-low-powered-studies-will-be-overestimates/
80% Power? Really?
https://replicationnetwork.com/2018/09/01/80-power-really/
Responsible Research Results: What can universities do?
https://replicationnetwork.com/2018/09/07/what-can-universities-do/
Reproducibility and Replicability in Science ---
www.nap.edu/catalog/25303/reproducibility-and-replicability-in-science
Contributors
National
Academies of Sciences, Engineering, and Medicine;
Division of Behavioral and Social Sciences and
Education;
Division on Earth and Life Studies;
Division on Engineering and Physical Sciences;
Policy and Global Affairs;
Committee on National Statistics;
Board on Behavioral, Cognitive, and Sensory
Sciences;
Nuclear and Radiation Studies Board;
Committee on Applied and Theoretical Statistics;
Board on Mathematical Sciences and Analytics;
Committee on Science, Engineering, Medicine, and
Public Policy;
Board on Research Data and Information;
Committee on Reproducibility and Replicability
in Science
Description
One of the pathways by which the scientific community confirms the validity
of a new scientific discovery is by repeating the research that produced it.
When a scientific effort fails to independently confirm the computations or
results of a previous study, some fear that it may be a symptom of a lack of
rigor in science, while others argue that such an observed inconsistency can
be an important precursor to new discovery.
[read full description]
Topics
Suggested Citation
National Academies of Sciences, Engineering, and Medicine. 2019.
Reproducibility and Replicability in Science. Washington, DC: The
National Academies Press. https://doi.org/10.17226/25303.
Pottery Barn Rule ---
https://en.wikipedia.org/wiki/Pottery_Barn_rule
A Pottery Barn Rule for Scientific Journals ---
https://thehardestscience.com/2012/09/27/a-pottery-barn-rule-for-scientific-journals/
Proposed: Once a journal has published a study, it
becomes responsible for publishing direct replications of that study.
Publication is subject to editorial review of technical merit but is not
dependent on outcome. Replications shall be published as brief reports in an
online supplement, linked from the electronic version of the original.
Another Journal Adopts the “Pottery Barn Rule” ---
https://replicationnetwork.com/2019/05/04/another-journal-adopts-the-pottery-barn-rule/
I suspect the AAA has not even considered a pottery barn rule for journals
like The Accounting Review.
Ten universities that have officially joined a UK network set up to tackle
the issue of reproducibility in research ---
https://www.timeshighereducation.com/news/ten-uk-universities-create-reproducibility-focused-senior-roles#survey-answer
Each university has created a role that will
feature a senior academic leading on practical steps the institution is
taking to bolster research quality, such as better training, open data
practices and assessing the criteria used in recruitment and promotion
decisions
Jensen Comment
Leading academic accounting journals publish neither commentaries on their
articles nor replications of research. It's almost rare for academic accounting
research to be independently reproduced or otherwise verified. It's not
that accounting researchers are more accurate and honest than scientists. It's
more of a problem with lack of relevance of the research in the profession of
accountancy ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
It's doubtful that the UK network mentioned above will affect schools of
business in general.
Creating Relevance of
Accounting Research (ROAR) Scores to Evaluate the Relevance of
Accounting Research to Practice
SSRN
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3501871
49 Pages
Posted: 17 Dec 2019
Brigham Young University -
School of Accountancy
Brigham Young University -
School of Accountancy
Brigham Young University
Brigham Young University -
School of Accountancy
Date Written: December 10, 2019
Keywords: Research Relevance,
Accounting
Rankings, Practice-Oriented Research, Journal Rankings
JEL Classification: M40, M41, M49, M00
Abstract
The relevance of
accounting
academic research to practice has been frequently discussed in the
accounting
academy; yet, very little data has been put forth in these discussions.
We create relevance of
accounting
research (ROAR) scores by having practitioners read and evaluate the
abstract of every article published in 12 leading
accounting
journals for the past three years. The ROAR scores allow for a more
evidence-based evaluation and discussion of how academic
accounting
research is relevant to practitioners. Through these scores, we identify
the articles, authors, journals, and
accounting
topic areas and methodologies that are producing practice-relevant
scholarship. By continuing to produce these scores in perpetuity, we
expect this data to help academics and practitioners better identify and
utilize practice-relevant scholarship.
V. CONCLUSIONS
This research provides empirical data
about the contribution accounting academics are making to practice.
Specifically, we had nearly 1,000 professionals read the abstract of
academic accounting articles and rate how relevant the articles are to
practice. We then present the data to rank journals, universities, and
individual scholars. Overall, we interpret the results to suggest that
some of the research that is currently produced and published in 12
accounting journals is relevant to practice, but at the same time, there
is room to improve. Our hope is that by producing these rankings, it
will encourage journals, institutions, and authors to produce and
publish more relevant research, thus helping to fulfill the Pathways
charge “to build a learned profession.”
We now take the liberty to provide some
normative comments about our research findings in relation to the goal
of producing a learned profession.
One of the key findings in this study is
that the traditional top 3 and top 6 journals are not producing the most
or the greatest average amount of practice relevant research, especially
for the distinct accounting topic areas.
Prior research shows that the collection of a small group of 3/6
journals is not representative of the breadth of accounting scholarship
(Merchant 2010; Summers and Wood 2017; Barrick, et al. 2019). Given the
empirical research on this topic, we question why institutions and
individual scholars continue to have a myopic focus on a small set of
journals. The idea that these 3/6 journals publish “the best” research
is not empirically substantiated. While many scholars argue that the
focus is necessary for promotion and tenure decisions, this seems like a
poor excuse (see Kaplan 2019). Benchmarking production in a larger set
of journals would not be hard, and indeed has been done (Glover, Prawitt,
and Wood 2006; Glover, Prawitt, Summers, and Wood 2019). Furthermore, as
trained scholars, we could read and opine on article quality without
outsourcing that decision to simple counts of publications in “accepted”
journals. We call on the 18 We recognize that only looking at 12
journals also limits the scope unnecessarily. The primary reason for the
limitation in this paper is the challenge of collecting data for a
greater number of journals. Thus, we view 12 journals as a start, but
not the ideal. academy to be much more open to considering research in
all venues and to push evaluation committees to do the same.
A second important finding is that
contribution should be a much larger construct than is previously
considered in the academy. In our experience, reviewers, editors, and
authors narrowly define the contribution an article makes and are too
often unwilling to consider a broad view of contribution. The current
practice of contribution too often requires authors to “look like
everyone else” and rarely, if ever, allows for a contribution that is
focused exclusively on a practice audience. We encourage the AACSB, AAA,
and other stakeholders to make a more concerted effort to increase the
focus on practice-relevant research. This may entail journals rewriting
mission statements, editors taking a more pro-active approach, and
training of reviewers to allow articles to be published that focus
exclusively on “practical contributions.” This paper has important
limitations. First, we only examine 12 journals. Ideally, we would like
to examine a much more expansive set of journals but access to
professionals makes this challenging at this time. Second, measuring
relevance is difficult. We do not believe this paper “solves” all of the
issues and we agree that we have not perfectly measured relevance.
However, we believe this represents a reasonable first attempt in this
regard and moves the literature forward. Third, the ROAR scores are only
as good as the professionals’ opinions. Again, we limited the scores to
5 professionals hoping to get robust opinions, but realize that some
articles (and thus authors and universities) are not likely rated
“correctly.” Furthermore, articles may make a contribution to practice
in time and those contributions may not be readily apparent by
professionals at the time of publication. Future research can improve
upon what we have done in this regard.
We are hopeful that shining a light on
the journals, institutions, and authors that are excelling at producing
research relevant to practice will encourage increased emphasis in this
area.
Jensen Question
Is accounting research stuck in a rut of repetitiveness and irrelevancy?
"Accounting
Craftspeople versus Accounting Seers: Exploring the Relevance and
Innovation Gaps in Academic Accounting Research," by William E.
McCarthy, Accounting
Horizons, December 2012, Vol. 26, No. 4, pp. 833-843 ---
http://aaajournals.org/doi/full/10.2308/acch-10313
Is accounting research stuck in a rut of
repetitiveness and irrelevancy?
I (Professor
McCarthy) would
answer yes, and I would even predict that both its gap in relevancy and
its gap in innovation are going to continue to get worse if the people
and the attitudes that govern inquiry in the American academy remain the
same. From my perspective in
accounting information systems, mainstream accounting research topics
have changed very little in 30 years, except for the fact that their
scope now seems much more narrow and crowded. More and more people seem
to be studying the same topics in financial reporting and managerial
control in the same ways, over and over and over. My suggestions to get
out of this rut are simple. First, the profession should allow itself to
think a little bit normatively, so we can actually target practice
improvement as a real goal. And second, we need to allow new scholars a
wider berth in research topics and methods, so we can actually give the
kind of creativity and innovation that occurs naturally with young
people a chance to blossom.
Since the
2008 financial crisis, colleges and universities have faced
increased pressure to identify essential disciplines, and cut the
rest. In 2009, Washington State University announced it would
eliminate the department of theatre and dance, the department of
community and rural sociology, and the German major – the same year
that the University of Louisiana at Lafayette ended its philosophy
major. In 2012, Emory University in Atlanta did away with the visual
arts department and its journalism programme. The cutbacks aren’t
restricted to the humanities: in 2011, the state of Texas announced
it would eliminate nearly half of its public undergraduate physics
programmes. Even when there’s no downsizing, faculty salaries have
been frozen and departmental budgets have shrunk.
But despite the funding crunch, it’s a bull
market for academic economists. According to a 2015 sociological study in
the Journal
of Economic Perspectives, the median salary of economics
teachers in 2012 increased to $103,000 – nearly $30,000 more than
sociologists. For the top 10 per cent of economists, that figure
jumps to $160,000, higher than the next most lucrative academic
discipline – engineering. These figures, stress the study’s authors,
do not include other sources of income such as consulting fees for
banks and hedge funds, which, as many learned from the documentary Inside
Job (2010),
are often substantial. (Ben Bernanke, a former academic economist
and ex-chairman of the Federal Reserve, earns $200,000-$400,000 for
a single appearance.)
Unlike
engineers and chemists, economists cannot point to concrete objects
– cell phones, plastic – to justify the high valuation of their
discipline. Nor, in the case of financial economics and
macroeconomics, can they point to the predictive power of their
theories. Hedge funds employ cutting-edge economists who command
princely fees, but routinely underperform index funds. Eight years
ago, Warren Buffet made a 10-year, $1 million bet that a portfolio
of hedge funds would lose to the S&P 500, and it looks like he’s
going to collect. In 1998, a fund that boasted two Nobel Laureates
as advisors collapsed, nearly causing a global financial crisis.
The failure of the field to predict the 2008
crisis has also been well-documented. In 2003, for example, only
five years before the Great Recession, the Nobel Laureate Robert E
Lucas Jr told the
American Economic Association that ‘macroeconomics […] has
succeeded: its central problem of depression prevention has been
solved’. Short-term predictions fair little better – in April 2014,
for instance, a
survey of
67 economists yielded 100 per cent consensus: interest rates would
rise over the next six months. Instead, they fell. A lot.
Nonetheless, surveys
indicate that
economists see their discipline as ‘the most scientific of the
social sciences’. What is the basis of this collective faith, shared
by universities, presidents and billionaires? Shouldn’t successful
and powerful people be the first to spot the exaggerated worth of a
discipline, and the least likely to pay for it?
In the
hypothetical worlds of rational markets, where much of economic
theory is set, perhaps. But real-world history tells a different
story, of mathematical models masquerading as science and a public
eager to buy them, mistaking elegant equations for empirical
accuracy.
Real Science versus Pseudo Science ---
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm#Pseudo-Science
Jensen Comment
Academic accounting (accountics) scientists took economic astrology a
step further when their leading journals stopped encouraging and
publishing commentaries and replications of published articles ---
How Accountics Scientists Should Change:
"Frankly, Scarlett, after I get a hit for my resume in The
Accounting Review I just
don't give a damn"
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
Times are changing in social science research
(including economics) where misleading p-values are no longer the Holy
Grail. Change among accountics scientist will lag behind change in
social science research but some day leading academic accounting
research journals may publish articles without equations and/or articles
of interest to some accounting practitioner somewhere in the world ---
See below
Academic accounting researchers sheilded themselves from validity
challenges by refusing to publish commentaries and refusing to accept
replication studies for publication ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
Scientific Method in Accounting Has Not Been a Method for Generating New
Theories
The following is a quote from the 1993 President’s
Message of Gary Sundem, President’s
Message. Accounting Education News 21 (3). 3.
Although empirical scientific
method has made many positive contributions to accounting research, it
is not the method that is likely to generate new theories, though it
will be useful in testing them. For example, Einstein’s theories were
not developed empirically, but they relied on understanding the
empirical evidence and they were tested empirically. Both the
development and testing of theories should be recognized as acceptable
accounting research.
Message from Bob Jensen to
Steve Kachelmeier in 2015
Hi Steve,
As usual, these AECM threads between you, me, and Paul Williams resolve
nothing to date. TAR still has zero articles without equations unless
such articles are forced upon editors like the Kaplan article was forced
upon you as Senior Editor. TAR still has no commentaries about the
papers it publishes and the authors make no attempt to communicate and
have dialog about their research on the AECM or the AAA Commons.
I do hope that our AECM threads will continue and lead one day to when
the top academic research journals do more to both encourage (1)
validation (usually by speedy replication), (2) alternate methodologies,
(3) more innovative research, and (4) more interactive commentaries.
I remind you that Professor Basu's essay is only one of four essays
bundled together in Accounting Horizons on the topic of how to make
accounting research, especially the so-called Accounting Sciience or
Accountics Science or Cargo Cult science, more innovative.
The four essays in this bundle are summarized and extensively quoted at http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm#Essays
- "Framing the Issue of Research Quality in a Context of Research
Diversity," by Christopher S. Chapman ---
- "Accounting Craftspeople versus Accounting Seers: Exploring the
Relevance and Innovation Gaps in Academic Accounting Research," by
William E. McCarthy ---
- "Is Accounting Research Stagnant?" by Donald V. Moser ---
- Cargo Cult Science "How Can Accounting Researchers Become More
Innovative? by Sudipta Basu ---
I will try to keep drawing attention to these important essays and spend
the rest of my professional life trying to bring accounting research
closer to the accounting profession.
I also want to dispel the myth that accountics research is harder than
making research discoveries without equations. The hardest research I
can imagine (and where I failed) is to make a discovery that has a
noteworthy impact on the accounting profession. I always look but never
find such discoveries reported in TAR.
The easiest research is to purchase a database and beat it with an
econometric stick until something falls out of the clouds. I've searched
for years and find very little that has a noteworthy impact on the
accounting profession. Quite often there is a noteworthy impact on other
members of the Cargo Cult and doctoral students seeking to beat the same
data with their sticks. But try to find a practitioner with an interest
in these academic accounting discoveries?
Our latest thread leads me to such questions as:
- Is accounting research of inferior quality relative to other
disciplines like engineering and finance?
- Are there serious innovation gaps in academic accounting
research?
- Is accounting research stagnant?
- How can accounting researchers be more innovative?
- Is there an "absence of dissent" in academic accounting
research?
- Is there an absence of diversity in our top academic accounting
research journals and doctoral programs?
- Is there a serious disinterest (except among the Cargo Cult) and
lack of validation in findings reported in our academic accounting
research journals, especially TAR?
- Is there a huge communications gap between academic accounting
researchers and those who toil teaching accounting and practicing
accounting?
- Why do our accountics scientists virtually ignore the AECM and
the AAA Commons and the Pathways Commission Report?
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
One fall out of this thread is that I've been privately
asked to write a paper about such matters. I hope that others will
compete with me in thinking and writing about these serious challenges
to academic accounting research that never seem to get resolved.
Thank you Steve for sometimes responding in my threads on
such issues in the AECM.
Respectfully,
Bob Jensen
Sadly Steve like all other
accountics scientists (with one sort of exception) no longer contributes
to the AECM
April 22, 2012 reply from Bob Jensen
Steve Kachelmeier wrote:
"I am very proud to have accepted and published
the Magilke, Mayhew, and Pike experiment, and I think it is excellent
research, blending both psychology and economic insights to examine
issues of clear importance to accounting and auditing. In fact, the
hypocrisy somewhat amazes me that, amidst all the complaining about a
perceived excess of financial empirical-archival (or what you so fondly
call "accountics" studies), even those studies that are quite different
in style also provoke wrath."
July 8, 2009 reply from Dennis Beresford [dberesfo@TERRY.UGA.EDU]
Bob,
I read the first 25
or so pages of the paper. As an actual audit committee member, I
feel comfortable in saying that the assumptions going into the
experiment design make no sense whatsoever. And using students to
"compete to be hired" as audit committee members is preposterous.
I have served on five
audit committees of large public companies, all as chairman. My
compensation has included cash, stock options, restricted stock, and
unrestricted stock. The value of those options has gone from zero to
seven figures and back to zero and there have been similar
fluctuations in the value of the stock. In no case did I ever sell a
share or exercise an option prior to leaving a board. And in every
case my *only *objective as an audit committee member was to do my
best to insure that the company followed GAAP to the best of its
abilities and that the auditors did the very best audit possible.
No system is perfect
and not all audit committee members are perfect (certainly not me!).
But I believe that the vast majority of directors want to do the
right thing. Audit committee members take their responsibilities
extremely seriously as evidenced by the very large number of
seminars, newsletters, etc. to keep us up to date. It's too bad that
accounting researchers can't find ways to actually measure what is
going on in practice rather than revert to silly exercises like this
paper. To have it published in the leading accounting journal shows
how out of touch the academy truly is, I'm afraid.
Denny Beresford
Bob Jensen's Reply
Thanks Steve, but if if the Maglke, Mayhew, and Pike experiment was such
excellent research, why did no independent accountics science
researchers or practitioners find it worthy of being validated?
The least likely accountics science research
studies to be replicated are accountics behavioral experiments that are
usually quite similar to psychology experiments and commonly use student
surrogates for real life professionals? Why is that these studies are so
very, very rarely replicated by independent researchers using either
other student surrogates or real world professionals?
Why are these accountics behavioral experiments
virtually never worthy of replication?
Years ago I was hired, along with
another accounting professor, by the FASB to evaluate research proposals
on investigating the impact of FAS 13. The FASB reported to us that they
were interested in capital markets studies and case studies. The one
thing they explicitly stated, however, was that they were not interested
in behavioral experiments. Wonder why?
Bob Jensen's
threads on what went wrong with academic accounting research
?
http://faculty.trinity.edu/rjensen/theory01.htm#WhatWentWrong
The Bottom Line
As with so many disciplines academic research ceased being
relevant to the outside world --- like Political Science
Chronicle of Higher Education: How
Political Science Became Irrelevant
The field turned its back on the Beltway
https://www.chronicle.com/article/How-Political-Science-Became/245777?utm_source=cr&utm_medium=en&cid=cr
In a 2008
speech to the Association of American Universities, the former Texas A&M
University president and then-Secretary of Defense Robert M. Gates
declared that "we must again embrace eggheads and ideas." He went on to
recall the role of universities as "vital centers of new research"
during the Cold War. The late Thomas Schelling would have agreed. The
Harvard economist and Nobel laureate once described "a wholly
unprecedented ‘demand’ for the results of theoretical work. … Unlike any
other country … the United States had a government permeable not only by
academic ideas but by academic people."
Gates’s
efforts to bridge the gap between Beltway and ivory tower came at a time
when it was growing wider, and indeed, that gap has continued to grow in
the years since. According to a Teaching, Research & International
Policy Project
survey,
a regular poll of international-relations scholars, very few believe
they should not contribute to policy making in some way. Yet a majority
also recognize that the state-of-the-art approaches of academic social
science are precisely those approaches that policy makers find least
helpful. A related poll of senior national-security decision-makers
confirmed that, for the most part, academic social science is not giving
them what they want.
The problem,
in a nutshell, is that scholars increasingly privilege rigor over
relevance. That has become strikingly apparent in the subfield of
international security (the part of political science that once most
successfully balanced those tensions), and has now fully permeated
political science as a whole. This skewed set of intellectual priorities
— and the field’s transition into a cult of the irrelevant — is the
unintended result of disciplinary professionalization.
The
decreasing relevance of political science flies in the face of a
widespread and longstanding optimism about the compatibility of rigorous
social science and policy relevance that goes back to the Progressive
Era and the very dawn of modern American social science. One of the most
important figures in the early development of political science, the
University of Chicago’s Charles Merriam, epitomized the ambivalence
among political scientists as to whether what they did was "social
science as activism or technique," as the American-studies scholar Mark
C. Smith put it. Later, the growing tension between rigor and relevance
would lead to what David M. Ricci
termed
the "tragedy of political science": As the discipline sought to become
more scientific, in part to better address society’s ills, it became
less practically relevant.
When
political scientists seek rigor, they increasingly conflate it with the
use of particular methods such as statistics or formal modeling. The
sociologist Leslie A. White
captured
that ethos as early as 1943:
We may thus
gauge the ‘scientific-ness’ of a study by observing the extent to which
it employs mathematics — the more mathematics the more scientific the
study. Physics is the most mature of the sciences, and it is also the
most mathematical. Sociology is the least mature of the sciences and
uses very little mathematics. To make sociology scientific, therefore,
we should make it mathematical.
Relevance, in
contrast, is gauged by whether scholarship contributes to the making of
policy decisions.
That
increasing tendency to embrace methods and models for their own sake
rather than because they can help us answer substantively important
questions is, I believe, a misstep for the field. This trend is in part
the result of the otherwise normal and productive workings of science,
but it is also reinforced by less legitimate motives, particularly
organizational self-interest and the particularities of our intellectual
culture.
While
the use of statistics and formal models is not by definition irrelevant,
their edging out of qualitative approaches has over time made the
discipline less relevant to policy makers. Many pressing policy
questions are not readily amenable to the preferred methodological tools
of political scientists. Qualitative case studies most often produce the
research that policy makers need, and yet the field is moving away from
them.
Continued in article
Jensen Comment
This sounds so, so familiar. The same type of practitioner irrelevancy
commenced in the 1960s when when academic accounting became "accountics
science" --- About the time when The Accounting
Review stopped publishing submissions that did not have equations and
practicing accountants dropped out of the American Accounting Association
and stopped subscribing to academic accounting research journals.
An Analysis of the Contributions of The Accounting
Review Across 80 Years: 1926-2005 --- http://faculty.trinity.edu/rjensen/395wpTAR/Web/TAR395wp.htm
Co-authored with Jean Heck and forthcoming in the December 2007 edition
of the Accounting Historians Journal.
Unlike engineering, academic accounting research is no
longer a focal point of practicing accountants. If we gave a prize for
academic research discovery that changed the lives of the practicing
profession who would practitioners choose to honor for the findings?
The silence is deafening!
Dismal Science Cartel: Economists and its main association face
criticism that the field's power centers are a small number of top departments.
Grad students, meanwhile, push for standards of conduct. ---
Click Here
Jensen Comment
Unlike business disciplines like accounting, economists are at long last
promoting and publishing research replications ---
https://www.bloomberg.com/opinion/articles/2018-09-17/economics-gets-it-wrong-because-research-is-hard-to-replicate
Also see
https://davegiles.blogspot.com/2018/10/the-refereeing-process-in-economics.html
Why so little replication in accounting research?
Allegedly accounting researchers are always truthful and painstakingly accurate
there's no need for replication and validity research ---
In truth the reason is that there are so few readers of accounting research who
care about validity.
I think a PhD seminar should focus on the dogged tradition
in other disciplines to replicate original research findings. We usually think
of the physical sciences for replication examples, although the social science
research journals are getting more and more concerned about replication and
validity. Interestingly, some areas of the humanities are dogged about
replication, particularly historians. Much of historical research is devoted to
validating historical claims. For example, see
http://hnn.us/articles/568.html
The Cult of Statistical Significance: How Standard Error Costs Us
Jobs, Justice, and Lives, by Stephen T. Ziliak and Deirdre N. McCloskey
(Ann Arbor: University of Michigan Press, ISBN-13: 978-472-05007-9, 2007)
http://www.cs.trinity.edu/~rjensen/temp/DeirdreMcCloskey/StatisticalSignificance01.htm
Page 206
Like scientists today in medical and economic and other
sizeless sciences, Pearson mistook a large sample size for the definite,
substantive significance---evidence s Hayek put it, of "wholes." But it was
as Hayek said "just an illusion." Pearson's columns of sparkling asterisks,
though quantitative in appearance and as appealing a is the simple truth of
the sky, signified nothing.
In Accountics Science R2
= 0.0004 = (-.02)(-.02) Can Be Deemed a Statistically Significant Linear
Relationship ---
http://www.cs.trinity.edu/~rjensen/temp/DeirdreMcCloskey/StatisticalSignificance01.htm
How Accountics Scientists Should Change:
"Frankly, Scarlett, after I get a hit for my resume in The Accounting Review
I just don't give a damn"
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
One more mission in what's left of my life will be to try to change this
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
"The Absence of Dissent," by Joni J. Young,
Accounting and the Public Interest 9 (1), 1 (2009); doi:
10.2308/api.2009.9.1.1 ---
Click Here
ABSTRACT:
The persistent malaise in accounting research continues to resist remedy.
Hopwood (2007) argues that revitalizing academic accounting cannot be
accomplished by simply working more diligently within current paradigms.
Based on an analysis of articles published in Auditing: A Journal of
Practice & Theory, I show that this paradigm block is not confined to
financial accounting research but extends beyond the work appearing in the
so-called premier U.S. journals. Based on this demonstration I argue that
accounting academics must tolerate (and even encourage) dissent for
accounting to enjoy a vital research academy. ©2009 American Accounting
Association
June 15, 2010 reply from Paul Williams
[Paul_Williams@NCSU.EDU]
Bob,
Thank you advertising the availability of this paper in API, the on line
journal of the AAA Public Interest Section (which I just stepped down
from editing after my 3+ years stint). Joni is one of the most
(incisively) thoughtful people in our discipline (her paper in AOS,
"Making Up Users" is a must read). The absence of dissent is evident
from even casual perusal of the so-called premier journals. Every paper
is erected on the same premises -- assumptions about human decision
making (i.e., rational decision theory), "free markets," economic
naturalism, etc. There is a metronomic repetition of the same
meta-narrative about the "way the world is" buttressed by exercises in
statistical causal analysis (the method of agricultural research, but
without any of the controls). There is a growing body of evidence that
these premises are myths -- the so-called rigorous research valorized in
the "top" journals is built on an ideological foundation of sand.
Paul Williams
paul_williams@ncsu.edu
(919)515-4436
A Must Read Document
The Pathways Commission Implementing
Recommendations for the Future of Accounting Education: The First Year Update
American Accounting Association
August 2013
http://commons.aaahq.org/files/3026eae0b3/Pathways_Update_FIN.pdf
Draft: August 3, 2010
http://commons.aaahq.org/files/8273566240/Overview_8_03_10.pdf
I hope
some creative AECM and CPA-L threads emerge on this topic. In particular, I hope
this document stimulates academic accounting research that is more focused on
the needs of the business world and the profession (which was the main theme of
Bob Kaplan’s outstanding plenary session on August 4 in San Francisco).
Note that to watch the entire Kaplan video ---
http://commons.aaahq.org/hives/531d5280c3/posts?postTypeName=session+video
I think the video is only available to AAA members.
Also note the AAA’s new Issues and Resources page ---
http://aaahq.org/resources.cfm
September 9, 2011 reply from Paul Williams
Bob,
I have avoided chiming in on this thread; have gone down this same road and
it is a cul-de-sac. But I want to say that this line of argument is a
clever one. The answer to your rhetorical question is, No, they aren't
more ethical than other "scientists." As you tout the Kaplan
speech I would add the caution that before he raised the issue of practice,
he still had to praise the accomplishments of "accountics" research by
claiming numerous times that this research has led us to greater
understanding about analysts, markets, info. content, contracting, etc.
However, none of that is actually true. As a panelist at the AAA
meeting I juxtaposed Kaplan's praise for what accountics research has taught
us with Paul Krugman's observations about Larry Summer's 1999 observation
that GAAP is what makes US capital markets so stable and efficient. Of
course, as Krugman noted, none of that turned out to be true. And if
that isn't true, then Kaplan's assessment of accountics research isn't
credible, either. If we actually did understand what he claimed we now
understand much better than we did before, the financial crisis of 2008
(still ongoing) would not have happened. The title of my talk was (the
panel was organized by Cheryl McWatters) "The Epistemology of
Ignorance." An obsessive preoccupation with method could be a choice not to
understand certain things-- a choice to rigorously understand things as you
already think they are or want so desperately to continue to believe for
reasons other than scientific ones.
Paul
"Social Media Lure Academics Frustrated by Journals," by Jennifer
Howard, Chronicle of Higher Education, February 22, 2011 ---
http://chronicle.com/article/Social-Media-Lure-Academics/126426/
Social media have become serious academic tools for
many scholars, who use them for collaborative writing, conferencing, sharing
images, and other research-related activities. So says a study just posted
online called "Social
Media and Research Workflow." Among its findings:
Social scientists are now more likely to use social-media tools in their
research than are their counterparts in the biological sciences. And
researchers prefer popular applications like Twitter to those made for
academic users.
The survey, conducted late last year, is the work
of Ciber, as the Centre for Information Behaviour and the Evaluation of
Research is known. Ciber is an interdisciplinary research center based in
University College London's department of information studies. It takes on
research projects for various clients. This one was paid for by the Emerald
Publishing Group Ltd. The idea for the survey came from the Charleston
Observatory, the research arm of the annual Charleston Conference of
librarians, publishers, and vendors.
An online questionnaire went to researchers and
editors as well as publishers, administrators, and librarians on
cross-disciplinary e-mail lists maintained by five participating
publishers—Cambridge University Press; Emerald; Kluwer; Taylor & Francis;
and Wiley. Responses came from 2,414 researchers in 215 countries and "every
discipline under the sun," according to David Nicholas, one of the lead
researchers on the study. He directs the department of information studies
at University College London.
Continued in article
Bob Jensen's threads on social networking are at
http://faculty.trinity.edu/rjensen/ListservRoles.htm
The videos of the three plenary speakers at the 2010 Annual Meetings in San
Francisco are now linked at
http://commons.aaahq.org/hives/1f77f8e656/summary
Although all three speakers
provided inspirational presentations, Steve Zeff and I both concluded that Bob
Kaplan’s presentation was possibly the best that we had ever viewed among all
past AAA plenary sessions. And we’ve seen a lot of plenary sessions in our long
professional careers.
Now that Kaplan’s video is
available I cannot overstress the importance that accounting educators and
researchers watch the video of Bob Kaplan's August 4, 2010 plenary presentation
Note that to watch the entire Kaplan video ---
http://commons.aaahq.org/hives/531d5280c3/posts?postTypeName=session+video
I think the video is only available to AAA members.
Also see (slow loading)
http://faculty.trinity.edu/rjensen/theory01.htm#WhatWentWrong
Trivia Questions
1. Why did Bob wish he’d worn a different color suit?
2. What does JAE stand for
besides the Journal of Accounting and Economics?
September 9, 2011 reply from Paul Williams
Bob,
I have avoided chiming in on this thread; have gone down this same road and
it is a cul-de-sac. But I want to say that this line of argument is a
clever one. The answer to your rhetorical question is, No, they aren't
more ethical than other "scientists." As you tout the Kaplan
speech I would add the caution that before he raised the issue of practice,
he still had to praise the accomplishments of "accountics" research by
claiming numerous times that this research has led us to greater
understanding about analysts, markets, info. content, contracting, etc.
However, none of that is actually true. As a panelist at the AAA
meeting I juxtaposed Kaplan's praise for what accountics research has taught
us with Paul Krugman's observations about Larry Summer's 1999 observation
that GAAP is what makes US capital markets so stable and efficient. Of
course, as Krugman noted, none of that turned out to be true. And if
that isn't true, then Kaplan's assessment of accountics research isn't
credible, either. If we actually did understand what he claimed we now
understand much better than we did before, the financial crisis of 2008
(still ongoing) would not have happened. The title of my talk was (the
panel was organized by Cheryl McWatters) "The Epistemology of
Ignorance." An obsessive preoccupation with method could be a choice not to
understand certain things-- a choice to rigorously understand things as you
already think they are or want so desperately to continue to believe for
reasons other than scientific ones.
Paul
TAR versus AMR and AMJ and Footnotes of the American Sociology Association
Introduction
Accountics Scientists Seeking Truth:
"Frankly, Scarlett, after I get a hit for my resume in The Accounting Review
I just don't give a damn"
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
One more mission in what's left of my life will be to try to change this
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
Hi Roger,
Although I agree with you regarding how the AAA journals do not have a means of
publishing "short research articles quickly," Accounting Horizons
(certainly not TAR) for publishing now has a Commentaries section. I don't know
if the time between submission and publication of an AH Commentary is faster on
average than mainline AH research articles, but my priors are that it is quicker
to get AH Commentaries published on a more timely basis.
The disappointing aspect of the published AH Commentaries to date is that they
do not directly focus on controversies of published research articles. Nor are
they a vehicle for publishing abstracts of attempted replications of published
accounting research. I don't know if this is AH policy or just the lack of
replication in accountics science. In real science journals there are generally
alternatives for publishing abstracts of replication outcomes and commentaries
on published science articles. The AH Commentaries do tend to provide literature
reviews on narrow topics.
The American Sociological Association has a journal called Footnotes ---
http://www.asanet.org/journals/footnotes.cfm
Article Submissions are limited to
1,100 words and must have journalistic value (e.g., timeliness, significant
impact, general interest) rather than be research-oriented or scholarly in
nature. Submissions are reviewed by the editorial board for possible
publication.
ASA Forum (including letters to
the editor) - 400-600-word limit.
Obituaries - 700-word limit.
Announcements - 150-word limit.
All submissions should include a contact name and
an email address. ASA reserves the right to edit for style and length all
material published.
Deadline for all materials is the
first of the month preceding publication (e.g., February 1 for March issue).
Send communications on materials, subscriptions,
and advertising to:
American Sociological Association
1430 K Street, NW - Suite 600
Washington, DC 20005-4701
The American Accounting Association Journals do not have something
comparable to Footnotes or the ASA Forum, although the AAA does
have both the AAA Commons and the AECM where non-refereed "publishing" is common
for gadflies like Bob Jensen. The Commons is still restricted to AAA members and
as such does not get covered by search crawlers like Google. The AECM is
unrestricted to AAA Members, but since it requires free subscribing it does not
get crawled over by Google, Yahoo, Bing, etc.
Hi Zane,
I, along with others, have been trying to make TAR and other AAA journals more
responsible about publishing the commentaries on previously published resear4ch
papers, including commentaries on successful or failed replication efforts.
TAR is particularly troublesome in this regard. Former TAR Senior Editor Steve
Kachelmeier insists that the problem does not lie with TAR editors. Literally
every submitted commentary, including short reports of replication efforts, has
been rejected by TAR referees for decades.
So I looked into how other research journals met their responsibilities for
publishing these commentaries. They do it in a variety of ways, but my
preferred model is the Dialogue section of The Academy of Management
Journal (AMJ) --- in part because the AMJ has been somewhat successful in
engaging practitioner commententaries. I wrote the following at
The Dialogue section of the AMJ invites reader comments challenging validity of
assumptions in theory and, where applicable, the assumptions of an analytics
paper. The AMJ takes a slightly different tack for challenging validity in what
is called an “Editors’ Forum,” examples of which are listed in the index at
http://journals.aomonline.org/amj/amj_index_2007.pdf
One index had some academic vs. practice Editors'
Forum articles that especially caught my eye as it might be extrapolated to the
schism between academic accounting research versus practitioner needs for
applied research:
Bartunek, Jean M. Editors’ forum (AMJ turns 50!
Looking back and looking ahead)—Academic-practitioner collaboration need not
require joint or relevant research: Toward a relational
Cohen, Debra J. Editors’ forum
(Research-practice gap in human resource management)—The very separate
worlds of academic and practitioner publications in human resource
management: Reasons for the divide and concrete solutions for bridging the
gap. 50(5): 1013–10
Guest, David E. Editors’ forum
(Research-practice gap in human resource management)—Don’t shoot the
messenger: A wake-up call for academics. 50(5): 1020–1026.
Hambrick, Donald C. Editors’ forum (AMJ turns
50! Looking back and looking ahead)—The field of management’s devotion to
theory: Too much of a good thing? 50(6): 1346–1352.
Latham, Gary P. Editors’ forum
(Research-practice gap in human resource management)—A speculative
perspective on the transfer of behavioral science findings to the workplace:
“The times they are a-changin’.” 50(5): 1027–1032.
Lawler, Edward E, III. Editors’ forum
(Research-practice gap in human resource management)—Why HR practices are
not evidence-based. 50(5): 1033–1036.
Markides, Costas. Editors’ forum (Research with
relevance to practice)—In search of ambidextrous professors. 50(4): 762–768.
McGahan, Anita M. Editors’ forum (Research with
relevance to practice)—Academic research that matters to managers: On
zebras, dogs, lemmings,
Rousseau, Denise M. Editors’ forum
(Research-practice gap in human resource management)—A sticky, leveraging,
and scalable strategy for high-quality connections between organizational
practice and science. 50(5): 1037–1042.
Rynes, Sara L. Editors’ forum (Research with
relevance to practice)—Editor’s foreword—Carrying Sumantra Ghoshal’s torch:
Creating more positive, relevant, and ecologically valid research. 50(4):
745–747.
Rynes, Sara L. Editors’ forum (Research-practice
gap in human resource management)—Editor’s afterword— Let’s create a tipping
point: What academics and practitioners can do, alone and together. 50(5):
1046–1054.
Rynes, Sara L., Tamara L. Giluk, and Kenneth G.
Brown. Editors’ forum (Research-practice gap in human resource
management)—The very separate worlds of academic and practitioner
periodicals in human resource management: Implications
More at
http://journals.aomonline.org/amj/amj_index_2007.pdf
Also see the index sites for earlier years ---
http://journals.aomonline.org/amj/article_index.htm
My appeal for an AMJ model as a way to meet TAR responsibilities for reporting
replications and commentaries fell on deaf ears in the AECM.
So now I'm working on another tack The AAA Commons now publishes TAR tables of
contents. But the accountics science authors have never made an effort to
explain their research on the Commons. And members of the AAA have never taken
an initiative to comment on those articles or to report successful or failed
replication efforts.
I think the problem is that a spark has to ignite both the TAR authors and the
AAA membership to commence dialogs on TAR articles as well as articles published
by other AAA journals.
To this extent I have the start of a working paper on these issues at
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
My purpose in starting the above very unfinished working paper is two fold.
Firstly, it is to show how the very best of the AAA's accountics scientists up
to now just don't give a damn about supporting the AAA Commons. My mission for
the rest my life will be to change this.
Secondly, it is to show that the AAA membership has shown no genuine interest to
discuss research published in the AAA journals. My mission in life for the rest
of my life will be to change this. Julie Smith David, bless her heart, is now
working at my behest to provide me with data regarding who has been the most
supportive of the AAA Commons over since it was formed in 2008. From this I hope
to learn more about what active contributors truly want from their Commons. To
date my own efforts have simply been to add honey-soaked tidbits to help attract
the publish to the AAA Commons. I most certainly like more active contributors
to relieve me of this chore in my life.
My impossible dream is to draw accounting teachers, students, and
practitioners into public hives of discussion of AAA journal research.
Maybe I'm just a dreamer. But at least I'm still trying after every other
initiative I've attempted to draw accountics researchers onto the Commons has
failed. I know we have some accountics scientist lurkers on the AECM, but aside
from Steve Kachelmeier they do not submit posts regarding their work in progress
or their published works.
Thank you Steve for providing value added in your AECM debates with me and some
others like Paul Williams even if that debate did boil over.
Respectfully,
Bob Jensen
Hi Marc,
Paul Williams has addressed your accountics scientists power questions much
better than me in both an AOS article and in AECM messaging ---
http://www.trinity.edu/rjensen/TheoryTAR.htm#Comments
Williams, P. F., Gregory, J. J., I. L. (2006). The Winnowing Away of Behavioral
Accounting Research in the U.S.:The Process of Anointing Academic Elites.
Accounting, Organizations and Society/Elsevier, 31, 783-818.
Williams, P.F. “Reshaping Accounting Research: Living in the World in Which We
Live,” Accounting Forum, 33, 2009: 274 – 279.
Schwartz, B., Williams, S. and Williams, P.F., “U.S. Doctoral Students
Familiarity with Accounting Journals: Insights into the Structure of the U.S.
Academy,” Critical Perspectives on Accounting, 16(2),April 2005: 327-348.
Williams, Paul F., “A Reply to the Commentaries on: Recovering Accounting as a
Worthy Endeavor,” Critical Perspectives on Accounting, 15(4/5), 2004: 551-556.
Jensen Note: This journal prints
Commentaries on previous published articles, something that TAR referees just
will not allow.
Williams, Paul and Lee, Tom, “Accounting from the Inside: Legitimizing the
Accounting Academic Elite,” Critical Perspectives on Accounting (forthcoming).
Jensen Comment
As far as accountics science power in the AAA is concerned, I think that in year
2010 we will look back at years 2011-12 as monumental shifts in power, not the
least of which is the democratization of the AAA. Changes will take time in both
the AAA and in the AACSB's accountancy doctoral programs where accountics
scientists are still firmly entrenched.
But accountics scientist political power will wane, Changes will begin with the
AAA Publications Committee and then with key editorships, notably the editorship
of TAR.
If I have any influence in any of this it will be to motivate our leading
accountics scientists to at last start making contributions to the AAA Commons.
I know that making accountics scientists feel guilty of negligence on the AAA
Commons is not the best motivator as a rule, but what other choice have I got at
this juncture?
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
Respectfully,
Bob Jensen
Calvin Ball
Accountics science is defined at
http://faculty.trinity.edu/rjensen/395wpTAR/Web/TAR395wp.htm
One of the main reasons Bob Jensen contends that accountics science is not yet a
real science is that lack of exacting replications of accountics science
findings. By exacting replications he means reproducibility as defined in the
IAPUC Gold Book ---
http://en.wikipedia.org/wiki/IUPAC_Gold_Book
The leading accountics science (an indeed the leading academic accounting
research journals) are The Accounting Review (TAR), the Journal of
Accounting Research (JAR), and the Journal of Accounting and Economics
(JAE). Publishing accountics science in these journals is a necessary condition
for nearly all accounting researchers at top R1 research universities in North
America.
On the AECM listserv, Bob Jensen and former TAR Senior Editor Steven
Kachelmeier have had an ongoing debate about accountics science relevance and
replication for well over a year in what Steve now calls a game of CalvinBall.
When Bob Jensen noted the lack of exacting replication in accountics science,
Steve's CalvinBall reply was that replication is the name of the game in
accountics science:
The answer to your question, "Do you really think
accounting researchers have the hots for replicating their own findings?" is
unequivocally YES,
though I am not sure about the word "hots." Still, replications in the sense
of replicating prior findings and then extending (or refuting) those
findings in different settings happen all the time, and they get published
regularly. I gave you four examples from one TAR issue alone (July 2011).
You seem to disqualify and ignore these kinds of replications because they
dare to also go beyond the original study. Or maybe they don't count for you
because they look at their own watches to replicate the time instead of
asking to borrow the original researcher's watch. But they count for me.
To which my CalvinBall reply to Steve is --- "WOW!" In the past four decades
of all this unequivocal replication in accountics science there's not been a
single scandal. Out of the thousands of accountics science papers published in
TAR, JAR, and JAE there's not been a single paper withdrawn after publication,
to my knowledge, because of a replication study discovery. Sure there have been
some quibbles about details in the findings and some improvements in statistical
significance by tweaking the regression models, but there's not been a
replication finding serious enough to force a publication retraction or serious
enough to force the resignation of an accountics scientist.
In real science, where more exacting replications really are the name of the
game, there have been many scandals over the past four decades. Nearly all top
science journals have retracted articles because independent researchers could
not exactly replicate the reported findings. And it's not all that rare to force
a real scientist to resign due to scandalous findings in replication efforts.
The most serious scandals entail faked data or even faked studies. These
types of scandals apparently have never been detected among thousands of
accountics science publications. The implication is that accountics
scientists are more honest as a group than real scientists. I guess that's
either good news or bad replicating.
Given the pressures brought to bear on accounting faculty to publish
accountics science articles, the accountics science scandal may be that
accountics science replications have never revealed a scandal --- to my
knowledge at least.
One of the most recent scandals arose when a very well-known psychologist
named Mark Hauser.
"Author on leave after Harvard inquiry Investigation of scientist’s work finds
evidence of misconduct, prompts retraction by journal," by Carolyn Y. Johnson,
The Boston Globe, August 10, 2010 ---
http://www.boston.com/news/education/higher/articles/2010/08/10/author_on_leave_after_harvard_inquiry/
Harvard University psychologist Marc Hauser — a
well-known scientist and author of the book “Moral Minds’’ — is taking a
year-long leave after a lengthy internal investigation found evidence of
scientific misconduct in his laboratory.
The findings have resulted in the retraction of an
influential study that he led. “MH accepts responsibility for the error,’’
says the retraction of the study on whether monkeys learn rules, which was
published in 2002 in the journal Cognition.
Two other journals say they have been notified of
concerns in papers on which Hauser is listed as one of the main authors.
It is unusual for a scientist as prominent as
Hauser — a popular professor and eloquent communicator of science whose work
has often been featured on television and in newspapers — to be named in an
investigation of scientific misconduct. His research focuses on the
evolutionary roots of the human mind.
In a letter Hauser wrote this year to some Harvard
colleagues, he described the inquiry as painful. The letter, which was shown
to the Globe, said that his lab has been under investigation for three years
by a Harvard committee, and that evidence of misconduct was found. He
alluded to unspecified mistakes and oversights that he had made, and said he
will be on leave for the upcoming academic year.
Continued in article
Update: Hauser resigned from Harvard in 2011 after the published
research in question was retracted by the journals.
Not only have there been no similar reported accountics science scandals
called to my attention, I'm not aware of any investigations of impropriety that
were discovered among all those "replications" claimed by Steve.
Below is a link to a long article about scientific misconduct and the
difficulties of investigating such misconduct. The conclusion seems to rest
mostly upon what insiders apparently knew but were unwilling to testify about in
public. Marc Hauser eventually resigned from Harvard. The most aggressive
investigator in this instance appears to be Harvard University itself.
"Disgrace: On Marc Hauser," by Mark Gross, The Nation, January
9, 2012 ---
http://www.thenation.com/article/165313/disgrace-marc-hauser?page=0,2
. . .
Although some of my knowledge of the Hauser case is
based on conversations with sources who have preferred to remain unnamed,
there seems to me to be little doubt that Hauser is guilty of scientific
misconduct, though to what extent and severity remains to be revealed.
Regardless of the final outcome of the investigation of Hauser by the
federal Office of Research Integrity, irreversible damage has been done to
the field of animal cognition, to Harvard University and most of all to Marc
Hauser.
"Dutch University Suspends Prominent Social Psychologist," Inside
Higher Ed, September 12, 2011 ---
http://www.insidehighered.com/news/2011/09/12/qt#270113
Tilburg University, in the Netherlands,
announced last week that it was suspending D.A.
Stapel from his positions as professor of cognitive social psychology and
dean of the School of Social and Behavioral Sciences because he "has
committed a serious breach of scientific integrity by using fictitious
data in his publications." The university
has convened a panel to determine which of Stapel's papers were based on
false data. Science noted that Stapel's work -- in that publication and
elsewhere -- was known for attracting attention. Science reported that
Philip Eijlander, Tilburg's rector, told a Dutch television station that
Stapel had admitted to the fabrications. Eijlander said that junior
researchers in Stapel's lab came forward with concerns about the honesty of
his data, setting off an investigation by the university.
Jensen Comment
Actually I'm being somewhat unfair here. It was not exacting replication studies
that upended Professor Stapel in this instance. There are, of course, other
means of testing internal controls in scientific research. But the most common
tool is replication of reproducible experiments.
Replication researchers did upend Marc Hauser at Harvard ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
Below is a link to a long article about scientific misconduct and the
difficulties of investigating such misconduct. The conclusion seems to rest
mostly upon what insiders apparently knew but were unwilling to testify about in
public. Marc Hauser eventually resigned from Harvard. The most aggressive
investigator in this instance appears to be Harvard University itself.
"Disgrace: On Marc Hauser," by Mark Gross, The Nation, January
9, 2012 ---
http://www.thenation.com/article/165313/disgrace-marc-hauser?page=0,2
. . .
Although some of my knowledge of the Hauser case is
based on conversations with sources who have preferred to remain unnamed,
there seems to me to be little doubt that Hauser is guilty of scientific
misconduct, though to what extent and severity remains to be revealed.
Regardless of the final outcome of the investigation of Hauser by the
federal Office of Research Integrity, irreversible damage has been done to
the field of animal cognition, to Harvard University and most of all to Marc
Hauser.
Bob Jensen's threads on the lack of validity testing and investigations of
misconduct in accountics science ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
"Bad science: The psychology behind exaggerated & false research [infographic],"
Holykaw, December 21, 2011 ---
http://holykaw.alltop.com/bad-science-the-psychology-behind-exaggerated
One in three scientists admits to using shady research practices.
Bravo: Zero accountics scientists admit to using shady research practices.
One in 50 scientists admit to falsifying data outright.
Bravo: Zero accountics scientists admit to falsifying data in the history
of accountics science.
Reports of colleague misconduct are even more common.
Bravo: But not in accountics science
Misconduct rates are highest among clinical, medical, and phamacological
researchers
Bravo: Such reports are lowest (zero) among accountics scientists
Four ways to make research more honest
- Make all raw data available to other scientists
- Hold journalists accountable
- Introduce anonymous publication
- Change from real science into accountics science where research is
unlikely to be validated/replicated except on rare occasions where no errors
are ever found
"Fraud Scandal Fuels Debate Over Practices of Social Psychology:
Even legitimate researchers cut corners, some admit," by Christopher Shea,
Chronicle of Higher Education, November 13, 2011 ---
http://chronicle.com/article/As-Dutch-Research-Scandal/129746/
Jensen Comment
This leads me to wonder why in its entire history, there has never been a
reported scandal or evidence of data massaging in accountics (accounting)
science. One possible explanation is that academic accounting researchers are
more careful and honest than academic social psychologists. Another explanation
is that accountics science researchers rely less on teams of student assistants
who might blow the whistle, which is how Professor Diederik A. Stapel got caught
in social psychology.
But there's also a third possible reason there have been no scandals in the
last 40 years of accountics research. That reason is that the leading accountics
research journal referees discourage validity testing of accountics research
findings ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
Yet a fifth and more probable explanation is that there's just not enough
interest in most accountics science findings to inspire replications and active
debate/commentaries in either the academic journals or the practicing
profession's journals.
There also is the Steve Kachelmeier argument that there are indirect
replications taking place that do not meet scientific standards for replications
but nevertheless point to consistencies in some of the capital markets studies
(rarely the behavioral accounting studies). This does not answer the question of
why nearly all of the indirect replications rarely point to inconsistencies.
It follows that accountics science researchers are just more accurate and honest
than their social science colleagues.
Yeah Right!
Accountics scientists "never cut corners" except where fully disclosed in their
research reports.
We just know what's most important in legitimate science.
Why can't real scientists be more like us --- ever honest and ever true?
Are the foot soldiers behind psychology’s replication crisis (reform)
saving science — or destroying it? ---
https://www.chronicle.com/article/I-Want-to-Burn-Things-to/244488?cid=at&utm_source=at&utm_medium=en&elqTrackId=927c155b3f3a433faf1edb36c7554be8&elq=16868c5647c6471fadb18cae5ca9e795&elqaid=20470&elqat=1&elqCampaignId=9626
. . .
As you’ve no doubt
heard by now, social psychology has had a rough few years. The trouble
concerns the replicability crisis, a somewhat antiseptic phrase that refers
to the growing realization that often the papers published in peer-reviewed
journals — papers with authoritative abstracts and nifty-looking charts —
can’t be reproduced. In other words, they don’t work when scientists try
them again. If you wanted to pin down the moment when the replication crisis
really began, you might decide it was in 2010, when Daryl Bem, a Cornell
psychologist, published a paper in
The Journal of Personality and Social
Psychology
that purported to prove that subjects could predict the future. Or maybe it
was in 2012, when researchers
failed to replicate
a much-heralded 1996 study by John Bargh, a Yale psychologist, that claimed
to show that reading about old people made subjects walk more slowly.
And it’s only gotten
worse. Some of the field’s most exciting and seemingly rock-solid findings
now appear sketchy at best. Entire subfields are viewed with suspicion. It’s
likely that many, perhaps most, of the studies published in the past couple
of decades are flawed. Just last month the Center for Open Science reported
that, of 21 social-behavioral-science studies published in Science
and Nature between 2010 and 2015, researchers could successfully
replicate only 13 of them. Again, that’s Science and Nature,
two of the most prestigious scientific journals around.
If you’re a human
interested in reliable information about human behavior, that news is
probably distressing. If you’re a psychologist who has built a career on
what may turn out to be a mirage, it’s genuinely terrifying. The replication
crisis often gets discussed in technical terms: p-values, sample sizes, and
so on. But for those who have devoted their lives to psychology, the
consequences are not theoretical, and the feelings run deep. In 2016, Susan
Fiske, a Princeton psychologist, used the phrase "methodological terrorism"
to describe those who dissect questionable research online, bypassing the
traditional channels of academic discourse (one researcher at SIPS, who
asked not to be identified, wore a T-shirt to the conference emblazoned with
the words "This Is What a Methodological Terrorist Looks Like"). Fiske wrote
that "unmoderated attacks" were leading psychologists to abandon the field
and discouraging students from pursuing it in the first place.
Psychologists like
Fiske argue that these data-crunching critics, like many of the attendees at
SIPS, paint far too dark a portrait of the field. Yes, there are lousy
studies that slip through the peer-review net and, sure, methods can always
be improved. Science progresses in fits and starts, with inevitable missteps
along the way. But they complain that the tactics of the reformers — or
terrorists, take your pick — can be gleefully aggressive, that they’re too
eager to, well, burn things to the ground. The handful of researchers who
make it their mission to unearth and expose examples of psychology’s
failings come in for particular scorn. As one tenured professor I spoke with
recently put it, "I think they’re human scum."
ames Heathers is a jovial, bearded Australian who loves cats. He is a
postdoc at Northeastern University with a Ph.D. in cardiac psychophysiology;
when he’s not ranting about subpar research practices on Everything
Hertz, the podcast he co-hosts, he’s hunting for connections between
emotion and heartbeat variability. He’s been working, along with his fellow
data thugs — a term Heathers coined, and one that’s usually (though not
always) employed with affection — on something called Sample Parameter
Reconstruction via Interactive Techniques, or SPRITE. Basically, SPRITE is a
computer program that can be used to see whether survey results, as reported
in a paper, appear to have been fabricated. It can do this because results
usually follow certain statistical patterns, and people who massage data
frequently fail to fake it convincingly. During a SIPS session, Heathers
explained SPRITE with typical élan: "Sometimes you push the button and it
says, ‘Here’s a forest of lunatic garbage.’ "
. . .
As Barrett sees
it, some of what the data thugs do "borders on harassment." The prime
example is that of Amy Cuddy, whose power-pose study was the basis for a TED
talk that’s been viewed more than 48 million times and led to a best-selling
book, Presence (Little, Brown & Company, 2015). The 2010 study has
failed to replicate,
and the first author, Dana Carney, a psychologist at Berkeley, no longer
believes in the effect. The power-pose study is held up as an example of
psychology at its most frivolous and unreliable. Cuddy, though, has not
renounced the research and has likened her treatment to bullying. She
recently tweeted: "People who want to destroy often do so with greater
passion and energy and time than people who want to build." Some
psychologists, including Barrett, see in the ferocity of that criticism an
element of sexism. It’s true that the data thugs tend to be, but are not
exclusively, male — though if you tick off the names of high-profile social
psychologists whose work has been put through the replication ringer, that
list has lots of men on it, too. Barrett thinks the tactics of the data
thugs aren’t creating an atmosphere for progress in the field. "It’s a hard
enough life to be a scientist," she says. "If we want our best and brightest
to be scientists, this is not the way to do it."
Richard Nisbett
agrees. Nisbett has been a major figure in psychology since the 1970s. He’s
co-director of the Culture and Cognition program at the University of
Michigan at Ann Arbor, author of books like Mindware: Tools for Smart
Thinking (Farrar, Straus, and Giroux, 2015), and a slew of influential
studies. Malcolm Gladwell called him "the most influential thinker in my
life." Nisbett has been calculating effect sizes since before most of those
in the replication movement were born.
And he’s a skeptic of
this new generation of skeptics. For starters, Nisbett doesn’t think direct
replications are efficient or sensible; instead he favors so-called
conceptual replication, which is more or less taking someone else’s
interesting result and putting your own spin on it. Too much navel-gazing,
according to Nisbett, hampers professional development. "I’m alarmed at
younger people wasting time and their careers," he says. He thinks that
Nosek’s ballyhooed finding that most psychology experiments didn’t replicate
did enormous damage to the reputation of the field, and that its leaders
were themselves guilty of methodological problems. And he’s annoyed that
it’s led to the belief that social psychology is riddled with errors. How do
they know that?, Nisbett asks, dropping in an expletive for emphasis.
Simine Vazire has
heard that argument before. Vazire, an associate professor of psychology at
the University of California at Davis, and one of the SIPS organizers,
regularly finds herself in meetings where no one shares her sense of urgency
about the replication crisis. "They think the status quo is fine, and we can
make tweaks," she says. "I’m often the only person in the room who thinks
there’s a big problem."
It’s not that the
researchers won’t acknowledge the need for improvement. Who’s against
progress? But when she pushes them on what that means, the division becomes
apparent. They push back on reforms like data transparency (sharing your
data freely with other researchers, so they can check your work) or
preregistration (saying publicly what you’re trying to discover in your
experiment before you try to discover it). That’s not the way it’s normally
been done. Psychologists tend to keep their data secret, arguing that it’s
proprietary or that revealing it would endanger subjects’ anonymity. But not
showing your work makes it easier to fudge what you found. Plus the freedom
to alter your hypothesis is what leads to so-called p-hacking, which is
shorthand for when a researcher goes searching for patterns in statistical
noise.
Continued in article
"Replication
Crisis in Psychology Research Turns Ugly and Odd," by Tom Bartlett,
Chronicle of Higher Education,
June 23, 2014
---
https://www.chronicle.com/article/Replication-Crisis-in/147301/?cid=at&utm_medium=en&utm_source=at
In a blog post published last week, Timothy D. Wilson, a professor of
psychology at the University of Virginia and the author of
The Surprising New Science of Psychological Change
"thatdeclared that "the field has become preoccupied with prevention and
error detection—negative psychology—at the expense of exploration and
discovery." The evidence that psychology is beset with false positives is
weak, according to Mr. Wilson, and he pointed instead to the danger of inept
replications that serve only to damage "the reputation of the original
researcher and the progression of science." While he called for finding
common ground, Mr. Wilson pretty firmly sided with those who fear that
psychology’s growing replication movement, which aims to challenge what some
critics see as a tsunami of suspicious science, is more destructive than
corrective.
Continued in article
The Stanford Prison Experiment lasted just six days, and it took place 47
years ago. But it has shaped our fundamental understanding of human nature. Now
many in the field are wondering: Should it have?
https://www.chronicle.com/article/How-a-Decades-Old-Experiment/244256?cid=at&utm_source=at&utm_medium=en&elqTrackId=8b283b87f55e48d281e307a3d73eb2a1&elq=16868c5647c6471fadb18cae5ca9e795&elqaid=20470&elqat=1&elqCampaignId=9626
Sometimes it takes decades for awareness of flaws in popular research studies to
come to light
Jensen Comment
In academic accountancy the editors have a policy that if the article has
equations (most often multiple regression equations) it does not need to
be replicated. Fortunately this does not matter much in the profession since
practitioners tend to ignore academic articles with equations ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
Sometimes it takes decades for awareness of flaws in popular research studies to
come to light. For example, for decades accounting empiricists based their
regression models on the Capital Asset Pricing Model (CAPM) and the Efficient
Market Hypothesis (EMH) as if the underlying bases for these without truly
examining how flaws in these foundations of capital market research. In fact,
the untested assumptions heavily destroyed robustness of the research,
robustness that went unchallenged and still often goes unchallenged. Even now as
p-tests in statistical inference testing are being challenged in science our
accounting research journal editors and referees seem oblivious to the
limitations of p-test outcomes.
For example on the AECM listserv I called attention to the following discovery
in an empirical accounting research study:
"Finally, we predict and find lower EPS forecast accuracy for U.K. firms
when reporting under the full fair value model of IFRS, in which unrealized
fair value gains and losses are included in net income."
"The
Effect of Fair Value versus Historical Cost Reporting Model on Analyst
Forecast Accuracy,"
by Lihong Liang and Edward J. Riedl,
The Accounting Review (TAR),: May 2014, Vol. 89, No. 3, pp. 1151-1177
---
http://aaajournals.org/doi/full/10.2308/accr-50687 (Not Free)
Accounting Review
readers will have to accept the above finding as truth since TAR will not
encourage or publish a replication study of that finding or even publish a
commentary about that finding. This is wrong in our Academy.
What is an Exacting Replication?
I define an exacting replication as one in which the findings are reproducible
by independent researchers using the IAPUC Gold Book standards for
reproducibility. Steve makes a big deal about time extensions when making such
exacting replications almost impossible in accountics science. He states:
By "exacting replication," you appear to mean doing
exactly what the original researcher did -- no more and no less. So if one
wishes to replicate a study conducted with data from 2000 to 2008, one had
better not extend it to 2009, as that clearly would not be "exacting." Or,
to borrow a metaphor I've used earlier, if you'd like to replicate my
assertion that it is currently 8:54 a.m., ask to borrow my watch -- you
can't look at your watch because that wouldn't be an "exacting" replication.
That's CalvinBall bull since in many of these time extensions it's also
possible to conduct an exacting replication. Richard Sansing pointed out the how
he conducted an exacting replication of the findings in Dhaliwal, Li and R.
Trezevant (2003), "Is a dividend tax penalty
incorporated into the return on a firm’s common stock?," Journal of
Accounting and Economics 35: 155-178. Although Richard and his coauthor
extend the Dhaliwal findings they first conducted an exacting replication in
their paper published in The Accounting Review 85 (May
2010): 849-875.
My quibble with Richard is mostly that conducting an exacting replication of
the Dhaliwal et al. paper was not exactly a burning (hot)
issue if nobody bothered to replicate that award winning JAE paper for seven
years.
This begs the question of why there are not more frequent and timely exacting
replications conducted in accountics science if the databases themselves are
commercially available like the CRSP, Compustat, and AuditAnalytics databases.
Exacting replications from these databases are relatively easy and cheap to
conduct. My contention here is that there's no incentive to excitedly conduct
exacting replications if the accountics journals will not even publish
commentaries about published studies. Steve and I've played CalvinBall with the
commentaries issue before. He contends that TAR editors do not prevent
commentaries from being published in TAR. The barriers to validity questioning
commentaries in TAR are the 574 referees who won't accept submitted commentaries
---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm#ColdWater
Exacting replications of behavioral experiments in accountics science is more
difficult and costly because the replicators must conduct their own experiments
by collecting their own data. But it seems to me that it's no more difficult in
accountics science than in performing exacting replications that are reported in
the research literature of psychology. However, psychologists often have more
incentives to conduct exacting replications for the following reasons that I
surmise:
- Practicing psychologists are more demanding of validity tests of
research findings. Practicing accountants seem to pretty much ignore
behavioral experiments published in TAR, JAR, and JAE such that there's not
as much pressure brought to bear on validity testing of accountics science
findings. One test of practitioner lack of interest is the lack of citation
of accountics science in practitioner journals.
- Psychology researchers have more incentives to replicate experiments of
others since there are more outlets for publication credits of replication
studies, especially in psychology journals that encourage commentaries on
published research ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm#TARversusJEC
My opinion remains that accountics science will never be a real science until
exacting replication of research findings become the name of the game in
accountics science. This includes exacting replications of behavioral
experiments as well as analysis of public data from CRSP, Compustat,
AuditAnalytics, and other commercial databases. Note that willingness of
accountics science authors to share their private data for replication purposes
is a very good thing (I fought for this when I was on the AAA Executive
Committee), but conducting replication studies of such data does not hold up
well under the IAPUC Gold Book.
Note, however, that lack of exacting replication and other validity testing
in general are only part of the huge problems with accountics science. The
biggest problem, in my judgment, is the way accountics scientists have
established monopoly powers over accounting doctoral programs, faculty hiring
criteria, faculty performance criteria, and pay scales. Accounting researchers
using other methodologies like case and field research become second class
faculty.
IS THERE A MULTINATIONALITY EFFECT? A REPLICATION AND REEXAMINATION OF THE
MULTINATIONALITYPERFORMANCE RELATIONSHIP
by Heather Berry and Aseem Kahl
SSRN
June 2015
Abstract:
We revisit the effect of
multinationality on firm performance while
accounting for problems of
consolidation and selection. Using detailed longitudinal data from a
comprehensive sample of US manufacturing MNCs, we replicate the U-shaped
relationship found in prior studies and then show that this U-shaped
relationship results from the combination of a negative relationship
with aggregation activities and a positive relationship with adaptation
and arbitrage activities. Further, once we control for the endogeneity
of multinationality, we no longer find a significant effect of overall
multinationality on performance, although arbitrage activities, in the
form of cross-border product transfers, continue to have a positive
effect on firm performance. These findings provide fresh empirical
insight into the multinationality-performance relationship, while
highlighting the benefits from arbitrage across subsidiary networks.
. . .
Replication of prior studies
We start by trying to replicate the approach and measures used in prior
work; specifically, we try to replicate the relationships found by Lu and
Beamish (2004) in their study of Japanese multinationals. We choose to
replicate Lu and Beamish (2004) both because it is an important and highly
cited study of the multinationality-performance relationship, and because it
is the closest to our work in that it studies multinationals using panel
data. Models I-IV in Table Three show the results of our attempt to
replicate the findings of Lu and Beamish (2004) in our sample, using the
same dependent variable and predictors that they use6, as well as a similar
estimation approach..
Models I-III in Table Three
show the relationship of performance with the main, squared
and cubed terms of our consolidated multinationality index respectively,
using a fixed effects OLS regression. Model I shows a moderately significant
negative coefficient for multinationality, which becomes significant at
conventional levels in Model II once we include a squared multinationality
term, which takes a positive and significant coefficient. Model II thus
indicates a U-shaped relationship between multinationality and performance.
We do not find evidence of an S-shaped relationship (Contractor et al.,
2003; Lu and Beamish, 2004), with the coefficient for the cubed term in
Model III being insignificant. Lu and Beamish (2004) also find a positive
interaction between multinationality and parent R&D intensity when
predicting RoA. We attempt to replicate this finding in Model IV, but the
coefficient of the interaction term is insignificant.
Continued in article
Jensen Comment
Replication is not at all common in accounting research ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
To my knowledge there's never been a replication study in accounting that
alters the findings of the original research. When replication does take
place there's usually a relatively long time lag (ten years or more) such that
the intent of the replication is not to validate the original findings. Rather
the intent is to set the stage for expanding the research model to better
explain the findings of the earlier studies.
The Berry and Kahl replication and model expansion fits into this pattern.
The original studies went over ten years without being replicated.
Berry and Kahl conducted a replication that did not alter the findings of the
original studies. Berry and Kahl design a more complicated model to explain
better explain the U-shaped relationship as described above.
Since the odds of getting a case or field study published are so low, very
few of such studies are even submitted for publication in TAR in recent years.
Replication of these is a non-issue in TAR.
"Annual Report and Editorial Commentary for The Accounting Review,"
by Steven J. Kachelmeier The University of Texas at Austin, The
Accounting Review, November 2009, Page 2056.
Insert Table

There's not much hope for case, field, survey, and other non-accountics
researchers to publish in the leading research journal of the American
Accounting Association.
What went wrong with accountics research?
http://faculty.trinity.edu/rjensen/theory01.htm#WhatWentWrong
"We fervently hope that the research pendulum will soon swing back from the
narrow lines of inquiry that dominate today's leading journals to a rediscovery
of the richness of what accounting research can be. For that to occur, deans and
the current generation of academic accountants must
give it a push."
Granof and Zeff ---
http://www.trinity.edu/rjensen/TheoryTAR.htm#Appendix01
Michael H. Granof is a professor of accounting at the McCombs School of
Business at the University of Texas at Austin. Stephen A. Zeff is a
professor of accounting at the Jesse H. Jones Graduate School of Management at
Rice University.
I admit that I'm just one of those
professors heeding the Granof and Zeff call to "give it a push," but it's
hard to get accountics professors to give up their monopoly on TAR, JAR, JAE,
and in recent years Accounting Horizons. It's even harder to get them to
give up their iron monopoly clasp on North American Accountancy Doctoral
Programs ---
http://www.trinity.edu/rjensen/Theory01.htm#DoctoralPrograms
September 9, 2011 reply from Paul Williams
Bob,
I have avoided chiming in on this thread; have gone down this same road and
it is a cul-de-sac. But I want to say that this line of argument is a
clever one. The answer to your rhetorical question is, No, they aren't
more ethical than other "scientists." As you tout the Kaplan
speech I would add the caution that before he raised the issue of practice,
he still had to praise the accomplishments of "accountics" research by
claiming numerous times that this research has led us to greater
understanding about analysts, markets, info. content, contracting, etc.
However, none of that is actually true. As a panelist at the AAA
meeting I juxtaposed Kaplan's praise for what accountics research has taught
us with Paul Krugman's observations about Larry Summer's 1999 observation
that GAAP is what makes US capital markets so stable and efficient. Of
course, as Krugman noted, none of that turned out to be true. And if
that isn't true, then Kaplan's assessment of accountics research isn't
credible, either. If we actually did understand what he claimed we now
understand much better than we did before, the financial crisis of 2008
(still ongoing) would not have happened. The title of my talk was (the
panel was organized by Cheryl McWatters) "The Epistemology of
Ignorance." An obsessive preoccupation with method could be a choice not to
understand certain things-- a choice to rigorously understand things as you
already think they are or want so desperately to continue to believe for
reasons other than scientific ones.
Paul
September 10, 2011 reply from Bob Jensen (known on the AECM as Calvin of
Calvin and Hobbes)
This is a reply to Steve Kachelmeier, former Senior Editor of The Accounting
Review (TAR)
I agree Steve and will not bait you further in a game of Calvin Ball.
It is, however, strange to me that exacting replication
(reproducibility) is such a necessary condition to almost all of real
science empiricism and such a small part of accountics science empiricism.
My only answer to this is that the findings themselves in science seem to
have greater importance to both the scientists interested in the findings
and the outside worlds affected by those findings.
It seems to me that empirical findings that are not replicated with as much
exactness as possible are little more than theories that have only been
tested once but we can never be sure that the tests were not faked or
contain serious undetected errors for other reasons.
It is sad that the accountics science system really is not designed to guard
against fakers and careless researchers who in a few instances probably get
great performance evaluations for their hits in TAR, JAR, and JAE. It is
doubly sad since internal controls play such an enormous role in our
profession but not in our accoutics science.
I thank you for being a noted accountics scientist who was willing to play
Calvin Ball.with me for a while. I want to stress that this is not really a
game with me. I do want to make a difference in the maturation of accountics
science into real science. Exacting replications in accountics science would
be an enormous giant step in the real-science direction.
Allowing validity-questioning commentaries in TAR would be a smaller start
in that direction but nevertheless a start. Yes I know that it was your 574
TAR referees who blocked the few commentaries that were submitted to TAR
about validity questions. But the AAA Publications Committees and you as
Senior Editor could've done more to encourage both submissions of more
commentaries and submissions of more non-accountics research papers to TAR
--- cases, field studies, history studies, AIS studies, and (horrors)
normative research.
I would also like to bust the monopoly that accountics scientists have on
accountancy doctoral programs. But I've repeated my arguments here far to
often ---
http://www.trinity.edu/rjensen/Theory01.htm#DoctoralPrograms
In any case thanks for playing Calvin Ball with me. Paul Williams and
Jagdish Gangolly played Calvin Ball with me for a while on an entirely
different issue --- capitalism versus socialism versus bastardized versions
of both that evolve in the real world.
Hopefully there's been some value added on the AECM in my games of Calvin
Ball.
Even though my Calvin Ball opponents have walked off the field, I will
continue to invite others to play against me on the AECM.
And I'm certain this will not be the end to my saying that accountics
farmers are more interested in their tractors than their harvests. This may
one day be my epitaph.
Respectfully,
Calvin
November 22, 2011 reply from Steve Kachelmeier
First, Table 3 in the 2011 Annual Report
(submissions and acceptances by area) only includes manuscripts that went
through the regular blind reviewing process. That is, it excludes invited
presidential scholar lectures, editorials, book reviews, etc. So "other"
means "other regular submissions."
Second, you are correct Bob that "other" continues
to represent a small percentage of the total acceptances. But "other" is
also a very small percentage of the total submissions. As I state explicitly
in the report, Table 3 does not prove that TAR is sufficienty diverse. It
does, however, provide evidence that TAR acceptances by topical area (or by
method) are nearly identically proportional to TAR submissions by topical
area (or by method).
Third, for a great example of a recently published
TAR study with substantial historical content, see Madsen's analysis of the
historical development of standardization in accounting that we published in
in the September 2011 issue. I conditionally accepted Madsen's submission in
the first round, backed by favorable reports from two reviewers with
expertise in accounting history and standardization.
Take care,
Steve
November 23, 2011 reply from Bob Jensen
Hi Steve,
Thank you for the clarification.
Interestingly, Madsen's September 2011 historical study (which came out
after your report's May 2011 cutoff date) is a heavy accountics science
paper with a historical focus.
It would be interesting to whether such a paper would've been accepted by
TAR referees without the factor (actually principal components) analysis.
Personally, I doubt any history paper would be accepted without equations
and quantitative analysis. Once again I suspect that accountics science
farmers are more interested in their tractors than in their harvests.
In the case of Madsen's paper, if I were a
referee I would probably challenge the robustness of the principal
components and loadings ---
http://en.wikipedia.org/wiki/Principle_components_analysis
Actually factor analysis in general like nonlinear multiple regression and
adaptive versions thereof suffer greatly from lack of robustness. Sometimes
quantitative models gild the lily to a fault.
Bob Kaplan's Presidential Scholar historical study was published, but
this was not subjected to the usual TAR refereeing process.
The History of The Accounting Review paper written by Jean Heck and Bob
Jensen which won a best paper award from the Accounting Historians Journal
was initially flatly rejected by TAR. I was never quite certain if the main
reason was that it did not contain equations or if the main reason was that
it was critical of TAR editorship and refereeing. In any case it was flatly
rejected by TAR, including a rejection by one referee who refused to put
reasons in writing for feed\back to Jean and me.
“An Analysis of the Evolution of Research Contributions by The
Accounting Review: 1926-2005,” (with Jean Heck), Accounting
Historians Journal, Volume 34, No. 2, December 2007, pp. 109-142.
I would argue that accounting history papers, normative methods papers,
and scholarly commentary papers (like Bob Kaplan's plenary address) are not
submitted to TAR because of the general perception among the AAA membership
that such submissions do not have a snowball's chance in Hell of being
accepted unless they are also accountics science papers.
It's a waste of time and money to submit papers to TAR that are not
accountics science papers.
In spite of differences of opinion, I do thank you for the years of
blood, sweat, and tears that you gave us as Senior Editor of TAR.
And I wish you and all U.S. subscribers to the AECM a very Happy
Thanksgiving. Special thanks to Barry and Julie and the AAA staff for
keeping the AECM listserv up and running.
Respectfully,
Bob Jensen
In only one way do I want to distract from the quality and quantity of effort of
TAR Senior Editor Steve Kachelmeier. The job of TAR's Senior Editor is
overwhelming given the greatly increased number of submissions to TAR
while he's been our Senior Editor. Steve's worked long and hard assembling a
superb team of associate editors and reviewers for over 600 annual submissions.
He's had to resolve many conflicts between reviewers and deal personally with
often angry and frustrated authors. He's helped to re-write a lot of badly
written papers reporting solid research. He's also suggested countless ways to
improve the research itself. And in terms of communications with me (I can be a
pain in the butt), Steve has been willing to take time from his busy schedule to
debate with me in private email conversations.
The most discouraging aspect of Steve's editorship is, in my viewpoint, his
failure to encourage readers to submit discussions, comments, replication
abstracts, or commentaries on previously published articles in TAR. He says that
readers are free to submit most anything to him, but that if a submission does
not "extend" the research in what is essentially a new research paper, his teams
of referees are likely to reject it.
While Steve has been Senior Editor of TAR, I do not know of any submitted
discussion or comment on a previously published paper that simply raised
questions about a published paper but did not actually conduct research
needed to submit an entirely new research product. Hence, if readers want
to comment on a TAR article they should, according to Steve, submit a full research paper for review that extends that research in a significant
way or find some other outlet for commentary such as the
AECM listserv that only
reaches a relatively small subset of all accountants, accounting teachers, and accounting researchers
in the world.
Steve replied by stating that, during his term as Senior Editor, he only sent out
one comment submission that was resoundingly rejected by his referees but
was later accepted after the author conducted empirical research
and extended the original study in a significant way. However, he and I differ
with respect to what I call a "commentary" for purposes of this
document. For this document I am limiting the term "commentary" to a comment or
discussion of a previously published paper that does not extend the research in
a significant way. I consider a "commentary" here to be more like a discussant's comments when the paper is
presented at a conference. Without actually conducting additional empirical
research a discussant can criticize or praise a paper and suggest ways that the
research can be improved. The discussant does not actually have to conduct the
suggested research extensions that Steve tells me is a requisite for his
allowing TAR to publish a comment.
I also allow, in this document, the term "commentary" to include a brief
abstract of an attempt to exactly replicate the research reported in a
previously-published TAR paper. The replication report can be more of a summary
than a complete research paper. It might simply report on how a replication
succeeded or failed. I elaborate on the term "replication" below. I do not know
of a single exact replication report ever published in TAR regarding a lab
experiment. I'm hoping that someone will point out where TAR published a report
of an exact replication of a lab experiment. Of course, some empirical study
replications are more complex, and I discuss this below.
In fairness, I was wrong to have asserted that Steve will not send a
"commentary" as defined above out for review. His reply to me was as follows:
No, no, no! Once again, your characterization makes
me out to be the dictator who decides the standards of when a comment gets
in and when it doesn’t. The last sentence is especially bothersome regarding
what “Steve tells me is a requisite for his allowing TAR to publish a
comment.” I never said that, so please don’t put words in my mouth.
If I were to receive a comment of the “discussant”
variety, as you describe, I would send it out for review to two reviewers in
a manner 100% consistent with our stated policy on p. 388 of the January
2010 issue (have you read that policy?). If both reviewers or even the one
independent reviewer returned favorable assessments, I would then strongly
consider publishing it and would most likely do so. My observation, however,
which you keep wanting to personalize as “my policy,” is that most peer
reviewers, in my experience, want to see a meaningful incremental
contribution. (Sorry for all the comma delimited clauses, but I need this to
be precise.) Bottom line: Please don’t make it out to be the editor’s
“policy” if it is a broader phenomenon of what the peer community wants to
see. And the “peer community,” by the way, are regular professors from all
varieties of backgrounds. I name 574 of them in the November 2009 issue.
Steve reports that readers of TAR just do not submit the "discussant" variety
to him for consideration for publication in TAR. My retort is that, unlike the
AMR discussed below, Steve has not encouraged TAR readers to send in such
commentaries about papers published in TAR. To the contrary, in meetings and
elsewhere he's consistently stated that his referees are likely to reject any
commentaries that simply question underlying assumptions, model structures, or
data in a previously published paper. Hence, I contend
that there are 574 Shields Against Validity Challenges in Plato's Cave,
An illustration of a commentary that two of the 574 guards would resoundingly
reject is illustrated at
http://faculty.trinity.edu/rjensen/TheoryTAR.htm#Analytics
However, I think this commentary might be of value to accounting students,
faculty, and practitioners. Students could write similar commentaries about
other selected TAR articles and then meet in chat rooms or class to search for
common themes or patterns in their commentaries.
Most papers published in TAR simply accept external validity of underlying
assumptions. Normative arguments to the contrary are not likely to be published
in TAR.
"Deductive reasoning," Phil Johnson-Laird, Wiley Interscience,
,2009 ---
http://www3.interscience.wiley.com/cgi-bin/fulltext/123228371/PDFSTART?CRETRY=1&SRETRY=0
This article begins with an account of logic,
and of how logicians formulate formal rules of inference for the sentential
calculus, which hinges on analogs of negation and the connectives if, or,
and and. It considers the various ways in which computer scientists have
written programs to prove the validity of
inferences in this and other domains. Finally,
it outlines the principal psychological theories of how human reasoners
carry out deductions. 2009 John Wiley & Sons, Ltd. WIREs Cogn Sci 2010
1 8–1
By far the most important recommendation that I make below in this message
is for the American Accounting Association to create an electronic journal for
purposes of commentaries and replication abstracts that follow up on
previously published articles in AAA research journals, particularly TAR. In that
context, my recommendation is an extension of the Dialogue section of the
Academy of Management Review.
Nearly all the articles published in TAR over the past several decades are
limited to accountics studies that, in my viewpoint, have questionable internal
and external validity due to missing variables, measurement errors, and
simplistic mathematical structures. If accountants grounded in the real world
were allowed to challenge the external validity of accountics studies it is
possible that accountics researchers would pay greater attention to
external validity ---
http://en.wikipedia.org/wiki/External_Validity
Similarly if accountants grounded in the real world were allowed to
challenge the external validity of accountics studies it is possible that
accountics researchers would pay greater attention to
internal validity ---
http://en.wikipedia.org/wiki/Internal_Validity
An illustration of a commentary that the 574 guards would refuse to put out to review
is illustrated at
http://faculty.trinity.edu/rjensen/TheoryTAR.htm#Analytics
However, I think this commentary might be of value to accounting students,
faculty, and practitioners. Students could write similar commentaries about
other selected TAR articles and then meet in chat rooms or class to search for
common themes or patterns in their commentaries.
I should note that the above commentary is linked at the AAA Commons. Perhaps
the AAA Commons should start a special hive for commentaries about TAR articles,
including student commentaries submitted by their instructors to the Commons ---
http://commons.aaahq.org/pages/home
In the practitioner literature readers have to be a little careful on the
definition of "analytics." Practitioners often define analytics in terms of
micro-level use of data for decisions such as decisions to adopt a new product
or launch a promotion campaign..
See
Analytics at Work: Smarter Decisions, Better Results, by Tom
Davenport (Babson College) --- ISBN-13: 9781422177693, February
2010
Listen to Tom Davenport being interviewed about his book ---
http://blogs.hbr.org/ideacast/2010/01/better-decisions-through-analy.html?cm_mmc=npv-_-DAILY_ALERT-_-AWEBER-_-DATE
The book does not in general find a niche for analytics for huge decisions
such as mergers, but the above book does review an application by Chevron.
The problem with "big decisions" is that the analytical models generally
cannot mathematically model or get good data on some of the most relevant
variables. In academe, professors often simply assume the real world away and
derive elegant solutions to fantasy-land problems in Plato's Cave. This is all
well and good, but these academic researchers generally ignore validity tests of
their harvests inside Plato's Cave.
June 30, 2012
Hi again Steve and David,
I think most of the problem of relevance of academic accounting research to
the accounting profession commenced with the development of the giant commercial
databases like CRSP, Compustat, and AuditAnalytics. To a certain extent it
hurt sociology research to have giant government databases like the giant census
databases. This gave rise to accountics researchers and sociometrics researchers
who commenced to treat their campuses like historic castles with moats. The
researchers no longer mingled with the outside world due, to a great extent, to
a reduced need to collect their own data from the riff raff.
The focus of our best researchers turned toward increasing creativity of
mathematical and statistical models and reduced creativity in collecting data.
If data for certain variables cannot be found in a commercial database then our
accounting professors and doctoral students merely assume away the importance of
those variables --- retreating more and more into Plato's Cave.
I think the difference between accountics versus sociometrics researchers,
however, is that sociometrics researchers often did not get as far removed from
database building as accountics researchers. They are more inclined to field
research. One of my close sociometric
scientist friends is Mike Kearl. The reason his Website is one of the most
popular Websites in Sociology is Mike's dogged effort to make privately
collected databases available to other researchers ---
Mike Kearl's great social theory site
Go to
http://www.trinity.edu/rjensen/theory02.htm#Kearl
I cannot find a single accountics researcher counterpart to Mike Kearl.
Meanwhile in accounting research, the gap between accountics researchers in
their campus castles and the practicing profession became separated by widening
moats.
In the first 50 years of the American Accounting Association over half
the membership was made up of practitioners, and practitioners took part in
committee projects, submitted articles to TAR, and in various instances were
genuine scholarly leaders in the AAA. All this changed when accountics
researchers evolved who had less and less interest in close interactions with
the practitioner world.
“An Analysis of the Evolution of Research Contributions by The Accounting
Review: 1926-2005,” (with Jean Heck), Accounting Historians Journal,
Volume 34, No. 2, December 2007, pp. 109-142.
. . .
Practitioner membership in the AAA faded along with
their interest in journals published by the AAA [Bricker and Previts, 1990].
The exodus of practitioners became even more pronounced in the 1990s when
leadership in the large accounting firms was changing toward professional
managers overseeing global operations. Rayburn [2006, p. 4] notes that
practitioner membership is now less than 10 percent of AAA members, and many
practitioner members join more for public relations and student recruitment
reasons rather than interest in AAA research. Practitioner authorship in TAR
plunged to nearly zero over recent decades, as reflected in Figure 2.
I think that much good could come from providing serious incentives to
accountics researchers to row across the mile-wide moats. Accountics leaders
could do much to help. For example, they could commence to communicate in
English on the AAA Commons ---
How Accountics Scientists Should Change:
"Frankly, Scarlett, after I get a hit for my resume in The Accounting Review
I just don't give a damn"
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
One more mission in what's left of my life will be to try to change this
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
Secondly, I think TAR editors and associate editors could do a great deal by
giving priority to publishing more applied research in TAR so that accountics
researchers might think more about the practicing profession. For example,
incentives might be given to accountics researchers to actually collect their
own data on the other side of the moat --- much like sociologists and medical
researchers get academic achievement rewards for collecting their own data.
Put in another way, it would be terrific if accountics researchers got off
their butts and ventured out into the professional world on the other side of
their moats.
Harvard still has some (older) case researchers like Bob Kaplan who interact
extensively on the other side of the Charles River. But Bob complains that
journals like TAR discourage rather than encourage such interactions.
Accounting Scholarship that Advances Professional
Knowledge and Practice
Robert S. Kaplan
The Accounting Review, March 2011, Volume 86, Issue 2,
Recent accounting scholarship has
used statistical analysis on asset prices, financial reports and
disclosures, laboratory experiments, and surveys of practice. The research
has studied the interface among accounting information, capital markets,
standard setters, and financial analysts and how managers make accounting
choices. But as accounting scholars have focused on understanding how
markets and users process accounting data, they have distanced themselves
from the accounting process itself. Accounting scholarship has failed to
address important measurement and valuation issues that have arisen in the
past 40 years of practice. This gap is illustrated with missed opportunities
in risk measurement and management and the estimation of the fair value of
complex financial securities. This commentary encourages accounting scholars
to devote more resources to obtaining a fundamental understanding of
contemporary and future practice and how analytic tools and contemporary
advances in accounting and related disciplines can be deployed to improve
the professional practice of accounting. ©2010 AAA
It's high time that the leaders of accountics scientists make monumental
efforts to communicate with the teachers of accounting and the practicing
professions. I have enormous optimism regarding our forthcoming fabulous
accountics scientist Mary Barth when she becomes President of the AAA.
I'm really, really hoping that Mary will commence the bridge
building across moats ---
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
The American Sociological Association has a journal called the American
Sociological Review (ASR) that is to the ASA much of what TAR is to the AAA.
The ASR like TAR publishes mostly statistical studies. But there are some
differences that I might note. Firstly, ASR authors are more prone to gathering
their own data off campus rather than only dealing with data they can purchase
or behavioral experimental data derived from students on campus.
Another thing I've noticed is that the ASR papers are more readable and many
have no complicated equations. For example, pick any recent TAR paper at random
and then compare it with the write up at
http://www.asanet.org/images/journals/docs/pdf/asr/Aug11ASRFeature.pdf
Then compare the randomly chosen TAR paper with a randomly chosen ASR paper at
http://www.asanet.org/journals/asr/index.cfm#articles
Hi Roger,
Although I agree with you regarding how the AAA journals do not have a means of
publishing "short research articles quickly," Accounting Horizons
(certainly not TAR) for publishing now has a Commentaries section. I don't know
if the time between submission and publication of an AH Commentary is faster on
average than mainline AH research articles, but my priors are that it is quicker
to get AH Commentaries published on a more timely basis.
The disappointing aspect of the published AH Commentaries to date is that they
do not directly focus on controversies of published research articles. Nor are
they a vehicle for publishing abstracts of attempted replications of published
accounting research. I don't know if this is AH policy or just the lack of
replication in accountics science. In real science journals there are generally
alternatives for publishing abstracts of replication outcomes and commentaries
on published science articles. The AH Commentaries do tend to provide literature
reviews on narrow topics.
The American Sociological Association has a journal called Footnotes ---
http://www.asanet.org/journals/footnotes.cfm
Article Submissions are limited to
1,100 words and must have journalistic value (e.g., timeliness, significant
impact, general interest) rather than be research-oriented or scholarly in
nature. Submissions are reviewed by the editorial board for possible
publication.
ASA Forum (including letters to
the editor) - 400-600-word limit.
Obituaries - 700-word limit.
Announcements - 150-word limit.
All submissions should include a contact name and
an email address. ASA reserves the right to edit for style and length all
material published.
Deadline for all materials is the
first of the month preceding publication (e.g., February 1 for March issue).
Send communications on materials, subscriptions,
and advertising to:
American Sociological Association
1430 K Street, NW - Suite 600
Washington, DC 20005-4701
The American Accounting Association Journals do not have something
comparable to Footnotes or the ASA Forum, although the AAA does
have both the AAA Commons and the AECM where non-refereed "publishing" is common
for gadflies like Bob Jensen. The Commons is still restricted to AAA members and
as such does not get covered by search crawlers like Google. The AECM is
unrestricted to AAA Members, but since it requires free subscribing it does not
get crawled over by Google, Yahoo, Bing, etc.
Richard Feynman Creates a Simple Method for Telling Science From Pseudoscience
(1966) ---
http://www.openculture.com/2016/04/richard-feynman-creates-a-simple-method-for-telling-science-from-pseudoscience-1966.html
By Feynman's standard standard accountics science is pseudoscience
The Refereeing Process in Economics Journals ---
https://davegiles.blogspot.com/2018/10/the-refereeing-process-in-economics.html
Thank you Tom Dyckman for the heads up
Jensen Comment
Readers might note the Dan Stone's "10 reasons why peer review, as is often
constructed, frequently fails to improve manuscripts, and often diminishes their
contribution," ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm#Referees
Scroll down to "Dan Stone."
This led to the then Editor (Steve Kacheimeir) of The Accounting Review
(TAR) to present counterpoints on each of Dan
Stone's "10 reasons" quoted in the above link.
Steve goes on to blame the (then) 574 referees of TAR for the virtual lack of
commentaries in TAR, particularly commentaries on recently published papers in
TAR. Steve's contention is that as TAR Editor he does not block commentaries
from being published.
However, I think Steve is wrong on two grounds. The policy of a number of
editors that preceded Steve was to not publish
commentaries or replication studies. This led to the virtual absence of
submissions of commentaries under Steve's editorship, and if there were any
submissions of commentaries his remarks lead me to believe that they were all
rejected by the referees.
The same can be said for replication studies. Publishing of a replication
study or even mention of it is a very rare event in TAR. Replications that are
mentioned in new research submissions are usually years and years overdue.
David Giles: October 2018 Update on the A Shout-Out for The
Replication Network (in economics)
https://davegiles.blogspot.com/2018/10/a-shout-out-for-replication-network.html
Accountics Scientists Seeking Truth:
"Frankly, Scarlett, after I get a hit for my resume in The Accounting Review
I just don't give a damn"
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
One more mission in what's left of my life will be to try to change this
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
Introduction to Replication Commentaries
In this message I will define a research "replication" as an
experiment that exactly and independently reproduces hypothesis testing of an
original scientific experiment. The replication must be done by "independent"
researchers using the same hypotheses and models that test those hypotheses such
as multivariate statistical models. Researchers must be sufficiently independent
such that the replication is not performed by the same scientists or
students/colleagues of those scientists. Experimental data sets may be identical
in original studies and replications, although if replications generate
different data sets the replications also test for errors in data collection and
recording. When identical data sets are used, replicators are mainly checking
analysis errors apart from data errors.
Presumably a successful replication "reproduces" exactly the same outcomes
and authenticates/verifies the original research. In scientific research, such
authentication is considered extremely important. The IAPUC Gold Book
makes a distinction between reproducibility and repeatability at
http://goldbook.iupac.org/
For purposes of this message, replication, reproducibility, and repeatability
will be viewed as synonyms.
It would be neat if replication clearly marked the difference between the
real sciences versus the pseudo sciences, but this demarcation is not so clear
cut since pseudo scientists sometimes (not as often) replicate research
findings. A more clear cut demarcation is the obsession with finding causes that
cannot be discovered in models from big data like census databases, financial
statement databases (e.g. Compustat and EDGAR), and economic
statistics generated by governments and the United Nations. Real scientists
slave away to go beyond discovered big data correlations in search of causality
---
http://www.cs.trinity.edu/~rjensen/temp/AccounticsGranulationCurrentDraft.pdf
Why Economics is Having a Replication Crisis ---
https://www.bloomberg.com/view/articles/2018-09-17/economics-gets-it-wrong-because-research-is-hard-to-replicate
Replication and Validity Testing: How are things going in political
science? ---
https://replicationnetwork.com/2018/09/12/and-how-are-things-going-in-political-science/
Replication and Validity Testing: How are things going in
psychology? ---
https://replicationnetwork.com/2018/09/14/in-the-news-the-chronicle-of-higher-education-september-11-2018/
Replication and Validity Testing: How are things going in
accountancy?
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
Philosophy of Science Meets the Statistics Wars ---
https://replicationnetwork.com/2018/09/10/philosophy-of-science-meets-the-statistics-wars/
Significant Effects From Low-Powered Studies Will Be Overestimates ---
https://replicationnetwork.com/2018/09/08/significant-effects-from-low-powered-studies-will-be-overestimates/
80% Power? Really?
https://replicationnetwork.com/2018/09/01/80-power-really/
Responsible Research Results: What can universities do?
https://replicationnetwork.com/2018/09/07/what-can-universities-do/
Are the foot soldiers behind psychology’s replication crisis (reform)
saving science — or destroying it? ---
https://www.chronicle.com/article/I-Want-to-Burn-Things-to/244488?cid=at&utm_source=at&utm_medium=en&elqTrackId=927c155b3f3a433faf1edb36c7554be8&elq=16868c5647c6471fadb18cae5ca9e795&elqaid=20470&elqat=1&elqCampaignId=9626
. . .
As you’ve no doubt
heard by now, social psychology has had a rough few years. The trouble
concerns the replicability crisis, a somewhat antiseptic phrase that refers
to the growing realization that often the papers published in peer-reviewed
journals — papers with authoritative abstracts and nifty-looking charts —
can’t be reproduced. In other words, they don’t work when scientists try
them again. If you wanted to pin down the moment when the replication crisis
really began, you might decide it was in 2010, when Daryl Bem, a Cornell
psychologist, published a paper in
The Journal of Personality and Social
Psychology
that purported to prove that subjects could predict the future. Or maybe it
was in 2012, when researchers
failed to replicate
a much-heralded 1996 study by John Bargh, a Yale psychologist, that claimed
to show that reading about old people made subjects walk more slowly.
And it’s only gotten
worse. Some of the field’s most exciting and seemingly rock-solid findings
now appear sketchy at best. Entire subfields are viewed with suspicion. It’s
likely that many, perhaps most, of the studies published in the past couple
of decades are flawed. Just last month the Center for Open Science reported
that, of 21 social-behavioral-science studies published in Science
and Nature between 2010 and 2015, researchers could successfully
replicate only 13 of them. Again, that’s Science and Nature,
two of the most prestigious scientific journals around.
If you’re a human
interested in reliable information about human behavior, that news is
probably distressing. If you’re a psychologist who has built a career on
what may turn out to be a mirage, it’s genuinely terrifying. The replication
crisis often gets discussed in technical terms: p-values, sample sizes, and
so on. But for those who have devoted their lives to psychology, the
consequences are not theoretical, and the feelings run deep. In 2016, Susan
Fiske, a Princeton psychologist, used the phrase "methodological terrorism"
to describe those who dissect questionable research online, bypassing the
traditional channels of academic discourse (one researcher at SIPS, who
asked not to be identified, wore a T-shirt to the conference emblazoned with
the words "This Is What a Methodological Terrorist Looks Like"). Fiske wrote
that "unmoderated attacks" were leading psychologists to abandon the field
and discouraging students from pursuing it in the first place.
Psychologists like
Fiske argue that these data-crunching critics, like many of the attendees at
SIPS, paint far too dark a portrait of the field. Yes, there are lousy
studies that slip through the peer-review net and, sure, methods can always
be improved. Science progresses in fits and starts, with inevitable missteps
along the way. But they complain that the tactics of the reformers — or
terrorists, take your pick — can be gleefully aggressive, that they’re too
eager to, well, burn things to the ground. The handful of researchers who
make it their mission to unearth and expose examples of psychology’s
failings come in for particular scorn. As one tenured professor I spoke with
recently put it, "I think they’re human scum."
ames Heathers is a jovial, bearded Australian who loves cats. He is a
postdoc at Northeastern University with a Ph.D. in cardiac psychophysiology;
when he’s not ranting about subpar research practices on Everything
Hertz, the podcast he co-hosts, he’s hunting for connections between
emotion and heartbeat variability. He’s been working, along with his fellow
data thugs — a term Heathers coined, and one that’s usually (though not
always) employed with affection — on something called Sample Parameter
Reconstruction via Interactive Techniques, or SPRITE. Basically, SPRITE is a
computer program that can be used to see whether survey results, as reported
in a paper, appear to have been fabricated. It can do this because results
usually follow certain statistical patterns, and people who massage data
frequently fail to fake it convincingly. During a SIPS session, Heathers
explained SPRITE with typical élan: "Sometimes you push the button and it
says, ‘Here’s a forest of lunatic garbage.’ "
. . .
As Barrett sees
it, some of what the data thugs do "borders on harassment." The prime
example is that of Amy Cuddy, whose power-pose study was the basis for a TED
talk that’s been viewed more than 48 million times and led to a best-selling
book, Presence (Little, Brown & Company, 2015). The 2010 study has
failed to replicate,
and the first author, Dana Carney, a psychologist at Berkeley, no longer
believes in the effect. The power-pose study is held up as an example of
psychology at its most frivolous and unreliable. Cuddy, though, has not
renounced the research and has likened her treatment to bullying. She
recently tweeted: "People who want to destroy often do so with greater
passion and energy and time than people who want to build." Some
psychologists, including Barrett, see in the ferocity of that criticism an
element of sexism. It’s true that the data thugs tend to be, but are not
exclusively, male — though if you tick off the names of high-profile social
psychologists whose work has been put through the replication ringer, that
list has lots of men on it, too. Barrett thinks the tactics of the data
thugs aren’t creating an atmosphere for progress in the field. "It’s a hard
enough life to be a scientist," she says. "If we want our best and brightest
to be scientists, this is not the way to do it."
Richard Nisbett
agrees. Nisbett has been a major figure in psychology since the 1970s. He’s
co-director of the Culture and Cognition program at the University of
Michigan at Ann Arbor, author of books like Mindware: Tools for Smart
Thinking (Farrar, Straus, and Giroux, 2015), and a slew of influential
studies. Malcolm Gladwell called him "the most influential thinker in my
life." Nisbett has been calculating effect sizes since before most of those
in the replication movement were born.
And he’s a skeptic of
this new generation of skeptics. For starters, Nisbett doesn’t think direct
replications are efficient or sensible; instead he favors so-called
conceptual replication, which is more or less taking someone else’s
interesting result and putting your own spin on it. Too much navel-gazing,
according to Nisbett, hampers professional development. "I’m alarmed at
younger people wasting time and their careers," he says. He thinks that
Nosek’s ballyhooed finding that most psychology experiments didn’t replicate
did enormous damage to the reputation of the field, and that its leaders
were themselves guilty of methodological problems. And he’s annoyed that
it’s led to the belief that social psychology is riddled with errors. How do
they know that?, Nisbett asks, dropping in an expletive for emphasis.
Simine Vazire has
heard that argument before. Vazire, an associate professor of psychology at
the University of California at Davis, and one of the SIPS organizers,
regularly finds herself in meetings where no one shares her sense of urgency
about the replication crisis. "They think the status quo is fine, and we can
make tweaks," she says. "I’m often the only person in the room who thinks
there’s a big problem."
It’s not that the
researchers won’t acknowledge the need for improvement. Who’s against
progress? But when she pushes them on what that means, the division becomes
apparent. They push back on reforms like data transparency (sharing your
data freely with other researchers, so they can check your work) or
preregistration (saying publicly what you’re trying to discover in your
experiment before you try to discover it). That’s not the way it’s normally
been done. Psychologists tend to keep their data secret, arguing that it’s
proprietary or that revealing it would endanger subjects’ anonymity. But not
showing your work makes it easier to fudge what you found. Plus the freedom
to alter your hypothesis is what leads to so-called p-hacking, which is
shorthand for when a researcher goes searching for patterns in statistical
noise.
Continued in article
"Replication
Crisis in Psychology Research Turns Ugly and Odd," by Tom Bartlett,
Chronicle of Higher Education,
June 23, 2014
---
https://www.chronicle.com/article/Replication-Crisis-in/147301/?cid=at&utm_medium=en&utm_source=at
In a blog post published last week, Timothy D. Wilson, a professor of
psychology at the University of Virginia and the author of
The Surprising New Science of Psychological Change
"thatdeclared that "the field has become preoccupied with prevention and
error detection—negative psychology—at the expense of exploration and
discovery." The evidence that psychology is beset with false positives is
weak, according to Mr. Wilson, and he pointed instead to the danger of inept
replications that serve only to damage "the reputation of the original
researcher and the progression of science." While he called for finding
common ground, Mr. Wilson pretty firmly sided with those who fear that
psychology’s growing replication movement, which aims to challenge what some
critics see as a tsunami of suspicious science, is more destructive than
corrective.
Continued in article
The Stanford Prison Experiment lasted just six days, and it took place 47
years ago. But it has shaped our fundamental understanding of human nature. Now
many in the field are wondering: Should it have?
https://www.chronicle.com/article/How-a-Decades-Old-Experiment/244256?cid=at&utm_source=at&utm_medium=en&elqTrackId=8b283b87f55e48d281e307a3d73eb2a1&elq=16868c5647c6471fadb18cae5ca9e795&elqaid=20470&elqat=1&elqCampaignId=9626
Sometimes it takes decades for awareness of flaws in popular research studies to
come to light
Jensen Comment
In academic accountancy the editors have a policy that if the article has
equations (most often multiple regression equations) it does not need to
be replicated. Fortunately this does not matter much in the profession since
practitioners tend to ignore academic articles with equations ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
Sometimes it takes decades for awareness of flaws in popular research studies to
come to light. For example, for decades accounting empiricists based their
regression models on the Capital Asset Pricing Model (CAPM) and the Efficient
Market Hypothesis (EMH) as if the underlying bases for these without truly
examining how flaws in these foundations of capital market research. In fact,
the untested assumptions heavily destroyed robustness of the research,
robustness that went unchallenged and still often goes unchallenged. Even now as
p-tests in statistical inference testing are being challenged in science our
accounting research journal editors and referees seem oblivious to the
limitations of p-test outcomes.
For example on the AECM listserv I called attention to the following discovery
in an empirical accounting research study:
"Finally, we predict and find lower EPS forecast accuracy for U.K. firms
when reporting under the full fair value model of IFRS, in which unrealized
fair value gains and losses are included in net income."
"The
Effect of Fair Value versus Historical Cost Reporting Model on Analyst
Forecast Accuracy,"
by Lihong Liang and Edward J. Riedl,
The Accounting Review (TAR),: May 2014, Vol. 89, No. 3, pp. 1151-1177
---
http://aaajournals.org/doi/full/10.2308/accr-50687 (Not Free)
Accounting Review
readers will have to accept the above finding as truth since TAR will not
encourage or publish a replication study of that finding or even publish a
commentary about that finding. This is wrong in our Academy.
Lack of Research Validity/Replication Testing: The
Dismal Science Remains Dismal, Say Scientists ---
https://www.wired.com/story/econ-statbias-study/
Jensen Comment
The lack of replication and validity testing is even worse in academic
accounting research, but nobody cares ---
"How to Fix Psychology’s Replication Crisis," by Brian D. Earp and Jim
A.C. Everett, Chronicle of Higher Education, October 25, 2015 ---
http://chronicle.com/article/How-to-Fix-Psychology-s/233857?cid=cr&utm_source=cr&utm_medium=en&elqTrackId=5260de11ef714813a4003f5dc2eede4e&elq=fadcc1747dcb40cb836385262f29afe5&elqaid=9619&elqat=1&elqCampaignId=3428
Jensen Comment
Academic accounting research has a worse flaw --- replication in accounting
research is a rare event due largely to the fact that leading accounting
research journals will not publish reports of replication efforts and outcomes.
One thing we can say about hypothesis testing in accounting research is that the
first test constitutes TRUTH!
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
"The Flaw at the Heart of Psychological Research," the Chronicle of
Higher Education's Chronicle Review, June 26, 2016 ---
http://chronicle.com/article/The-Flaw-at-the-Heart-of/236916?cid=cr&utm_source=cr&utm_medium=en&elqTrackId=724bd7450b2a480cb14b37b02d872fcf&elq=fadcc1747dcb40cb836385262f29afe5&elqaid=9619&elqat=1&elqCampaignId=3428
Jensen Comment
Academic accounting research has this same flaw plus a boatload of other flaws.
What went wrong?
http://faculty.trinity.edu/rjensen/theory01.htm#WhatWentWrong
This should set accountics scientists
rethinking about their failures to replicate each other's research
"New Evidence on Linear Regression and Treatment Effect Heterogeneity." by Tymon
Słoczyński, iza, November 2015 ---
http://ftp.iza.org/dp9491.pdf
Jensen Comment
Accountics scientists seldom replicate the works of each other ---
http://faculty.trinity.edu/rjensen/theoryTar.htm
The Tymon Słoczyński's replications of two
studies published in the American Economic Review should make accountics
scientists rethink their implicit "policy" of not replicating.
It is standard practice in applied work to rely on
linear least squares regression to estimate the effect of a binary variable
(“treatment”) on some outcome of interest. In this paper I study the
interpretation of the regression estimand when treatment effects are in fact
heterogeneous. I show that the coefficient on treatment is identical to the
outcome of the following three-step procedure: first, calculate the linear
projection of treatment on the vector of other covariates (“propensity
score”); second, calculate average partial effects for both groups of
interest (“treated” and “controls”) from a regression of outcome on
treatment, the propensity score, and their interaction; third, calculate a
weighted average of these two effects, with weights being inversely related
to the unconditional probability that a unit belongs to a given group. Each
of these steps is potentially problematic, but this last property – the
reliance on implicit weights which are inversely related to the proportion
of each group – can have particularly severe consequences for applied work.
To illustrate the importance of this result, I perform Monte Carlo
simulations as well as replicate two applied
papers: Berger, Easterly, Nunn and Satyanath (2013) on the effects of
successful CIA interventions during the Cold War on imports from the US; and
Martinez-Bravo (2014) on the effects of appointed officials on village-level
electoral results in Indonesia. In both cases some of the
conclusions change dramatically after allowing for heterogeneity in effect.
Common Accountics Science and Econometric Science Statistical Mistakes ---
http://www.cs.trinity.edu/~rjensen/temp/AccounticsScienceStatisticalMistakes.htm
How Accountics Scientists Should Change:
"Frankly, Scarlett, after I get a hit for my resume in The Accounting Review
I just don't give a damn"
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
One more mission in what's left of my life will be to try to change this
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
Real Science versus Pseudo Science ---
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm#Pseudo-Science
Having said this scientists, especially real scientists, are obsessed with
replication
Presumably a successful replication "reproduces" exactly the same outcomes
and authenticates/verifies the original research. In scientific research, such
authentication is considered extremely important. The IAPUC Gold Book
makes a distinction between reproducibility and repeatability at
http://goldbook.iupac.org/
For purposes of this message, replication, reproducibility, and repeatability
will be viewed as synonyms.
Allowance should be made for "conceptual replications" apart from "exact
replications ---
http://www.jasnh.com/pdf/Vol6-No2.pdf
Scientific Replication Woes of Psychology
Accountics scientists in accountancy avoid such woes by rarely even trying to
replicate behavioral experiements
"The Results of the Reproducibility Project Are In. They’re Not Good,"
by Tom Bartlett, Chronicle of Higher Education, August 28, 2015 ---
http://chronicle.com/article/The-Results-of-the/232695/?cid=at
A decade ago, John P.A. Ioannidis published a
provocative and much-discussed paper arguing that
most published research findings are false. It’s
starting to look like he was right.
The
results
of the
Reproducibility Project are in, and the news is
not good. The goal of the project was to attempt to replicate findings in
100 studies from three leading psychology journals published in the year
2008. The very ambitious endeavor,
led by Brian Nosek, a
professor of psychology at the University of Virginia and executive director
of the
Center for Open Science, brought together more
than 270 researchers who tried to follow the same methods as the original
researchers — in essence, double-checking their work by painstakingly
re-creating it.
Turns out, only 39 percent of the studies withstood
that scrutiny.
Even Mr. Nosek, a self-described congenital
optimist, doesn’t try to put a happy spin on that number. He’s pleased that
the replicators were able to pull off the project, which began in 2011 and
involved innumerable software issues, language differences, logistical
challenges, and other assorted headaches. Now it’s done! That’s the upside.
Continued in article
574 Shields Against Validity Testing in Accounting
Research---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
"Over half of psychology studies fail
reproducibility test." "Study delivers bleak verdict on validity of psychology
experiment results." "Psychology is a discipline in crisis."
"How to Fix Psychology’s Replication Crisis," by Brian D. Earp and Jim
A.C. Everett, Chronicle of Higher Education, October 25, 2015 ---
http://chronicle.com/article/How-to-Fix-Psychology-s/233857?cid=at&utm_source=at&utm_medium=en&elq=ffdd5e32cd6c4add86ab025b68705a00&elqCampaignId=1697&elqaid=6688&elqat=1&elqTrackId=ffd568b276aa4a30804c90824e34b8d9
These and other similar headlines
followed the results of a large-scale initiative called the
Reproducibility Project, recently
published in Science magazine,
which appeared to show that a majority of findings from a
sample of 100 psychology studies did not hold up when
independent labs attempted to replicate them. (A similar
initiative is underway
in cancer biology and other
fields: Challenges with replication are
not unique to psychology.)
Headlines tend
to run a little hot. So the media’s dramatic response to the
Science paper was not entirely surprising given the
way these stories typically go. As it stands, though, it is
not at all clear what these replications mean. What the
experiments actually yielded in most cases was a different
statistical value or a smaller effect-size estimate compared
with the original studies, rather than positive evidence
against the existence of the underlying phenomenon.
This
is an important distinction. Although it would be nice if it
were otherwise, the data points we collect in psychology
don’t just hold up signs saying, "there’s an effect here" or
"there isn’t one." Instead, we have to make inferences based
on statistical estimates, and we should expect those
estimates to vary over time. In the typical scenario, an
initial estimate turns out to be on the high end (that’s why
it
ends up getting published in the
first place — it looks impressive), and then subsequent
estimates are a bit more down to earth.
. . .
To make the point a slightly different way: While
it is in everyone’s interest that high-quality, direct replications of key
studies in the field are conducted (so that we can know what degree of
confidence to place in previous findings), it is not typically in any
particular researcher’s interest to spend her time conducting such
replications.
As Huw Green, a Ph.D. student at the City
University of New York, recently put it, the "real crisis in psychology
isn’t that studies don’t replicate, but that we usually don’t even try."
What is needed is a "structural solution" —
something that has the power to resolve collective-action problems like the
one we’re describing. In simplest terms, if everyone is forced to cooperate
(by some kind of regulation), then no single individual will be at a
disadvantage compared to her peers for doing the right thing.
There are lots of ways of pulling this off — and we
don’t claim to have a perfect solution. But here is one idea.
As we proposed in a recent paper, graduate students in
psychology should be required to conduct, write up, and submit for
publication a high-quality replication attempt
of at least one key finding from the literature (ideally focusing on the
area of their doctoral research), as a condition of receiving their Ph.D.s.
Of course, editors
would need to agree to publish these kinds of submissions, and fortunately
there are a growing number — led by journals like PLoS ONE — that are
willing to do just that.
. . .
Since our
paper
was featured several weeks ago in
Nature, we’ve begun to get some constructive
feedback. As one psychologist wrote to us in an email
(paraphrased):
Your proposed
solution would only apply to some fields of psychology. It’s
not a big deal to ask students to do cheap replication
studies involving, say, pen-and-paper surveys — as is common
in social psychology. But to replicate an experiment
involving sensitive populations (babies, for instance, or
people with clinical disorders) or fancy equipment like an
fMRI machine, you would need a dedicated lab, a team of
experimenters, and several months of hard work — not to
mention the money to pay for all of this!
That much is
undoubtedly true. Expensive, time-consuming studies with
hard-to-recruit participants would not be replicated very
much if our proposal were taken up.
But that is
exactly the way things are now — so the problem would not be
made any worse. On the other hand, there are literally
thousands of studies that can be tested relatively cheaply,
at a skill level commensurate with a graduate student’s
training, which would benefit from being replicated. In
other words, having students perform replications as part of
their graduate work is very unlikely to make the problem of
not having enough replications any worse, but it has great
potential to help make it better.
Beyond
this, there is a pedagogical benefit. As Michael C. Frank
and Rebecca Saxe
have written: In their own
courses, they have found "that replicating cutting-edge
results is exciting and fun; it gives students the
opportunity to make real scientific contributions (provided
supervision is appropriate); and it provides object lessons
about the scientific process, the importance of reporting
standards, and the value of openness."
At the end of the day,
replication is indispensable.
It is a key part of the scientific enterprise; it helps us determine how
much confidence to place in published findings; and it will advance our
knowledge in the long run.
Continued in article
Jensen Comments
Accountics is the
mathematical science of values.
Charles Sprague [1887] as quoted by McMillan [1998, p. 1]
In accountics science I'm not aware of a single exacting replication of the
type discussed above of a published behavioral accounting research study.
Whether those findings constitute "truth" really does not matter much because
the practicing profession ignores accountics science behavior studies as
irrelevant and academics are only interested in the research methodologies
rather than the findings.
For example, years ago the FASB engaged Tom Dyckman and Bob Jensen to work
with the academic FASB member Bob Sprouse in evaluating research proposals to
study (with FASB funding) the post hoc impact of FAS 13 on the practicing
profession. In doing so the FASB said that both capital markets empiricism and
analytical research papers were acceptable but that the FASB had no interest in
behavioral studies. The implication was that behavioral studies were of little
interest too the FASB for various reasons, the main reason is that the tasks in
behavioral research were too artificial and removed from decision making in
real-world settings.
Interestingly both Tom and Bob had written doctoral theses that entailed
behavioral experiments in artificial settings. Tom used students as subjects,
and Bob used financial analysts doing, admittedly, artificial tasks. However,
neither Dyckman nor Jensen had much interest in subsequently conducting
behavioral experiments when they were professors. Of course in this FAS 13
engagement Dyckman and Jensen were only screening proposals submitted by other
researchers.
Accountics science research journals to my knowledge still will not publish
replications of behavioral experiments that only replicate and do not extend the
findings. Most like The Accounting Review, will not publish replications
of any kind. Accountics scientists have never
considered replication is indispensable at
the end of the day.
A Success Case for the Inability to Replicate
in Validation of Social Science Research
"The Unraveling of Michael LaCour," by Tom Bartlett, Chronicle of Higher
Education, Chronicle of Higher Education, June 2, 2015 ---
http://chronicle.com/article/The-Unraveling-of-Michael/230587/?cid=at
By his own account, Michael J. LaCour has told big
lies. He claimed to have received $793,000 in research grants. In fact, he
admits now, there were no grants.
The researchers who attempted to replicate his
widely lauded Science paper on persuasion
instead exposed a brazen fabrication, one in which Mr. LaCour appears to
have forged an email and invented a representative for a research firm.
New York magazine’s Science of Us blog noted that Mr. LaCour claimed to
have won
a nonexistent teaching award, and then caught him
trying to cover up that fiction.
As more facts emerge from one of the strangest
research scandals in recent memory, it becomes clear that this wasn’t merely
a flawed study performed by a researcher who cut a few corners. Instead it
appears to have been an elaborate, years-long con that fooled several highly
respected, senior professors and one of the nation’s most prestigious
journals.
Commenters are doling out blame online. Who, if
anyone, was supervising Mr. LaCour’s work? Considering how perfect his
results seemed, shouldn’t colleagues have been more suspicious? Is this
episode a sign of a deeper problem in the world of university research, or
is it just an example of how a determined fabricator can manipulate those
around him?
Those questions will be asked for some time to
come. Meanwhile, though, investigators at the University of California at
Los Angeles, where Mr. LaCour is a graduate student, are still figuring out
exactly what happened.
It now appears that even after Mr. LaCour was
confronted about accusations that his research was not on the level, he
scrambled to create a digital trail that would support his rapidly crumbling
narrative, according to sources connected to UCLA who asked to speak
anonymously because of the university investigation. The picture they paint
is of a young scholar who told an ever-shifting story and whose varied
explanations repeatedly failed to add up.
An Absence of Evidence
On May 17, Mr. LaCour’s dissertation adviser, Lynn
Vavreck, sent him an email asking that he meet her the next day. During that
meeting, the sources say, Ms. Vavreck told Mr. LaCour that accusations had
been made about his work and asked whether he could show her the raw data
that underpinned his (now-retracted) paper, "When Contact Changes Minds: An
Experiment on Transmission of Support for Gay Equality." The university
needed proof that the study had actually been conducted. Surely there was
some evidence: a file on his computer. An invoice from uSamp, the company
that had supposedly provided the participants. Something.
That paper, written with Donald Green, a professor
of political science at Columbia University who is well-known for pushing
the field to become more experimental, had won an award and had been
featured in
major news
outlets and in
a segment on This American Life. It was
the kind of home run graduate students dream about, and it had helped him
secure an offer to become an assistant professor at Princeton University. It
was his ticket to an academic career, and easily one of the most
talked-about political-science papers in recent years. It was a big deal.
"What Social Science Can Learn From the LaCour Scandal," by Joseph K.
Young and Nicole Janz, Chronicle of Higher Education, June 3, 2015 ---
http://chronicle.com/article/What-Social-Science-Can-Learn/230645/?cid=cr&utm_source=cr&utm_medium=en
. . .
So why don’t more researchers replicate? Because
replication isn’t sexy. Our professional incentives are to come up with
novel ideas and data, not confirm other people’s prior work. Replication is
the yeoman’s work of social science. It is time-consuming, it is
frustrating, and it does not gain any accolades for your CV. Worse, critics
of students' doing replications state that they are amateurs, or that they
may jeopardize their reputations by starting their scientific careers as
"error hunters." The LaCour scandal shows that critics could not be more
wrong. Scientific knowledge is built on the edifice of prior work. Before we
get to a stage where we need more new ideas, we need to have a better sense
of what works given the data.
Others have argued that the LaCour incident shows
the weakness of the social sciences. Some have decided to make this some
kind of steamy academic soap opera, even dubbing it LaCourGate, with daily
revelations about fake awards and fake funding. While Americans love to
shame, this episode is not about LaCour or Green or what is or was not the
cause of the errors in the study. This is about openness, transparency, and
replication.
The important lesson, however, is that replication
works. It is a verification tool that improves science and our knowledge
base. The takeaway is that we need to provide more incentives for such work.
We need a new, highly respected journal that is just about replication. More
funding sources are needed for replications. Each current journal in all of
the social sciences should establish policies that require data, tools, and
processes to be completely open-source upon publication.
The data given to Science provided the
evidence needed to identify errors in LaCour and Green. What prevents this
from occurring more often is an incentive for others to replicate. Students
can be a crucial force, and colleges should start embedding replication in
their courses more rigorously and systematically. And instructors should
encourage students to publish their work; currently most replications done
in class are an untapped resource.
In fact, LaCour and the uproar surrounding the
scandal did supporters of replication and data transparency a big favor. The
field of political science was already undergoing changes toward more
reproducibility. Top journals — but not all journals in the field — have
started to adopt strict replication policies requiring authors to provide
their materials upon publication. The American Political Science Association
released
new guidelines on data access and research
transparency.
Those new trends toward higher-quality research
were not based on a crisis in political science itself. For example, there
were hardly any retractions, accusations of fraud, plagiarism, or
large-scale irreproducibility scandals in political science before this one.
But there were scandals in psychology, economics, and cancer research that
sparked a discussion in our discipline. In fact, political science has been
feeding off crises in other fields without bleeding itself. We’ve often
wondered: If there were more scandals in political science, could a change
toward higher research quality be more rapid, and more profound? Enter
LaCour.
Joseph K. Young is an associate professor in the School of Public
Affairs and the School of International Service at American University, and
Nicole Janz is a political scientist and research-methods associate at the
University of Cambridge.
Jensen Comment
Detection of fraud with inability to replicate is quite common in the physical
sciences. It occasionally happens in the social sciences. More commonly,
however, whistle blowers are the most common source of fraud detection, often
whistle blowers that were insiders in the research process itself such as when
insiders revealed the faked data of
http://faculty.trinity.edu/rjensen/Plagiarism.htm#ProfessorsWhoPlagiarize
I know of zero instances where failure to replicate detected fraud in the
entire history of accounting research.
One reason is that exacting replication itself is a rare event in academic
accounting research ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm#Replication
Academic accountants most likely consider themselves more honest than other
academic researchers to a point where journal editors do not require replication
and in most instances like The Accounting Review will not even publish
critical commentaries about published articles ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
Whereas real scientists are a suspicious lot when it comes to published
research, accounting researchers tend to be a polite and unsuspecting lot ---
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
Large-Scale Fake Data in Academe
"The Case of the Amazing Gay-Marriage Data: How a Graduate Student
Reluctantly Uncovered a Huge Scientific Fraud," by Jesse Singal, New York
Magazine, May 2015 ---
http://nymag.com/scienceofus/2015/05/how-a-grad-student-uncovered-a-huge-fraud.html
The exposure of one of the
biggest scientific frauds in recent memory didn’t start with concerns about
normally distributed data, or the test-retest reliability of feelings
thermometers, or anonymous Stata output on shady message boards, or any of
the other statistically complex details that would make it such a bizarre
and explosive scandal. Rather, it started in the most unremarkable way
possible: with a graduate student trying to figure out a money issue.
It was September of 2013,
and David Broockman (pronounced “brock-man”), then a third-year
political-science doctoral student at UC Berkeley, was blown away by some
early results published by Michael LaCour, a political-science grad student
at UCLA. On the first of the month, LaCour had invited Broockman, who is
originally from Austin, Texas, to breakfast during the American Political
Science Association’s annual meeting in Chicago. The pair met in a café
called Freshii at the Palmer House Hilton, where the conference was taking
place, and LaCour showed Broockman some early results on an iPad.
. . .
So when LaCour and
Green’s research was eventually published in December 2014 in Science,
one of the leading peer-reviewed research publications in the world, it
resonated far and wide. “When
contact changes minds: an expression of transmission of support for gay
equality” garnered
attention in the New York Times and a
segment on "This
American Life" in which a reporter tagged along
with canvassers as they told heart-wrenching stories about being gay. It
rerouted countless researchers’ agendas, inspired activists to change their
approach to voter outreach, generated shifts in grant funding, and launched
follow-up experiments.
But back in 2013, the
now-26-year-old Broockman, a self-identifying “political science nerd,” was
so impressed by LaCour’s study that he wanted to run his own version of it
with his own canvassers and his own survey sample. First, the
budget-conscious Broockman had to figure out how much such an enterprise
might cost. He did some back-of-the-envelope calculations based on what he’d
seen on LaCour’s iPad — specifically, that the survey involved about 10,000
respondents who were paid about $100 apiece — and out popped an imposing
number: $1 million. That can’t be right, he thought to himself.
There’s no way LaCour — no way any grad student, save one who’s
independently wealthy and self-funded — could possibly run a study that cost
so much. He sent out a Request for Proposal to a bunch of polling firms,
describing the survey he wanted to run and asking how much it would cost.
Most of them said that they couldn’t pull off that sort of study at all, and
definitely not for a cost that fell within a graduate researcher’s budget.
It didn’t make sense. What was LaCour’s secret?
Eventually, Broockman’s
answer to that question would take LaCour down.
June 2, 2015 reply from Patricia Walters
I'm sure many of you received the
announcement today of this new journal. I added the emphasis (bold
& purple) to the last sentence of the description that encourages (at
least, IMHO) replications. Only time will tell whether replications and
eventual publication will occur.
Pat
|
The Financial Accounting and Reporting Section (FARS) of the AAA
is excited to announce the official opening of submissions for
its new journal:
The Journal of Financial Reporting
The Journal
of Financial Reporting (JFR)
is open to research on a broad spectrum of financial reporting
issues related to the production, dissemination, and analysis of
information produced by a firm's financial accounting and
reporting system. JFR
welcomes research that employs empirical archival, analytical,
and experimental methods, and especially
encourages
less traditional approaches such as field studies, small sample
studies, and analysis of survey data. JFR also
especially encourages "innovative" research, defined as research
that examines a novel question or develops new theory or
evidence that challenges current paradigms, or research that
reconciles, confirms, or refutes currently mixed or questionable
results.
Editors: Mary Barth, Anne Beatty, and Rick Lambert
See the complete Editorial Advisory Board and more details about
the journal's background and submission guidelines at:
|
Added Jensen Comment
I don't think the following quotation is a whole lot different from the
current policy of The Accounting Review. The supreme test is whether there
will be evidence that The Journal of Financial Reporting lives up to
its promise where The Accounting Review failed us in recent decades ---
http://aaajournals.org/userimages/ContentEditor/1433273408490/JFR_Editorial_Policy.pdf
. . .
Replications
Replications include a partial or comprehensive repeat of an experiment
that sustains as many conditions as possible but uses a different
sample. The sample employed in the replication should be at least as
“strong” as the original sample. JFR also uses the term “Replication” to
describe an archival empirical analysis that primarily performs the same
analysis as an existing study but ad ds, for example, another control
variable or additional sensitivity analysis, or uses a slightly
different sample.
Replications are expected to be short. The
Introduction should provide a limited review of the essential features
of the analysis being replicated: the re search issue addressed, the
contribution of the original article, and the key differences between
the manuscript’s analysis and the replicated study. The remainder of the
paper need only provide a limited summary of the analysis that restates
the central theory and hypotheses or research questions addressed in the
replicated study. Authors should provide more detail about the sample,
if using a new sample is the purpose of the replication, or about any
new variables. Sufficient results should be presented to support
conclusions drawn regarding the comparison of the results of the current
paper to the replicated study.
Comments on Previously Published Papers
Authors who wish to comment on previously published articles should
first communicate directly with the author(s) of the original article to
eliminate any misunderstandings or misconceptions. If substantive issues
remain after the initial exchange of views with the author(s), the
Commentator may submit the proposed Comment to the JFR . The
correspondence between the Commentator and the author (s) of the
original article should be submitted as a supplementary file. Comments
will gene rally be reviewed by two reviewers, usually including an
author of the original article to ensure that the Comment represents th
e prior article accurately and an additional reviewer who is independent
of the original article. If a Comment is accepted for publication, the
original author will generally be invited to reply.
Continued article
Accountics scientists are not accustomed to such challenges of their
research and their research findings. Time will tell if JFR can pull off
what TAR seemingly cannot pull off.
How Accountics Scientists Should Change:
"Frankly, Scarlett, after I get a hit for my resume in The Accounting
Review I just don't give a damn"
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
One more mission in what's left of my life will be to try to change this
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
"Scientists Fail to Identify Their Tools, Study Finds, and May Hurt
Replication," by Paul Voosen, Chronicle of Higher Education,
September 5, 2013 ---
http://chronicle.com/article/Scientists-Fail-to-Identify/141389/?cid=at
Define your terms. It's one of the oldest rules of
writing. Yet when it comes to defining the exact resources used to conduct
their research, many scientists fail to do exactly that. At least that's the
conclusion of a
new study,
published on Thursday in the journal PeerJ.
Looking at 238 recently published papers, pulled
from five fields of biomedicine, a team of scientists found that they could
uniquely identify only 54 percent of the research materials, from lab mice
to antibodies, used in the work. The rest disappeared into the terse fuzz
and clipped descriptions of the methods section, the journal standard that
ostensibly allows any scientist to reproduce a study.
"Our hope would be that 100 percent of materials
would be identifiable," said Nicole A. Vasilevsky, a project manager at
Oregon Health & Science University, who led the investigation.
The group quantified a finding already well known
to scientists: No one seems to know how to write a proper methods section,
especially when different journals have such varied requirements. Those
flaws, by extension, may make reproducing a study more difficult, a problem
that has prompted, most recently, the journal Nature to impose
more rigorous standards for reporting research.
"As researchers, we don't entirely know what to put
into our methods section," said Shreejoy J. Tripathy, a doctoral student in
neurobiology at Carnegie Mellon University, whose laboratory served as a
case study for the research team. "You're supposed to write down everything
you need to do. But it's not exactly clear what we need to write down."
Ms. Vasilevsky's study offers no grand solution.
Indeed, despite its rhetoric, which centers on the hot topic of
reproducibility, it provides no direct evidence that poorly labeled
materials have hindered reproduction. That finding tends to rest on
anecdote. Stories abound of dissertations diverted for years as students
struggled to find the genetic strain or antibody used in a study they were
recreating.
A Red Herring?
Here's what the study does show: In neuroscience,
in immunology, and in developmental, molecular, and general biology, catalog
codes exist to uniquely identify research materials, and they are often not
used. (The team studied five biomedical resources in all: antibody proteins,
model organisms, cell lines, DNA constructs, and gene-silencing chemicals.)
Without such specificity, it can be difficult, for example, to distinguish
multiple antibodies from the same vendor. That finding held true across the
journals, publishers, and reporting methods surveyed—including,
surprisingly, the few journals considered to have strict reporting
requirements.
This goes back to anecdote, but the interior rigor
of the lab also wasn't reflected in its published results. Ms. Vasilevsky
found that she could identify about half of the antibodies and organisms
used by the Nathan N. Urban lab at Carnegie Mellon, where Mr. Tripathy
works. The lab's interior Excel spreadsheets were meticulous, but somewhere
along the route to publication, that information disappeared.
How deep and broad a problem is this? It's
difficult to say. Ms. Vasilevsky wouldn't be surprised to see a similar
trend in other sciences. But for every graduate student reluctant to ask
professors about their methods, for fear of sounding critical, other
scientists will give them a ring straightaway. Given the shoddy state of the
methods section, such calls will remain a staple even if 100 percent of
materials are perfectly labeled, Ms. Vasilevsky added. And that's not
necessarily a problem.
Continued in article
This message does have a very long quotation from a study by Watson et al.
(2008) that does elaborate on quasi-replication and partial-replication. That
quotation also elaborates on concepts of
external versus
internal validity
grounded in the book:
Cook, T. D., & Campbell, D. T. (1979).
Quasi-experimentation: Design & analysis
issues for field settings. Boston:
Houghton Mifflin Company.
I define an "extended study" as one which may have similar hypotheses but
uses non-similar data sets and/or non-similar models. For example, study of
female in place of male test subjects is an extended study with different data
sets. An extended study may vary the variables under investigation or change the
testing model structure such as changing to a logit model as an extension of a
more traditional regression model.
Extended studies that create knew knowledge are not replications in terms of the above definitions,
although an extended study my start with an exact replication.
Replication in Accountics Science Research or Lack Thereof
Steve Kachelmeier called my attention to this article
that can be rented for $6 at
http://onlinelibrary.wiley.com/doi/10.1111/1911-3846.12102/full
Steve wants me to stress that he's not even read the above paper in its entirety
and is not (yet) taking a position on replication.
Steve did not mention that without citation the 2014 article makes some of the
same points Steve made in July 2011.
"Introduction to a Forum on Internal Control Reporting and Corporate Debt,"
by Steven J. Kachelmeier, The Accounting Review, Vol. 86, No. 4, July
2011 pp. 1129–113 (not free online) ---
http://aaapubs.aip.org/getpdf/servlet/GetPDFServlet?filetype=pdf&id=ACRVAS000086000004001129000001&idtype=cvips&prog=normal
One of the more surprising things I
have learned from my experience as Senior Editor of The Accounting Review is
just how often a ‘‘hot topic’’ generates multiple submissions that pursue
similar research objectives. Though one might view such situations as
enhancing the credibility of research findings through the independent
efforts of multiple research teams, they often result in unfavorable
reactions from reviewers who question the incremental contribution of a
subsequent study that does not materially advance the findings already
documented in a previous study, even if the two (or more) efforts were
initiated independently and pursued more or less concurrently. I understand
the reason for a high incremental contribution standard in a top-tier
journal that faces capacity constraints and deals with about 500 new
submissions per year. Nevertheless, I must admit that I sometimes feel bad
writing a rejection letter on a good study, just because some other research
team beat the authors to press with similar conclusions documented a few
months earlier. Research, it seems, operates in a highly competitive arena.
My criticisms of lack of replication in accountics research still stand:
• Replication is not a priority in accountics science like it is
in real science. Journal editors do not encourage replications even to the
extent of encouraging and publishing commentaries where scholars can mention
they replicated the studies.
• Replications that do take place, usually when newer research
extends the original studies, are long-delayed sort of like being after thoughts
when research for extensions take place, usually years later. In other words,
there's little interest in replicating until researchers elect to conduct
extension research.
• I've not encountered failed replications in accountics science.
Many examples exist in real science where original findings are thrown into
doubt because other scientists could not independently reproduce the findings.
The Hunton and Gold paper was not withdrawn because it could not be replicated.
I was not an insider to the real reasons for the withdrawal, but I suspect it
was withdrawn because insiders commenced to suspect that Jim was fabricating
data.
• Most archival replications simply use the same purchased data
(e.g., CompuStat or AuditAnalytics) without error checking the data. In reality
errors are common in these purchased databases. But if replications are made
using the same data there is no chance of detecting errors in the data.
I really miss Steve on the AECM. He always sparked interesting debates and made
great criticisms of my tidbits critical of accountics scientists.
December 18, 2014 reply from Steve Kachelmeier
Bob Jensen wrote:
Replications in Accountics Science or Lack
Thereof
Steve Kachelmeier called my attention to this
article that can be rented for $6 at
http://onlinelibrary.wiley.com/doi/10.1111/1911-3846.12102/full
Steve wants me to stress that he's not even
read the above paper in its entirety and is not (yet) taking a position
on replication.
Kachelmeier clarifies:
The full citation is as follows: Salterio, Steven
E. "We Don't Replicate Accounting Research -- Or Do We?" Contemporary
Accounting Research, Winter 2014, pp. 1134-1142.
Bob also wrote that I wanted him to stress that I'm
"not (yet) taking a position on replication." That's not what I wrote in my
email to Bob. What I wrote to Bob is that I'm not taking a position on
Salterio's article, which I have not yet read in its entirety. Based on a
brief scanning, however, Salterio does appear to provide intriguing evidence
from a search for the word "replication" (or its derivatives) in the
accounting literature that replications in accounting are more common than
we tend to believe. If that statement provokes AECM readers' interest, I
encourage you to take a look at Salterio's article and draw your own
conclusions.
Best,
Steve K.
Bob Jensen's threads on replication or lack thereof in
accountics science are at
http://www.trinity.edu/rjensen/TheoryTAR.htm
A paper can become highly cited because it is good
science – or because it is eye-catching, provocative or wrong. Luxury-journal
editors know this, so they accept papers that will make waves because they
explore sexy subjects or make challenging claims. This influences the science
that scientists do. It builds bubbles in fashionable fields where researchers
can make the bold claims these journals want, while discouraging other
important work, such as
replication studies.
"How journals like Nature, Cell and Science are damaging science:
The incentives offered by top journals distort science, just as big bonuses
distort banking," Randy Schekman, The Guardian, December 9, 2013 ---
http://www.theguardian.com/commentisfree/2013/dec/09/how-journals-nature-science-cell-damage-science
I am a scientist. Mine is a professional world that
achieves great things for humanity. But it is disfigured by inappropriate
incentives. The prevailing structures of personal reputation and career
advancement mean the biggest rewards often follow the flashiest work, not
the best. Those of us who follow these incentives are being entirely
rational – I have followed them myself – but we do not always best serve our
profession's interests, let alone those of humanity and society.
e all know what distorting incentives have done to
finance and banking. The incentives my colleagues face are not huge bonuses,
but the professional rewards that accompany publication in prestigious
journals – chiefly
Nature,
Cell and
Science.
These luxury journals are supposed to be the
epitome of quality, publishing only the best research. Because funding and
appointment panels often use place of publication as a proxy for quality of
science, appearing in these titles often leads to grants and professorships.
But the big journals' reputations are only partly warranted. While they
publish many outstanding papers, they do not publish only
outstanding papers. Neither are they the only publishers of outstanding
research.
These journals aggressively curate their brands, in
ways more conducive to selling subscriptions than to stimulating the most
important research. Like fashion designers who create limited-edition
handbags or suits, they know scarcity stokes demand, so they artificially
restrict the number of papers they accept. The exclusive brands are then
marketed with a gimmick called "impact factor" – a score for each journal,
measuring the number of times its papers are cited by subsequent research.
Better papers, the theory goes, are cited more often, so better journals
boast higher scores. Yet it is a deeply flawed measure, pursuing which has
become an end in itself – and is as damaging to science as the bonus culture
is to banking.
It is common, and encouraged by many journals, for
research to be judged by the impact factor of the journal that publishes it.
But as a journal's score is an average, it says little about the quality of
any individual piece of research. What is more, citation is sometimes, but
not always, linked to quality. A paper can become highly cited because it is
good science – or because it is eye-catching, provocative or wrong.
Luxury-journal editors know this, so they accept papers that will make waves
because they explore sexy subjects or make challenging claims. This
influences the science that scientists do. It builds bubbles in fashionable
fields where researchers can make the bold claims these journals want,
while discouraging other important work, such as
replication studies.
In extreme cases, the lure of the luxury journal
can encourage the cutting of corners, and contribute to the escalating
number of papers that are retracted as flawed or fraudulent. Science alone
has recently
retracted high-profile papers reporting cloned human embryos,
links between littering and violence, and the genetic
profiles of centenarians. Perhaps worse, it has not retracted claims that a
microbe is able to use arsenic in its DNA instead of phosphorus, despite
overwhelming scientific criticism.
There is a better way, through the new breed of
open-access journals that are free for anybody to read, and have no
expensive subscriptions to promote. Born on the web, they can accept all
papers that meet quality standards, with no artificial caps. Many are edited
by working scientists, who can assess the worth of papers without regard for
citations. As I know from my editorship of
eLife,
an open access journal funded by the Wellcome Trust, the Howard Hughes
Medical Institute and the Max Planck Society, they are publishing
world-class science every week.
Funders and universities, too, have a role to play.
They must tell the committees that decide on grants and positions not to
judge papers by where they are published. It is the quality of the science,
not the journal's brand, that matters. Most importantly of all, we
scientists need to take action. Like many successful researchers, I have
published in the big brands, including the papers that won me the Nobel
prize for medicine, which I will be honoured to collect tomorrow.. But no
longer. I have now committed my lab to avoiding luxury journals, and I
encourage others to do likewise.
Coninued in article
Bob Jensen's threads on how prestigious journals in academic accounting
research have badly damaged academic accounting research, especially in the
accountics science takeover of doctoral programs where dissertation research no
longer is accepted unless it features equations ---
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
Lack or Replication in Accountics Science:
574 Shields Against Validity Challenges in Plato's Cave ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
A validity testing testimony illustration about how research needs to be
replicated.
GM is also the company that bought the patent rights to the doomed Wankel Engine
---
http://en.wikipedia.org/wiki/Wankel_Engine
"The Sad Story of the Battery Breakthrough that Proved Too Good to Be
True," by Kevin Bullis, MIT's Technology Review, December 6, 2013 ---
http://www.technologyreview.com/view/522361/the-sad-story-of-the-battery-breakthrough-that-proved-too-good-to-be-true/?utm_campaign=newsletters&utm_source=newsletter-daily-all&utm_medium=email&utm_content=20131209
Two lurkers on the AECM listserv forwarded the link below:
"The Replication Myth: Shedding Light on One of Science’s Dirty Little
Secrets," by Jared Horvath, Scientific American, December 4, 2013
---
http://blogs.scientificamerican.com/guest-blog/2013/12/04/the-replication-myth-shedding-light-on-one-of-sciences-dirty-little-secrets/
In a series of recent articles published in The
Economist (Unreliable Research: Trouble at the Lab and Problems with
Scientific Research: How Science Goes Wrong), authors warned of a growing
trend in unreliable scientific research. These authors (and certainly many
scientists) view this pattern as a detrimental byproduct of the cutthroat
‘publish-or-perish’ world of contemporary science.
In actuality, unreliable research and
irreproducible data have been the status quo since the inception of modern
science. Far from being ruinous, this unique feature of research is integral
to the evolution of science.
At the turn of the 17th century, Galileo rolled a
brass ball down a wooden board and concluded that the acceleration he
observed confirmed his theory of the law of the motion of falling bodies.
Several years later, Marin Mersenne attempted the same experiment and failed
to achieve similar precision, causing him to suspect that Galileo fabricated
his experiment.
Early in the 19th century, after mixing oxygen with
nitrogen, John Dalton concluded that the combinatorial ratio of the elements
proved his theory of the law of multiple proportions. Over a century later,
J. R. Parington tried to replicate the test and concluded that “…it is
almost impossible to get these simple ratios in mixing nitric oxide and air
over water.”
At the beginning of the 20th century, Robert
Millikan suspended drops of oil in an electric field, concluding that
electrons have a single charge. Shortly afterwards, Felix Ehrenhaft
attempted the same experiment and not only failed to arrive at an identical
value, but also observed enough variability to support his own theory of
fractional charges.
Other scientific luminaries have similar stories,
including Mendel, Darwin and Einstein. Irreproducibility is not a novel
scientific reality. As noted by contemporary journalists William Broad and
Nicholas Wade, “If even history’s most successful scientists resort to
misrepresenting their findings in various ways, how extensive may have been
the deceits of those whose work is now rightly forgotten?”
There is a larger lesson to be gleaned from this
brief history. If replication were the gold standard of scientific progress,
we would still be banging our heads against our benches trying to arrive at
the precise values that Galileo reported. Clearly this isn’t the case.
The 1980’s saw a major upswing in the use of
nitrates to treat cardiovascular conditions. With prolonged use, however,
many patients develop a nitrate tolerance. With this in mind, a group of
drug developers at Pfizer set to creating Sildenafil, a pill that would
deliver similar therapeutic benefits as nitrates without declining efficacy.
Despite its early success, a number of unanticipated drug interactions and
side-effects—including penile erections—caused doctors to shelve Sildenafil.
Instead, the drug was re-trialed, re-packaged and re-named Viagra. The rest
is history.
This tale illustrates the true path by which
science evolves. Despite a failure to achieve initial success, the results
generated during Sildenafil experimentation were still wholly useful and
applicable to several different lines of scientific work. Had the initial
researchers been able to massage their data to a point where they were able
to publish results that were later found to be irreproducible, this would
not have changed the utility of a sub-set of their results for the field of
male potency.
Many are taught that science moves forward in
discreet, cumulative steps; that truth builds upon truth as the tapestry of
the universe slowly unfolds. Under this ideal, when scientific intentions
(hypotheses) fail to manifest, scientists must tinker until their work is
replicable everywhere at anytime. In other words, results that aren’t valid
are useless.
In reality, science progresses in subtle degrees,
half-truths and chance. An article that is 100 percent valid has never been
published. While direct replication may be a myth, there may be information
or bits of data that are useful among the noise. It is these bits of data
that allow science to evolve. In order for utility to emerge, we must be
okay with publishing imperfect and potentially fruitless data. If scientists
were to maintain the ideal, the small percentage of useful data would never
emerge; we’d all be waiting to achieve perfection before reporting our work.
This is why Galileo, Dalton and Millikan are held
aloft as scientific paragons, despite strong evidence that their results are
irreproducible. Each of these researchers presented novel methodologies,
ideas and theories that led to the generation of many useful questions,
concepts and hypotheses. Their work, if ultimately invalid, proved useful.
Doesn’t this state-of-affairs lead to dead ends,
misused time and wasted money? Absolutely. It is here where I believe the
majority of current frustration and anger resides. However, it is important
to remember two things: first, nowhere is it written that all science can
and must succeed. It is only through failure that the limits of utility can
be determined. And second, if the history of science has taught us anything,
it is that with enough time all scientific wells run dry. Whether due to the
achievement of absolute theoretical completion (a myth) or, more likely, the
evolution of more useful theories, all concepts will reach a scientific end.
Two reasons are typically given for not wanting to
openly discuss the true nature of scientific progress and the importance of
publishing data that may not be perfectly replicable: public faith and
funding. Perhaps these fears are justified. It is a possibility that public
faith will dwindle if it becomes common knowledge that scientists are
too-often incorrect and that science evolves through a morass of noise.
However, it is equally possible that public faith will decline each time
this little secret leaks out in the popular press. It is a possibility that
funding would dry up if, in our grant proposals, we openly acknowledge the
large chance of failure, if we replace gratuitous theories with simple
unknowns. However, it is equally possible that funding will diminish each
time a researcher fails to deliver on grandiose (and ultimately unjustified)
claims of efficacy and translatability.
Continued in article
Jensen Comment
I had to chuckle that in an article belittling the role of reproducibility in
science the author leads out with an illustration of how Marin Mersenne could
not reproduce one of Galileo's experiments led to suspicions that the experiment
was faked by Galileo. It seems to me that this illustration reinforces the
importance of reproducibility/replication in science.
I totally disagree that "unreliable research and irreproducible data have
been the status quo since the inception of modern science." If it really were
the "status quo" then all science would be pseudo science. Real scientists are
obsessed with replication to a point that modern science findings in experiments
are not considered new knowledge until they have been independently validated.
That of course does not mean that it's always easy or sometimes even possible to
validate findings in modern science. Much of the spending in real science is
devoted to validating earlier discoveries and databases to be shared with other
scientists.
Real scientists are generally required by top journals and funding sources to
maintain detailed lab books of steps performed in laboratories. Data collected
for use by other scientists (such as ocean temperature data) is generally
subjected to validation tests such that research outcomes are less likely to be
based upon flawed data. There are many examples of where reputations of
scientists were badly tarnished due to inability of other scientists to validate
findings ---
http://faculty.trinity.edu/rjensen/Plagiarism.htm#ProfessorsWhoPlagiarize
Nearly all real science journals have illustrations where journal articles
are later retracted because the findings could not be validated.
What the article does point out that real scientists do not always validate
findings independently. What this is saying is that real science is often
imperfect. But this does not necessarily make validation, reproduction, and
replication of original discoveries less important. It only says that the
scientists themselves often deviate from their own standards of validation.
The article does above does not change my opinion that reproducibility is the
holy grail of real science. If findings are not validated what you have is
imperfect implementation of a scientific process rather than imperfect
standards.
Accountics science is defined at
http://faculty.trinity.edu/rjensen/395wpTAR/Web/TAR395wp.htm
in short, an accountics science study is any accounting research study that
features equations and/or statistical inference.
One of the main reasons Bob Jensen contends that accountics science is not yet a
real science is that lack of exacting replications of accountics science
findings. By exacting replications he means reproducibility as defined in the
IAPUC Gold Book ---
http://en.wikipedia.org/wiki/IUPAC_Gold_Book
My study of the 2013 articles in The Accounting Review suggests that
over 90% of the articles rely upon public databases that are purchased, such as
the CompuStat, CRSP, Datastream, and AuditAnalytics. The reason I think
accountics scientists are not usually real scientists includes the following:
- High reliance on public databases without apparent concerns for data
errors, particularly in highly suspect databases like the AuditAnalytics
database that relies heavily on self-reporting within audit firms.
- Replication of accountics science discoveries is rare, and even when
replicated the same public databases are accepted without challenge in
the original studies and their replications. Replications that do rarely
take place are performed years away from the original studies and are
generally performed in studies that extend the original research.
Replication of the extensions is almost unheard of leaning me to doubt
the value of the original findings and the extensions.
- Has there ever been an accountics science exacting replication that
challenges the original study? Challenges that arise do not usually
challenge the original studies. Instead the challenges generally focus
on extended models that add new variables without questioning the
integrity of the original accountics science studies.
- Accountics science journals like The Accounting Review no
longer encourage publication of commentaries where other accountics
scientists comment favorably and critically on earlier studies. What's
the point if the public cannot engage the original authors in a
discussion of the published findings.
Audit Fees By Industry, As Presented By Audit Analytics ---
http://goingconcern.com/post/audit-fees-industry-presented-audit-analytics
Jensen Comment
In auditing courses, students might do some research on misleading aspects of
the above data apart from being self reported data. For example, some clients
save on audit fees by spending more in internal audit activities. Audit fees may
vary depending upon the quality of internal controls or lack thereof.
Audit fees may differ for two clients in the same industry where one client
is in great financial shape and the other client's employees are wearing waders.
There may also be differences between what different audit firms charge for
similar services. Aggregations of apples and oranges can be somewhat misleading.
Accountics scientists prefer purchased data such as data from Audit Analytics
so that the accountics scientists are not responsible for errors in the data. My
research of TAR suggests that accountics science research uses purchased
databases over 90% of the time. That way accountics scientists are not
responsible for collecting data or errors in that data. Audit Analytics is a
popular database purchased by accountics scientists even though it is probably
more prone to error than most of the other purchased databases. A huge problem
is reliance on self reporting by auditors and clients.
These and my other complaints about the lack of replications in accountics
science can be found at
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
The source of these oddities is Brian Dillon's
intriguing Curiosity: Art and the Pleasures of Knowing (Hayward
Publishing), a new volume of essays, excerpts, descriptions, and photographs
that accompanies his exhibit of the same name, touring Britain and the
Netherlands during 2013-14. But what does it mean to be curious?
"Triumph of the Strange," by James Delbourgo, Chronicle of Higher
Education, December 8, 2013 ---
http://chronicle.com/article/Triumph-of-the-Strange/143365/?cid=cr&utm_source=cr&utm_medium=en
Bob Jensen's threads on Real Science versus Pseudo Science ---
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
Replication Research May Take Years to Resolve
Purdue University is investigating “extremely serious” concerns about the
research of Rusi Taleyarkhan, a professor of nuclear engineering who has
published articles saying that he had produced nuclear fusion in a tabletop
experiment,
The New York Times
reported. While the research was published in Science in 2002, the findings have
faced increasing skepticism because other scientists have been unable to
replicate them. Taleyarkhan did not respond to inquiries from The Times
about the investigation.
Inside Higher Ed, March 08, 2006 ---
http://www.insidehighered.com/index.php/news/2006/03/08/qt
The New York Times March 9 report is at
http://www.nytimes.com/2006/03/08/science/08fusion.html?_r=1&oref=slogin
"Climategate's Phil Jones Confesses to Climate Fraud," by Marc
Sheppard, American Thinker, February 14, 2010 ---
http://www.americanthinker.com/2010/02/climategates_phil_jones_confes.html
Interesting Video
"The Placebo Effect," by Gwen Sharp, Sociological Images,
March 10, 2011 ---
Click Here
http://thesocietypages.org/socimages/2011/03/10/the-placebo-effect/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+SociologicalImagesSeeingIsBelieving+%28Sociological+Images%3A+Seeing+Is+Believing%29
A good example of replication in econometrics is illustrated by the inability
of obscure graduate students and an economics professor at the University
of Massachusetts to to replicate the important findings of two famous Harvard
monetary economics scientists named Carmen Reinhart and Kenneth Roghoff ---
http://en.wikipedia.org/wiki/Carmen_Reinhart#Research_and_publication
In 2013, Reinhart and Rogoff were in the spotlight
after researchers discovered that their 2010 paper "Growth in a Time of
Debt" in the American Economic Review Papers and Proceedings had a
computational error. The work argued that debt above 90% of GDP was
particularly harmful to economic growth, while corrections have shown that
the negative correlation between debt and growth does not increase above
90%. A separate and previous criticism is that the negative correlation
between debt and growth need not be causal. Rogoff and Reinhardt
claimed that their fundamental conclusions were accurate, despite the
errors.
A review by
Herndon, Ash and
Pollin of [Reinhart's] widely cited paper with
Rogoff, "Growth
in a time of debt", argued that "coding errors,
selective exclusion of available data, and unconventional weighting of
summary statistics lead to serious errors that inaccurately represent the
relationship between public debt and GDP growth among 20 advanced economies
in the post-war period."
Their error detections that received worldwide attention demonstrates that
high debt countries grew at 2.2 percent, rather than the −0.1 percent figure
claimed by Reinhart and Rogoff.
I'm critical of this replication example in one respect. Why did it take over
two years? In chemistry such an important finding would've most likely been
replicated in weeks or months rather than years.
Thus we do often have a difference between the natural sciences and the
social sciences with respect to how immediate replications transpire. In the
natural sciences it is common for journals to not even publish findings before
they've been replicated. The social sciences, also known as the softer sciences,
are frequently softer with respect to timings of replications.
DATABASE BIASES AND ERRORS
My casual studies of accountics science articles suggests that over 90% of those
studies rely exclusively on one or more public database whenever the studies use
data. I find few accountics science research into bias and errors of those
databases. Here's a short listing of research into these biases and errors, some
of which were published by accountics scientists ---
This page provides references for articles that
study specific aspects of CRSP, Compustat and other popular sources of
data used by researchers at Kellogg. If you know of any additional
references, please e-mail
researchcomputing-help@kellogg.northwestern.edu.
What went wrong with accountics science?
http://faculty.trinity.edu/rjensen/Theory01.htm#WhatWentWrong
October 21, 2013 message from Dan Stone
A recent article in "The Economist" decries the
absence of replication in
science.
short url:
http://tinyurl.com/lepu6zz
http://www.economist.com/news/leaders/21588069-scientific-research-
has-changed-world-now-it-needs-change-itself-how-science-goes-wrong
October 21, 2013 reply from Bob Jensen
I read The Economist every week and usually respect it sufficiently to
quote it a lot. But sometimes articles disappoint me as an academic in
search of evidence for controversial assertions like the one you link to
about declining replication in the sciences.
Dartmouth Professor Nyhan paints a somewhat similar picture about where
some of the leading medical journals now "tend to fail to replicate."
However other journals that he mentions are requiring a replication archives
and replication audits. It seems to me that some top science journals are
becoming more concerned about validity of research findings while perhaps
others have become more lax.
"Academic reforms: A four-part proposal," by Brendon Nyhan, April 16,
2013 ---
http://www.brendan-nyhan.com/blog/2012/04/academic-reforms-a-four-part-proposal.html
The "collaborative replication" idea has become a big deal. I have a
former psychology colleague at Trinity who has a stellar reputation for
empirical brain research in memory. She tells me that she does not submit
articles any more until they have been independently replicated by other
experts.
It may well be true that natural science journals have become negligent
in requiring replication and in providing incentives to replicate. However,
perhaps, because the social science journals have a harder time being
believed, I think that some of their top journals have become more obsessed
with replication.
In any case I don't know of any science that is less concerned with lack
of replication than accountics science. TAR has a policy of not publishing
replications or replication abstracts unless the replication is only
incidental to extending the findings with new research findings. TAR also
has a recent reputation of not encouraging commentaries on the papers it
publishes.
Has TAR even published a commentary on any paper it published in recent
years?
Have you encountered any recent investigations into errors in our most
popular public databases in accountics science?
Thanks,
Bob Jensen
November 11, 2012
Before reading Sudipta's posting of a comment to one of my earlier postings
on the AAA Commons, I would like to call your attention to the following two
links:
How Accountics Scientists Should Change:
"Frankly, Scarlett, after I get a hit for my resume in The Accounting Review
I just don't give a damn"
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
Sudipta Basu has posted a new comment in Research
Tools, on the post titled "Gaming Publications and Presentations at
Academic...".
To view the comment (and 3 other comment(s) in the
thread), or to post your own, visit:
http://commons.aaahq.org/comment/19181
posted 05:13 PM EST by
Sudipta Basu
| Comment: |
You will
probably love the new issue of Perspectives on Psychological
Science (November 2012) which is entirely devoted to (lack of)
Replication and other Research (mal)Practice issues in
psychology (behavioral research). I think there is lots of
thought-provoking material with implications for accounting
research (not only of the accountics variety). The link for the
current issue is (will change once the next issue is uploaded):
http://pps.sagepub.com/content/current
One website that provides useful
documentation on errors in standard accountics databases,
differences between databases, and their implications for
previously published research is (even as I agree that many
researchers pay little attention to these documented problems):
http://www.kellogg.northwestern.edu/rc/crsp-cstat-references.htm
I note
that several accounting researchers appear as authors in the
website above, although likely fewer than desired (possible
biases in database coverage...) |
Some Comments About Accountics Science Versus Real Science
This is the lead article in the May 2013 edition of The Accounting Review
"On Estimating Conditional Conservatism
Authors
Ray Ball (The University of Chicago)
S. P. Kothari )Massachusetts Institute of Technology)
Valeri V. Nikolaev (The University of Chicago)
The Accounting Review, Volume 88, No. 3, May 2013, pp. 755-788
The concept of conditional conservatism (asymmetric
earnings timeliness) has provided new insight into financial reporting and
stimulated considerable research since Basu (1997). Patatoukas and Thomas
(2011) report bias in firm-level cross-sectional asymmetry estimates that
they attribute to scale effects. We do not agree with their advice that
researchers should avoid conditional conservatism estimates and inferences
from research based on such estimates. Our theoretical and empirical
analyses suggest the explanation is a correlated omitted variables problem
that can be addressed in a straightforward fashion, including fixed-effects
regression. Correlation between the expected components of earnings and
returns biases estimates of how earnings incorporate the information
contained in returns. Further, the correlation varies with returns, biasing
asymmetric timeliness estimates. When firm-specific effects are taken into
account, estimates do not exhibit the bias, are statistically and
economically significant, are consistent with priors, and behave as a
predictable function of book-to-market, size, and leverage.
. . .
We build on and provide a different interpretation
of the anomalous evidence reported by PT. We begin by replicating their
[Basu (1997). Patatoukas and Thomas (2011)] results. We then provide
evidence that scale-related effects are not the explanation. We control for
scale by sorting observations into relatively narrow portfolios based on
price, such that within each portfolio approximately 99 percent of the
cross-sectional variation in scale is eliminated. If scale effects explain
the anomalous evidence, then it would disappear within these portfolios, but
the estimated asymmetric timeliness remains considerable. We conclude that
the data do not support the scale-related explanation.4 It thus becomes
necessary to look for a better explanation.
Continued in article
Jensen Comment
The good news is that the earlier findings were replicated. This is not common
in accountics science research. The bad news is that such replications took 16
years and two years respectively. And the probability that TAR will publish a
one or more commentaries on these findings is virtually zero.
How does this differ from real science?
In real science most findings are replicated before or very quickly after
publication of scientific findings. And interest is in the reproducible results
without also requiring an extension of the research for publication of the
replication outcomes.
In accountics science there is little incentive to perform exact replications
since top accountics science journals neither demand such replications nor will
they publish (even in commentaries) replication outcomes. A necessary condition
to publish replication outcomes in accountics science is the extend the research
into new frontiers.
How long will it take for somebody to replicate these May 2013 findings of
Ball, Kothari, and Nikolaev? If the past is any indicator of the future the BKN
findings will never be replicated. If they are replicated it will most likely
take years before we receive notice of such replication in an extension of the
BKN research published in 2013.
Epistemologists present several challenges to Popper's arguments
"Separating the Pseudo From Science," by Michael D. Gordon, Chronicle
of Higher Education, September 17, 2012 ---
http://chronicle.com/article/Separating-the-Pseudo-From/134412/
Bridging the Gap Between Academic Accounting Research and Audit Practice
"Highlights of audit research: Studies examine auditors' industry
specialization, auditor-client negotiations, and executive confidence regarding
earnings management,". By Cynthia E. Bolt-Lee and D. Scott Showalter,
Journal of Accountancy, August 2012 ---
http://www.journalofaccountancy.com/Issues/2012/Jul/20125104.htm
Jensen Comment
This is a nice service of the AICPA in attempting to find accountics science
articles most relevant to the practitioner world and to translate (in summary
form) these articles for a practitioner readership.
Sadly, the service does not stress that research is of only limited relevance
until it is validated in some way at a minimum by encouraging critical
commentaries and at a maximum by multiple and independent replications by
scientific standards for replications ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
Unlike real scientists, accountics scientists seldom replicate published
accountics science research by the exacting standards real science ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm#Replication
Multicollinearity ---
http://en.wikipedia.org/wiki/Multicollinearity
Robust Statistics ---
http://en.wikipedia.org/wiki/Robust_statistics
Robust statistics are statistics with good
performance for data drawn from a wide range of probability distributions,
especially for distributions that are not normally distributed. Robust
statistical methods have been developed for many common problems, such as
estimating location, scale and regression parameters. One motivation is to
produce statistical methods that are not unduly affected by outliers.
Another motivation is to provide methods with good performance when there
are small departures from parametric distributions. For example, robust
methods work well for mixtures of two normal distributions with different
standard-deviations, for example, one and three; under this model,
non-robust methods like a t-test work badly.
Continued in article
Jensen Comment
To this might be added that models that grow adaptively by adding components in
sequencing are not robust if the mere order in which components are added
changes the outcome of the ultimate model.
David Johnstone wrote the following:
Indeed if you hold H0 the same and keep changing
the model, you will eventually (generally soon) get a significant result,
allowing “rejection of H0 at 5%”, not because H0 is necessarily false but
because you have built upon a false model (of which there are zillions,
obviously).
Jensen Comment
I spent a goodly part of two think-tank years trying in vain to invent robust
adaptive regression and clustering models where I tried to adaptively reduce
modeling error by adding missing variables and covariance components. To my
great frustration I found that adaptive regression and cluster analysis seems to
almost always suffer from lack of robustness. Different outcomes can be obtained
simply because of the order in which new components are added to the model,
i.e., ordering of inputs changes the model solutions.
Accountics scientists who declare they have "significant results" may also
have non-robust results that they fail to analyze.
When you combine issues on non-robustness with the impossibility of testing
for covariance you have a real mess in accountics science and econometrics in
general.
It's relatively uncommon for accountics scientists to criticize each
others' published works. A notable exception is as follows:
"Selection Models in Accounting Research," by Clive S. Lennox, Jere R.
Francis, and Zitian Wang, The Accounting Review, March 2012, Vol.
87, No. 2, pp. 589-616.
This study explains the challenges associated with
the Heckman (1979) procedure to control for selection bias, assesses the
quality of its application in accounting research, and offers guidance for
better implementation of selection models. A survey of 75 recent accounting
articles in leading journals reveals that many researchers implement the
technique in a mechanical way with relatively little appreciation of
important econometric issues and problems surrounding its use. Using
empirical examples motivated by prior research, we illustrate that selection
models are fragile and can yield quite literally any possible outcome in
response to fairly minor changes in model specification. We conclude with
guidance on how researchers can better implement selection models that will
provide more convincing evidence on potential selection bias, including the
need to justify model specifications and careful sensitivity analyses with
respect to robustness and multicollinearity.
. . .
CONCLUSIONS
Our review of the accounting literature indicates
that some studies have implemented the selection model in a questionable
manner. Accounting researchers often impose ad hoc exclusion restrictions or
no exclusion restrictions whatsoever. Using empirical examples and a
replication of a published study, we demonstrate that such practices can
yield results that are too fragile to be considered reliable. In our
empirical examples, a researcher could obtain quite literally any outcome by
making relatively minor and apparently innocuous changes to the set of
exclusionary variables, including choosing a null set. One set of exclusion
restrictions would lead the researcher to conclude that selection bias is a
significant problem, while an alternative set involving rather minor changes
would give the opposite conclusion. Thus, claims about the existence and
direction of selection bias can be sensitive to the researcher's set of
exclusion restrictions.
Our examples also illustrate that the selection
model is vulnerable to high levels of multicollinearity, which can
exacerbate the bias that arises when a model is misspecified (Thursby 1988).
Moreover, the potential for misspecification is high in the selection model
because inferences about the existence and direction of selection bias
depend entirely on the researcher's assumptions about the appropriate
functional form and exclusion restrictions. In addition, high
multicollinearity means that the statistical insignificance of the inverse
Mills' ratio is not a reliable guide as to the absence of selection bias.
Even when the inverse Mills' ratio is statistically insignificant,
inferences from the selection model can be different from those obtained
without the inverse Mills' ratio. In this situation, the selection model
indicates that it is legitimate to omit the inverse Mills' ratio, and yet,
omitting the inverse Mills' ratio gives different inferences for the
treatment variable because multicollinearity is then much lower.
In short, researchers are faced with the following
trade-off. On the one hand, selection models can be fragile and suffer from
multicollinearity problems, which hinder their reliability. On the other
hand, the selection model potentially provides more reliable inferences by
controlling for endogeneity bias if the researcher can find good exclusion
restrictions, and if the models are found to be robust to minor
specification changes. The importance of these advantages and disadvantages
depends on the specific empirical setting, so it would be inappropriate for
us to make a general statement about when the selection model should be
used. Instead, researchers need to critically appraise the quality of their
exclusion restrictions and assess whether there are problems of fragility
and multicollinearity in their specific empirical setting that might limit
the effectiveness of selection models relative to OLS.
Another way to control for unobservable factors
that are correlated with the endogenous regressor (D) is to use panel data.
Though it may be true that many unobservable factors impact the choice of D,
as long as those unobservable characteristics remain constant during the
period of study, they can be controlled for using a fixed effects research
design. In this case, panel data tests that control for unobserved
differences between the treatment group (D = 1) and the control group (D =
0) will eliminate the potential bias caused by endogeneity as long as the
unobserved source of the endogeneity is time-invariant (e.g., Baltagi 1995;
Meyer 1995; Bertrand et al. 2004). The advantages of such a
difference-in-differences research design are well recognized by accounting
researchers (e.g., Altamuro et al. 2005; Desai et al. 2006; Hail and Leuz
2009; Hanlon et al. 2008). As a caveat, however, we note that the
time-invariance of unobservables is a strong assumption that cannot be
empirically validated. Moreover, the standard errors in such panel data
tests need to be corrected for serial correlation because otherwise there is
a danger of over-rejecting the null hypothesis that D has no effect on Y
(Bertrand et al. 2004).10
Finally, we note that there is a recent trend in
the accounting literature to use samples that are matched based on their
propensity scores (e.g., Armstrong et al. 2010; Lawrence et al. 2011). An
advantage of propensity score matching (PSM) is that there is no MILLS
variable and so the researcher is not required to find valid Z variables
(Heckman et al. 1997; Heckman and Navarro-Lozano 2004). However, such
matching has two important limitations. First, selection is assumed to occur
only on observable characteristics. That is, the error term in the first
stage model is correlated with the independent variables in the second stage
(i.e., u is correlated with X and/or Z), but there is no selection on
unobservables (i.e., u and υ are uncorrelated). In contrast, the purpose of
the selection model is to control for endogeneity that arises from
unobservables (i.e., the correlation between u and υ). Therefore, propensity
score matching should not be viewed as a replacement for the selection model
(Tucker 2010).
A second limitation arises if the treatment
variable affects the company's matching attributes. For example, suppose
that a company's choice of auditor affects its subsequent ability to raise
external capital. This would mean that companies with higher quality
auditors would grow faster. Suppose also that the company's characteristics
at the time the auditor is first chosen cannot be observed. Instead, we
match at some stacked calendar time where some companies have been using the
same auditor for 20 years and others for not very long. Then, if we matched
on company size, we would be throwing out the companies that have become
large because they have benefited from high-quality audits. Such companies
do not look like suitable “matches,” insofar as they are much larger than
the companies in the control group that have low-quality auditors. In this
situation, propensity matching could bias toward a non-result because the
treatment variable (auditor choice) affects the company's matching
attributes (e.g., its size). It is beyond the scope of this study to provide
a more thorough assessment of the advantages and disadvantages of propensity
score matching in accounting applications, so we leave this important issue
to future research.
Jensen Comment
To this we might add that it's impossible in these linear models to test for
multicollinearity.
David Johnstone posted the
following message on the AECM Listserv on November 19, 2013:
An interesting aspect of all this is that there is
a widespread a priori or learned belief in empirical research that all and only
what you have to do to get meaningful results is to get data and run statistics
packages, and that the more advanced the stats the better. Its then just a
matter of turning the handle. Admittedly it takes a lot of effort to get very
proficient at this kind of work, but the presumption that it will naturally lead
to reliable knowledge is an act of faith, like a religious tenet. What needs to
be taken into account is that the human systems (markets, accounting reporting,
asset pricing etc.) are madly complicated and likely changing structurally
continuously. So even with the best intents and best methods, there is no
guarantee of reliable or lasting findings a priori, no matter what “rigor” has
gone in.
Part and parcel of the presumption that empirical
research methods are automatically “it” is the even stronger position that no
other type of work is research. I come across this a lot. I just had a 4th
year Hons student do his thesis, he was particularly involved in the
superannuation/pension fund industry, and he did a lot of good practical stuff,
thinking about risks that different fund allocations present, actuarial life
expectancies etc. The two young guys (late 20s) grading this thesis, both
excellent thinkers and not zealots about anything, both commented to me that the
thesis was weird and was not really a thesis like they would have assumed
necessary (electronic data bases with regressions etc.). They were still
generous in their grading, and the student did well, and it was only their
obvious astonishment that there is any kind of worthy work other than the
formulaic-empirical that astonished me. This represents a real narrowing of mind
in academe, almost like a tendency to dark age, and cannot be good for us long
term. In Australia the new push is for research “impact”, which seems to include
industry relevance, so that presents a hope for a cultural widening.
I have been doing some work with a lawyer-PhD
student on valuation in law cases/principles, and this has caused similar raised
eyebrows and genuine intrigue with young colleagues – they just have never heard
of such stuff, and only read the journals/specific papers that do what they do.
I can sense their interest, and almost envy of such freedom, as they are all
worrying about how to compete and make a long term career as an academic in the
new academic world.
"Good Old R-Squared," by David Giles, Econometrics Beat: Dave
Giles’ Blog, University of Victoria, June 24, 2013 ---
http://davegiles.blogspot.com/2013/05/good-old-r-squared.html
My students are often horrified when I
tell them, truthfully, that one of the last pieces of information that I
look at when evaluating the results of an OLS regression, is the coefficient
of determination (R2), or its "adjusted" counterpart.
Fortunately, it doesn't take long to change their perspective!
After all, we all know that with
time-series data, it's really easy to get a "high" R2 value,
because of the trend components in the data. With cross-section data, really
low R2 values are really common. For most of us, the signs,
magnitudes, and significance of the estimated parameters are of primary
interest. Then we worry about testing the assumptions underlying our
analysis. R2 is at the bottom of the list of priorities.
Continued in article
Also see
http://davegiles.blogspot.com/2013/07/the-adjusted-r-squared-again.html
Bob Jensen's threads on validity testing in accountics science ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
"Can You Actually TEST for Multicollinearity?" by David Giles, Econometrics
Beat: Dave Giles’ Blog, University of Victoria, June 24, 2013 ---
http://davegiles.blogspot.com/2013/06/can-you-actually-test-for.html
. . .
Now, let's return to the "problem" of
multicollinearity.
What do we mean by this term, anyway? This turns
out to be the key question!
Multicollinearity is a phenomenon associated with
our particular sample of data when we're trying to estimate a
regression model. Essentially, it's a situation where there is
insufficient information in the sample of data to enable us to
enable us to draw "reliable" inferences about the individual parameters
of the underlying (population) model.
I'll be elaborating more on the "informational content" aspect of this
phenomenon in a follow-up post. Yes, there are various sample measures
that we can compute and report, to help us gauge how severe this data
"problem" may be. But they're not statistical tests, in any sense
of the word
Because multicollinearity is a characteristic of the sample, and
not a characteristic of the population, you should immediately be
suspicious when someone starts talking about "testing for
multicollinearity". Right?
Apparently not everyone gets it!
There's an old paper by Farrar and Glauber (1967) which, on the face of
it might seem to take a different stance. In fact, if you were around
when this paper was published (or if you've bothered to actually read it
carefully), you'll know that this paper makes two contributions. First,
it provides a very sensible discussion of what multicollinearity is all
about. Second, the authors take some well known results from the
statistics literature (notably, by Wishart, 1928; Wilks, 1932; and
Bartlett, 1950) and use them to give "tests" of the hypothesis that the
regressor matrix, X, is orthogonal.
How can this be? Well, there's a simple explanation if you read the
Farrar and Glauber paper carefully, and note what assumptions are made
when they "borrow" the old statistics results. Specifically, there's an
explicit (and necessary) assumption that in the population the X
matrix is random, and that it follows a multivariate normal
distribution.
This assumption is, of course totally at odds with what is usually
assumed in the linear regression model! The "tests" that Farrar and
Glauber gave us aren't really tests of multicollinearity in the
sample. Unfortunately, this point wasn't fully appreciated by
everyone.
There are some sound suggestions in this paper, including looking at the
sample multiple correlations between each regressor, and all of
the other regressors. These, and other sample measures such as
variance inflation factors, are useful from a diagnostic viewpoint, but
they don't constitute tests of "zero multicollinearity".
So, why am I even mentioning the Farrar and Glauber paper now?
Well, I was intrigued to come across some STATA code (Shehata, 2012)
that allows one to implement the Farrar and Glauber "tests". I'm not
sure that this is really very helpful. Indeed, this seems to me to be a
great example of applying someone's results without understanding
(bothering to read?) the assumptions on which they're based!
Be careful out there - and be highly suspicious of strangers bearing
gifts!
References
Shehata, E. A. E., 2012. FGTEST: Stata module to compute
Farrar-Glauber Multicollinearity Chi2, F, t tests.
Wilks, S. S., 1932. Certain generalizations in the analysis of
variance. Biometrika, 24, 477-494.
Wishart, J., 1928. The generalized product moment distribution
in samples from a multivariate normal population. Biometrika,
20A, 32-52.
Bob Jensen's threads on validity testing in accountics science ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
"Statistical Significance - Again " by David Giles, Econometrics
Beat: Dave Giles’ Blog, University of Victoria, December 28, 2013 ---
http://davegiles.blogspot.com/2013/12/statistical-significance-again.html
Statistical Significance - Again
With all of this emphasis
on "Big Data", I was pleased to see
this post on the Big Data
Econometrics blog, today.
When you have a sample that runs
to the thousands (billions?), the conventional significance
levels of 10%, 5%, 1% are completely inappropriate. You need to
be thinking in terms of tiny significance levels.
I discussed this in some
detail back in April of 2011, in a post titled, "Drawing
Inferences From Very Large Data-Sets".
If you're of those (many) applied
researchers who uses large cross-sections of data, and then
sprinkles the results tables with asterisks to signal
"significance" at the 5%, 10% levels, etc., then I urge
you read that earlier post.
It's sad to encounter so many
papers and seminar presentations in which the results, in
reality, are totally insignificant!
Also see
"Drawing Inferences From Very Large Data-Sets," by David Giles,
Econometrics
Beat: Dave Giles’ Blog, University of Victoria, April 26, 2013 ---
http://davegiles.blogspot.ca/2011/04/drawing-inferences-from-very-large-data.html
. . .
Granger (1998;
2003 ) has
reminded us that if the sample size is sufficiently large, then it's
virtually impossible not to reject almost any hypothesis.
So, if the sample is very large and the p-values associated with
the estimated coefficients in a regression model are of the order of, say,
0.10 or even 0.05, then this really bad news. Much,
much, smaller p-values are needed before we get all excited about
'statistically significant' results when the sample size is in the
thousands, or even bigger. So, the p-values reported above are
mostly pretty marginal, as far as significance is concerned. When you work
out the p-values for the other 6 models I mentioned, they range
from to 0.005 to 0.460. I've been generous in the models I selected.
) has
reminded us that if the sample size is sufficiently large, then it's
virtually impossible not to reject almost any hypothesis.
So, if the sample is very large and the p-values associated with
the estimated coefficients in a regression model are of the order of, say,
0.10 or even 0.05, then this really bad news. Much,
much, smaller p-values are needed before we get all excited about
'statistically significant' results when the sample size is in the
thousands, or even bigger. So, the p-values reported above are
mostly pretty marginal, as far as significance is concerned. When you work
out the p-values for the other 6 models I mentioned, they range
from to 0.005 to 0.460. I've been generous in the models I selected.
Here's another set of results taken from a second, really nice, paper by
Ciecieriski et al. (2011) in the same issue of
Health Economics:
Continued in article
Jensen Comment
My research suggest that over 90% of the recent papers published in TAR use
purchased databases that provide enormous sample sizes in those papers. Their
accountics science authors keep reporting those meaningless levels of
statistical significance.
What is even worse is when meaningless statistical significance tests are
used to support decisions.
Bob Jensen's threads on the often way analysts, particularly accountics
scientists, often cheer for statistical significance of large sample outcomes
that praise statistical significance of insignificant results such as R2
values of .0001 ---
The Cult of Statistical Significance: How Standard Error Costs Us Jobs, Justice,
and Lives ---
http://www.cs.trinity.edu/~rjensen/temp/DeirdreMcCloskey/StatisticalSignificance01.htm
"Solution to Regression Problem," by David Giles, Econometrics
Beat: Dave Giles’ Blog, University of Victoria, December 26, 2013 ---
http://davegiles.blogspot.com/2013/12/solution-to-regression-problem.html
O.K. - you've had long enough to think about that
little regression problem I
posed the other day.
It's time to put you
out of your misery!
Here's the problem again, with a solution.
Problem:
Suppose that we estimate the following regression model by OLS:
yi = α + β xi +
εi .
The model has a single regressor, x, and the point
estimate of β turns out to be 10.0.
Now consider the "reverse regression", based on
exactly the same data:
xi = a + b yi +
ui .
What can we say about the value of the OLS point
estimate of b?
- It will be 0.1.
- It will be less than or equal to 0.1.
- It will be greater than or equal to 0.1.
- It's impossible to tell from the information
supplied.
Solution:
Continued in article
David Giles' Top Five Econometrics Blog Postings for 2013 ---
Econometrics Beat: Dave Giles’ Blog, University of Victoria, December
31, 2013 ---
http://davegiles.blogspot.com/2013/12/my-top-5-for-2013.html
Everyone seems to be doing it at this time of the year.
So, here are the five most popular new posts on this blog in 2013:
-
Econometrics and "Big Data"
-
Ten Things for Applied Econometricians to Keep in Mind
-
ARDL Models - Part II - Bounds Tests
-
The Bootstrap - A Non-Technical Introduction
-
ARDL Models - Part I
Thanks for reading, and for your comments.
Happy New Year!
Jensen Comment
I really like the way David Giles thinks and writes about econometrics. He does
not pull his punches about validity testing.Bob Jensen's threads on validity
testing in accountics science ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
The
Insignificance of Testing the Null
"Statistics: reasoning on uncertainty, and
the insignificance of testing null," by Esa Läärä
Ann. Zool. Fennici 46: 138–157
ISSN 0003-455X (print), ISSN 1797-2450 (online)
Helsinki 30 April 2009 © Finnish Zoological and Botanical Publishing Board 200
http://www.sekj.org/PDF/anz46-free/anz46-138.pdf
The practice of statistical
analysis and inference in ecology is critically reviewed. The dominant doctrine
of null hypothesis signi fi cance testing (NHST) continues to be applied
ritualistically and mindlessly. This dogma is based on superficial understanding
of elementary notions of frequentist statistics in the 1930s, and is widely
disseminated by influential textbooks targeted at biologists. It is
characterized by silly null hypotheses and mechanical dichotomous division of
results being “signi fi cant” ( P < 0.05) or not. Simple examples are given to
demonstrate how distant the prevalent NHST malpractice is from the current
mainstream practice of professional statisticians. Masses of trivial and
meaningless “results” are being reported, which are not providing adequate
quantitative information of scientific interest. The NHST dogma also retards
progress in the understanding of ecological systems and the effects of
management programmes, which may at worst contribute to damaging decisions in
conservation biology. In the beginning of this millennium, critical discussion
and debate on the problems and shortcomings of NHST has intensified in
ecological journals. Alternative approaches, like basic point and interval
estimation of effect sizes, likelihood-based and information theoretic methods,
and the Bayesian inferential paradigm, have started to receive attention. Much
is still to be done in efforts to improve statistical thinking and reasoning of
ecologists and in training them to utilize appropriately the expanded
statistical toolbox. Ecologists should finally abandon the false doctrines and
textbooks of their previous statistical gurus. Instead they should more
carefully learn what leading statisticians write and say, collaborate with
statisticians in teaching, research, and editorial work in journals.
Jensen Comment
And to think Alpha (Type 1) error is the easy part. Does anybody ever test for
the more important Beta (Type 2) error? I think some engineers test for Type 2
error with Operating Characteristic (OC) curves, but these are generally applied
where controlled experiments are super controlled such as in quality control
testing.
Beta Error ---
http://en.wikipedia.org/wiki/Beta_error#Type_II_error
The Cult of
Statistical Significance
The Cult of Statistical Significance:
How Standard Error Costs Us Jobs, Justice, and Lives, by Stephen T.
Ziliak and Deirdre N. McCloskey (Ann Arbor: University of Michigan Press,
ISBN-13: 978-472-05007-9, 2007)
http://www.cs.trinity.edu/~rjensen/temp/DeirdreMcCloskey/StatisticalSignificance01.htm
Page 206
Like scientists today in medical and economic and
other sizeless sciences, Pearson mistook a large sample size for the definite,
substantive significance---evidence s Hayek put it, of "wholes." But it was as
Hayek said "just an illusion." Pearson's columns of sparkling asterisks, though
quantitative in appearance and as appealing a is the simple truth of the sky,
signified nothing.
pp. 250-251
The textbooks are wrong. The teaching is wrong. The
seminar you just attended is wrong. The most prestigious journal in your
scientific field is wrong.
You are searching, we know,
for ways to avoid being wrong. Science, as Jeffreys said, is mainly a series of
approximations to discovering the sources of error. Science is a systematic way
of reducing wrongs or can be. Perhaps you feel frustrated by the random
epistemology of the mainstream and don't know what to do. Perhaps you've been
sedated by significance and lulled into silence. Perhaps you sense that the
power of a Roghamsted test against a plausible Dublin alternative is
statistically speaking low but you feel oppressed by the instrumental variable
one should dare not to wield. Perhaps you feel frazzled by what Morris Altman
(2004) called the "social psychology rhetoric of fear," the deeply embedded path
dependency that keeps the abuse of significance in circulation. You want to come
out of it. But perhaps you are cowed by the prestige of Fisherian dogma. Or,
worse thought, perhaps you are cynically willing to be corrupted if it will keep
a nice job
Thank you Jagdish for adding another doubt in to the validity of more than
four decades of accountics science worship.
"Weak statistical standards implicated in scientific irreproducibility:
One-quarter of studies that meet commonly used statistical cutoff may be false."
by Erika Check Hayden, Nature, November 11, 2013 ---
http://www.nature.com/news/weak-statistical-standards-implicated-in-scientific-irreproducibility-1.14131
The
plague of non-reproducibility in science may be
mostly due to scientists’ use of weak statistical tests, as shown by an
innovative method developed by statistician Valen Johnson, at Texas A&M
University in College Station.
Johnson compared the strength of two types of
tests: frequentist tests, which measure how unlikely a finding is to occur
by chance, and Bayesian tests, which measure the likelihood that a
particular hypothesis is correct given data collected in the study. The
strength of the results given by these two types of tests had not been
compared before, because they ask slightly different types of questions.
So Johnson developed a method that makes the
results given by the tests — the P value in the frequentist paradigm,
and the Bayes factor in the Bayesian paradigm — directly comparable. Unlike
frequentist tests, which use objective calculations to reject a null
hypothesis, Bayesian tests require the tester to define an alternative
hypothesis to be tested — a subjective process. But Johnson developed a
'uniformly most powerful' Bayesian test that defines the alternative
hypothesis in a standard way, so that it “maximizes the probability that the
Bayes factor in favor of the alternate hypothesis exceeds a specified
threshold,” he writes in his paper. This threshold can be chosen so that
Bayesian tests and frequentist tests will both reject the null hypothesis
for the same test results.
Johnson then used these uniformly most powerful
tests to compare P values to Bayes factors. When he did so, he found
that a P value of 0.05 or less — commonly considered evidence in
support of a hypothesis in fields such as social science, in which
non-reproducibility has become a serious issue —
corresponds to Bayes factors of between 3 and 5, which are considered weak
evidence to support a finding.
False positives
Indeed, as many as 17–25% of such findings are
probably false, Johnson calculates1.
He advocates for scientists to use more stringent P values of 0.005
or less to support their findings, and thinks that the use of the 0.05
standard might account for most of the problem of non-reproducibility in
science — even more than other issues, such as biases and scientific
misconduct.
“Very few studies that fail to replicate are based
on P values of 0.005 or smaller,” Johnson says.
Some other mathematicians said that though there
have been many calls for researchers to use more stringent tests2,
the new paper makes an important contribution by laying bare exactly how lax
the 0.05 standard is.
“It shows once more that standards of evidence that
are in common use throughout the empirical sciences are dangerously
lenient,” says mathematical psychologist Eric-Jan Wagenmakers of the
University of Amsterdam. “Previous arguments centered on ‘P-hacking’,
that is, abusing standard statistical procedures to obtain the desired
results. The Johnson paper shows that there is something wrong with the P
value itself.”
Other researchers, though, said it would be
difficult to change the mindset of scientists who have become wedded to the
0.05 cutoff. One implication of the work, for instance, is that studies will
have to include more subjects to reach these more stringent cutoffs, which
will require more time and money.
“The family of Bayesian methods has been well
developed over many decades now, but somehow we are stuck to using
frequentist approaches,” says physician John Ioannidis of Stanford
University in California, who studies the causes of non-reproducibility. “I
hope this paper has better luck in changing the world.”
574 Shields Against Validity Challenges in Plato's Cave
An Appeal for Replication and Commentaries in Accountics Science
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
April 11, 2012 reply by Steve Kachelmeier
Thank you for acknowledging this Bob. I've tried to offer other
examples of critical replications before, so it is refreshing to see you
identify one. I agree that the Lennox et al. (2012) article is a great
example of the type of thing for which you have long been calling, and
I was proud to have been the accepting editor on their article.
Steve Kachelmeier
April 11, 2011 reply by Bob Jensen
Hi Steve
I really do hate to be negative so often, but even in the excellent
Lennox et al. study I have one complaint to raise about the purpose of the
replication. In real science, the purpose of most replications is driven out
of interest in the conclusions (findings) more than the methods or
techniques. The main purpose of the Lennox et al. study was more one of
validating model robustness rather than the findings themselves which are
validated more or less incidentally to the main purpose.
Respectfully,
Bob Jensen
April 12, 2012 reply by Steve Kachelmeier
Fair enough Bob. But those other examples exist
also, and one immediately came to mind as I read your reply. Perhaps at some
point you really ought to take a look at Shaw and Zhang, "Is CEO Cash
Compensation Punished for Poor Firm Performance?" The Accounting Review,
May 2010. It's an example I've raised before. Perhaps there are not as many
of these as there should be, but they do exist, and in greater frequency
than you acknowledge.
Best,
Steve
April 12, 2011 reply by Bob Jensen
Firstly,
Firstly, I might note that in the past you and I have differed as to what
constitutes "replication research" in science. I stick by my definitions.---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm#Replication
In your previous reply you drew our attention to the following article:
"Is CEO Cash Compensation Punished for Poor Firm Performance?" by Kenneth W.
Shaw and May H. Zhang, The Accounting Review, May 2010 ---
http://aaajournals.org/doi/pdf/10.2308/accr.2010.85.3.1065
ABSTRACT:
Leone et al. (2006) conclude that CEO cash
compensation is more sensitive to negative stock returns than to
positive stock returns, due to Boards of Directors enforcing an ex post
settling up on CEOs. Dechow (2006) conjectures that Leone et al.’s
�2006� results might be due to the sign of stock returns misclassifying
firm performance. Using three-way performance partitions, we find no
asymmetry in CEO cash compensation for firms with low stock returns.
Further, we find that CEO cash compensation is less sensitive to poor
earnings performance than it is to better earnings performance. Thus, we
find no evidence consistent with ex post settling up for poor firm
performance, even among the very worst performing firms with strong
corporate governance. We find similar results when examining changes in
CEO bonus pay and when partitioning firm performance using
earnings-based measures. In sum, our results suggest that CEO cash
compensation is not punished for poor firm performance.
The above Shaw and Zhang study does indeed replicate an earlier study and
is critical of that earlier study. Shaw and Zhang then extend that earlier
research. As such it is a great step in the right direction since there are
so few similar replications in accountics science research.
My criticisms of TAR and accountics science, however, still are valid.
Note that it took four years before the Leone (2006) study was replicated.
In real science the replication research commences on the date studies are
published or even before. Richard Sansing provided me with his own
accountics science replication effort, but that one took seven years after
the study being replicated was published.
Secondly, replications are not even mentioned in TAR unless these
replications significantly extend or correct the original publications in
what are literally new studies being published. In real science, journals
have outlets for mentioning replication research that simply validates the
original research without having to significantly extend or correct that
research.
What TAR needs to do to encourage more replication efforts in accountics
science is to provide an outlet for commentaries on published studies,
possibly in a manner styled after the
Journal of Electroanalytical Chemistry (JEC) that publishes short
versions of replication studies.
I mention this journal because
one of its famous published studies on cold fusion in 1989 could not (at
least not yet) be replicated. The inability of any researchers
worldwide to replicate that study destroyed the stellar reputations of the
original authors
Stanley
Pons and
Martin Fleischmann.
Others who were loose with their facts:
former Harvard researcher John Darsee (faked cardiac research);
radiologist Rober Slutsky (altered data; lied); obstetrician William
McBride (changed data, ruined stellar reputation), and physicist J.
Hendrik Schon (faked breakthroughs in molecular electronics).
Discover Magazine, December 2010, Page 43
See
http://faculty.trinity.edu/rjensen/TheoryTAR.htm#TARversusJEC
In any case, I hope you will continue to provide the AECM illustrations
of replication efforts in accountics science. Maybe one day accountics
science will grow into real science and, hopefully, also become more of
interest to the outside world.
Respectfully,
Bob Jensen
Replication Paranoia: Can you imagine anything like this happening
in accountics science?
"Is Psychology About to Come Undone?" by Tom Bartlett, Chronicle of
Higher Education, April 17, 2012 ---
Click Here
http://chronicle.com/blogs/percolator/is-psychology-about-to-come-undone/29045?sid=at&utm_source=at&utm_medium=en
If you’re a psychologist, the news has to make you
a little nervous—particularly if you’re a psychologist who published an
article in 2008 in any of these three journals: Psychological Science,
the Journal of Personality and Social Psychology, or the
Journal of Experimental Psychology: Learning, Memory, and Cognition.
Because, if you did, someone is going to check your
work. A group of researchers have already begun what they’ve dubbed
the Reproducibility Project, which aims to
replicate every study from those three journals for that one year. The
project is part of Open Science Framework, a group interested in scientific
values, and its stated mission is to “estimate the reproducibility of a
sample of studies from the scientific literature.” This is a more polite way
of saying “We want to see how much of what gets published turns out to be
bunk.”
For decades, literally, there has been talk about
whether what makes it into the pages of psychology journals—or the journals
of other disciplines, for that matter—is actually, you know, true.
Researchers anxious for novel, significant, career-making findings have an
incentive to publish their successes while neglecting to mention their
failures. It’s what the psychologist Robert Rosenthal named “the file drawer
effect.” So if an experiment is run ten times but pans out only once you
trumpet the exception rather than the rule. Or perhaps a researcher is
unconsciously biasing a study somehow. Or maybe he or she is flat-out faking
results, which is not unheard of.
Diederik Stapel, we’re looking at you.
So why not check? Well, for a lot of reasons. It’s
time-consuming and doesn’t do much for your career to replicate other
researchers’ findings. Journal editors aren’t exactly jazzed about
publishing replications. And potentially undermining someone else’s research
is not a good way to make friends.
Brian Nosek
knows all that and he’s doing it anyway. Nosek, a
professor of psychology at the University of Virginia, is one of the
coordinators of the project. He’s careful not to make it sound as if he’s
attacking his own field. “The project does not aim to single out anybody,”
he says. He notes that being unable to replicate a finding is not the same
as discovering that the finding is false. It’s not always possible to match
research methods precisely, and researchers performing replications can make
mistakes, too.
But still. If it turns out that a sizable
percentage (a quarter? half?) of the results published in these three top
psychology journals can’t be replicated, it’s not going to reflect well on
the field or on the researchers whose papers didn’t pass the test. In the
long run, coming to grips with the scope of the problem is almost certainly
beneficial for everyone. In the short run, it might get ugly.
Nosek told Science that a senior colleague
warned him not to take this on “because psychology is under threat and this
could make us look bad.” In a Google discussion group, one of the
researchers involved in the project wrote that it was important to stay “on
message” and portray the effort to the news media as “protecting our
science, not tearing it down.”
The researchers point out, fairly, that it’s not
just social psychology that has to deal with this issue. Recently, a
scientist named C. Glenn Begley attempted to replicate 53 cancer studies he
deemed landmark publications. He could only replicate six. Six! Last
December
I interviewed Christopher Chabris about his paper
titled “Most Reported Genetic Associations with General Intelligence Are
Probably False Positives.” Most!
A related new endeavour called
Psych File Drawer
allows psychologists to upload their attempts to
replicate studies. So far nine studies have been uploaded and only three of
them were successes.
Both Psych File Drawer and the Reproducibility
Project were started in part because it’s hard to get a replication
published even when a study cries out for one. For instance, Daryl J. Bem’s
2011 study that seemed to prove that extra-sensory perception is real — that
subjects could, in a limited sense, predict the future —
got no shortage of attention and seemed to turn
everything we know about the world upside-down.
Yet when Stuart Ritchie, a doctoral student in
psychology at the University of Edinburgh, and two colleagues failed to
replicate his findings, they had
a heck of a time
getting the results into print (they finally did, just recently, after
months of trying). It may not be a coincidence that the journal that
published Bem’s findings, the Journal of Personality and Social
Psychology, is one of the three selected for scrutiny.
Continued in article
Jensen Comment
Scale Risk
In accountics science such a "Reproducibility Project" would be much more
problematic except in behavioral accounting research. This is because accountics
scientists generally buy rather than generate their own data (Zoe-Vonna Palmrose
is an exception). The problem with purchased data from such as CRSP data,
Compustat data, and AuditAnalytics data is that it's virtually impossible to
generate alternate data sets, and if there are hidden serious errors in the data
it can unknowingly wipe out thousands of accountics science publications all at
one --- what we might call a "scale risk."
Assumptions Risk
A second problem in accounting and finance research is that researchers tend to
rely upon the same models over and over again. And when serious flaws were
discovered in a model like CAPM it not only raised doubts about thousands of
past studies, it made accountics and finance researchers make choices about
whether or not to change their CAPM habits in the future. Accountics researchers
that generally look for an easy way out blindly continued to use CAPM in
conspiracy with journal referees and editors who silently agreed to ignore CAPM
problems and limitations of assumptions about efficiency in capital markets---
http://faculty.trinity.edu/rjensen/Theory01.htm#EMH
We might call this an "assumptions risk."
Hence I do not anticipate that there will ever be a Reproducibility Project
in accountics science. Horrors. Accountics scientists might not continue to be
the highest paid faculty on their respected campuses and accounting doctoral
programs would not know how to proceed if they had to start focusing on
accounting rather than econometrics.
Bob Jensen's threads on replication and other forms of validity checking
---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
Thomas Kuhn ---
http://en.wikipedia.org/wiki/Thomas_Kuhn
On its 50th anniversary, Thomas Kuhn’s "The
Structure of Scientific Revolutions" remains not only revolutionary but
controversial.
"Shift Happens," David Weinberger, The Chronicle Review, April 22, 2012
---
http://chronicle.com/article/Shift-Happens/131580/
April 24, 2012 reply from Jagdish Gangolly
Bob,
A more thoughtful analysis of Kuhn is at the
Stanford Encyclopedia of Philosophy. This is one of the best resources apart
from the Principia Cybernetika (
http://pespmc1.vub.ac.be/ ).
http://plato.stanford.edu/entries/thomas-kuhn/
Regards,
Jagdish
April 24, 2012
Excellent article. It omits one aspect of Kuhn's
personal life (probably because the author thought it inconsequential).
Apparently Kuhn liked to relax by riding roller coasters.In a way, that's a
neat metaphor for the impact of his work.
Thanks Bob.
Roger
Roger Collins
TRU School of Business & Economics
April 24, 2012 message from Zane Swanson
One of the unintended consequences of a paradigm shift may have meaning for
the replication discussion which has occurred on this list. Consider the
relevance of the replications when a paradigm shifts. The change permits an
examination of replications pre and post the paradigm shift of key
attributes. In accounting, one paradigm shift is arguably the change from
historical to fair value. For those looking for a replication reason of
being, it might be worthwhile to compare replication contributions before
and after the historical to fair value changes.
In other words, when the prevailing view was that “the world is flat” …
the replication “evidence” appeared to support it. But, when the paradigm
shifted to “the world is round”, the replication evidence changed also. So,
what is the value of replications and do they matter? Perhaps, the
replications have to be novel in some way to be meaningful.
Zane Swanson
www.askaref.com accounting
dictionary for mobile devices
April 25, 2012 reply from Bob Jensen
Kuhn wrote of science that "In a science, on the
other had, a paradigm is rarely an object for replication. Instead like a
judicial decision in the common law, it is an object for further
articulation and specification under new and more stringent conditions."
This is the key to Kuhn's importance in the development of law and science
for children's law. He did seek links between the two fields of knowledge
and he by this insight suggested how the fields might work together ...
Michael Edmund Donnelly, ISBN 978-0-8204-1385 ---
Click Here
http://books.google.com/books?id=rGKEN11r-9UC&pg=PA23&lpg=PA23&dq=%22Kuhn%22+AND+%22Replication%22+AND+%22Revolution%22&source=bl&ots=RDDBr9VBWt&sig=htGlcxqtX9muYqrn3D4ajnE0jF0&hl=en&sa=X&ei=F9WXT7rFGYiAgweKoLnrBg&ved=0CCoQ6AEwAg#v=onepage&q=%22Kuhn%22%20AND%20%22Replication%22%20AND%20%22Revolution%22&f=false
My question Zane is whether historical cost (HC) accounting versus fair
value (FV) accounting is truly a paradigm shift. For centuries the two
paradigms have worked in tandem for different purposes where FV is used by
the law for personal estates and non-going concerns and HC accounting has
never been a pure paradigm for any accounting in the real world. Due to
conservatism and other factors, going-concern accounting has always been a
mixed-model of historical cost modified in selected instances for fair value
as in the case of lower-of-cost-or-market (LCM) inventories.
I think Kuhn was thinking more in terms of monumental paradigm
"revolutions" like we really have not witnessed in accounting standards that
are more evolutionary than revolutionary.
My writings are at
574 Shields Against Validity Challenges in Plato's Cave ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
Respectfully,
Bob Jensen
Biography of an Experiment ---
http://www.haverford.edu/kinsc/boe/
Questions
- Apart from accountics science journals are there real science journals
that refuse to publish replications?
- What are biased upward positive effects?
- What is the "decline" effect as research on a topic progresses?
- Why is scientific endeavor sometimes a victim of its own success?
- What is “statistically significant but not clinically significant”
problem.
Jensen
note:
I think this is a serious drawback of many accountics science published
papers.
In the past when invited to be a
discussant, this is the first problem I look for in the paper assigned for
me to discuss.
This is a particular problem in capital markets events studies having very,
very large sample sizes. Statistical significance is almost always assured
when sample sizes are huge even when the clinical significance of small
differences may be completely insignificant.
An example:
"Discussion of Foreign Currency Exposure of Multinational Firms:
Accounting Measures and Market Valuation," by
Robert E. Jensen, Rutgers University at Camden, Camden, New
Jersey, May 31, 1997. Research Conference on International Accounting and
Related Issues,
"The Value of Replication," by Steven Novella, Science-Based
Medicine, June 15, 2011 ---
http://www.sciencebasedmedicine.org/index.php/the-value-of-replication/
Daryl Bem is a respected psychology researcher who
decided to try his hand at parapsychology. Last year he published a series
of studies in which he
claimed evidence for precognition — for test
subjects being influenced in their choices by future events. The studies
were published in a peer-reviewed psychology journal, the Journal of
Personality and Social Psychology. This created somewhat of a
controversy,
and was deemed by some to be a failure of peer-review.
While the study designs were clever (he simply
reversed the direction of some standard psychology experiments, putting the
influencing factor after the effect it was supposed to have), and the
studies looked fine on paper, the research raised many red flags —
particularly in Bem’s conclusions.
The episode has created the opportunity to debate
some important aspects of the scientific literature. Eric-Jan Wagenmakers
and others questioned the p-value approach to statistical analysis, arguing
that it tends to over-call a positive result.
They argue for a Bayesian analysis, and in their
re-analysis of the Bem data they found the evidence for psi to be
“weak to non-existent.” This is essentially the
same approach to the data that we support as science-based medicine, and the
Bem study is a good example of why. If the standard techniques are finding
evidence for the impossible, then it is more likely that the techniques are
flawed rather than the entire body of physical science is wrong.
Now another debate has been spawned by the same Bem
research — that involving the role and value of exact replication. There
have already been several attempts to replicate Bem’s research, with
negative results:
Galak and Nelson,
Hadlaczky, and
Circee,
for example. Others, such as psychologist Richard
Wiseman, have also replicated Bem’s research with negative results, but are
running into trouble getting their studies published — and this is the crux
of the new debate.
According to Wiseman, (as
reported by The Psychologist, and
discussed by Ben Goldacre) the Journal of
Personality and Social Psychology turned down Wiseman’s submission on the
grounds that they don’t publish replications, only “theory-advancing
research.” In other words — strict replications are not of sufficient
scientific value and interest to warrant space in their journal. Meanwhile
other journals are reluctant to publish the replication because they feel
the study should go in the journal that published the original research,
which makes sense.
This episode illustrates potential problems with
the scientific literature. We often advocate at SBM that individual studies
can never be that reliable — rather, we need to look at the pattern of
research in the entire literature. That means, however, understanding how
the scientific literature operates and how that may create spurious
artifactual patterns.
For example, I recently wrote about the so-called
“decline effect” — a tendency for effect sizes to
shrink or “decline” as research on a phenomenon progresses. In fact, this
was first observed in the psi research, as the effect is very dramatic there
— so far, all psi effects have declined to non-existence. The decline effect
is likely a result of artifacts in the literature. Journals are more
inclined to publish dramatic positive studies (“theory-advancing research”),
and are less interested in boring replications, or in initially negative
research. A journal is unlikely to put out a press release that says, “We
had this idea, and it turned out to be wrong, so never-mind.” Also, as
research techniques and questions are honed, research results are likely to
become closer to actual effect sizes, which means the effect of researcher
bias will be diminished.
If the literature itself is biased toward positive
studies, and dramatic studies, then this would further tend to exaggerate
apparent phenomena — whether it is the effectiveness of a new drug or the
existence of anomalous cognition. If journals are reluctant to publish
replications, that might “hide the decline” (to borrow an inflammatory
phrase) — meaning that perhaps there is even more of a decline effect if we
consider unpublished negative replications. In medicine this would be
critical to know — are we basing some treatments on a spurious signal in the
noise of research.
There have already been proposals to create a
registry of studies, before they are even conducted (specifically for human
research), so that the totality of evidence will be transparent and known —
not just the headline-grabbing positive studies, or the ones that meet the
desires of the researchers or those funding the research. This proposal is
primarily to deal with the issue of publication bias — the tendency not to
publish negative studies.
Wiseman now makes the same call for a registry of
trials before they even begin to avoid the bias of not publishing
replications. In fact, he has taken it upon himself to create a
registry of attempted replications of Bem’s research.
While this may be a specific fix for replications
for Bem’s psi research — the bigger issues remain. Goldacre argues that
there are systemic problems with how information filters down to
professionals and the public. Reporting is highly biased toward dramatic
positive studies, while retractions, corrections, and failed replications
are quiet voices lost in the wilderness of information.
Most readers will already understand the critical
value of replication to the process of science. Individual studies are
plagued by flaws and biases. Most preliminary studies turn out to be wrong
in the long run. We can really only arrive at a confident conclusion when a
research paradigm produces reliable results in different labs with different
researchers. Replication allows for biases and systematic errors to average
out. Only if a phenomenon is real should it reliably replicate.
Further — the excuse by journals that they don’t
have the space now seems quaint and obsolete, in the age of digital
publishing. The scientific publishing industry needs a bit of an overhaul,
to fully adapt to the possibilities of the digital age and to use this as an
opportunity to fix some endemic problems. For example, journals can publish
just abstracts of certain papers with the full articles available only
online. Journals can use the extra space made available by online publishing
(whether online only or partially in print) to make dedicated room for
negative studies and for exact replications (replications that also expand
the research are easier to publish). Databases and reviews of such studies
can also make it as easy to find and access negative studies and
replications as it is the more dramatic studies that tend to grab headlines.
Conclusion
The scientific endeavor is now a victim of its own
success, in that research is producing a tsunami of information. The modern
challenge is to sort through this information in a systematic way so that we
can find the real patterns in the evidence and reach reliable conclusions on
specific questions. The present system has not fully adapted to this volume
of information, and there remain obsolete practices that produce spurious
apparent patterns in the research. These fake patterns of evidence tend to
be biased toward the false positive — falsely concluding that there is an
effect when there really isn’t — or at least in exaggerating effects.
These artifactual problems with the literature as a
whole combine with the statistical flaws in relying on the p-value, which
tends to over-call positive results as well. This problem can be fixed by
moving to a more Bayesian approach (considering prior probability).
All of this is happening at a time when prior
probability (scientific plausibility) is being given less attention than it
should, in that highly implausible notions are being seriously entertained
in the peer-reviewed literature. Bem’s psi research is an excellent example,
but we deal with many other examples frequently at SBM, such as homeopathy
and acupuncture. Current statistical methods and publication biases are not
equipped to deal with the results of research into highly implausible
claims. The result is an excess of false-positive studies in the literature
— a residue that is then used to justify still more research into highly
implausible ideas. These ideas can never quite reach the critical mass of
evidence to be generally accepted as real, but they do generate enough noise
to confuse the public and regulators, and to create an endless treadmill of
still more research.
The bright spot is that highly implausible research
has helped to highlight some of these flaws in the literature. Now all we
have to do is fix them.
Jensen Recommendation
Read all or at least some of the 58 comments following this article
daedalus2u comments:
Sorry if this sounds harsh, it is meant to be harsh. What this episode
shows is that the journal JPSP is not a serious scientific journal. It
is fluff, it is pseudoscience and entertainment, not a journal worth
publishing in, and not a journal worth reading, not a journal that has
scientific or intellectual integrity.
“Professor Eliot Smith, the editor of JPSP
(Attitudes and Social Cognition section) told us that the journal has a
long-standing policy of not publishing simple replications. ‘This policy
is not new and is not unique to this journal,’ he said. ‘The policy
applies whether the replication is successful or unsuccessful; indeed, I
have rejected a paper reporting a successful replication of Bem’s work
[as well as the negative replication by Ritchie et al].’ Smith added
that it would be impractical to suspend the journal’s long-standing
policy precisely because of the media attention that Bem’s work had
attracted. ‘We would be flooded with such manuscripts and would not have
page space for anything else,’ he said.”
Scientific journals have an obligation to the
scientific community that sends papers to them to publish to be honest
and fair brokers of science. Arbitrarily rejecting studies that
directly bear on extremely controversial prior work they have published,
simply because it is a “replication”, is an abdication of their
responsibility to be a fair broker of science and an honest record of
the scientific literature. It conveniently lets them publish crap with
poor peer review and then never allow the crap work to be responded to.
If the editor consider it impractical to
publish any work that is a replication because they would then have no
space for anything else, then they are receiving too many manuscripts.
If the editor needs to apply a mindless triage of “no replications”,
then the editor is in over his head and is overwhelmed. The journal
should either revise the policy and replace the overwhelmed editor, or
real scientists should stop considering the journal a suitable place to
publish.
. . .
Harriet Hall comments
A close relative of the “significant but trivial”
problem is the “statistically significant but not clinically
significant” problem. Vitamin B supplements lower blood homocysteine
levels by a statistically significant amount, but they don’t decrease
the incidence of heart attacks. We must ask if a statistically
significant finding actually represents a clinical benefit for patient
outcome, if it is POEMS – patient-oriented evidence that matters.
"Alternative Treatments for ADHD Alternative Treatments for ADHD: The
Scientific Status," David Rabiner, Attention Deficit Disorder Resources,
1998 ---
http://www.addresources.org/?q=node/279
Based on his review of the existing research
literature, Dr. Arnold rated the alternative treatments presented on a 0-6
scale. It is important to understand this scale before presenting the
treatments. (Note: this is one person's opinion based on the existing data;
other experts could certainly disagree.) The scale he used is presented
below:
- 0-No supporting evidence and not worth
considering further.
- 1-Based on a reasonable idea but no data
available; treatments not yet subjected to any real scientific study.
- 2-Promising pilot data but no careful trial.
This includes treatments where very preliminary work appears promising,
but where the treatment approach is in the very early stages of
investigation.
- 3-There is supporting evidence beyond the
pilot data stage but carefully controlled studies are lacking. This
would apply to treatments where only open trials, and not double-blind
controlled trials, have been done.
Let me briefly review the difference between an
open trial and a double-blind trial because this is a very important
distinction. Say you are testing the effect of a new medication on ADHD.
In an open trial, you would just give the medication to the child, and
then collect data on whether the child improved from either parents or
teachers. The child, the child's parents, and the child's teacher would
all know that the child was trying a new medication. In a double-blind
trial, the child would receive the new medicine for a period of time and
a placebo for a period of time. None of the children, parents, or
teachers would know when medication or placebo was being received. The
same type of outcome data as above would be collected during both the
medication period and the placebo period.
The latter is considered to be a much more
rigorous test of a new treatment because it enables researchers to
determine whether any reported changes are above and beyond what can be
attributed to a placebo effect. In an open trial, you cannot be certain
that any changes reported are actually the result of the treatment, as
opposed to placebo effects alone. It is also very hard for anyone to
provide objective ratings of a child's behavior when they know that a
new treatment is being used. Therefore, open trials, even if they yield
very positive results, are considered only as preliminary evidence.
- 4-One significant double-blind, controlled
trial that requires replication. (Note: replicating a favorable
double-blind study is very important. The literature is full of
initially promising reports that could not be replicated.)
- 5-There is convincing double-blind controlled
evidence, but further refinement is needed for clinical application.
This rating would be given to treatments where replicated double-blind
trials are available, but where it is not completely clear who is best
suited for the treatment. For example, a treatment may be known to help
children with ADHD, but it may be effective for only a minority of the
ADHD population and the specific subgroup it is effective for is not
clearly defined.
- 6-A well established treatment for the
appropriate subgroup. Of the numerous alternative treatments reviewed by
Dr. Arnold, no treatments received a rating of 6.
Only one treatment reviewed received a rating of 5.
Dr. Arnold concluded that there is convincing scientific evidence that some
children who display
Continued in article
"If you can write it up and get it published you're
not even thinking of reproducibility," said Ken Kaitin, director of the Tufts
Center for the Study of Drug Development. "You make an observation and move on.
There is no incentive to find out it was wrong."
April 14, 2012 reply from Richard Sansing
Inability to replicate may be a problem in other
fields as well.
http://www.vision.org/visionmedia/article.aspx?id=54180
Richard Sansing
Bob Jensen's threads on replication in accountics science ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
"The Baloney Detection Kit: A 10-Point Checklist for Science Literacy,"
by Maria Popova, Brain Pickings, March 16, 2012 ---
Click Here
http://www.brainpickings.org/index.php/2012/03/16/baloney-detection-kit/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+brainpickings%2Frss+%28Brain+Pickings%29&utm_content=Google+Reader
Video Not Included Here
The above sentiment in particular echoes this
beautiful definition of science as
“systematic wonder” driven by an osmosis of
empirical rigor and imaginative whimsy.
The complete checklist:
- How reliable is the source of the claim?
- Does the source make similar claims?
- Have the claims been verified by
somebody else?
- Does this fit with the way the world
works?
- Has anyone tried to disprove the claim?
- Where does the preponderance of evidence
point?
- Is the claimant playing by the rules of
science?
- Is the claimant providing positive
evidence?
- Does the new theory account for as many
phenomena as the old theory?
- Are personal beliefs driving the claim?
The charming animation comes from UK studio
Pew 36.
The Richard Dawkins Foundation has a free
iTunes podcast, covering topics as diverse as
theory of mind, insurance policy, and Socrates’ “unconsidered life.”
Possibly the Worst Academic Scandal in Past 100 Years: Deception
at Duke
The Loose Ethics of Co-authorship of Research in Academe
In general we don't allow faculty to have publications ghost written for
tenure and performance evaluations. However, the rules are very loose regarding
co-author division of duties. A faculty member can do all of the research but
pass along all the writing to a co-author except when co-authoring is not
allowed such as in the writing of dissertations.
In my opinion the rules are too loose regarding co-authorship. Probably the
most common abuse in the current "publish or perish" environment in academe is
the partnering of two or more researchers to share co-authorships when their
actual participation rate in the research and writing of most the manuscripts is
very small, maybe less than 10%. The typical partnering arrangement is for an
author to take the lead on one research project while playing only a small role
in the other research projects
Gaming for Tenure as an
Accounting Professor ---
http://faculty.trinity.edu/rjensen/TheoryTenure.htm
(with a reply about tenure publication point systems from Linda Kidwell)
Another common abuse, in my opinion, is where a senior faculty member with a
stellar reputation lends his/her name to an article written and researched
almost entirely by a lesser-known colleague or graduate student. The main author
may agree to this "co-authorship" when the senior co-author's name on the paper
improves the chances for publication in a prestigious book or journal.
This is what happened in a sense in what is becoming the most notorious
academic fraud in the history of the world. At Duke University a famous
cancer researcher co-authored research that was published in the most
prestigious science and medicine journals in the world. The senior faculty
member of high repute is now apologizing to the world for being a part of a
fraud where his colleague fabricated a significant portion of the data to make
it "come out right" instead of the way it actually turned out.
What is interesting is to learn about how super-knowledgeable researchers at
the Anderson Cancer Center in Houston detected this fraud and notified the Duke
University science researchers of their questions about the data. Duke appears
to have resisted coming out with the truth way to long by science ethics
standards and even continued to promise miraculous cures to 100 Stage Four
cancer patients who underwent the miraculous "Duke University" cancer cures that
turned out to not be miraculous at all. Now Duke University is exposed to quack
medicine lawsuit filed by families of the deceased cancer patients who were
promised phone 80% cure rates.
The above Duke University scandal was the headline module in the February 12,
2012 edition of CBS Sixty Minutes. What an eye-opening show about science
research standards and frauds ---
Deception at Duke (Sixty Minutes
Video) ---
http://www.cbsnews.com/8301-18560_162-57376073/deception-at-duke/
Next comes the question of whether college administrators operate under
different publishing and speaking ethics vis-à-vis their faculty
"Faking It for the Dean," by Carl Elliott, Chronicle of Higher Education,
February 7, 2012 ---
http://chronicle.com/blogs/brainstorm/says-who/43843?sid=cr&utm_source=cr&utm_medium=en
Added Jensen Comment
I've no objection to "ghost writing" of interview remarks as long as the ghost
writer is given full credit for doing the writing itself.
I also think there is a difference between speeches versus publications with
respect to citations. How awkward it would be if every commencement speaker had
to read the reference citation for each remark in the speech. On the other hand,
I think the speaker should announce at the beginning and end that some of the
points made in the speech originated from other sources and that references will
be provided in writing upon request.
Bob Jensen's threads on professors who let students cheat ---
http://faculty.trinity.edu/rjensen/Plagiarism.htm#RebeccaHoward
Bob Jensen's threads on professors who cheat
http://faculty.trinity.edu/rjensen/Plagiarism.htm#ProfessorsWhoPlagiarize
Steven J. Kachelmeier's July 2011 Editorial as Departing Senior Editor of
The Accounting Review (TAR)
"Introduction to a Forum on Internal Control Reporting and Corporate Debt,"
by Steven J. Kachelmeier, The Accounting Review, Vol. 86, No. 4, July
2011 pp. 1129–113 (not free online) ---
http://aaapubs.aip.org/getpdf/servlet/GetPDFServlet?filetype=pdf&id=ACRVAS000086000004001129000001&idtype=cvips&prog=normal
One of the more surprising things I
have learned from my experience as Senior Editor of
The Accounting Review
is just how often a
‘‘hot
topic’’
generates multiple
submissions that pursue similar research objectives. Though one might view
such situations as enhancing the credibility of research findings through
the independent efforts of multiple research teams, they often result in
unfavorable reactions from reviewers who question the incremental
contribution of a subsequent study that does not materially advance the
findings already documented in a previous study, even if the two (or more)
efforts were initiated independently and pursued more or less concurrently.
I understand the reason for a high incremental contribution standard in a
top-tier journal that faces capacity constraints and deals with about 500
new submissions per year. Nevertheless, I must admit that I sometimes feel
bad writing a rejection letter on a good study, just because some other
research team beat the authors to press with similar conclusions documented
a few months earlier. Research, it seems, operates in a highly competitive
arena.
Fortunately, from time to time, we
receive related but still distinct submissions that, in combination, capture
synergies (and reviewer support) by viewing a broad research question from
different perspectives. The two articles comprising this issue’s forum are a
classic case in point. Though both studies reach the same basic conclusion
that material weaknesses in internal controls over financial reporting
result in negative repercussions for the cost of debt financing, Dhaliwal et
al. (2011) do so by examining the public market for corporate debt
instruments, whereas Kim et al. (2011) examine private debt contracting with
financial institutions. These different perspectives enable the two research
teams to pursue different secondary analyses, such as Dhaliwal et al.’s
examination of the sensitivity of the reported findings to bank monitoring
and Kim et al.’s examination of debt covenants.
Both studies also overlap with yet a
third recent effort in this arena, recently published in the
Journal of Accounting
Research by Costello and
Wittenberg-Moerman (2011). Although the overall
‘‘punch
line’’
is similar in all three studies (material
internal control weaknesses result in a higher cost of debt), I am intrigued
by a ‘‘mini-debate’’
of sorts on the different conclusions
reache by Costello and Wittenberg-Moerman (2011) and by Kim et al.
(2011) for the effect of material weaknesses on debt covenants.
Specifically, Costello and Wittenberg-Moerman (2011, 116) find that
‘‘serious,
fraud-related weaknesses result in a significant decrease in financial
covenants,’’
presumably because banks substitute more
direct protections in such instances, whereas Kim et al.
Published Online: July 2011
(2011) assert from their cross-sectional
design that company-level material weaknesses are associated with
more
financial covenants in
debt contracting.
In reconciling these conflicting
findings, Costello and Wittenberg-Moerman (2011, 116) attribute the Kim et
al. (2011) result to underlying
‘‘differences
in more fundamental firm characteristics, such as riskiness and information
opacity,’’
given that, cross-sectionally, material
weakness firms have a greater number of financial covenants than do
non-material weakness firms even
before the disclosure of the material
weakness in internal controls. Kim et al. (2011) counter that they control
for risk and opacity characteristics, and that advance leakage of internal
control problems could still result in a debt covenant effect due to
internal controls rather than underlying firm characteristics. Kim et al.
(2011) also report from a supplemental change analysis that, comparing the
pre- and post-SOX 404 periods, the number of debt covenants falls for
companies both with and without
material
weaknesses in internal controls, raising the question of whether the
Costello and Wittenberg-Moerman (2011)
finding reflects a reaction to the disclosures or simply a more general
trend of a declining number of debt covenants affecting all firms around
that time period. I urge readers to take a look at both articles, along with
Dhaliwal et al. (2011), and draw their own conclusions. Indeed, I believe
that these sorts . . .
Continued in article
Jensen Comment
Without admitting to it, I think Steve has been embarrassed, along with many
other accountics researchers, about the virtual absence of validation and
replication of accounting science (accountics) research studies over the past
five decades. For the most part, accountics articles are either ignored or
accepted as truth without validation. Behavioral and capital markets empirical
studies are rarely (ever?) replicated. Analytical studies make tremendous leaps
of faith in terms of underlying assumptions that are rarely challenged (such as
the assumption of equations depicting utility functions of corporations).
Accounting science thereby has become a pseudo
science where highly paid accountics professor referees are protecting each
others' butts ---
"574 Shields Against Validity Challenges in Plato's Cave" ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
The above link contains Steve's rejoinders on the replication debate.
In the above editorial he's telling us that there is a middle ground for
validation of accountics studies. When researchers independently come to similar
conclusions using different data sets and different quantitative analyses they
are in a sense validating each others' work without truly replicating each
others' work.
I agree with Steve on this, but I would also argue that these types of
"validation" is too little to late relative to genuine science where replication
and true validation are essential to the very definition of science. The types
independent but related research that Steve is discussing above is too
infrequent and haphazard to fall into the realm of validation and replication.
When's the last time you witnesses a TAR author criticizing the research of
another TAR author (TAR does not publish critical commentaries)?
Are TAR articles really all that above criticism?
Even though I admire Steve's scholarship, dedication,
and sacrifice, I hope future TAR editors will work harder at turning accountics
research into real science!
What Went Wrong With Accountics Research? ---
http://faculty.trinity.edu/rjensen/theory01.htm#WhatWentWrong
September 10, 2011 reply from Bob Jensen (known on the AECM as Calvin of
Calvin and Hobbes)
This is a reply to Steve Kachelmeier, former Senior Editor of The Accounting
Review (TAR)
I agree Steve and will not bait you further in a game of Calvin Ball.
It is, however, strange to me that exacting replication
(reproducibility) is such a necessary condition to almost all of real
science empiricism and such a small part of accountics science empiricism.
My only answer to this is that the findings themselves in science seem to
have greater importance to both the scientists interested in the findings
and the outside worlds affected by those findings.
It seems to me that empirical findings that are not replicated with as much
exactness as possible are little more than theories that have only been
tested once but we can never be sure that the tests were not faked or
contain serious undetected errors for other reasons.
It is sad that the accountics science system really is not designed to guard
against fakers and careless researchers who in a few instances probably get
great performance evaluations for their hits in TAR, JAR, and JAE. It is
doubly sad since internal controls play such an enormous role in our
profession but not in our accoutics science.
I thank you for being a noted accountics scientist who was willing to play
Calvin Ball.with me for a while. I want to stress that this is not really a
game with me. I do want to make a difference in the maturation of accountics
science into real science. Exacting replications in accountics science would
be an enormous giant step in the real-science direction.
Allowing validity-questioning commentaries in TAR would be a smaller start
in that direction but nevertheless a start. Yes I know that it was your 574
TAR referees who blocked the few commentaries that were submitted to TAR
about validity questions. But the AAA Publications Committees and you as
Senior Editor could've done more to encourage both submissions of more
commentaries and submissions of more non-accountics research papers to TAR
--- cases, field studies, history studies, AIS studies, and (horrors)
normative research.
I would also like to bust the monopoly that accountics scientists have on
accountancy doctoral programs. But I've repeated my arguments here far to
often ---
http://www.trinity.edu/rjensen/Theory01.htm#DoctoralPrograms
In any case thanks for playing Calvin Ball with me. Paul Williams and
Jagdish Gangolly played Calvin Ball with me for a while on an entirely
different issue --- capitalism versus socialism versus bastardized versions
of both that evolve in the real world.
Hopefully there's been some value added on the AECM in my games of Calvin
Ball.
Even though my Calvin Ball opponents have walked off the field, I will
continue to invite others to play against me on the AECM.
And I'm certain this will not be the end to my saying that accountics
farmers are more interested in their tractors than their harvests. This may
one day be my epitaph.
Respectfully,
Calvin
"574 Shields Against Validity Challenges in Plato's Cave" --- See Below
"Psychology’s Treacherous Trio: Confirmation Bias, Cognitive Dissonance,
and Motivated Reasoning," by sammcnerney, Why We Reason, September 7,
2011 ---
Click Here
http://whywereason.wordpress.com/2011/09/07/psychologys-treacherous-trio-confirmation-bias-cognitive-dissonance-and-motivated-reasoning/
Regression Towards the Mean ---
http://en.wikipedia.org/wiki/Regression_to_the_mean
"The Truth Wears Off Is there something wrong with the scientific method?"
by Johah Lehrer, The New Yorker, December 12, 2010 ---
http://www.newyorker.com/reporting/2010/12/13/101213fa_fact_lehrer
Jensen Comment
This article deals with instances where scientists honestly cannot replicate
earlier experiments including their own experiments.
"Milgram's obedience studies - not about obedience after all?"
Research Digest, February 2011 ---
Click Here
http://bps-research-digest.blogspot.com/2011/02/milgrams-obedience-studies-not-about.html?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+BpsResearchDigest+%28BPS+Research+Digest%29
"Success Comes From Better Data, Not Better Analysis," by Daryl Morey,
Harvard Business Review Blog, August 8, 2011 ---
Click Here
http://blogs.hbr.org/cs/2011/08/success_comes_from_better_data.html?referral=00563&cm_mmc=email-_-newsletter-_-daily_alert-_-alert_date&utm_source=newsletter_daily_alert&utm_medium=email&utm_campaign=alert_date
Jensen Comment
I think accountics researchers often use purchased databases (e.g., Compustat,
AuditAnalytics, and CRSP) without questioning the possibility of data errors and
limitation. For example, we recently took a look at the accounting litigation
database of AuditAnalytics and found many serious omissions.
These databases are used by multiple accountics researchers, thereby
compounding the felony,.
Bob Jensen's threads on what went wrong with accountics research are at
http://faculty.trinity.edu/rjensen/theory01.htm#WhatWentWrong
A Mutation in the Evolution of Accountics Science Toward Real Science:
A Commentary Published in TAR in May 2012
The publication of the Moser and Martin commentary in the May
2012 edition of TAR is a mutation of progress in accountics science evolution.
We owe a big thank you to both TAR Senior Editors Steve Kachelmeier and Harry
Evans.
Accountics is the mathematical science of values.
Charles Sprague [1887] as quoted by McMillan [1998, p. 1]
http://faculty.trinity.edu/rjensen/395wpTAR/Web/TAR395wp.htm#_msocom_1
A small step for accountics science,
A giant step for accounting
Accountics science made a giant step in its evolution toward becoming a real
science when it published a commentary in The Accounting Review (TAR) in
the May 2012 edition.
""A Broader Perspective on Corporate Social Responsibility Research in
Accounting," by Donald V. Moser and Patrick R. Martin, The Accounting
Review, Vol. 87, May 2012, pp. 797-806 ---
http://aaajournals.org/doi/full/10.2308/accr-10257
We appreciate the helpful comments of Ramji
Balakrishnan, Harry Evans, Lynn Hannan, Steve Kachelmeier, Geoff Sprinkle,
Greg Waymire, Michael Williamson, and the authors of the two Forum papers on
earlier versions of this commentary. Although we have benefited
significantly from such comments, the views expressed are our own and do not
necessarily represent the views of others who have kindly shared their
insights with us.
. . .
In this commentary we suggest that CSR research in
accounting could benefit significantly if accounting researchers were more
open to (1) the possibility that CSR activities and related disclosures are
driven by both shareholders and non-shareholder constituents, and (2) the
use of experiments to answer important CSR questions that are difficult to
answer with currently available archival data. We believe that adopting
these suggestions will help accounting researchers obtain a more complete
understanding of the motivations for corporate investments in CSR and the
increasing prevalence of related disclosures.
Our two suggestions are closely related. Viewing
CSR more broadly as being motivated by both shareholders and a broader group
of stakeholders raises new and important questions that are unlikely to be
studied by accounting researchers who maintain the traditional perspective
that firms only engage in CSR activities that maximize shareholder value. As
discussed in this commentary, one example is that if CSR activities actually
respond to the needs or demands of a broader set of stakeholders, it is more
likely that some CSR investments are made at the expense of shareholders.
Data limitations make it very difficult to address this and related issues
in archival studies. In contrast, such issues can be addressed directly and
effectively in experiments. Consequently, we believe that CSR research is an
area in which integrating the findings from archival and experimental
studies can be especially fruitful. The combination of findings from such
studies is likely to provide a more complete understanding of the drivers
and consequences of CSR activities and related disclosures. Providing such
insights will help accounting researchers become more prominent players in
CSR research. Our hope is that the current growing interest in CSR issues,
as reflected in the two papers included in this Forum, represents a renewed
effort to substantially advance CSR research in accounting.
Jensen Comment
There are still two disappointments for me in the evolution of accountics
science into real science.
It's somewhat revealing to track how this Moser and Martin commentary found its
way into TAR. You might begin by noting the reason former Senior Editor Steve
Kachelmeier gave to the absence of commentaries in TAR (since 1998). In
fairness, I was wrong to have asserted that Steve will not send a "commentary"
out to TAR referees. His reply to me was as follows ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
No, no, no! Once again, your characterization
makes me out to be the dictator who decides the standards of when a
comment gets in and when it doesn’t. The last sentence is especially
bothersome regarding what “Steve tells me is a requisite for his
allowing TAR to publish a comment.” I never said that, so please don’t
put words in my mouth.
If I were to receive a comment of the
“discussant” variety, as you describe, I would send it out for review to
two reviewers in a manner 100% consistent with our stated policy on p.
388 of the January 2010 issue (have you read that policy?). If both
reviewers or even the one independent reviewer returned favorable
assessments, I would then strongly consider publishing it and would most
likely do so. My observation, however, which you keep wanting to
personalize as “my policy,” is that most peer reviewers, in my
experience, want to see a meaningful incremental contribution. (Sorry
for all the comma delimited clauses, but I need this to be precise.)
Bottom line: Please don’t make it out to be the editor’s “policy” if it
is a broader phenomenon of what the peer community wants to see. And the
“peer community,” by the way, are regular professors from all varieties
of backgrounds. I name 574 of them in the November 2009 issue.
Thus the reason given by Steve that a commentary was not published by TAR
since 1998 is that the TAR referees rejected each and every submitted commentary
since 1998. In the back of my mind, however, I always thought the Senior and
Associate Editors of TAR could do more to encourage the publication of
commentaries in TAR.
Thus it's interesting to track the evolution of the May 2012 Moser and Martin
commentary published in TAR.
"A FORUM ON CORPORATE SOCIAL RESPONSIBILITY RESEARCH IN ACCOUNTING
Introduction," by John Harry Evans III (incoming Senior Editor of TAR), The
Accounting Review, Vol. 87, May 2012, pp. 721-722 ---
http://aaajournals.org/doi/full/10.2308/accr-10279
In July 2011, shortly after I began my term as
Senior Editor of The Accounting Review, outgoing editor Steve
Kachelmeier alerted me to an excellent opportunity. He and his co-editors
(in particular, Jim Hunton) had conditionally accepted two manuscripts on
the topic of corporate social responsibility (CSR), and the articles were
scheduled to appear in the May 2012 issue of TAR. Steve suggested
that I consider bundling the two articles as a “forum on corporate social
responsibility research in accounting,” potentially with an introductory
editorial or commentary.
Although I had never worked in the area of CSR
research, I was aware of a long history of interest in CSR research among
accounting scholars. In discussions with my colleague, Don Moser, who was
conducting experiments on CSR topics with his doctoral student, Patrick
Martin, I was struck by the potential for synergy in a forum that combined
the two archival articles with a commentary by experimentalists (Don and
Patrick). Because archival and experimental researchers face different
constraints in terms of what they can observe and control, they tend to
address different, but related, questions. The distinctive questions and
answers in each approach can then provide useful challenges to researchers
in the other, complementary camp. A commentary by Moser and Martin also
offered the very practical advantage that, with Don and Patrick down the
hall from me, it might be feasible to satisfy a very tight schedule calling
for completing the commentary and coordinating it with the authors of the
archival articles within two to three months.
The
Moser and Martin (2012) commentary offers
potential insight concerning how experiments can complement archival
research such as the two fine studies in the forum by
Dhaliwal et al. (2012) and by
Kim et al. (2012). The two forum archival studies
document that shareholders have reason to care about CSR disclosure because
of its association with lower analyst forecast errors and reduced earnings
management. These are important findings about what drives firms' CSR
activities and disclosures, and these results have natural ties to
traditional financial accounting archival research issues.
Like the two archival studies, the
Moser and Martin (2012) commentary focuses on the
positive question of what drives CSR
activities and disclosures in practice as opposed to normative or legal
questions about what should drive these decisions. However, the Moser
and Martin approach to addressing the positive question begins by taking a
broader perspective that allows for the possibility that firms may
potentially consider the demands of stakeholders other than shareholders in
making decisions about CSR activities and disclosures. They then argue that
experiments have certain advantages in understanding CSR phenomena given
this broader environment. For example, in a tightly controlled environment
in which future economic returns are known for certain and individual
reputation can play no role, would managers engage in CSR activities that do
not maximize profits and what information would they disclose about such
activities? Also, how would investors respond to such disclosures?
Jensen Comment
And thus we have a mutation in the evolution of "positive" commentaries in TAR
with the Senior TAR editor being a driving force in that mutation. However, in
accountics science we have a long way to go in terms of publishing critical
commentaries and performing replications of accountics science research ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm#Replication
As Joni Young stated, there's still "an absence of dissent" in accountics
science.
We also have a long way to go in the evolution of accountics science in that
accountics scientists do very little to communicate with accounting teachers and
practitioners ---
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
But the publication of the Moser and Martin commentary in the
May 2012 edition of TAR is a mutation of progress in accountics science
evolution. We owe a big thank you to both TAR Senior Editors Steve Kachelmeier
and Harry Evans.
Bob Jensen's threads on Corporate Social
Responsibility research and
Triple-Bottom (Social, Environmental, Human Resource)
Reporting ---
---
http://faculty.trinity.edu/rjensen/Theory02.htm#TripleBottom
Fortunately this sort of public dispute has never happened in accountics
science where professors just don't steal each others' ideas or insultingly
review each others' work in public. Accountics science is a polite science ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
"Publicizing (Alleged) Plagiarism," by Alexandra Tilsley, Inside
Higher Ed, October 22, 2012 ---
http://www.insidehighered.com/news/2012/10/22/berkeley-launches-plagiarism-investigation-light-public-nature-complaints
The varied effects of the Internet age on the world
of academic research are
well-documented, but a website devoted solely to
highlighting one researcher’s alleged plagiarism has put a new spin on the
matter.
The University of California at Berkeley has begun
an investigation into allegations of plagiarism in professor Terrence
Deacon’s book, Incomplete Nature: How Mind Emerged from Matter,
largely in response to
the website
created about the supposed problems with Deacon’s
book. In Incomplete
Nature, Deacon, the chair of Berkeley's
anthropology department, melds science and philosophy to explain how mental
processes, the stuff that makes us human, emerged from the physical world.
The allegations are not of direct, copy-and-paste
plagiarism, but of using ideas without proper citation. In a June review in
The New York Review of Books, Colin McGinn, a professor of
philosophy at the University of Miami, writes that ideas in Deacon’s book
draw heavily on ideas in works by
Alicia Juarrero,
professor emerita of philosophy at Prince George’s Community College who
earned her Ph.D. at Miami, and Evan Thompson, a philosophy professor at the
University of Toronto, though neither scholar is cited, as Thompson also
notes in his own
review in Nature.
McGinn writes: “I have no way of knowing whether
Deacon was aware of these books when he was writing his: if he was, he
should have cited them; if he was not, a simple literature search would have
easily turned them up (both appear from prominent presses).”
That is an argument Juarrero and her colleagues
Carl Rubino and Michael Lissack have pursued forcefully and publicly. Rubino,
a classics professor at Hamilton College, published a book with Juarrero
that he claims Deacon misappropriated, and that book was published by
Lissack’s Institute for the
Study of Coherence and Emergence. Juarrero, who
declined to comment for this article because of the continuing
investigation, is also a fellow of the institute.
Continued in article
Bob Jensen's threads on professors who cheat ---
http://faculty.trinity.edu/rjensen/Plagiarism.htm#ProfessorsWhoPlagiarize
Consensus Seeking in Real Science Versus Accountics Science
Question
Are there any illustrations of consensus seeking in accountics like consensus
seeking in the real sciences, e.g., consensus seeking on climate change,
consensus seeking on pollution impacts, and consensus seeking on the implosion
of the Twin Towers on 9/11 (whether the towers had to be laced with explosives
in advance to bring them down)?
For example, some scientists predicted environmental disaster when Saddam set
virtually all the oil wells ablaze near the end of the Gulf War. But there was
no consensus among the experts, and those that made dire predictions ultimately
turned out wrong.
Noam Chomsky Schools 9/11 Truther; Explains the Science of Making Credible
Claims ---
http://www.openculture.com/2013/10/noam-chomsky-derides-911-truthers.html
Jensen Comment
I can't recall any instances where high numbers of accountics scientists were
polled with respect to any of their research findings. Are there any good
illustrations that I missed?
In the real sciences consensus seeking is sometimes sought when scientists
cannot agree on the replication outcomes or where replication is impractical or
impossible based upon theory that has not yet been convincingly tested., I
suspect consensus seeking is more common in the natural sciences than in the
social sciences with economics being somewhat of an exception. Polls among
economists are somewhat common, especially regarding economic forecasts.
The closest thing to accounting consensus seeking might take place among expert
witnesses in court, but this is a poor example since consensus may only be
sought among a handful of experts. In science and engineering consensus seeking
takes place among hundreds or even thousands of experts.
Over Reliance Upon Public Databases and Failure to Error Check
DATABASE BIASES AND ERRORS
My casual studies of accountics science articles suggests that over 90% of those
studies rely exclusively on one or more public database whenever the studies use
data. I find few accountics science research into bias and errors of those
databases. Here's a short listing of research into these biases and errors, some
of which were published by accountics scientists ---
This page provides references for articles that
study specific aspects of CRSP, Compustat and other popular sources of
data used by researchers at Kellogg. If you know of any additional
references, please e-mail
researchcomputing-help@kellogg.northwestern.edu.
What went wrong with accountics science?
http://faculty.trinity.edu/rjensen/Theory01.htm#WhatWentWrong
In 2013 I scanned all six issues of The Accounting Review (TAR) published
in 2013 to detect what public databases were (usually at relatively heavy fees
for a system of databases) in the 72 articles published January-November, 2013
in TAR. The outcomes were as follows:
Many of these 72 articles used more than one public database, and when the Compustat and
CRSP joint database was used I counted one for the Compustat Database and
one for the CRSP Database. Most of the non-public databases are behavioral
experiments using students as surrogates for real-world decision makers.
My
opinion is that 2013 is a typical year where over 92% of the articles published
in TAR used putvhsdrf public databases. The good news is that most of these
public databases are enormous, thereby allowing for huge samples for which
statistical inference is probably superfluous. For very large samples even
miniscule differences are significant for hypothesis testing making statistical
inference testing superfluous:
My theory is that accountics science gained
dominance in accounting research, especially in North American accounting Ph.D.
programs, because it abdicated responsibility:
1.
Most accountics scientists buy
data, thereby avoiding the greater cost and drudgery of collecting data.
2.
By relying so heavily on purchased
data, accountics scientists abdicate responsibility for errors in the data.
3.
Since adding missing variable data
to the public database is generally not at all practical in purchased databases,
accountics scientists have an excuse for not collecting missing variable data.
The small subset of accountics scientists that do conduct behavior experiments
generally use students as surrogates for real world decision makers. In addition
the tasks are hypothetical and artificial such that making extrapolations
concerning real world behavior are dubious to say the least.
The good news is that most of these public databases are enormous, thereby
allowing for huge samples for which statistical inference is probably
superfluous. For very large samples even miniscule differences are significant
for hypothesis testing making statistical inference testing superfluous:
The Cult of Statistical Significance: How Standard Error Costs Us
Jobs, Justice, and Lives ---
http://www.cs.trinity.edu/~rjensen/temp/DeirdreMcCloskey/StatisticalSignificance01.htm
Association is Not Causation
The bad news is that the accountics scientists who rely only on public databases
are limited to what is available in those databases. It is much more common in
the real sciences for scientists to collect their own data in labs and field
studies. Accountics scientists tend to model data but not collect their own data
(with some exceptions, especially in behavioral experiments and simulation
games). As a result real scientists can often make causal inferences whereas
accountics scientists can only make correlation or other types of association
inferences leaving causal analysis to speculation.
Of course real scientists many times are forced to work with public databases
like climate and census databases. But they are more obsessed with collecting
their own data that go deeper into root causes. This also leads to more risk of
data fabrication and the need for independent replication efforts (often before
the original results are even published) ---
http://faculty.trinity.edu/rjensen/Plagiarism.htm#ProfessorsWhoPlagiarize
Note the quotation below from from veteran accountics science researchers:
Title: "Fair Value Accounting for Financial Instruments: Does It Improve
the Association between Bank Leverage and Credit Risk?"
Authors: Elizabeth Blankespoor, Thomas J. Linsmeier, Kathy R. Petroni and
Catherine Shakespeare
Source: The Accounting Review, July 2013, pp. 1143-1178
http://aaajournals.org/doi/full/10.2308/accr-50419
"We test for association, not causation."
Bob Jensen discusses the inability to search
for causes in the following reference
"How Non-Scientific Granulation Can Improve Scientific Accountics"
http://www.cs.trinity.edu/~rjensen/temp/AccounticsGranulationCurrentDraft.pdf:
Potential Database Errors
Inability to search for causes is only one of the problems of total reliance on
public databases rather than databases collected by researchers themselves. The other potentially huge
problem is failure to test for errors in the public databases. This is an
enormous problem because accountics science public databases are exceptionally large with tens of
thousands of companies from which thousands of companies are sampled by
accountics scientists. It's sometimes possible to randomly test for database
errors but doing so is tedious and not likely to end up with corrections that
are very useful for large samples.
What I note is that accountics scientists
these days overlook potential problems of errors in their databases. In the past
there were some efforts to check for errors, but I don't know of recent
attempts. This is why I'm asking AECMers to cite where accountics scientists
recently tested for errors in their public databases.
The Audit Analytics database is purportedly especially prone to errors
and biases, but I've not seen much in the way of published studies on
these potential problems. This database is critically analyzed with several
others in the following reference:
A Critical Analysis of Databases Used in Financial Misconduct Research
by Jonathan M. Karpoff , Allison Koester, D. Scott Lee, and Gerald S.
Martin
July 20, 2012
http://www.efa2012.org/papers/s1a1.pdf
Also see
http://www.fesreg.com/index.php/research/financial-misconduct/88-a-critical-analysis-of-databases-used-in-financial-misconduct-research
ERROR RATES IN CRSP AND COMPUSTAT DATA BASES AND THEIR IMPLICATIONS
Barr Rosenberg Associate Professor†, Michel Houglet Associate Professor†
The Journal of Finance
Volume 29, Issue 4, pages 1303–1310, September 1974
Higgledy piggledy bankruptcy
Douglas Wood, Jenifer Piesse
Volume 148 of Manchester business school. working paper
1987
http://books.google.com/books/about/Higgledy_piggledy_bankruptcy.html?id=bZBXAAAAMAAJ
The market reaction to 10-K and 10-Q filings and to subsequent The Wall
Street Journal earnings announcements
EK Stice -
Accounting Review, 1991
On The Operating Performance of REITs Following Seasoned Equity
Offerings: Anomaly Revisited
by
C Ghosh, S Roark, CF Sirmans
The Journal of Real Estate Finance and …, 2013
- Springer
A further examination of income shifting
through transfer pricing considering firm size and/or distress TL
Conover, NB Nichols - The International Journal of Accounting, 2000 -
Elsevier ... of information as well as the firm characteristics.
Kinney and Swanson (1993) specifically addressed COMPUSTAT errors and
omissions involving the tax fields. Since research investigating
transfer prices involves the impact ...
On Alternative Measures of Accruals
L Shi, H Zhang - Accounting Horizons, 2011 -
aaajournals.org
...
Panel B reports results on non-articulations in changes in accounts
receivable. The main
explanation for this type of non-articulation is Compustat
errors, to which five out of the six
observations can be attributed. ... All of them can be attributed
to Compustat errors. ...
Questions (actually a favor request)
Are there some current references on the data errors in public databases that
are mostly used in accountics science studies?
For example, how reliable are the Datastream databases?
I have not seen much published about Datastream errors and biases.
October 21, 2013 reply from Dan Stone
A recent article in "The Economist" decries the
absence of replication in
science.
short url:
http://tinyurl.com/lepu6zz
http://www.economist.com/news/leaders/21588069-scientific-research-
has-changed-world-now-it-needs-change-itself-how-science-goes-wrong
October 21, 2013 reply from Bob Jensen
I read The Economist every week and usually respect it sufficiently to
quote it a lot. But sometimes articles disappoint me as an academic in
search of evidence for controversial assertions like the one you link to
about declining replication in the sciences.
Dartmouth Professor Nyhan paints a somewhat similar picture about where
some of the leading medical journals now "tend to fail to replicate."
However other journals that he mentions are requiring a replication archives
and replication audits. It seems to me that some top science journals are
becoming more concerned about validity of research findings while perhaps
others have become more lax.
"Academic reforms: A four-part proposal," by Brendon Nyhan, April 16,
2013 ---
http://www.brendan-nyhan.com/blog/2012/04/academic-reforms-a-four-part-proposal.html
The "collaborative replication" idea has become a big deal. I have a
former psychology colleague at Trinity who has a stellar reputation for
empirical brain research in memory. She tells me that she does not submit
articles any more until they have been independently replicated by other
experts.
It may well be true that natural science journals have become negligent
in requiring replication and in providing incentives to replicate. However,
perhaps, because the social science journals have a harder time being
believed, I think that some of their top journals have become more obsessed
with replication.
In any case I don't know of any science that is less concerned with lack
of replication than accountics science. TAR has a policy of not publishing
replications or replication abstracts unless the replication is only
incidental to extending the findings with new research findings. TAR also
has a recent reputation of not encouraging commentaries on the papers it
publishes.
Has TAR even published a commentary on any paper it published in recent
years?
Have you encountered any recent investigations into errors in our most
popular public databases in accountics science?
Thanks,
Bob Jensen
October 22, 2013 reply from Roman Chychyla
Hello Professor Jensen,
My name is Roman Chychyla and I am a 5th year PhD
student in AIS at Rutgers business school. I have seen your post at AECM
regarding errors in accounting databases. I find this issue quite
interesting. As a matter of fact, it is a part of my dissertation. I have
recently put on SSRN a working paper that I wrote with my adviser, Alex
Kogan, that compares annual numbers in Compustat to numbers in 10-K filings
on a large-scale basis using the means of XBRL technology: http://ssrn.com/abstract=2304473
My impression from working on that paper is that
the volume of errors in Compustat is relatively low (probably by now
Compustat has decent data verification process in place). However, the
Compustat adjustments designed to standardize variables may be a serious
issue. These adjustments sometimes results in both economically and
statistically significant differences between Compustat and 10-K concepts
that change the distribution of underlying variables. This, in turn, may
affect the outcome of empirical models that rely on Compustat data.
Arguably, the adjustments may be a good thing
(although an opposite argument is that companies themselves are in the best
position to present their numbers adequately). But it may well be the case
that accounting researches are not fully aware of these adjustments and do
not take them into account. For example, a number of archival accounting
studies implicitly assume that market participants operate based on
Compustat numbers at the times of financial reports being released, while
what market participants really see are the unmodified numbers in financial
reports. Moreover, Compustat does not provide original numbers from
financial reports, and it was unknown how large the differences are. In our
paper, we study the amount and magnitude of these differences and document
them.
Hope you find this information interesting. Please
feel free to contact me any time. Thanks.
All the best,
Roman
October 22, 2013 reply from Bob Jensen
Hi Roman,
Thank you so much for your reply. I realize that Compustat and CRSP have
been around long enough to program in some error controls. However, you are
on a tack that I never thought of taking.
My interest is more with the newer Datastream database and with Audit
Analytics where I'm still not trusting.
May I share your reply with the AECM?
Thanks,
Bob
October 23, 2013 reply from Roman Chychyla
I agree, new databases are more prone to errors.
There were a lot of errors in early versions of Compustat and CRSP as
Rosenberg and Houglet showed. On the other hand, the technology now is
better and the error-verification processes should be more advanced and less
costly.
Of course, feel free to share our correspondence with the AECM.
Thanks!
Best,
Roman
October 21, 2013 reply from Dan Stone
A recent article in "The Economist" decries the
absence of replication in
science.
short url:
http://tinyurl.com/lepu6zz
http://www.economist.com/news/leaders/21588069-scientific-research-
has-changed-world-now-it-needs-change-itself-how-science-goes-wrong
October 21, 2013 reply from Bob Jensen
I read The Economist every week and usually respect it sufficiently to
quote it a lot. But sometimes articles disappoint me as an academic in
search of evidence for controversial assertions like the one you link to
about declining replication in the sciences.
Dartmouth Professor Nyhan paints a somewhat similar picture about where
some of the leading medical journals now "tend to fail to replicate."
However other journals that he mentions are requiring a replication archives
and replication audits. It seems to me that some top science journals are
becoming more concerned about validity of research findings while perhaps
others have become more lax.
"Academic reforms: A four-part proposal," by Brendon Nyhan, April 16,
2013 ---
http://www.brendan-nyhan.com/blog/2012/04/academic-reforms-a-four-part-proposal.html
The "collaborative replication" idea has become a big deal. I have a
former psychology colleague at Trinity who has a stellar reputation for
empirical brain research in memory. She tells me that she does not submit
articles any more until they have been independently replicated by other
experts.
It may well be true that natural science journals have become negligent
in requiring replication and in providing incentives to replicate. However,
perhaps, because the social science journals have a harder time being
believed, I think that some of their top journals have become more obsessed
with replication.
In any case I don't know of any science that is less concerned with lack
of replication than accountics science. TAR has a policy of not publishing
replications or replication abstracts unless the replication is only
incidental to extending the findings with new research findings. TAR also
has a recent reputation of not encouraging commentaries on the papers it
publishes.
Has TAR even published a commentary on any paper it published in recent
years?
Have you encountered any recent investigations into errors in our most
popular public databases in accountics science?
Thanks,
Bob Jensen
Are accountics scientists more honest and ethical than real scientists?
Accountics science is defined at
http://faculty.trinity.edu/rjensen/395wpTAR/Web/TAR395wp.htm
One of the main reasons Bob Jensen contends that accountics science is not yet a
real science is that lack of exacting replications of accountics science
findings. By exacting replications he means reproducibility as defined in the
IAPUC Gold Book ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm#Replication
The leading accountics science (an indeed the leading academic accounting
research journals) are The Accounting Review (TAR), the Journal of
Accounting Research (JAR), and the Journal of Accounting and Economics
(JAE). Publishing accountics science in these journals is a necessary condition
for nearly all accounting researchers at top R1 research universities in North
America.
On the AECM listserv, Bob Jensen and former TAR Senior Editor Steven
Kachelmeier have had an ongoing debate about accountics science relevance and
replication for well over a year in what Steve now calls a game of CalvinBall.
When Bob Jensen noted the lack of exacting replication in accountics science,
Steve's CalvinBall reply was that replication is the name of the game in
accountics science:
The answer to your question, "Do you really think
accounting researchers have the hots for replicating their own findings?" is
unequivocally YES,
though I am not sure about the word "hots." Still, replications in the sense
of replicating prior findings and then extending (or refuting) those
findings in different settings happen all the time, and they get published
regularly. I gave you four examples from one TAR issue alone (July 2011).
You seem to disqualify and ignore these kinds of replications because they
dare to also go beyond the original study. Or maybe they don't count for you
because they look at their own watches to replicate the time instead of
asking to borrow the original researcher's watch. But they count for me.
To which my CalvinBall reply to Steve is --- "WOW!" In the past four decades
of all this unequivocal replication in accountics science there's not been a
single scandal. Out of the thousands of accountics science papers published in
TAR, JAR, and JAE there's not been a single paper withdrawn after publication,
to my knowledge, because of a replication study discovery. Sure there have been
some quibbles about details in the findings and some improvements in statistical
significance by tweaking the regression models, but there's not been a
replication finding serious enough to force a publication retraction or serious
enough to force the resignation of an accountics scientist.
In real science, where more exacting replications really are the name of the
game, there have been many scandals over the past four decades. Nearly all top
science journals have retracted articles because independent researchers could
not exactly replicate the reported findings. And it's not all that rare to force
a real scientist to resign due to scandalous findings in replication efforts.
The most serious scandals entail faked data or even faked studies. These
types of scandals apparently have never been detected among thousands of
accountics science publications. The implication is that accountics
scientists are more honest as a group than real scientists. I guess that's
either good news or bad replicating.
Given the pressures brought to bear on accounting faculty to publish
accountics science articles, the accountics science scandal may be that
accountics science replications have never revealed a scandal --- to my
knowledge at least.
One of the most recent scandals arose when a very well-known psychologist
named Mark Hauser.
"Author on leave after Harvard inquiry Investigation of scientist’s work finds
evidence of misconduct, prompts retraction by journal," by Carolyn Y. Johnson,
The Boston Globe, August 10, 2010 ---
http://www.boston.com/news/education/higher/articles/2010/08/10/author_on_leave_after_harvard_inquiry/
Harvard University psychologist Marc Hauser — a
well-known scientist and author of the book “Moral Minds’’ — is taking a
year-long leave after a lengthy internal investigation found evidence of
scientific misconduct in his laboratory.
The findings have resulted in the retraction of an
influential study that he led. “MH accepts responsibility for the error,’’
says the retraction of the study on whether monkeys learn rules, which was
published in 2002 in the journal Cognition.
Two other journals say they have been notified of
concerns in papers on which Hauser is listed as one of the main authors.
It is unusual for a scientist as prominent as
Hauser — a popular professor and eloquent communicator of science whose work
has often been featured on television and in newspapers — to be named in an
investigation of scientific misconduct. His research focuses on the
evolutionary roots of the human mind.
In a letter Hauser wrote this year to some Harvard
colleagues, he described the inquiry as painful. The letter, which was shown
to the Globe, said that his lab has been under investigation for three years
by a Harvard committee, and that evidence of misconduct was found. He
alluded to unspecified mistakes and oversights that he had made, and said he
will be on leave for the upcoming academic year.
Continued in article
Update: Hauser resigned from Harvard in 2011 after the published
research in question was retracted by the journals.
Not only have there been no similar reported accountics science scandals
called to my attention, I'm not aware of any investigations of impropriety that
were discovered among all those "replications" claimed by Steve.
What is an Exacting Replication?
I define an exacting replication as one in which the findings are reproducible
by independent researchers using the IAPUC Gold Book standards for
reproducibility. Steve makes a big deal about time extensions when making such
exacting replications almost impossible in accountics science. He states:
By "exacting replication," you appear to mean doing
exactly what the original researcher did -- no more and no less. So if one
wishes to replicate a study conducted with data from 2000 to 2008, one had
better not extend it to 2009, as that clearly would not be "exacting." Or,
to borrow a metaphor I've used earlier, if you'd like to replicate my
assertion that it is currently 8:54 a.m., ask to borrow my watch -- you
can't look at your watch because that wouldn't be an "exacting" replication.
That's CalvinBall bull since in many of these time extensions it's also
possible to conduct an exacting replication. Richard Sansing pointed out the how
he conducted an exacting replication of the findings in Dhaliwal, Li and R.
Trezevant (2003), "Is a dividend tax penalty
incorporated into the return on a firm’s common stock?," Journal of
Accounting and Economics 35: 155-178. Although Richard and his coauthor
extend the Dhaliwal findings they first conducted an exacting replication in
their paper published in The Accounting Review 85 (May
2010): 849-875.
My quibble with Richard is mostly that conducting an exacting replication of
the Dhaliwal et al. paper was not exactly a burning (hot)
issue if nobody bothered to replicate that award winning JAE paper for seven
years.
This begs the question of why there are not more frequent and timely exacting
replications conducted in accountics science if the databases themselves are
commercially available like the CRSP, Compustat, and AuditAnalytics databases.
Exacting replications from these databases are relatively easy and cheap to
conduct. My contention here is that there's no incentive to excitedly conduct
exacting replications if the accountics journals will not even publish
commentaries about published studies. Steve and I've played CalvinBall with the
commentaries issue before. He contends that TAR editors do not prevent
commentaries from being published in TAR. The barriers to validity questioning
commentaries in TAR are the 574 referees who won't accept submitted commentaries
---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm#ColdWater
Exacting replications of behavioral experiments in accountics science is more
difficult and costly because the replicators must conduct their own experiments
by collecting their own data. But it seems to me that it's no more difficult in
accountics science than in performing exacting replications that are reported in
the research literature of psychology. However, psychologists often have more
incentives to conduct exacting replications for the following reasons that I
surmise:
- Practicing psychologists are more demanding of validity tests of
research findings. Practicing accountants seem to pretty much ignore
behavioral experiments published in TAR, JAR, and JAE such that there's not
as much pressure brought to bear on validity testing of accountics science
findings. One test of practitioner lack of interest is the lack of citation
of accountics science in practitioner journals.
- Psychology researchers have more incentives to replicate experiments of
others since there are more outlets for publication credits of replication
studies, especially in psychology journals that encourage commentaries on
published research ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm#TARversusJEC
My opinion remains that accountics science will never be a real science until
exacting replication of research findings become the name of the game in
accountics science. This includes exacting replications of behavioral
experiments as well as analysis of public data from CRSP, Compustat,
AuditAnalytics, and other commercial databases. Note that willingness of
accountics science authors to share their private data for replication purposes
is a very good thing (I fought for this when I was on the AAA Executive
Committee), but conducting replication studies of such data does not hold up
well under the IAPUC Gold Book.
Note, however, that lack of exacting replication and other validity testing
in general are only part of the huge problems with accountics science. The
biggest problem, in my judgment, is the way accountics scientists have
established monopoly powers over accounting doctoral programs, faculty hiring
criteria, faculty performance criteria, and pay scales. Accounting researchers
using other methodologies like case and field research become second class
faculty.
Since the odds of getting a case or field study published are so low, very
few of such studies are even submitted for publication in TAR in recent years.
Replication of these is a non-issue in TAR.
"Annual Report and Editorial Commentary for The Accounting Review,"
by Steven J. Kachelmeier The University of Texas at Austin, The
Accounting Review, November 2009, Page 2056.
There's not much hope for case, field, survey, and other non-accountics
researchers to publish in the leading research journal of the American
Accounting Association.
What went wrong with accountics research?
http://faculty.trinity.edu/rjensen/theory01.htm#WhatWentWrong
"We fervently hope that the research pendulum will soon swing back from the
narrow lines of inquiry that dominate today's leading journals to a rediscovery
of the richness of what accounting research can be. For that to occur, deans and
the current generation of academic accountants must
give it a push."
Granif and Zeff ---
http://www.trinity.edu/rjensen/TheoryTAR.htm#Appendix01
Michael H. Granof is a professor of accounting at the McCombs School of
Business at the University of Texas at Austin. Stephen A. Zeff is a
professor of accounting at the Jesse H. Jones Graduate School of Management at
Rice University.
I admit that I'm just one of those
professors heeding the Granof and Zeff call to "give it a push," but it's
hard to get accountics professors to give up their monopoly on TAR, JAR, JAE,
and in recent years Accounting Horizons. It's even harder to get them to
give up their iron monopoly clasp on North American Accountancy Doctoral
Programs ---
http://www.trinity.edu/rjensen/Theory01.htm#DoctoralPrograms
September 10, 2011 message from Bob Jensen
Hi Raza,
Please don't get me wrong. As an old accountics researcher myself, I'm
all in favor of continuing accountics research full speed ahead. The
younger mathematicians like Richard Sansing are doing it better these
days. What I'm upset about is the way the accountics science quants took
over TAR, AH, accounting faculty performance standards in R1
universities, and virtually all accounting doctoral programs in North
America.
Monopolies are not all bad --- they generally do great good they for
mankind. The problem is that monopolies shut out the competition. In the
case of accountics science, the accountics scientists have shut out
competing research methods to a point where accounting doctoral students
must write accountics science dissertations, and TAR referees will not
open the door to case studies, field studies, accounting history
studies, or commentaries critical of accountics science findings in TAR.
The sad thing is that even if we open up our doctoral programs to other
research methodologies, the students themselves may prefer accountics
science research. It's generally easier to apply regression models to
CRSP, Compustat, and Audit Analytics databases than have to go off
campus to collect data and come up with clever ideas to improve
accounting practice in ways that will amaze practitioners.
Another problem with accountics science is that this monopoly has not
created incentives for validity checking of accountics science findings.
This has prevented accountics science from being real science where
validity checking is a necessary condition for research and publication.
If TAR invited commentaries on validity testing of TAR publications, I
think there would be more replication efforts.
If TAR commenced a practitioners' forum where practitioners were
"assigned" to discuss TAR articles, perhaps there would be more
published insights into possible relevance of accountics science to the
practice of accountancy. I put "assign" in quotations since
practitioners may have to be nudged in some ways to get them to critique
accountics science articles.
There are some technical areas where practitioners have more expertise
than accountics scientists, particularly in the areas of insurance
accounting, pension accounting, goodwill impairment testing, accounting
for derivative financial instruments, hedge accounting, etc. Perhaps
these practitioner experts might even publish a "research needs" forum
in TAR such that our very bright accountics scientists would be inspired
to focus their many talents on some accountancy practice technical
problems.
My main criticism of accountics scientists is that the 600+ TAR referees
have shut down critical commentaries of their works and the recent
editors of TAR have been unimaginative when in thinking of ways to
motivate replication research, TAR article commentaries, and focus of
accountics scientists on professional practice problems.
Some ideas for improving TAR are provided at
http://www.trinity.edu/rjensen/TheoryTAR.htm
Particularly note the module on
TAR versus AMR and AMJ
Accountics Scientists Seeking Truth:
"Frankly, Scarlett, after I get a hit for my resume in The Accounting Review
I just don't give a damn"
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
One more mission in what's left of my life will be to try to change this
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
title:
Science Warriors' Ego Trips
(Accountics)
journal/magazine/etc.:
The Chronicle Review
publication date:
April 25, 2010
article text:
It is the
mark of an educated mind to be able to entertain a thought without
accepting it.
Aristotle"Science Warriors' Ego
Trips," by Carlin Romano, Chronicle of Higher Education's The
Chronicle Review, April 25, 2010 ---
http://chronicle.com/article/Science-Warriors-Ego-Trips/65186/
Standing up for science excites some intellectuals the way beautiful
actresses arouse Warren Beatty, or career liberals boil the blood of
Glenn Beck and Rush Limbaugh. It's visceral. The thinker of this ilk
looks in the mirror and sees Galileo bravely muttering "Eppure si
muove!" ("And yet, it moves!") while Vatican guards drag him away.
Sometimes the hero in the reflection is Voltaire sticking it to the
clerics, or Darwin triumphing against both Church and Church-going
wife. A brave champion of beleaguered science in the modern age of
pseudoscience, this Ayn Rand protagonist sarcastically derides the
benighted irrationalists and glows with a self-anointed superiority.
Who wouldn't want to feel that sense of power and rightness?
You
hear the voice regularly—along with far more sensible stuff—in the
latest of a now common genre of science patriotism, Nonsense on
Stilts: How to Tell Science From Bunk (University of Chicago Press),
by Massimo Pigliucci, a philosophy professor at the City University
of New York. Like such not-so-distant books as Idiot America, by
Charles P. Pierce (Doubleday, 2009), The Age of American Unreason,
by Susan Jacoby (Pantheon, 2008), and Denialism, by Michael Specter
(Penguin Press, 2009), it mixes eminent common sense and frequent
good reporting with a cocksure hubris utterly inappropriate to the
practice it apotheosizes.
According to Pigliucci, both Freudian psychoanalysis and Marxist
theory of history "are too broad, too flexible with regard to
observations, to actually tell us anything interesting." (That's
right—not one "interesting" thing.) The idea of intelligent design
in biology "has made no progress since its last serious articulation
by natural theologian William Paley in 1802," and the empirical
evidence for evolution is like that for "an open-and-shut murder
case."
Pigliucci offers more hero sandwiches spiced with derision and
certainty. Media coverage of science is "characterized by allegedly
serious journalists who behave like comedians." Commenting on the
highly publicized Dover, Pa., court case in which U.S. District
Judge John E. Jones III ruled that intelligent-design theory is not
science, Pigliucci labels the need for that judgment a "bizarre"
consequence of the local school board's "inane" resolution. Noting
the complaint of intelligent-design advocate William Buckingham that
an approved science textbook didn't give creationism a fair shake,
Pigliucci writes, "This is like complaining that a textbook in
astronomy is too focused on the Copernican theory of the structure
of the solar system and unfairly neglects the possibility that the
Flying Spaghetti Monster is really pulling each planet's strings,
unseen by the deluded scientists."
Is it
really? Or is it possible that the alternate view unfairly neglected
could be more like that of Harvard scientist Owen Gingerich, who
contends in God's Universe (Harvard University Press, 2006) that it
is partly statistical arguments—the extraordinary unlikelihood eons
ago of the physical conditions necessary for self-conscious
life—that support his belief in a universe "congenially designed for
the existence of intelligent, self-reflective life"? Even if we
agree that capital "I" and "D" intelligent-design of the scriptural
sort—what Gingerich himself calls "primitive scriptural
literalism"—is not scientifically credible, does that make
Gingerich's assertion, "I believe in intelligent design, lowercase i
and lowercase d," equivalent to Flying-Spaghetti-Monsterism?
Tone
matters. And sarcasm is not science.
The
problem with polemicists like Pigliucci is that a chasm has opened
up between two groups that might loosely be distinguished as
"philosophers of science" and "science warriors." Philosophers of
science, often operating under the aegis of Thomas Kuhn, recognize
that science is a diverse, social enterprise that has changed over
time, developed different methodologies in different subsciences,
and often advanced by taking putative pseudoscience seriously, as in
debunking cold fusion. The science warriors, by contrast, often
write as if our science of the moment is isomorphic with knowledge
of an objective world-in-itself—Kant be damned!—and any form of
inquiry that doesn't fit the writer's criteria of proper science
must be banished as "bunk." Pigliucci, typically, hasn't much
sympathy for radical philosophies of science. He calls the work of
Paul Feyerabend "lunacy," deems Bruno Latour "a fool," and observes
that "the great pronouncements of feminist science have fallen as
flat as the similarly empty utterances of supporters of intelligent
design."
It
doesn't have to be this way. The noble enterprise of submitting
nonscientific knowledge claims to critical scrutiny—an activity
continuous with both philosophy and science—took off in an admirable
way in the late 20th century when Paul Kurtz, of the University at
Buffalo, established the Committee for the Scientific Investigation
of Claims of the Paranormal (Csicop) in May 1976. Csicop soon after
launched the marvelous journal Skeptical Inquirer, edited for more
than 30 years by Kendrick Frazier.
Although Pigliucci himself publishes in Skeptical Inquirer, his
contributions there exhibit his signature smugness. For an antidote
to Pigliucci's overweening scientism 'tude, it's refreshing to
consult Kurtz's curtain-raising essay, "Science and the Public," in
Science Under Siege (Prometheus Books, 2009, edited by Frazier),
which gathers 30 years of the best of Skeptical Inquirer.
Kurtz's
commandment might be stated, "Don't mock or ridicule—investigate and
explain." He writes: "We attempted to make it clear that we were
interested in fair and impartial inquiry, that we were not dogmatic
or closed-minded, and that skepticism did not imply a priori
rejection of any reasonable claim. Indeed, I insisted that our
skepticism was not totalistic or nihilistic about paranormal
claims."
Kurtz
combines the ethos of both critical investigator and philosopher of
science. Describing modern science as a practice in which
"hypotheses and theories are based upon rigorous methods of
empirical investigation, experimental confirmation, and
replication," he notes: "One must be prepared to overthrow an entire
theoretical framework—and this has happened often in the history of
science ... skeptical doubt is an integral part of the method of
science, and scientists should be prepared to question received
scientific doctrines and reject them in the light of new evidence."
Considering the dodgy matters Skeptical Inquirer specializes in,
Kurtz's methodological fairness looks even more impressive. Here's
part of his own wonderful, detailed list: "Psychic claims and
predictions; parapsychology (psi, ESP, clairvoyance, telepathy,
precognition, psychokinesis); UFO visitations and abductions by
extraterrestrials (Roswell, cattle mutilations, crop circles);
monsters of the deep (the Loch Ness monster) and of the forests and
mountains (Sasquatch, or Bigfoot); mysteries of the oceans (the
Bermuda Triangle, Atlantis); cryptozoology (the search for unknown
species); ghosts, apparitions, and haunted houses (the Amityville
horror); astrology and horoscopes (Jeanne Dixon, the "Mars effect,"
the "Jupiter effect"); spoon bending (Uri Geller). ... "
Even
when investigating miracles, Kurtz explains, Csicop's intrepid
senior researcher Joe Nickell "refuses to declare a priori that any
miracle claim is false." Instead, he conducts "an on-site inquest
into the facts surrounding the case." That is, instead of declaring,
"Nonsense on stilts!" he gets cracking.
Pigliucci, alas, allows his animus against the nonscientific to pull
him away from sensitive distinctions among various sciences to
sloppy arguments one didn't see in such earlier works of science
patriotism as Carl Sagan's The Demon-Haunted World: Science as a
Candle in the Dark (Random House, 1995). Indeed, he probably sets a
world record for misuse of the word "fallacy."
To his
credit, Pigliucci at times acknowledges the nondogmatic spine of
science. He concedes that "science is characterized by a fuzzy
borderline with other types of inquiry that may or may not one day
become sciences." Science, he admits, "actually refers to a rather
heterogeneous family of activities, not to a single and universal
method." He rightly warns that some pseudoscience—for example,
denial of HIV-AIDS causation—is dangerous and terrible.
But at
other points, Pigliucci ferociously attacks opponents like the most
unreflective science fanatic, as if he belongs to some Tea Party
offshoot of the Royal Society. He dismisses Feyerabend's view that
"science is a religion" as simply "preposterous," even though he
elsewhere admits that "methodological naturalism"—the commitment of
all scientists to reject "supernatural" explanations—is itself not
an empirically verifiable principle or fact, but rather an almost
Kantian precondition of scientific knowledge. An article of faith,
some cold-eyed Feyerabend fans might say.
In an
even greater disservice, Pigliucci repeatedly suggests that
intelligent-design thinkers must want "supernatural explanations
reintroduced into science," when that's not logically required. He
writes, "ID is not a scientific theory at all because there is no
empirical observation that can possibly contradict it. Anything we
observe in nature could, in principle, be attributed to an
unspecified intelligent designer who works in mysterious ways." But
earlier in the book, he correctly argues against Karl Popper that
susceptibility to falsification cannot be the sole criterion of
science, because science also confirms. It is, in principle,
possible that an empirical observation could confirm intelligent
design—i.e., that magic moment when the ultimate UFO lands with
representatives of the intergalactic society that planted early life
here, and we accept their evidence that they did it. The point is
not that this is remotely likely. It's that the possibility is not
irrational, just as provocative science fiction is not irrational.
Pigliucci similarly derides religious explanations on logical
grounds when he should be content with rejecting such explanations
as unproven. "As long as we do not venture to make hypotheses about
who the designer is and why and how she operates," he writes, "there
are no empirical constraints on the 'theory' at all. Anything goes,
and therefore nothing holds, because a theory that 'explains'
everything really explains nothing."
Here,
Pigliucci again mixes up what's likely or provable with what's
logically possible or rational. The creation stories of traditional
religions and scriptures do, in effect, offer hypotheses, or claims,
about who the designer is—e.g., see the Bible. And believers
sometimes put forth the existence of scriptures (think of them as
"reports") and a centuries-long chain of believers in them as a form
of empirical evidence. Far from explaining nothing because it
explains everything, such an explanation explains a lot by
explaining everything. It just doesn't explain it convincingly to a
scientist with other evidentiary standards.
A
sensible person can side with scientists on what's true, but not
with Pigliucci on what's rational and possible. Pigliucci
occasionally recognizes that. Late in his book, he concedes that
"nonscientific claims may be true and still not qualify as science."
But if that's so, and we care about truth, why exalt science to the
degree he does? If there's really a heaven, and science can't (yet?)
detect it, so much the worse for science.
As an
epigram to his chapter titled "From Superstition to Natural
Philosophy," Pigliucci quotes a line from Aristotle: "It is the mark
of an educated mind to be able to entertain a thought without
accepting it." Science warriors such as Pigliucci, or Michael Ruse
in his recent clash with other philosophers in these pages, should
reflect on a related modern sense of "entertain." One does not
entertain a guest by mocking, deriding, and abusing the guest.
Similarly, one does not entertain a thought or approach to knowledge
by ridiculing it.
Long
live Skeptical Inquirer! But can we deep-six the egomania and
unearned arrogance of the science patriots? As Descartes, that
immortal hero of scientists and skeptics everywhere, pointed out,
true skepticism, like true charity, begins at home.
Carlin Romano, critic at large
for The Chronicle Review, teaches philosophy and media theory at the
University of Pennsylvania.
Jensen Comment
One way to distinguish my conceptualization of science from pseudo
science is that science relentlessly seeks to replicate and validate
purported discoveries, especially after the discoveries have been made
public in scientific journals ---
http://faculty.trinity.edu/rjensen/TheoryTar.htm
Science encourages conjecture but doggedly seeks truth about that
conjecture. Pseudo science is less concerned about validating purported
discoveries than it is about publishing new conjectures that are largely
ignored by other pseudo scientists.
Accountics Scientists Seeking
Truth:
"Frankly, Scarlett, after I get a hit for my resume in The
Accounting Review I just don't give a damn"
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
One more mission in what's left of my life will be to try to
change this
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
TAR Versus JEC
Nearly all lab experiments or other empirical studies published in
the
Journal of Electroanalytical Chemistry (JEC) are replicated. I
mention this journal because one of its famous published studies on cold fusion
in 1989 could not (at least not yet) be replicated. The inability of any
researchers worldwide to replicate that study destroyed the stellar reputations
of the original authors
Stanley Pons
and
Martin Fleischmann.
Others who were loose with their facts:
former Harvard researcher John Darsee (faked cardiac research); radiologist
Rober Slutsky (altered data; lied); obstetrician William McBride (changed
data, ruined stellar reputation), and physicist J. Hendrik Schon (faked
breakthroughs in molecular electronics).
Discover Magazine, December 2010, Page 43
Question
Has an accountics researcher ever retracted a claim?
Among the thousands of published accountics studies some author must be aware,
maybe in retrospect, of a false claim?
Perhaps we'll never know!
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
It's been a bad year for Harvard University science retractions
"3 Harvard Researchers Retract a Claim on the Aging of Stem Cells," by Nicolas
Wade, The New York Times, October 14, 2010 ---
http://www.nytimes.com/2010/10/15/science/15retract.html?hpw
Harvard researchers have retracted a far-reaching
claim they made in January that the aging of stem cells might be reversible.
The retraction was published in Thursday’s issue of
Nature and is signed by the senior author, Amy J. Wagers, and two others.
They say that serious concerns, which they did not specify, have undermined
their confidence in the original report.
A fourth author, Shane R. Mayack, maintained that
the results were still valid and refused to sign the retraction. All four
scientists are affiliated with Harvard University and the Joslin Diabetes
Center, a Harvard affiliate.
The original article, published by Nature in
January, asserted that there was a rejuvenating factor in the blood of young
mice that could reverse symptoms of aging in the blood-forming stem cells of
elderly mice. The therapeutic use of such a factor would be “to extend the
youthful function of the aging blood system,” Dr. Wagers and her colleagues
wrote.
The article states that Dr. Wagers designed and
interpreted the experiments and that Dr. Mayack, a post-doctoral student,
performed and analyzed them.
Dr. Wagers issued a statement saying that she had
immediately brought the disturbing information to the attention of Nature
and the Harvard Medical School, and that she was working to repeat the
experiments. She said by e-mail that the information came to light in the
course of studies in her laboratory, prompting her to re-examine the
reported data.
Press officers at Harvard Medical School, Joslin
and the Harvard Stem Cell Institute said the matter was being reviewed but
declined to comment further. Rachel Twinn, a Nature press officer, said she
could not comment.
Dr. Wagers has expressed her doubts about a second
paper co-authored with Dr. Mayack and published in the journal Blood in
August 2008. In a statement issued today, the journal said it was posting a
“Notice of Concern” about the paper pending further review.
Continued in article
Natural scientists in general are motivated to conduct replication studies in
large measure because their commentaries or abstracts on their
research, including results of replication testing, are widely published in top
science journals. Replication publications, however may be limited to short
commentaries or published abstracts. that are refereed. In any case,
replicators get publication credits in the academy. Natural scientists deem
integrity and accuracy to be too important to play down by not providing some
sort of publication outlet.
There are virtually no published reports of replications of experiments
published in The
Accounting Review (TAR), although nearly all of TAR's articles in the
last 25 years, aside from strictly mathematics analytical papers, are lab
experiments or other empirical studies. There are occasional extensions of
capital markets (archival database) empiricism, but it's not common in those
studies to report independent replication outcomes per se. Since the odds of
getting a case or field study published are so low, very few of such studies are
even submitted for publication in TAR in recent years. Replication of these is a
non-issue in TAR.
"Annual Report and Editorial Commentary for The Accounting Review,"
by Steven J. Kachelmeier The University of Texas at Austin, The
Accounting Review, November 2009, Page 2056.
Table 4 in Heck and Jensen (2007) identifies Cornell's Mark W. Nelson as
the accounting scientist having the highest number (eight) of studies
published in TAR in the decade 1986-2005 ---
“An Analysis of the Evolution of Research Contributions by The Accounting
Review: 1926-2005,” (with Jean Heck), Accounting Historians Journal,
Volume 34, No. 2, December 2007, pp. 109-142.
Mark Nelson tends to publish excellent accountancy lab experiments, but I do
not know of any of his experiments or other TAR-reported that have ever
been independently replicated. I suspect he wishes that all of his experiments
are replicated because, like any researcher, he's fallible on occasion.
Replication would also draw greater attention to his fine work. The current TAR
editor will not publish commentaries, including abstracts reporting
successful replication studies. My contention is that accounting science
researchers have been discouraged from conducting replication studies of TAR
research because TAR will not publish commentaries/dialogs about papers
published in TAR. They may also be discouraged from replication because the
hypotheses themselves are uninspiring and uninteresting, but I will not go into
that in this message.
November 22, 2011 reply from Steve Kachelmeier
First, Table 3 in the 2011 Annual Report
(submissions and acceptances by area) only includes manuscripts that went
through the regular blind reviewing process. That is, it excludes invited
presidential scholar lectures, editorials, book reviews, etc. So "other"
means "other regular submissions."
Second, you are correct Bob that "other" continues
to represent a small percentage of the total acceptances. But "other" is
also a very small percentage of the total submissions. As I state explicitly
in the report, Table 3 does not prove that TAR is sufficienty diverse. It
does, however, provide evidence that TAR acceptances by topical area (or by
method) are nearly identically proportional to TAR submissions by topical
area (or by method).
Third, for a great example of a recently published
TAR study with substantial historical content, see Madsen's analysis of the
historical development of standardization in accounting that we published in
in the September 2011 issue. I conditionally accepted Madsen's submission in
the first round, backed by favorable reports from two reviewers with
expertise in accounting history and standardization.
Take care,
Steve
November 23, 2011 reply from Bob Jensen
Hi Steve,
Thank you for the clarification.
Interestingly, Madsen's September 2011 historical study (which came out
after your report's May 2011 cutoff date) is a heavy accountics science
paper with a historical focus.
It would be interesting to whether such a paper would've been accepted by
TAR referees without the factor (actually principal components analysis).
Personally, I doubt any history paper would be accepted without equations
and quantitative analysis. In the case of Madsen's paper, if I were a
referee I would probably challenge the robustness of the principal
components and loadings ---
http://en.wikipedia.org/wiki/Principle_components_analysis
Actually factor analysis in general like nonlinear multiple regression and
adaptive versions thereof suffer greatly from lack of robustness. Sometimes
quantitative models gild the lily to a fault.
Bob Kaplan's Presidential Scholar historical study was published, but
this was not subjected to the usual TAR refereeing process.
The History of The Accounting Review paper written by Jean Heck and Bob
Jensen which won a best paper award from the Accounting Historians Journal
was initially flatly rejected by TAR. I was never quite certain if the main
reason was that it did not contain equations or if the main reason was that
it was critical of TAR editorship and refereeing. In any case it was flatly
rejected by TAR, including a rejection by one referee who refused to put
reasons in writing for feed\back to Jean and me.
“An Analysis of the Evolution of Research Contributions by The
Accounting Review: 1926-2005,” (with Jean Heck), Accounting
Historians Journal, Volume 34, No. 2, December 2007, pp. 109-142.
I would argue that accounting history papers, normative methods papers,
and scholarly commentary papers (like Bob Kaplan's plenary address) are not
submitted to TAR because of the general perception among the AAA membership
that such submissions do not have a snowball's chance in Hell of being
accepted unless they are also accountics science papers.
It's a waste of time and money to submit papers to TAR that are not
accountics science papers.
In spite of differences of opinion, I do thank you for the years of
blood, sweat, and tears that you gave us as Senior Editor of TAR.
And I wish you and all U.S. subscribers to the AECM a very Happy
Thanksgiving. Special thanks to Barry and Julie and the AAA staff for
keeping the AECM listserv up and running.
Respectfully,
Bob Jensen
Linda Bamber is a former editor of TAR and was greatly aided in this
effort by her husband.
The BAMBERs Illustration
Years back I
was responsible for an afternoon workshop and enjoyed the privilege to sit
in on the tail end of the morning workshop on journal editing conducted by
Linda and Mike Bamber. At the time Linda was Senior Editor of The
Accounting Review.
I have great respect for both Linda and Mike, and my criticism here applies
to the editorial policies of the American Accounting Association and other
publishers of top accounting research journals. In no way am I criticizing
Linda and Mike for the huge volunteer effort that both of them are giving to
The Accounting Review (TAR).
Mike’s presentation focused upon a recent publication in TAR based upon a
behavioral experiment using 25 auditors. Mike greatly praised the research
and the article’s write up. My question afterwards was whether TAR would
accept a replication study or publish and abstract of a replication that
confirmed the outcomes published original TAR publication. The answer was
absolutely NO! One subsequent TAR
editor even told me it would be confusing of the replication contradicted
the original study.
Now think of the absurdity of the above policy on publishing at least
commentary abstracts of replications. Scientists would shake their heads and
snicker at accounting research. No scientific experiment is considered
worthy until it has been independently replicated multiple times. Science
professors thus have an advantage over accounting professors in playing the
“journal hits” game for promotion and tenure, because their top journals
will publish replications. Scientists are constantly seeking truth and
challenging whether it’s really the truth.
Thus I come to my main point that is far beyond the co-authorship issue that
stimulated this message. My main point is that in academic accounting
research publishing, we are more concerned with the cleverness of the
research than in the “truth” of the findings themselves.
Have I become too much of a cynic in my old age? Except in a limited number
of capital markets events studies, have accounting researchers published
replications due to genuine interest by the public in whether the earlier
findings hold true? Or do we hold the findings as self-evident on the basis
of one published study with as few as 25 experimental participants? Or is
there any interest in the findings themselves to the general public apart
from interest in the methods and techniques of interest to researchers
themselves?
Accounting Research Versus Social Science Research
It is more common in the social sciences, relative to natural
sciences, to publish studies that are unreplicated. However, lack of replication
is often addressed more openly the articles themselves and in and stated as a
limitation relative to business and accounting empirical research.
"New Center Hopes to Clean Up Sloppy Science and Bogus Research," by
Tom Bartlett, Chronicle of Higher Education, March 6, 2013 ---
http://chronicle.com/article/New-Center-Hopes-to-Clean-Up/137683/
Something is wrong with science, or at least with
how science is often done. Flashy research in prestigious journals later
proves to be bogus. Researchers have built careers on findings that are
dubious or even turn out to be fraudulent. Much of the conversation about
that trend has focused on flaws in social psychology, but the problem is not
confined to a single field. If you keep up with the latest retractions and
scandals, it's hard not to wonder how much research is trustworthy.
But Tuesday might just be a turning point. A new
organization, called the
Center for Open
Science, is opening its doors in an attempt to
harness and focus a growing movement to clean up science. The center's
organizers don't put it quite like that; they say the center aims to "build
tools to improve the scientific process and promote accurate, transparent
findings in scientific research." Now, anybody with an idea and some
chutzpah can start a center. But what makes this effort promising is that it
has some real money behind it: The center has been given $5.25-million by
the Laura and John Arnold Foundation to help get started.
It's also promising because a co-director of the
center is Brian Nosek, an associate professor of psychology at the
University of Virginia (the other director is a Virginia graduate student,
Jeffrey Spies). Mr. Nosek is the force behind the
Reproducibility Project, an effort to replicate
every study from three psychology journals published in 2008, in an attempt
to gauge how much published research might actually be baseless.
Mr. Nosek is one of a number of strong voices in
psychology arguing for more transparency and accountability. But up until
now there hasn't been an organization solely devoted to solving those
problems. "This gives real backing to show that this is serious and that we
can really put the resources behind it to do it right," Mr. Nosek said.
"This whole movement, if it is a movement, has gathered sufficient steam to
actually come to this."
'Rejigger Those
Incentives'
So what exactly will the center do? Some of that
grant money will go to finance the Reproducibility Project and to further
develop the
Open Science
Framework, which already allows scientists to
share and store findings and hypotheses. More openness is intended to
combat, among other things, the so-called file-drawer effect, in which
scientists publish their successful experiments while neglecting to mention
their multiple flubbed attempts, giving a false impression of a finding's
robustness.
The center hopes to encourage scientists to
"register" their hypotheses before they carry out experiments, a procedure
that should help keep them honest. And the center is working with journals,
like Perspectives on Psychological Science, to publish the results
of experiments even if they don't pan out the way the researchers hoped.
Scientists are "reinforced for publishing, not for getting it right in the
current incentives," Mr. Nosek said. "We're working to rejigger those
incentives."
Mr. Nosek and his compatriots didn't solicit funds
for the center. Foundations have been knocking on their door. The Arnold
Foundation sought out Mr. Nosek because of a concern about whether the
research that's used to make policy decisions is really reliable.
"It doesn't benefit anyone if the publications that
get out there are in any way skewed toward the sexy results that might be a
fluke, as opposed to the rigorous replication and testing of ideas," said
Stuart Buck, the foundation's director of research.
Other foundations have been calling too. With more
grants likely to be on the way, Mr. Nosek thinks the center will have
$8-million to $10-million in commitments before writing a grant proposal.
The goal is an annual budget of $3-million. "There are other possibilities
that we might be able to grow more dramatically than that," Mr. Nosek said.
"It feels like it's raining money. It's just ridiculous how much interest
there is in these issues."
Continued in article
Jensen Comment
Accountics scientists set a high bar because they replicate virtually all their
published research.
Yeah Right!
Accountics science journals like The Accounting Review have referees that
discourage replications by refusing to publish them. They won't even publish
commentaries that question the outcomes ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
Accountics science researchers won't even discuss their work on the AAA
Commons ---
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
Robustness Issues
Robust Statistics ---
http://en.wikipedia.org/wiki/Robust_statistics
"ECONOMICS AS ROBUSTNESS ANALYSIS," by Jaakko Kuorikoski, Aki Lehtinen
and Caterina Marchionn, he University of Pittsburgh, 2007 ---
http://philsci-archive.pitt.edu/3550/1/econrobu.pdf
ECONOMICS AS ROBUSTNESS ANALYSIS
Jaakko Kuorikoski, Aki Lehtinen and Caterina
Marchionni
25.9. 2007
1. Introduction
.....................................................................................................................
1
2. Making sense of
robustness............................................................................................
4
3. Robustness in
economics................................................................................................
6
4. The epistemic import of robustness
analysis.................................................................
8
5. An illustration: geographical economics models
........................................................ 13
6. Independence of
derivations.........................................................................................
18
7. Economics as a Babylonian science
............................................................................
23
8. Conclusions
...................................................................................................................
1.Introduction
Modern economic analysis consists largely in building abstract
mathematical models and deriving familiar results from ever sparser
modeling assumptions is considered as a theoretical contribution. Why do
economists spend so much time and effort in deriving same old results
from slightly different assumptions rather than trying to come up with
new and exciting hypotheses? We claim that this is because the process
of refining economic models is essentially a form of robustness
analysis. The robustness of modeling results with respect to particular
modeling assumptions, parameter values or initial conditions plays a
crucial role for modeling in economics for two reasons. First, economic
models are difficult to subject to straightforward empirical tests for
various reasons. Second, the very nature of economic phenomena provides
little hope of ever making the modeling assumptions completely
realistic. Robustness analysis is therefore a natural methodological
strategy for economists because economic models are based on various
idealizations and abstractions which make at least some of their
assumptions unrealistic (Wimsatt 1987; 1994a; 1994b; Mäki 2000; Weisberg
2006b). The importance of robustness considerations in economics
ultimately forces us to reconsider many commonly held views on the
function and logical structure of economic theory.
Given that much of economic research praxis can
be characterized as robustness analysis, it is somewhat surprising that
philosophers of economics have only recently become interested in
robustness. William Wimsatt has extensively discussed robustness
analysis, which he considers in general terms as triangulation via
independent ways of determination . According to Wimsatt, fairly varied
processes or activities count as ways of determination: measurement,
observation, experimentation, mathematical derivation etc. all qualify.
Many ostensibly different epistemic activities are thus classified as
robustness analysis. In a recent paper, James Woodward (2006)
distinguishes four notions of robustness. The first three are all
species of robustness as similarity of the result under different forms
of determination. Inferential robustness refers to the idea that there
are different degrees to which inference from some given data may depend
on various auxiliary assumptions, and derivational robustness to whether
a given theoretical result depends on the different modelling
assumptions. The difference between the two is that the former concerns
derivation from data, and the latter derivation from a set of
theoretical assumptions. Measurement robustness means triangulation of a
quantity or a value by (causally) different means of measurement.
Inferential, derivational and measurement robustness differ with respect
to the method of determination and the goals of the corresponding
robustness analysis. Causal robustness, on the other hand, is a
categorically different notion because it concerns causal dependencies
in the world, and it should not be confused with the epistemic notion of
robustness under different ways of determination.
In Woodward’s typology, the kind of theoretical
model-refinement that is so common in economics constitutes a form of
derivational robustness analysis. However, if Woodward (2006) and Nancy
Cartwright (1991) are right in claiming that derivational robustness
does not provide any epistemic credence to the conclusions, much of
theoretical model- building in economics should be regarded as
epistemically worthless. We take issue with this position by developing
Wimsatt’s (1981) account of robustness analysis as triangulation via
independent ways of determination. Obviously, derivational robustness in
economic models cannot be a matter of entirely independent ways of
derivation, because the different models used to assess robustness
usually share many assumptions. Independence of a result with respect to
modelling assumptions nonetheless carries epistemic weight by supplying
evidence that the result is not an artefact of particular idealizing
modelling assumptions. We will argue that although robustness analysis,
understood as systematic examination of derivational robustness, is not
an empirical confirmation procedure in any straightforward sense,
demonstrating that a modelling result is robust does carry epistemic
weight by guarding against error and by helping to assess the relative
importance of various parts of theoretical models (cf. Weisberg 2006b).
While we agree with Woodward (2006) that arguments presented in favour
of one kind of robustness do not automatically apply to other kinds of
robustness, we think that the epistemic gain from robustness derives
from similar considerations in many instances of different kinds of
robustness.
In contrast to physics, economic theory itself
does not tell which idealizations are truly fatal or crucial for the
modeling result and which are not. Economists often proceed on a
preliminary hypothesis or an intuitive hunch that there is some core
causal mechanism that ought to be modeled realistically. Turning such
intuitions into a tractable model requires making various unrealistic
assumptions concerning other issues. Some of these assumptions are
considered or hoped to be unimportant, again on intuitive grounds. Such
assumptions have been examined in economic methodology using various
closely related terms such as Musgrave’s (1981) heuristic assumptions,
Mäki’s (2000) early step assumptions, Hindriks’ (2006) tractability
assumptions and Alexandrova’s (2006) derivational facilitators. We will
examine the relationship between such assumptions and robustness in
economic model-building by way of discussing a case: geographical
economics. We will show that an important way in which economists try to
guard against errors in modeling is to see whether the model’s
conclusions remain the same if some auxiliary assumptions, which are
hoped not to affect those conclusions, are changed. The case also
demonstrates that although the epistemological functions of guarding
against error and securing claims concerning the relative importance of
various assumptions are somewhat different, they are often closely
intertwined in the process of analyzing the robustness of some modeling
result.
. . .
8. Conclusions
The practice of economic theorizing largely consists of building models with
slightly different assumptions yielding familiar results. We have argued
that this practice makes sense when seen as derivational robustness
analysis. Robustness analysis is a sensible epistemic strategy in situations
where we know that our assumptions and inferences are fallible, but not in
what situations and in what way. Derivational robustness analysis guards
against errors in theorizing when the problematic parts of the ways of
determination, i.e. models, are independent of each other. In economics in
particular, proving robust theorems from different models with diverse
unrealistic assumptions helps us to evaluate what results correspond to
important economic phenomena and what are merely artefacts of particular
auxiliary assumptions. We have addressed Orzack and Sober’s criticism
against robustness as an epistemically relevant feature by showing that
their formulation of the epistemic situation in which robustness analysis is
useful is misleading. We have also shown that their argument actually shows
how robustness considerations are necessary for evaluating what a given
piece of data can support. We have also responded to Cartwright’s criticism
by showing that it relies on an untenable hope of a completely true economic
model.
Viewing economic model building as robustness
analysis also helps to make sense of the role of the rationality axioms that
apparently provide the basis of the whole enterprise. Instead of the
traditional Euclidian view of the structure of economic theory, we propose
that economics should be approached as a Babylonian science, where the
epistemically secure parts are the robust theorems and the axioms only form
what Boyd and Richerson call a generalized sample theory, whose the role is
to help organize further modelling work and facilitate communication between
specialists.
Jensen Comment
As I've mentioned before I spent a goodly proportion of my time for two years in
a think tank trying to invent adaptive regression and cluster analysis models.
In every case the main reasons for my failures were lack of robustness. In
particular, if any two models feeding in predictor variables w, x, y, and z
generated different outcomes that were not robust in terms of the time ordering
of the variables feeding into the algorithms. This made the results dependent of
dynamic programming which has rarely been noted for computing practicality ---
http://en.wikipedia.org/wiki/Dynamic_programming
Appeal for a "Daisy Chain of Replication"
"Nobel laureate challenges psychologists to clean up their act:
Social-priming research needs “daisy chain” of replication," by Ed Yong,
Nature, October 3, 2012 ---
http://www.nature.com/news/nobel-laureate-challenges-psychologists-to-clean-up-their-act-1.11535
Nobel prize-winner Daniel Kahneman has issued a
strongly worded call to one group of psychologists to restore the
credibility of their field by creating a replication ring to check each
others’ results.
Kahneman, a psychologist at Princeton University in
New Jersey, addressed his
open e-mail to researchers who work on social
priming, the study of how subtle cues can unconsciously influence our
thoughts or behaviour. For example, volunteers might walk more slowly down a
corridor after seeing words related to old age1,
or fare better in general-knowledge tests after writing down the attributes
of a typical professor2.
Such tests are widely used in psychology, and
Kahneman counts himself as a “general believer” in priming effects. But in
his e-mail, seen by Nature, he writes that there is a “train wreck
looming” for the field, due to a “storm of doubt” about the robustness of
priming results.
Under fire
This scepticism has been fed by failed attempts to
replicate classic priming studies, increasing concerns about replicability
in psychology more broadly (see 'Bad
Copy'), and the exposure of fraudulent social
psychologists such as Diederik Stapel, Dirk Smeesters and Lawrence Sanna,
who used priming techniques in their work.
“For all these reasons, right or wrong, your field
is now the poster child for doubts about the integrity of psychological
research,” Kahneman writes. “I believe that you should collectively do
something about this mess.”
Kahneman’s chief concern is that graduate students
who have conducted priming research may find it difficult to get jobs after
being associated with a field that is being visibly questioned.
“Kahneman is a hard man to ignore. I suspect that
everybody who got a message from him read it immediately,” says Brian Nosek,
a social psychologist at the University of Virginia in Charlottesville.David
Funder, at the University of California, Riverside, and president-elect of
the Society for Personality and Social Psychology, worries that the debate
about priming has descended into angry defensiveness rather than a
scientific discussion about data. “I think the e-mail hits exactly the right
tone,” he says. “If this doesn’t work, I don’t know what will.”
Hal Pashler, a cognitive psychologist at the
University of California, San Diego, says that several groups, including his
own, have already tried to replicate well-known social-priming findings, but
have not been able to reproduce any of the effects. “These are quite simple
experiments and the replication attempts are well powered, so it is all very
puzzling. The field needs to get to the bottom of this, and the quicker the
better.”
Chain of replication
To address this problem, Kahneman recommends that
established social psychologists set up a “daisy chain” of replications.
Each lab would try to repeat a priming effect demonstrated by its neighbour,
supervised by someone from the replicated lab. Both parties would record
every detail of the methods, commit beforehand to publish the results, and
make all data openly available.
Kahneman thinks that such collaborations are
necessary because priming effects are subtle, and could be undermined by
small experimental changes.
Norbert Schwarz, a social psychologist at the
University of Michigan in Ann Arbor who received the e-mail, says that
priming studies attract sceptical attention because their results are often
surprising, not necessarily because they are scientifically flawed.. “There
is no empirical evidence that work in this area is more or less replicable
than work in other areas,” he says, although the “iconic status” of
individual findings has distracted from a larger body of supportive
evidence.
“You can think of this as psychology’s version of
the climate-change debate,” says Schwarz. “The consensus of the vast
majority of psychologists closely familiar with work in this area gets
drowned out by claims of a few persistent priming sceptics.”
Still, Schwarz broadly supports Kahneman’s
suggestion. “I will participate in such a daisy-chain if the field decides
that it is something that should be implemented,” says Schwarz, but not if
it is “merely directed at one single area of research”.
Continued in article
The lack of validation is an enormous problem in accountics science, but the
saving grace is that nobody much cares
574 Shields Against Validity Challenges in Plato's Cave ---
See Below
Why Even Renowned Scientists Need to Have Their Research Independently
Replicated
"Author on leave after Harvard inquiry Investigation of scientist’s work
finds evidence of misconduct, prompts retraction by journal," by Carolyn Y.
Johnson, The Boston Globe, August 10, 2010 ---
http://www.boston.com/news/education/higher/articles/2010/08/10/author_on_leave_after_harvard_inquiry/
Harvard University psychologist Marc Hauser — a
well-known scientist and author of the book “Moral Minds’’ — is taking a
year-long leave after a lengthy internal investigation found evidence of
scientific misconduct in his laboratory.
The findings have resulted in the retraction of an
influential study that he led. “MH accepts responsibility for the error,’’
says the retraction of the study on whether monkeys learn rules, which was
published in 2002 in the journal Cognition.
Two other journals say they have been notified of
concerns in papers on which Hauser is listed as one of the main authors.
It is unusual for a scientist as prominent as
Hauser — a popular professor and eloquent communicator of science whose work
has often been featured on television and in newspapers — to be named in an
investigation of scientific misconduct. His research focuses on the
evolutionary roots of the human mind.
In a letter Hauser wrote this year to some Harvard
colleagues, he described the inquiry as painful. The letter, which was shown
to the Globe, said that his lab has been under investigation for three years
by a Harvard committee, and that evidence of misconduct was found. He
alluded to unspecified mistakes and oversights that he had made, and said he
will be on leave for the upcoming academic year.
In an e-mail yesterday, Hauser, 50, referred
questions to Harvard. Harvard spokesman Jeff Neal declined to comment on
Hauser’s case, saying in an e-mail, “Reviews of faculty conduct are
considered confidential.’’
“Speaking in general,’’ he wrote, “we follow a well
defined and extensive review process. In cases where we find misconduct has
occurred, we report, as appropriate, to external agencies (e.g., government
funding agencies) and correct any affected scholarly record.’’
Much remains unclear, including why the
investigation took so long, the specifics of the misconduct, and whether
Hauser’s leave is a punishment for his actions.
The retraction, submitted by Hauser and two
co-authors, is to be published in a future issue of Cognition, according to
the editor. It says that, “An internal examination at Harvard University . .
. found that the data do not support the reported findings. We therefore are
retracting this article.’’
The paper tested cotton-top tamarin monkeys’
ability to learn generalized patterns, an ability that human infants had
been found to have, and that may be critical for learning language. The
paper found that the monkeys were able to learn patterns, suggesting that
this was not the critical cognitive building block that explains humans’
ability to learn language. In doing such experiments, researchers videotape
the animals to analyze each trial and provide a record of their raw data.
The work was funded by Harvard’s Mind, Brain, and
Behavior program, the National Science Foundation, and the National
Institutes of Health. Government spokeswomen said they could not confirm or
deny whether an investigation was underway.
The findings have resulted in the retraction of an
influential study that he led. “MH accepts responsibility for the error,’’
says the retraction of the study on whether monkeys learn rules, which was
published in 2002 in the journal Cognition.
Two other journals say they have been notified of
concerns in papers on which Hauser is listed as one of the main authors.
It is unusual for a scientist as prominent as
Hauser — a popular professor and eloquent communicator of science whose work
has often been featured on television and in newspapers — to be named in an
investigation of scientific misconduct. His research focuses on the
evolutionary roots of the human mind.
In a letter Hauser wrote this year to some Harvard
colleagues, he described the inquiry as painful. The letter, which was shown
to the Globe, said that his lab has been under investigation for three years
by a Harvard committee, and that evidence of misconduct was found. He
alluded to unspecified mistakes and oversights that he had made, and said he
will be on leave for the upcoming academic year.
In an e-mail yesterday, Hauser, 50, referred
questions to Harvard. Harvard spokesman Jeff Neal declined to comment on
Hauser’s case, saying in an e-mail, “Reviews of faculty conduct are
considered confidential.’’
“Speaking in general,’’ he wrote, “we follow a well
defined and extensive review process. In cases where we find misconduct has
occurred, we report, as appropriate, to external agencies (e.g., government
funding agencies) and correct any affected scholarly record.’’
Much remains unclear, including why the
investigation took so long, the specifics of the misconduct, and whether
Hauser’s leave is a punishment for his actions.
The retraction, submitted by Hauser and two
co-authors, is to be published in a future issue of Cognition, according to
the editor. It says that, “An internal examination at Harvard University . .
. found that the data do not support the reported findings. We therefore are
retracting this article.’’
The paper tested cotton-top tamarin monkeys’
ability to learn generalized patterns, an ability that human infants had
been found to have, and that may be critical for learning language. The
paper found that the monkeys were able to learn patterns, suggesting that
this was not the critical cognitive building block that explains humans’
ability to learn language. In doing such experiments, researchers videotape
the animals to analyze each trial and provide a record of their raw data.
The work was funded by Harvard’s Mind, Brain, and
Behavior program, the National Science Foundation, and the National
Institutes of Health. Government spokeswomen said they could not confirm or
deny whether an investigation was underway.
Gary Marcus, a psychology professor at New York
University and one of the co-authors of the paper, said he drafted the
introduction and conclusions of the paper, based on data that Hauser
collected and analyzed.
“Professor Hauser alerted me that he was concerned
about the nature of the data, and suggested that there were problems with
the videotape record of the study,’’ Marcus wrote in an e-mail. “I never
actually saw the raw data, just his summaries, so I can’t speak to the exact
nature of what went wrong.’’
The investigation also raised questions about two
other papers co-authored by Hauser. The journal Proceedings of the Royal
Society B published a correction last month to a 2007 study. The correction,
published after the British journal was notified of the Harvard
investigation, said video records and field notes of one of the co-authors
were incomplete. Hauser and a colleague redid the three main experiments and
the new findings were the same as in the original paper.
Science, a top journal, was notified of the Harvard
investigation in late June and told that questions about record-keeping had
been raised about a 2007 paper in which Hauser is the senior author,
according to Ginger Pinholster, a journal spokeswoman. She said Science has
requested Harvard’s report of its investigation and will “move with utmost
efficiency in light of the seriousness of issues of this type.’’
Colleagues of Hauser’s at Harvard and other
universities have been aware for some time that questions had been raised
about some of his research, and they say they are troubled by the
investigation and forthcoming retraction in Cognition.
“This retraction creates a quandary for those of us
in the field about whether other results are to be trusted as well,
especially since there are other papers currently being reconsidered by
other journals as well,’’ Michael Tomasello, co-director of the Max Planck
Institute for Evolutionary Anthropology in Leipzig, Germany, said in an
e-mail. “If scientists can’t trust published papers, the whole process
breaks down.’’
This isn’t the first time Hauser’s work has been
challenged.
In 1995, he was the lead author of a paper in the
Proceedings of the National Academy of Sciences that looked at whether
cotton-top tamarins are able to recognize themselves in a mirror.
Self-recognition was something that set humans and other primates, such as
chimpanzees and orangutans, apart from other animals, and no one had shown
that monkeys had this ability.
Gordon G. Gallup Jr., a professor of psychology at
State University of New York at Albany, questioned the results and requested
videotapes that Hauser had made of the experiment.
“When I played the videotapes, there was not a
thread of compelling evidence — scientific or otherwise — that any of the
tamarins had learned to correctly decipher mirrored information about
themselves,’’ Gallup said in an interview.
In 1997, he co-authored a critique of the original
paper, and Hauser and a co-author responded with a defense of the work.
In 2001, in a study in the American Journal of
Primatology, Hauser and colleagues reported that they had failed to
replicate the results of the previous study. The original paper has never
been retracted or corrected.
Continued in article
“There is a difference between breaking the
rules and breaking the most sacred of all rules,” said Jonathan Haidt, a moral
psychologist at the University of Virginia. The failure to have performed a
reported control experiment would be “a very serious and perhaps unforgivable
offense,” Dr. Haidt said.
"Harvard Researcher May Have Fabricated Data," by Nicholas Wace,
The New York Times, August 27, 2010 ---
http://www.nytimes.com/2010/08/28/science/28harvard.html?_r=1&hpw
Harvard authorities have made available information
suggesting that Marc Hauser, a star researcher who was put on leave this
month, may have fabricated data in a 2002 paper.
“Given the published design of the experiment, my
conclusion is that the control condition was fabricated,” said Gerry Altmann,
the editor of the journal Cognition, in which the experiment was published.
Dr. Hauser said he expected to have a statement
about the Cognition paper available soon. He
issued a statement last week saying he was “deeply
sorry” and acknowledged having made “significant mistakes” but did not admit
to any scientific misconduct.
Dr. Hauser is a leading expert in comparing animal
and human mental processes and recently wrote a well-received book, “Moral
Minds,” in which he explored the evolutionary basis of morality. An inquiry
into his Harvard lab was opened in 2007 after students felt they were being
pushed to reach a particular conclusion that they thought was incorrect.
Though the inquiry was completed in January this year, Harvard announced
only last week that Dr. Hauser had been required to retract the Cognition
article, and it supplied no details about the episode.
On Friday, Dr. Altmann said Michael D. Smith, dean
of the Faculty of Arts and Sciences, had given him a summary of the part of
the confidential faculty inquiry related to the 2002 experiment, a test of
whether monkeys could distinguish algebraic rules.
The summary included a description of a videotape
recording the monkeys’ reaction to a test stimulus. Standard practice is to
alternate a stimulus with a control condition, but no tests of the control
condition are present on the videotape. Dr. Altmann, a psychologist at the
University of York in England, said it seemed that the control experiments
reported in the article were not performed.
Some forms of scientific error, like poor record
keeping or even mistaken results, are forgivable, but fabrication of data,
if such a charge were to be proved against Dr. Hauser, is usually followed
by expulsion from the scientific community.
“There is a difference between breaking the rules
and breaking the most sacred of all rules,” said Jonathan Haidt, a moral
psychologist at the
University of Virginia. The failure to have
performed a reported control experiment would be “a very serious and perhaps
unforgivable offense,” Dr. Haidt said.
Dr. Hauser’s case is unusual, however, because of
his substantial contributions to the fields of animal cognition and the
basis of morality. Dr. Altmann held out the possibility of redemption. “If
he were to give a full and frank account of the errors he made, then the
process can start of repatriating him into the community in some form,” he
said.
Dr. Hauser’s fall from grace, if it occurs, could
cast a shadow over several fields of research until Harvard makes clear the
exact nature of the problems found in his lab. Last week, Dr. Smith, the
Harvard dean, wrote in a
letter to the faculty that he had found Dr. Hauser
responsible for eight counts of scientific misconduct. He described these in
general terms but did not specify fabrication. An oblique sentence in his
letter said that the Cognition paper had been retracted because “the data
produced in the published experiments did not support the published
findings.”
Scientists trying to assess Dr. Hauser’s oeuvre are
likely to take into account another issue besides the eight counts of
misconduct. In 1995, Dr. Hauser published that cotton-top tamarins, the
monkey species he worked with, could recognize themselves in a mirror. The
finding was challenged by the psychologist Gordon Gallup, who asked for the
videotapes and has said that he could see no evidence in the monkey’s
reactions for what Dr. Hauser had reported. Dr. Hauser later wrote in
another paper that he could not repeat the finding.
The small size of the field in which Dr. Hauser
worked has contributed to the uncertainty. Only a handful of laboratories
have primate colonies available for studying cognition, so few if any
researchers could check Dr. Hauser’s claims.
“Marc was the only person working on cotton-top
tamarins so far as I know,” said Alison Gopnik, a psychologist who studies
infant cognition at the
University of California, Berkeley. “It’s always a
problem in science when we have to depend on one person.”
Many of Dr. Hauser’s experiments involved taking
methods used to explore what infants are thinking and applying them to
monkeys. In general, he found that the monkeys could do many of the same
things as infants. If a substantial part of his work is challenged or
doubted, monkeys may turn out to be less smart than recently portrayed.
But his work on morality involved humans and is
therefore easier for others to repeat. And much of Dr. Hauser’s morality
research has checked out just fine, Dr. Haidt said.
“Hauser has been particularly creative in studying
moral psychology in diverse populations, including small-scale societies,
patients with brain damage, psychopaths and people with rare genetic
disorders that affect their judgments,” he said.
Criticisms of the Doubters: Missing Data is Not Necessarily Scientific
Misconduct
"Difficulties in Defining Errors in Case Against Harvard Researcher," by
Nicholas Wade, The New York Times, October 25, 2010 ---
http://www.nytimes.com/2010/10/26/science/26hauser.html?_r=1&hpw
Jensen Comment
Hauser's accusers backed off slightly. It would seem that the best scientific
evidence would be for independent researchers to collect new data and try to
replicate Hauser's claims.
We must keep in mint that Hauser himself retracted one of his own scientific
journal articles.
Why did Harvard take three years on this one?
http://chronicle.com/blogPost/HauserHarvard/26308/
Bob Jensen's threads on Professors Who Cheat are at
http://faculty.trinity.edu/rjensen/Plagiarism.htm#ProfessorsWhoPlagiarize
Also see
http://faculty.trinity.edu/rjensen/TheoryTAR.htm#SocialScience
August 21, 2010 reply from Orenstein, Edith
[eorenstein@FINANCIALEXECUTIVES.ORG]
I believe a
broad lesson arises from the tale of Professor Hauser's monkey-business:
"It
is
unusual
for a scientist as
prominent
as Hauser - a
popular
professor and
eloquent communicator of
science whose work has often been featured on television and in newspapers
- to be named in an
investigation
of scientific
misconduct."
Disclaimer: this
is my personal opinion only,
and I believe these lessons apply to all professions, but since this is an
accounting listserv, lesson 1 with respect to accounting/auditing
research is:
1.
even the most
prominent, popular, and eloquent
communicator professors'
research, including but not limited to the field of accounting, and
including for purposes of standard-setting, rule-making, et al, should not
be above third party review and questioning (that may be the layman's
term; the technical term I assume is 'replication'). Although it can be
difficult for less prominent, popular, eloquent communicators to raise such
challenges, without fear of reprisal, it is important to get as close to the
'truth' or 'truths' as may (or may not) exist. This point applies not only
to formal, refereed journals, but non-refereed published research in any
form as well.
And, from the world of accounting
& auditing practice, (or any job, really), the lesson is the same:
2.
even the most
prominent, popular, and eloquent
communicator(s) -
e.g. audit clients....should
not be above third party review and questioning; once again, it can be
difficult for less prominent, popular, and eloquent communicators (internal
or external audit staff, whether junior or senior staff) to raise challenges
in the practice of auditing in the field (which is why staffing decisions,
supervision, and backbone are so important). And we have seen examples where
such challenges were met with reprisal or challenge (e.g. Cynthia Cooper
challenging WorldCom's accounting; HealthSouth's Richard Scrushy, the Enron
- Andersen saga, etc.)
Additionally, another lesson here, (I repeat
this is my personal opinion only)
is that in
the field of standard-setting or rulemaking, testimony of 'prominent'
experts and 'eloquent communicators'
should be judged on the basis of substance
vs. form, and others
(i.e. those who may feel less 'prominent' or 'eloquent') should step up to
the plate to offer concurring or counterarguments in verbal or written form
(including comment letters) if
their experience or thought process leads them to the same conclusion as the
more 'prominent' or 'eloquent' speakers/writers - or in particular, if it
leads them to another view.
I wonder sometimes, particularly
in public hearings, if individuals testifying believe there is
implied pressure to say what one thinks the sponsor of the hearing expects
or wants to hear, vs. challenging the status quo, particular proposed
changes, etc., particularly if they may fear reprisal. Once again, it is
important to provide the facts as one sees them, and it is about substance
vs. form; sometimes difficult to achieve.
Edith Orenstein
www.financialexecutives.org/blog
"Harvard Clarifies Wrongdoing by Professor," Inside Higher Ed,
August 23, 2010 ---
http://www.insidehighered.com/news/2010/08/23/qt#236200
Harvard University announced Friday that its
investigations had found eight incidents of scientific misconduct by Marc
Hauser, a prominent psychology professor who recently started a leave,
The Boston Globe reported. The university
also indicated that sanctions had been imposed, and that Hauser would be
teaching again after a year. Since the Globe reported on Hauser's
leave and the inquiry into his work, many scientists have called for a
statement by the university on what happened, and Friday's announcement goes
much further than earlier statements. In a statement sent to colleagues on
Friday, Hauser said: "I am deeply sorry for the problems this case has
caused to my students, my colleagues, and my university. I acknowledge that
I made some significant mistakes and I am deeply disappointed that this has
led to a retraction and two corrections. I also feel terrible about the
concerns regarding the other five cases."
Why did Harvard take three years on this one?
http://chronicle.com/blogPost/HauserHarvard/26308/
Bob Jensen's threads on this cheating scandal are at
http://faculty.trinity.edu/rjensen/TheoryTAR.htm#SocialScience
Bob Jensen's threads on Professors Who Cheat are at
http://faculty.trinity.edu/rjensen/Plagiarism.htm#ProfessorsWhoPlagiarize
Fabricated Data at Least 145 times
"UConn Investigation Finds That Health Researcher Fabricated Data." by Tom
Bartlett, Inside Higher Ed, January 11, 2012 ---
http://chronicle.com/blogs/percolator/uconn-investigation-finds-that-health-researcher-fabricated-data/28291
Jensen Comment
I knew of a few instances of plagiarism, but not once has it been discovered
that an accountics scientist fabricated data. This could, however, be due to
accountics scientists shielding each other from validity testing ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
National Center for Case Study Teaching in Science ---
http://sciencecases.lib.buffalo.edu/cs/
August 10, 2010 reply from Jagdish Gangolly
[gangolly@CSC.ALBANY.EDU]
Bob,
This is a classic example that shows how difficult
it is to escape accountability in science. First, when Gordon Gallup, a
colleague in our Bio-Psychology in Albany questioned the results, at first
Hauser tried to get away with a reply because Albany is not Harvard. But
then when Hauser could not replicate the experiment he had no choice but to
confess, unless he was willing to be caught some time in the future with his
pants down.
However, in a sneaky way, the confession was sent
by Hauser to a different journal. But Hauser at least had the gumption to
confess.
The lesson I learn from this episode is to do
something like what lawyers always do in research. They call it Shepardizing.
It is important not to take any journal article at its face value, even if
the thing is in a journal as well known as PNAS and by a person from a
school as well known as Harvard. The other lesson is not to ignore a work or
criticism even if it appears in a lesser known journal and is by an author
from a lesser known school (as in Albany in this case).
Jagdish -- J
agdish Gangolly (gangolly@albany.edu)
Department of Informatics College of Computing &
Information
State University of New York at Albany 7A, Harriman Campus Road, Suite 220
Albany, NY 12206
August 10, 2010 message from Paul Williams
[Paul_Williams@NCSU.EDU]
Bob and Jagdish,
This also illustrates the necessity of keeping records of experiments. How
odd that accounting researchers cannot see the necessity of "keeping a
journal!!!"
"Document Sheds Light on Investigation at Harvard," by Tom Bartlett,
Chronicle of Higher Education, August 19, 2010 ---
http://chronicle.com/article/Document-Sheds-Light-on/123988/
Ever since word got out that a prominent Harvard
University researcher was on leave after an investigation into academic
wrongdoing, a key question has remained unanswered: What, exactly, did he
do?
The researcher himself, Marc D. Hauser, isn't
talking. The usually quotable Mr. Hauser, a psychology professor and
director of Harvard's Cognitive Evolution Laboratory, is the author of Moral
Minds: How Nature Designed Our Universal Sense of Right and Wrong (Ecco,
2006) and is at work on a forthcoming book titled "Evilicious: Why We
Evolved a Taste for Being Bad." He has been voted one of the university's
most popular professors.
Harvard has also been taciturn. The public-affairs
office did issue a brief written statement last week saying that the
university "has taken steps to ensure that the scientific record is
corrected in relation to three articles co-authored by Dr. Hauser." So far,
Harvard officials haven't provided details about the problems with those
papers. Were they merely errors or something worse?
An internal document, however, sheds light on what
was going on in Mr. Hauser's lab. It tells the story of how research
assistants became convinced that the professor was reporting bogus data and
how he aggressively pushed back against those who questioned his findings or
asked for verification.
A copy of the document was provided to The
Chronicle by a former research assistant in the lab who has since left
psychology. The document is the statement he gave to Harvard investigators
in 2007.
The former research assistant, who provided the
document on condition of anonymity, said his motivation in coming forward
was to make it clear that it was solely Mr. Hauser who was responsible for
the problems he observed. The former research assistant also hoped that more
information might help other researchers make sense of the allegations.
It was one experiment in particular that led
members of Mr. Hauser's lab to become suspicious of his research and, in the
end, to report their concerns about the professor to Harvard administrators.
The experiment tested the ability of rhesus monkeys
to recognize sound patterns. Researchers played a series of three tones (in
a pattern like A-B-A) over a sound system. After establishing the pattern,
they would vary it (for instance, A-B-B) and see whether the monkeys were
aware of the change. If a monkey looked at the speaker, this was taken as an
indication that a difference was noticed.
The method has been used in experiments on primates
and human infants. Mr. Hauser has long worked on studies that seemed to show
that primates, like rhesus monkeys or cotton-top tamarins, can recognize
patterns as well as human infants do. Such pattern recognition is thought to
be a component of language acquisition.
Researchers watched videotapes of the experiments
and "coded" the results, meaning that they wrote down how the monkeys
reacted. As was common practice, two researchers independently coded the
results so that their findings could later be compared to eliminate errors
or bias.
According to the document that was provided to The
Chronicle, the experiment in question was coded by Mr. Hauser and a research
assistant in his laboratory. A second research assistant was asked by Mr.
Hauser to analyze the results. When the second research assistant analyzed
the first research assistant's codes, he found that the monkeys didn't seem
to notice the change in pattern. In fact, they looked at the speaker more
often when the pattern was the same. In other words, the experiment was a
bust.
But Mr. Hauser's coding showed something else
entirely: He found that the monkeys did notice the change in pattern—and,
according to his numbers, the results were statistically significant. If his
coding was right, the experiment was a big success.
The second research assistant was bothered by the
discrepancy. How could two researchers watching the same videotapes arrive
at such different conclusions? He suggested to Mr. Hauser that a third
researcher should code the results. In an e-mail message to Mr. Hauser, a
copy of which was provided to The Chronicle, the research assistant who
analyzed the numbers explained his concern. "I don't feel comfortable
analyzing results/publishing data with that kind of skew until we can verify
that with a third coder," he wrote.
A graduate student agreed with the research
assistant and joined him in pressing Mr. Hauser to allow the results to be
checked, the document given to The Chronicle indicates. But Mr. Hauser
resisted, repeatedly arguing against having a third researcher code the
videotapes and writing that they should simply go with the data as he had
already coded it. After several back-and-forths, it became plain that the
professor was annoyed.
"i am getting a bit pissed here," Mr. Hauser wrote
in an e-mail to one research assistant. "there were no inconsistencies! let
me repeat what happened. i coded everything. then [a research assistant]
coded all the trials highlighted in yellow. we only had one trial that
didn't agree. i then mistakenly told [another research assistant] to look at
column B when he should have looked at column D. ... we need to resolve this
because i am not sure why we are going in circles."
The research assistant who analyzed the data and
the graduate student decided to review the tapes themselves, without Mr.
Hauser's permission, the document says. They each coded the results
independently. Their findings concurred with the conclusion that the
experiment had failed: The monkeys didn't appear to react to the change in
patterns.
They then reviewed Mr. Hauser's coding and,
according to the research assistant's statement, discovered that what he had
written down bore little relation to what they had actually observed on the
videotapes. He would, for instance, mark that a monkey had turned its head
when the monkey didn't so much as flinch. It wasn't simply a case of
differing interpretations, they believed: His data were just completely
wrong.
As word of the problem with the experiment spread,
several other lab members revealed they had had similar run-ins with Mr.
Hauser, the former research assistant says. This wasn't the first time
something like this had happened. There was, several researchers in the lab
believed, a pattern in which Mr. Hauser reported false data and then
insisted that it be used.
They brought their evidence to the university's
ombudsman and, later, to the dean's office. This set in motion an
investigation that would lead to Mr. Hauser's lab being raided by the
university in the fall of 2007 to collect evidence. It wasn't until this
year, however, that the investigation was completed. It found problems with
at least three papers. Because Mr. Hauser has received federal grant money,
the report has most likely been turned over to the Office of Research
Integrity at the U.S. Department of Health and Human Services.
The research that was the catalyst for the inquiry
ended up being tabled, but only after additional problems were found with
the data. In a statement to Harvard officials in 2007, the research
assistant who instigated what became a revolt among junior members of the
lab, outlined his larger concerns: "The most disconcerting part of the whole
experience to me was the feeling that Marc was using his position of
authority to force us to accept sloppy (at best) science."
Also see
http://chronicle.com/blogPost/Harvard-Confirms-Hausergate/26198/
The Insignificance of Testing the Null
October 1, 2010 message from Amy Dunbar
Nick Cox posted a link to a statistics paper on
statalist:
2009. Statistics: reasoning on uncertainty, and the
insignificance of testing null. Annales Zoologici Fennici 46: 138-157.
http://www.sekj.org/PDF/anz46-free/anz46-138.pdf
Cox commented that the paper touches provocatively
on several topics often aired on statalist including the uselessness of
dynamite or detonator plots, displays for comparing group means and
especially the over-use of null hypothesis testing. The main target audience
is ecologists but most of the issues cut across statistical science.
Dunbar comment: The paper would be a great addition
to any PhD research seminar. The author also has some suggestions for
journal editors. I included some responses to Nick's original post below.
"Statistics: reasoning on uncertainty, and the insignificance of testing
null," by Esa Läärä
Ann. Zool. Fennici 46: 138–157
ISSN 0003-455X (print), ISSN 1797-2450 (online)
Helsinki 30 April 2009 © Finnish Zoological and Botanical Publishing Board 200
http://www.sekj.org/PDF/anz46-free/anz46-138.pdf
The practice of statistical analysis and inference
in ecology is critically reviewed. The dominant doctrine of null hypothesis
signi fi cance testing (NHST) continues to be applied ritualistically and
mindlessly. This dogma is based on superficial understanding of elementary
notions of frequentist statistics in the 1930s, and is widely disseminated
by influential textbooks targeted at biologists. It is characterized by
silly null hypotheses and mechanical dichotomous division of results being
“signi fi cant” ( P < 0.05) or not. Simple examples are given to demonstrate
how distant the prevalent NHST malpractice is from the current mainstream
practice of professional statisticians. Masses of trivial and meaningless
“results” are being reported, which are not providing adequate quantitative
information of scientific interest. The NHST dogma also retards progress in
the understanding of ecological systems and the effects of management
programmes, which may at worst contribute to damaging decisions in
conservation biology. In the beginning of this millennium, critical
discussion and debate on the problems and shortcomings of NHST has
intensified in ecological journals. Alternative approaches, like basic point
and interval estimation of effect sizes, likelihood-based and information
theoretic methods, and the Bayesian inferential paradigm, have started to
receive attention. Much is still to be done in efforts to improve
statistical thinking and reasoning of ecologists and in training them to
utilize appropriately the expanded statistical toolbox. Ecologists should
finally abandon the false doctrines and textbooks of their previous
statistical gurus. Instead they should more carefully learn what leading
statisticians write and say, collaborate with statisticians in teaching,
research, and editorial work in journals.
Jensen Comment
And to think Alpha (Type 1) error is the easy part. Does anybody ever test for
the more important Beta (Type 2) error? I think some engineers test for Type 2
error with Operating Characteristic (OC) curves, but these are generally applied
where controlled experiments are super controlled such as in quality control
testing.
Beta Error ---
http://en.wikipedia.org/wiki/Beta_error#Type_II_error
THE GENERAL SOCIAL SURVEY ---
http://www.sociology.ohio-state.edu/dbd/Weakley.html
The creator of the General Social Survey (GSS), the
National Opinion Research Center (NORC) was established in 1941. It serves
as the oldest national research facility in the nation that is neither for
profit nor university affiliated. The NORC uses a national probability
sample by using government census information. The GSS was first
administered in 1972, and uses personal interview information of US
households. As stated on the GSS webpage, "The mission of the GSS is to make
timely, high-quality, scientifically relevant data available to the social
science research community" (Internet, 2000)
The NORC prides itself on the GSS’s broad coverage,
its use of replication, its cross-national perspective, and its
attention to data quality. The survey is, as its name explicitly states,
general. The multitude of topics and interests make the GSS a fine tool for
the diversity of contemporary social science research. Replication is an
important component of the GSS. With the repetition of items and item
sequences over time, research can be accomplished that analyzes changes or
stability over time. Since 1982, NORC has had international collaborations
with other research groups. Through the insight of leading specialists and a
"rotating committee of distinguished social scientists," the GSS attempts to
follow the highest survey standards in design, sampling, interviewing,
processing, and documentation
Continued in article
"Using Replication to Help Inform Decisions about Scale-up: Three
Quasi-experiments on a Middle School Unit on Motion and Forces," by Bill
Watson, Curtis Pyke, Sharon Lynch, and Rob Ochsendorf, The George
Washington University, 2008 ---
http://www.gwu.edu/~scale-up/documents/NARST 2007 - Using Replication to Inform
Decisions about S..pdf
Research programs that include
experiments are becoming increasingly important in science education as a
means through which to develop a sound and convincing empirical basis for
understanding the effects of interventions and making evidence-based
decisions about their scale-up of in diverse settings. True experiments,
which are characterized by the random assignment of members of a population
to a treatment or a control group, are considered the “gold standard” in
education research because they reduce the differences between groups to
only random variation and the presence (or absence) of the treatment (Subotnik
& Walberg, 2006)
For researchers, these conditions
increase the likelihood that two samples drawn from the same population are
comparable to each other and to the population, thereby increasing
confidence in causal inferences about effectiveness (Cook & Campbell, 1979).
For practitioners, those making decisions about curriculum and instruction
in schools, the Institute for Educational Sciences at the US Department of
Education (USDOE) suggests that only studies with randomization be
considered as “strong evidence” or “possible evidence” of an intervention’s
effectiveness (Institute for Educational Sciences, 2006).
Quasi-experiments are also a practical
and valid means for the evaluation of interventions when a true experiment
is impractical due to the presence of natural groups, such as classes and
schools, within which students are clustered (Subotnik & Walberg, 2006). In
these circumstances, a Quasi-experiment that includes careful sampling
(e.g., random selection of schools),
a priori
assignment of matched pairs
to a treatment or control group and/or a pretest used to control for any
remaining group differences can often come close to providing the rigor of
true experiment (Subotnik & Walberg, 2006). However, there are inherent
threats to
internal validity in Quasi-experimental designs that the research
must take care to address with supplemental data. Systematic variation
introduced through the clustering of subjects that occurs in
Quasi-experiments can compete with the intervention studied as a cause of
differences observed.
Replications of quasi-experiments can
provide opportunities to adjust procedures to address some threats to the
internal validity of Quasi-experiments and can study new samples to address
external validity concerns. Replications can take many forms and serve a
multitude of purposes (e.g., Hendrick, 1990; Kline, 2003). Intuitively, a
thoughtful choice of replication of a quasi-experimental design can produce
new and improved result or increase the confidence researchers have in the
presence of a treatment effect found in an initial study. Therefore,
replication can be important in establishing the effectiveness of an
intervention when it fosters a sense of robustness in results or enhances
the generalizability of findings from stand-alone
studies (Cohen, 1994; Robinson &
Levin, 1997).
This paper presents data to show the
utility in combining a high quality quasiexperimental design with multiple
replications in school-based scale-up research. Scale-up research is
research charged with producing evidence to inform scale-up decisions;
decisions regarding which innovations can be expected to be effective for
all students in a range of school contexts and settings – “what works best,
for whom, and under what conditions” (Brown, McDonald, & Schneider, 2006, p.
1). Scaling-up by definition is the introduction of interventions whose
efficacy has been established in one context into new settings, with the
goal of producing similarly positive impacts in larger, frequently more
diverse, populations (Brown et al., 2006).
Using Replication
Our work shows that a good first step in scaling-up an intervention is a
series of experiments or quasi-experiments at small scale. Replication in
Educational Research Quasi-experiments are often the most practical research
design for an educational field study, including scale-up studies used to
evaluate whether or not an intervention is worth taking to scale. However,
because they are not true experiments and therefore do not achieve true
randomization, the possibility for systematic error to occur is always
present, and, with it, the risk of threats to internal and external validity
of the study. For the purposes of this discussion, we consider internal
validity to be “the validity with which statements can be made about whether
there is a causal relationship from one variable to another in the form in
which the variables were manipulated or measured” (Cook & Campbell, 1979, p.
38).
External validity refers to “the
approximate validity with which conclusions are drawn about the
generalizability of a causal relationship to and across populations of
persons, settings, and times” (Cook & Campbell, 1979). Unlike replications
with experimental designs, which almost always add to the efficacy of a
sound result, the replication of a quasi-experiment may not have an inherent
value if the potential threats to validity found in the initial study are
not addressed.
Replication: Frameworks
In social
science research, replication of research has traditionally been understood
to be a process in which different researchers repeat a study’s methods
independently with different subjects in different sites and at different
times with the goal of achieving the same results and increasing the
generalizability of findings (Meline & Paradiso, 2003; Thompson, 1996).
However, the process of replication in
social science research in field settings is considerably more nuanced than
this definition might suggest. In field settings, both the intervention and
experimental procedures can be influenced by the local context and sample in
ways that change the nature of the intervention or the experiment, or both
from one experiment to another. Before conducting a replication, an astute
researcher must therefore ask: In what context, with what kinds of subjects,
and by which researchers will the replication be conducted? (Rosenthal,
1990).
The purpose of the replication must
also be considered: Is the researcher interested in making adjustments to
the study procedures or intervention to increase the internal validity of
findings or will the sampling be adjusted to enhance the external validity
of initial results?
A broader view of replication of
field-based quasi-experiments might enable classification of different types
according the multiple purposes for replication when conducting research in
schools. Hendrick (1990) proposed four kinds of replication that take into
account the procedural variables associated with a study and contextual
variables (e.g., subject characteristics, physical setting). Hendrick’s
taxonomy proposes that an
exact replication
adheres as closely
as possible to the original variables and processes in order to replicate
results.
A
partial replication
varies some aspects of either the contextual or
procedural variables, and a
conceptual replication radically
departs from one or more of the procedural variables. Hendrick argued for a
fourth type of replication,
systematic replication,
which includes first a strict replication and then either a partial or
conceptual replication to isolate the original effect and explore the
intervention when new variables are considered.
Rosenthal (1990) referred to such a
succession of replications as a
replication battery:
"The simplest form of replication battery requires two replications of the
original study: one of these replications is as similar as we can make it to
the original study, the other is at least
Using Replication
Moderately dissimilar to the original study" (p. 6). Rosenthal (1990) argued
that if the same results were obtained with similar but not exact
Quasi-experimental procedures, internal validity would be increased because
differences between groups could more likely be attributed to the
intervention of interest and not to experimental procedures. Further, even
if one of the replications is of poorer quality than the others, Rosenthal
argued for its consideration in determining the overall effect of the
intervention, albeit with less weight than more rigorous (presumably
internally valid) replications. More recently, Kline (2003) also
distinguished among several types of replication according to the different
research purposes they address. For example, Kline’s
operational
replications are like Hendrick’s
(1990) exact replication: the sampling and experimental methods of the
original study are repeated to test whether results can be duplicated.
Balanced replications
are akin to
partial and conceptual replications in that they appear to address the
limitations of quasi-experiments by manipulating additional variables to
rule out competing explanations for results.
In a recent call for replication of
studies in educational research, Schneider (2004) also suggested a degree of
flexibility in replication, describing the process as "conducting an
investigation repeatedly with comparable subjects and conditions" (p. 1473)
while also suggesting that it might include making "controllable changes" to
an intervention as part of its replication. Schneider’s (2004) notion of
controllable changes, Kline’s (2003) description of balanced replication,
Hendrick’s (1990) systematic replication, and Rosenthal’s (1990) argument in
favor of the replication battery all suggest that a series of replications
taken together can provide important information about an intervention’s
effectiveness beyond a single Quasiexperiment.
Replication: Addressing Threats to
Internal Validity
When
multiple quasi-experiments (i.e., replications) are conducted with
adjustments, the threats to internal validity inherent in
quasi-experimentation might be more fully addressed (Cook & Campbell, 1979).
Although changing quasi-experiments in the process of replicating them might
decrease confidence in the external validity of an initial study finding,
when a replication battery is considered, a
set
of studies might provide
externally valid data to contribute to decision making within and beyond a
particular school district. The particular threats to internal validity
germane to the studies reported in this paper are those associated with the
untreated control group design with pretest and posttest (Cook & Campbell,
1979). This classic and widely implemented quasi-experimental design
features an observation of participants in two non-randomly assigned groups
before and after one of the groups receives treatment with an intervention
of interest.
The internal validity of a study or
set of studies ultimately depends on the confidence that the researcher has
that differences between groups are caused by the intervention of interest
(Cook & Campbell, 1979). Cook and Campbell (1979) provided considerable
detail about threats to internal validity in quasi-experimentation that
could reduce confidence in claims of causality (p. 37-94). However, they
concluded that the untreated control group design with pretest and posttest
usually controls for all but four threats to internal validity:
selection-maturation, instrumentation, differential regression to the mean,
and local history. Table 1 briefly describes each of these threats. In
addition, they are not mutually exclusive. In a study of the effectiveness
of curriculum materials, for example, the extent to which the researchers
are confident differential regression to the mean is not a threat relies
upon their confidence that sampling methods have produced two samples
similar on performance and demographic variables
Using Replication
(selection-maturation) and that the assessment instrument has similar
characteristics for all subjects (instrumentation). Cook and Campbell (1979)
suggest that replication plays a role in establishing external validity by
presenting the simplest case: An exact replication (Hendrick, 1990) of a
quasiexperiment in which results are corroborated and confidence in internal
validity is high.
However, we argue that the
relationship between replication and validity is more complex, given the
multiple combinations of outcomes that are possible when different kinds of
replications are conducted. Two dimensions of replication seem particularly
important. The first is the consistency of results across replication. The
second is whether a replication addresses internal validity threats that
were not addressed in a previous study (i.e., it
improves upon
the study) or informs the interpretation
of the presence or absence of threats in a prior study (i.e., it
enhances interpretation of
the study).
In an exact replication, results can
either be the same as or different from results in the original
quasi-experiment. If results are different, it seems reasonable to suggest
that some element of the local history - perhaps schools, teachers, or a
cohort of students - could have an effect on the outcomes, in addition to
(or instead of) the effect of an intervention. A partial replication
therefore seems warranted to adjust the quasi-experimental procedures to
address the threats. A partial replication would also be appropriate if the
results are the same, but the researchers do not have confidence that
threats to internal validity have been adequately addressed. Indeed,
conducting partial replications in either of these scenarios is consistent
with the recommendation of Hendrick (1990) to consider results from a
set
of replications when
attempting to determine the effectiveness of an intervention.
Addressing threats to validity with
partial replication, is, in turn, not a straightforward process. What if
results of a partial replication of a quasi-experiment are not the same as
those found in either the original quasi-experiment or its exact
replication? If the partial replication addresses a threat to internal
validity where the original quasi-experiment or its exact replication did
not, then the partial replication improves upon the study, and its results
might be considered the most robust. If threats to internal validity are
still not adequately addressed in the partial replication, the researcher
must explore relationships between all combinations of the quasiexperiments.
Alternatively, if the partial
replication provides data that help to address threats to the internal
validity of the original quasi-experiment or its exact replication, then the
partial replication enhances interpretation of the original study, and its
results might be considered
with
the results of the previous
study.
Figure 1 provides a possible decision
tree for researchers faced with data from a quasiexperiment and an exact
replication. Because multiple replications of quasi-experiments in
educational research are rare, Figure 1 is more an exercise in logic than a
decision matrix supported by data produced in a series of actual replication
batteries. However, the procedures and results described in this paper will
provide data generated from a series of quasi-experiments with practical
consequences for the scale-up of a set of curriculum materials in a large,
suburban school district. We hope to support the logic of Figure 1 by
applying it to the example to which we now turn.
Continued in article
"Internal and External Validity in Economics Research: Tradeoffs between
Experiments, Field Experiments, Natural Experiments and Field Data," by
Brian E. Roe and David R. Just, 2009 Proceedings Issue, American Journal
of Agricultural Economics ---
http://aede.osu.edu/people/roe.30/Roe_Just_AJAE09.pdf
Abstract: In the realm of empirical research,
investigators are first and foremost concerned with the validity of
their results, but validity is a multi-dimensional ideal. In this
article we discuss two key dimensions of validity – internal and
external validity – and underscore the natural tension that arises in
choosing a research approach to maximize both types of validity. We
propose that the most common approaches to empirical research – the use
of naturally-occurring field/market data and the use of laboratory
experiments – fall on the ends of a spectrum of research approaches, and
that the interior of this spectrum includes intermediary approaches such
as field experiments and natural experiments. Furthermore, we argue that
choosing between lab experiments and field data usually requires a
tradeoff between the pursuit of internal and external validity.
Movements toward the interior of the spectrum can often ease the tension
between internal and external validity but are also accompanied by other
important limitations, such as less control over subject matter or topic
areas and a reduced ability for others to replicate research. Finally,
we highlight recent attempts to modify and mix research approaches in a
way that eases the natural conflict between internal and external
validity and discuss if employing multiple methods leads to economies of
scope in research costs.
"What is the value of replicating other studies?" Park, C. L.,
Evaluation Research,13, 3, 2004. 189-195 ---
http://auspace.athabascau.ca:8080/dspace/handle/2149/1327
In response to a question on the value of
replication in social science research, the author undertook a search of the
literature for expert advise on the value of such an activity. Using the
information gleaned and the personal experience of attempting to replicate
the research of a colleague, the conclusion was drawn that replication has
great value but little ‘real life’ application in the true sense. The
activity itself, regardless of the degree of precision of the replication,
can have great merit in extending understanding about a method or a concept.
URI:
http://hdl.handle.net/2149/1327
Sometimes experimental outcomes impounded for years in textbooks become
viewed as "laws" by students, professors, and consultants. One example, is the
Hawthorne Effect impounded into psychology and management textbooks for the for
more than 50 years ---
http://en.wikipedia.org/wiki/Hawthorne_Effect
But Steven Levitt and John List, two economists
at the University of Chicago, discovered that the data had survived the decades
in two archives in Milwaukee and Boston, and decided to subject them to
econometric analysis. The Hawthorne experiments had another surprise in store
for them. Contrary to the descriptions in the literature, they found no
systematic evidence that levels of productivity in the factory rose whenever
changes in lighting were implemented.
"Light work," The Economist, June 4, 2009, Page 74 ---
http://www.economist.com/finance/displaystory.cfm?story_id=13788427
Revisiting a Research Study After 70 Years
"Thurstone's Crime Scale Re-Visited." by Mark H. Stone, Popular Measurement,
Spring 2000 ---
http://www.rasch.org/pm/pm3-53.pdf
A new one from my old behavioral accounting friend Jake
"Is Neuroaccounting Waiting in the Wings?" Jacob G. Birnberg and Ananda
R. Ganguly, SSRN, February 10 ,2011 ---
http://papers.ssrn.com/sol3/papers.cfm?abstract_id=1759460
Abstract:
This paper reviews a recently published handbook on neuroeconomics (Glimcher
et al. 2009H) and extends the discussion to reasons why this newly emerging
discipline should be of interest to behavioral accounting researchers. We
evaluate the achieved and potential contribution of neuroeconomics to the
study of human economic behavior, and examine what behavioral accountants
can learn from neuroeconomics and whether we should expect to see a similar
sub-field emerge within behavioral accounting in the near future. We
conclude that while a separate sub-field within behavioral accounting is not
likely in the near future due mostly to practical reasons, the behavioral
accounting researcher would do well to follow this discipline closely, and
behavioral accountants are likely to collaborate with neuroeconomists when
feasible to examine questions of mutual interest.
Keywords: Neuroeconomics, Neuroaccounting, Behavioral Accounting
Jensen Comment
This ties in somewhat with the work of John Dickhaut ---
http://www.neuroeconomics.org/dickhaut-memorial/in-memory-of-john-dickhaut
The lead article in the November 2009 issue of The Accounting Review
is like a blue plate special that differs greatly from the usual accountics
offerings on the TAR menu over the past four decades. TAR does not usually
publish case studies, field studies, or theory papers or commentaries or
conjectures that do not qualify as research on testable hypotheses or analytical
mathematics. But the November 2009 lead article by John Dickhout is an
exception.
Before reading the TAR tidbit below you
should perhaps read a bit about John Dichaut at the University of Minnesota,
apart from the fact that he's an old guy of my vintage with new ideas that
somehow leapt out of the accountics publishing shackles that typically restrain
creative ideas and "search" apart from "research."
"Gambling on Trust: John Dickhaut uses "neuroeconomics" to study how people
make decisions," OVPR, University of Minnesota ---
On the surface, it's obvious that trust
makes the economic world go round. A worker trusts that he or she will get
paid at the end of the week. Investors trust that earnings reports are based
on fact, not fiction. Back in the mid-1700s, Adam Smith-the father of
economics-built portions of his theories on this principle, which he termed
"sympathy." In the years since then, economists and other thinkers have
developed hundreds of further insights into the ways that people and
economies function. But what if Adam Smith was wrong about sympathy?
Professor John Dickhaut of the Carlson
School of Management's accounting department is one of a growing number of
researchers who uses verifiable laboratory techniques to put principles like
this one to the test. "I'm interested in how people make choices and how
these choices affect the economy," says Dickhaut. A decade ago, he and his
colleagues developed the trust game, an experiment that tracks trust levels
in financial situations between strangers. "The trust game mimics real-world
situations," he says.
Luckily for modern economics-and for
anyone planning an investment-Dickhaut's modern-day scientific methods
verify Adam Smith's insight. People tend to err on the side of trust than
mistrust-are more likely to be a little generous than a little bit stingy.
In fact, a basic tendency to be trusting and to reward trustworthy behavior
may be a norm of human behavior, upon which the laws of society are built.
And that's just the beginning of what the trust game and the field of
experimental economics can teach us.
Trust around the world
Since Dickhaut and his co-authors first
published the results of their research, the trust game has traveled from
the Carlson School at the University of Minnesota all the way to Russia,
China, and France. It's tested gender differences and other variations.
"It's an experiment that bred a cottage
industry," says Dickhaut. Because the trust game has proved so reliable,
researchers now use it to explore new areas. George Mason University's
Vernon Smith, 2002 Nobel Laureate for his work in experimental economics,
used the trust game in some of his path-breaking work. University of
Minnesota researcher and Dickhaut co-author Aldo Rustichini is discovering
that people's moods can be altered in the trust games so that participants
become increasingly organized in their behavior, as if this can impact the
outcome. This happens after the participants are repeatedly put in
situations where their trust has been violated.
Although it's too soon to be certain, such
research could reveal why people respond to troubled times by tightening up
regulations or imposing new ones, such as Sarbanes-Oxley. This new research
suggests that calls for tighter rules may reveal more about the brain than
reduce chaos in the world of finance.
Researchers who study the brain during
economic transactions, or neuroeconomists, scanned the brains of trust game
players in labs across the country to discover the parts of the brain that
"light up" during decision-making. Already, neuroeconomists have discovered
that the section of the brain investors use when making a risky investment,
like in the New York Stock Exchange, is different than the one used when
they invest in a less risky alternative, like a U.S. Treasury bill.
"People don't lay out a complete decision
tree every time they make a choice," Dickhaut says. Understanding the part
of the brain accessed during various situations may help to uncover the
regulatory structures that would be most effective-since people think of
different types of investments so differently, they might react to rules in
different ways as well. Such knowledge might also point to why behaviors
differ when faced with long- or short-term gains.
Dickhaut's original paper, "Trust,
Reciprocity, and Social History," is still a hit. Despite an original
publication date of 1995, the paper recently ranked first in ScienceDirect's
top 25 downloads from the journal Games and Economic Behavior.
Risky business
Dickhaut hasn't spent the past 10 years
resting on his laurels. Instead, he's challenged long-held beliefs with
startling new data. In his latest research, Dickhaut and his coauthors
create lab tests that mimic E-Bay style auctions, bidding contests for major
public works projects, and others types of auctions. The results may be
surprising.
"People don't appear to take risks based
on some general assessment of whether they're risk-seeking or risk-averse,"
says Dickhaut. In other words, it's easy to make faulty assumptions about
how a person will respond to risk. Even people who test as risk-averse might
be willing to make a risky gamble in a certain type of auction.
This research could turn the evaluation of
risk aversion upside down. Insurance company questionnaires are meant to
evaluate how risky a prospective client's behavior might be. In fact, the
questionnaires could simply reveal how a person answers a certain kind of
question, not how he or she would behave when faced with a risky
proposition.
Bubble and bust, laboratory style
In related research, Dickhaut and his
students seek that most elusive of explanations: what produces a
stock-market collapse? His students have successfully created models that
explain market crash situations in the lab. In these crashes, brokers try to
hold off selling until the last possible moment, hoping that they'll get out
at the peak. Buyers try to wait until the prices are the lowest they're
going to get. It's a complicated setting that happens every day-and
infrequently leads to a bubble and a crash.
"It must be more than price alone," says
Dickhaut. "Traditional economics tells us that people are price takers who
don't see that their actions influence prices. Stock buyers don't expect
their purchases to impact a stock's prices. Instead, they think of
themselves as taking advantages of outcomes."
He urges thinkers to take into account
that people are always trying to manipulate the market. "This is almost
always going to happen," he says. "One person will always think he knows
more than the other."
Transparency-giving a buyer all of the
information about a company-is often suggested as the answer to avoiding
inflated prices that can lead to a crash. Common sense says that the more
knowledge a buyer has, the less likely he or she is to pay more than a stock
is worth. Surprisingly, Dickhaut's findings refute this seemingly logical
answer. His lab tests prove that transparency can cause worse outcomes than
in a market with poorer information. In other words, transparent doesn't
equal clearly understood. "People fail to coordinate understanding,"
explains Dickhaut. "They don't communicate their expectations, and they
might think that they understand more than they do about a company."
Do stock prices balloon and crash because
of genuine misunderstandings? Can better communication about a stock's value
really be the key to avoiding future market crashes? "I wish you could say
for sure," says Dickhaut. "That's one of the things we want to find out."
Experimental economics is still a young
discipline, and it seems to raise new questions even as it answers old ones.
Even so, the contributions are real. In 2005 John Dickhaut was awarded the
Carlson School's first career research award, a signal that his research has
been of significant value in his field. "It's fun," he says with a grin.
"There's a lot out there to learn."
Reprinted with permission from the July 2005 edition of
Insights@Carlson School, a publication of the Carlson School of Management.
"The Brain as the Original Accounting Institution"
John Dickhaut
The Accounting Review 84(6), 1703 (2009) (10 pages)
TAR is not a free online journal, although articles can be purchased ---
http://aaahq.org/pubs.cfm
ABSTRACT:
The evolved brain neuronally processed information on human interaction long
before the development of formal accounting institutions. Could the neuronal
processes represent the underpinnings of the accounting principles that
exist today? This question is pursued several ways: first as an examination
of parallel structures that exist between the brain and accounting
principles, second as an explanation of why such parallels might exist, and
third as an explicit description of a paradigm that shows how the benefits
of an accounting procedure can emerge in an experiment.
The following are noteworthy in terms of this being a blue plate special
apart from the usual accountics fare at the TAR Restaurant:
- There are no equations that amount to anything beyond a seventh grade
algebra equation.
- There are no statistical inference tests, although much of the
discussion is based upon prior experimental models and tests.
- The paper is largely descriptive conjecture by brain analogy.
- I view this paper as a commentary even though the former Editor of TAR
declared he will not publish commentaries.
- The paper goes far back in history with the brain analogy.
- To date the TAR Editor has not been fired by the AAA Accountics Tribunal
for accepting and publishing this commentary that is neither empirical nor
advanced mathematical analysis. However, you must remember that it's a
November 2009 edition of TAR, and I'm writing this tidbit in late November.
Thunder and lightning from above could still wipe out Sarasota before the
year end.
- The paper is far out in the conjectural ether. I think John is lifting
the brain metaphor to where the air is thin and a bit too hot for me, but
perhaps I'm an aging luddite with a failing brain. I reached my limit of the
brain analogy in my metacognitive learning paper (which is also brain
conjecture by analogy) ---
http://faculty.trinity.edu/rjensen/265wp.htm
Professor Dickhaut presents a much wider discussion of all parts of the
brain. My research never went beyond the tiny hippocampus
part of the brain.
John was saved from the wrath of the AAA Accountics Tribunal by also having
an accountics paper (with complicated equations) published in the same November
2009 edition of TAR.
"Market Efficiencies and Drift: A Computational Model"
John Dickhaut and
Baohua Xin
The Accounting Review 84(6), 1805 (2009) (27 pages)
Whew!
Good work John!
John died in April 2010 at the age of 68.
The day Arthur Andersen loses the
public's trust is the day we are out of business.
Steve Samek, Country Managing Partner, United States, on Andersen's
Independence and Ethical Standards CD-Rom, 1999
Math Works Great—Until You Try to Map It Onto the World ---
http://www.wired.com/2015/07/math-works-great-try-map-onto-world/
In 1900, the great mathematician David Hilbert
presented a list of 23 unsolved problems worth investigating in the new
century. The list became a road map for the field, guiding mathematicians
through unexplored regions of the mathematical universe as they ticked off
problems one by one. But one of the problems was not like the others. It
required connecting the mathematical universe to the real one. Quanta
Magazine
Continued in article
Bob Jensen's threads on Mathematical Analytics in Plato's Cave
http://faculty.trinity.edu/rjensen/TheoryTAR.htm#Analytics
Mathematical Analytics in Plato's Cave
TAR Researchers Playing by Themselves in Isolated Dark Caves That the Sunlight
Cannot Reach
"In Plato's Cave: Mathematical models are a
powerful way of predicting financial markets. But they are fallible" The
Economist, January 24, 2009, pp. 10-14 ---
http://faculty.trinity.edu/rjensen/2008Bailout.htm#Bailout
Plato's Allegory of the Cave ---
http://en.wikipedia.org/wiki/Allegory_of_the_Cave
Mathematical analytics should not be immune from validity tests even though
replication is different from replication of experiments. Mathematical models
published in TAR all require underlying assumptions such that the robustness of the
analytics are generally only as good as the assumptions. Critical analyses of
such results thereby usually focus on the realism and validity of the assumptions regarding
such things as utility functions and decision behavior of persons assumed in the
models. For example, it's extremely common in TAR analytics to assume that
business firms are operating in a steady state equilibrium when in the real
world such assumed conditions rarely, if ever, apply. And the studies themselves
rarely, if ever, test the sensitivity of the conclusions to departures from
steady state equilibrium.
Until the giant leap from the analytical conclusions to reality can be
demonstrated, it does not take a rocket scientist to figure out why business
firms and most accounting teachers simply ignore the gaming going on in TAR
analytics. It's amazing to me how such analytics researchers perform such
talented and sophisticated mathematical analysis and then lightly brush over
their assumptions as "being reasonable" without any test of reasonableness.
Without validation of the enormous assumptions, we should not simply agree on
faith that these assumptions are indeed "reasonable."
At a minimum it would help greatly if TAR accepted commentaries where
scholars could debate the "reasonableness" of assumptions in the analytics.
Perhaps authors fear this might happen if the TAR editor
invited commentarie
In most instances the defense of underlying assumptions is based upon
assumptions passed down from previous analytical studies rather than empirical
or even case study evidence. An example is the following conclusion:
We find that audit quality and audit fees both
increase with the auditor’s expected litigation losses from audit failures.
However, when considering the auditor’s acceptance decision, we show that it
is important to carefully identify the component of the litigation
environment that is being investigated. We decompose the liability
environment into three components: (1) the strictness of the legal regime,
defined as the probability that the auditor is sued and found liable in case
of an audit failure, (2) potential damage payments from the auditor to
investors and (3) other litigation costs incurred by the auditor, labeled
litigation frictions, such as attorneys’ fees or loss of reputation. We show
that, in equilibrium,
an increase in the potential damage payment actually leads to a reduction in
the client rejection rate. This effect arises because the resulting higher
audit quality increases the value of the entrepreneur’s investment
opportunity, which makes it optimal for the entrepreneur to increase the
audit fee by an amount that is larger than the increase in the auditor’s
expected damage payment. However, for this result to hold, it is crucial
that damage payments be fully recovered by the investors. We show that an
increase in litigation frictions leads to the opposite result—client
rejection rates increase. Finally, since a shift in the strength of the
legal regime affects both the expected damage payments to investors as well
as litigation frictions, the relationship between the legal regime and
rejection rates is nonmonotonic. Specifically, we show that the relationship
is U-shaped, which implies that for both weak and strong legal liability
regimes, rejection rates are higher than those characterizing more moderate
legal liability regimes.
Volker Laux and D. Paul Newman, "Auditor Liability and Client
Acceptance Decisions," The Accounting Review, Vol. 85, No. 1, 2010
pp. 261–285
This analytical conclusion rests upon crucial underlying assumptions that are
mostly justified by reference to previous analytical studies that made similar
simplifying assumptions. For example, "the assumption that 'the entrepreneur has
no private information' is common in the auditing literature; see, for example,
Dye (1993, 1995), Schwartz (1997), Chan and Pae (1998), and Chan and Wong
(2002)." This assumption is crucial and highly dubious in many real-world
settings. Further reading of footnotes piles assumption upon assumption.
Laux and Newman contend their underlying assumptions are "reasonable." I will
argue that they are overly simplistic and thereby unreasonable. I instead
contend that risky clients must instead be pooled and that decisions regarding
fees and acceptances of risky clients must be made dynamically over time with
respect to the entire pool. In addition the current reputation losses have to be
factored in on a continuing basis.
Laux and Newman assume away the pooled and varying and interactive
externality costs of adverse publicity of litigation when clients fail. Such
costs are not as independent as assumed in the Laux and Newman audit pricing
model for a single risky client. Their model ignores the interactive covariances.
Even if the audit firm conducts a good audit, it usually finds itself drawn
into litigation as a deep pockets participant in the affairs of a failed client.
If the audit firms have had recent embarrassments for bad audits, the firm might
decide to drop a risky client no matter what the client might pay for an audit
fee. I contend the friction costs are disjointed and do not fit the Laux and
Newman model in a reasonable way. For example, after Deloitte, KMPG, and Ernst &
Young had their hands slapped by the PCAOB for some bad auditing, it becomes
even more imperative for these firms to reconsider their risky client pool that
could result in further damage to their reputations. Laux and Newman vaguely
bundle the reputation loss among what they call "frictions" but then assume that
the audit fee of a pending risky client can be adjusted to overcome such
"frictions." I would instead contend that the adverse publicity costs are
interdependent upon the entire subset of an audit firm's risky clients. Audit
firms must instead base audit pricing based upon an analysis of their entire
risk pool and seriously consider dropping some current clients irrespective of
audit fees. Also the friction cost of Client A is likely to be impacted by
a decision to drop Clients B, C, and D. Hence, friction costs are in reality
joint costs, and managers that make independent product pricing decisions amidst
joint products does so at great peril.
Laux and Newman assume possible reputation losses and other frictions can be
measured on a ratio scale. I consider this assumption entirely unrealistic. The
decision to take on a risky client depends greatly on the publicity losses that
have recently transpired combined with the potential losses due to adverse
publicity in the entire existing pool of risky clients. Andersen did not fail
because of Enron. Enron was merely the straw that broke the camel's back.
More importantly, it was found in the case of Andersen that accepting or
keeping risky Client A may impact on the cost of capital of Clients B, C, D, E,
etc.
Loss of Reputation was the Kiss of
Death for Andersen
Andersen Audits Increased Clients' Cost of Capital Relative to Clients of Other
Auditing Firms
"The Demise of Arthur Andersen," by
Clifford F. Thies, Ludwig Von Mises Institute, April 12, 2002 ---
http://www.mises.org/fullstory.asp?control=932&FS=The+Demise+of+Arthur+Andersen
From Yahoo.com,
Andrew and I downloaded the daily adjusted closing prices of the stocks of
these companies (the adjustment taking into account splits and dividends). I
then constructed portfolios based on an equal dollar investment in the
stocks of each of the companies and tracked the performance of the two
portfolios from August 1, 2001, to March 1, 2002. Indexes of the values of
these portfolios are juxtaposed in Figure 1.
From August 1,
2001, to November 30, 2001, the values of the two portfolios are very highly
correlated. In particular, the values of the two portfolios fell following
the September 11 terrorist attack on our country and then quickly recovered.
You would expect a very high correlation in the values of truly matched
portfolios. Then, two deviations stand out.
In early December
2001, a wedge temporarily opened up between the values of the two
portfolios. This followed the SEC subpoena. Then, in early February, a
second and persistent wedge opened. This followed the news of the coming DOJ
indictment. It appears that an Andersen signature (relative to a "Final
Four" signature) costs a company 6 percent of its market capitalization. No
wonder corporate clients--including several of the companies that were in
the Andersen-audited portfolio Andrew and I constructed--are leaving
Andersen.
Prior to the demise
of Arthur Andersen, the Big 5 firms seemed to have a "lock" on reputation.
It is possible that these firms may have felt free to trade on their names
in search of additional sources of revenue. If that is what happened at
Andersen, it was a big mistake. In a free market, nobody has a lock on
anything. Every day that you don’t earn your reputation afresh by serving
your customers well is a day you risk losing your reputation. And, in a
service-oriented economy, losing your reputation is the kiss of death.
Mathematics has been called the language of the
universe. Scientists and engineers often speak of the elegance of
mathematics when describing physical reality, citing examples such as π,
E=mc2, and even something as simple as using abstract integers to count
real-world objects. Yet while these examples demonstrate how useful math can
be for us, does it mean that the physical world naturally follows the rules
of mathematics as its "mother tongue," and that this mathematics has its own
existence that is out there waiting to be discovered? This point of view on
the nature of the relationship between mathematics and the physical world is
called Platonism, but not everyone agrees with it.
Derek Abbott, Professor of Electrical and
Electronics Engineering at The University of Adelaide in Australia, has
written a perspective piece to be published in the Proceedings of the IEEE
in which he argues that mathematical Platonism is an inaccurate view of
reality. Instead, he argues for the opposing viewpoint, the non-Platonist
notion that mathematics is a product of the human imagination that we tailor
to describe reality.
This argument is not new. In fact, Abbott estimates
(through his own experiences, in an admittedly non-scientific survey) that
while 80% of mathematicians lean toward a Platonist view, engineers by and
large are non-Platonist. Physicists tend to be "closeted non-Platonists," he
says, meaning they often appear Platonist in public. But when pressed in
private, he says he can "often extract a non-Platonist confession."
So if mathematicians, engineers, and physicists can
all manage to perform their work despite differences in opinion on this
philosophical subject, why does the true nature of mathematics in its
relation to the physical world really matter?
The reason, Abbott says, is that because when you
recognize that math is just a mental construct—just an approximation of
reality that has its frailties and limitations and that will break down at
some point because perfect mathematical forms do not exist in the physical
universe—then you can see how ineffective math is.
And that is Abbott's main point (and most
controversial one): that mathematics is not exceptionally good at describing
reality, and definitely not the "miracle" that some scientists have marveled
at. Einstein, a mathematical non-Platonist, was one scientist who marveled
at the power of mathematics. He asked, "How can it be that mathematics,
being after all a product of human thought which is independent of
experience, is so admirably appropriate to the objects of reality?"
In 1959, the physicist and mathematician Eugene
Wigner described this problem as "the unreasonable effectiveness of
mathematics." In response, Abbott's paper is called "The Reasonable
Ineffectiveness of Mathematics." Both viewpoints are based on the
non-Platonist idea that math is a human invention. But whereas Wigner and
Einstein might be considered mathematical optimists who noticed all the ways
that mathematics closely describes reality, Abbott pessimistically points
out that these mathematical models almost always fall short.
What exactly does "effective mathematics" look
like? Abbott explains that effective mathematics provides compact, idealized
representations of the inherently noisy physical world.
"Analytical mathematical expressions are a way
making compact descriptions of our observations," he told Phys.org. "As
humans, we search for this 'compression' that math gives us because we have
limited brain power. Maths is effective when it delivers simple, compact
expressions that we can apply with regularity to many situations. It is
ineffective when it fails to deliver that elegant compactness. It is that
compactness that makes it useful/practical ... if we can get that
compression without sacrificing too much precision.
"I argue that there are many more cases where math
is ineffective (non-compact) than when it is effective (compact). Math only
has the illusion of being effective when we focus on the successful
examples. But our successful examples perhaps only apply to a tiny portion
of all the possible questions we could ask about the universe."
Some of the arguments in Abbott's paper are based
on the ideas of the mathematician Richard W. Hamming, who in 1980 identified
four reasons why mathematics should not be as effective as it seems.
Although Hamming resigned himself to the idea that mathematics is
unreasonably effective, Abbott shows that Hamming's reasons actually support
non-Platonism given a reduced level of mathematical effectiveness.
Here are a few of Abbott's reasons for why
mathematics is reasonably ineffective, which are largely based on the
non-Platonist viewpoint that math is a human invention:
• Mathematics appears to be successful because we
cherry-pick the problems for which we have found a way to apply mathematics.
There have likely been millions of failed mathematical models, but nobody
pays attention to them. ("A genius," Abbott writes, "is merely one who has a
great idea, but has the common sense to keep quiet about his other thousand
insane thoughts.")
• Our application of mathematics changes at
different scales. For example, in the 1970s when transistor lengths were on
the order of micrometers, engineers could describe transistor behavior using
elegant equations. Today's submicrometer transistors involve complicated
effects that the earlier models neglected, so engineers have turned to
computer simulation software to model smaller transistors. A more effective
formula would describe transistors at all scales, but such a compact formula
does not exist.
• Although our models appear to apply to all
timescales, we perhaps create descriptions biased by the length of our human
lifespans. For example, we see the Sun as an energy source for our planet,
but if the human lifespan were as long as the universe, perhaps the Sun
would appear to be a short-lived fluctuation that rapidly brings our planet
into thermal equilibrium with itself as it "blasts" into a red giant. From
this perspective, the Earth is not extracting useful net energy from the
Sun.
• Even counting has its limits. When counting
bananas, for example, at some point the number of bananas will be so large
that the gravitational pull of all the bananas draws them into a black hole.
At some point, we can no longer rely on numbers to count.
• And what about the concept of integers in the
first place? That is, where does one banana end and the next begin? While we
think we know visually, we do not have a formal mathematical definition. To
take this to its logical extreme, if humans were not solid but gaseous and
lived in the clouds, counting discrete objects would not be so obvious. Thus
axioms based on the notion of simple counting are not innate to our
universe, but are a human construct. There is then no guarantee that the
mathematical descriptions we create will be universally applicable.
For Abbott, these points and many others that he
makes in his paper show that mathematics is not a miraculous discovery that
fits reality with incomprehensible regularity. In the end, mathematics is a
human invention that is useful, limited, and works about as well as
expected.
Continued in article
574 Shields Against Validity Challenges in Plato's Cave ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
Real Science versus Pseudo Science ---
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm#Pseudo-Science
How Accountics Scientists Should Change:
"Frankly, Scarlett, after I get a hit for my resume in The Accounting Review
I just don't give a damn"
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
One more mission in what's left of my life will be to try to change this
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
"How Non-Scientific Granulation Can Improve Scientific
Accountics"
http://www.cs.trinity.edu/~rjensen/temp/AccounticsGranulationCurrentDraft.pdf
A Mathematical Way To Think About Biology ---
http://qbio.lookatphysics.com/
"Do Biologists Avoid Math-Heavy Papers?" Inside Higher Ed, June
27, 2012 ---
http://www.insidehighered.com/quicktakes/2012/06/27/do-biologists-avoid-math-heavy-papers
New research by professors at the University of
Bristol suggests that biologists may be avoiding scientific papers that have
extensive mathematical detail,
Times Higher Education reported. The
Bristol researchers studied the number of citations to 600 evolutionary
biology papers published in 1998. They found that the most "maths-heavy"
papers were cited by others half as much as other papers. Each additional
math equation appears to reduce the odds of a paper being cited. Tim
Fawcett, a co-author of the paper, told Times Higher Education, "I think
this is potentially something that could be a problem for all areas of
science where there is a tight link between the theoretical mathematical
models and experiment."
"Maths-heavy papers put biologists off," by Elizabeth Gibney,
Times
Higher Education, June 26, 2012 ---
http://www.timeshighereducation.co.uk/story.asp?sectioncode=26&storycode=420388&c=1
The study, published in the Proceedings of the
National Academy of Sciences USA, suggests that scientists pay less
attention to theories that are dense with mathematical detail.
Researchers in Bristol’s School of Biological
Sciences compared citation data with the number of equations per page in
more than 600 evolutionary biology papers in 1998.
They found that most maths-heavy articles were
referenced 50 per cent less often than those with little or no maths. Each
additional equation per page reduced a paper’s citation success by 28 per
cent.
The size of the effect was striking, Tim Fawcett,
research fellow and the paper’s co-author, told Times Higher Education.
“I think this is potentially something that could
be a problem for all areas of science where there is a tight link between
the theoretical mathematical models and experiment,” he said.
The research stemmed from a suspicion that papers
full of equations and technical detail could be putting off researchers who
do not necessarily have much mathematical training, said Dr Fawcett.
“Even Steven Hawking worried that each equation he
added to A Brief History of Time would reduce sales. So this idea has been
out there for a while, but no one’s really looked at it until we did this
study,” he added.
Andrew Higginson, Dr Fawcett’s co-author and a
research associate in the School of Biological Sciences, said that
scientists need to think more carefully about how they present the
mathematical details of their work.
“The ideal solution is not to hide the maths away,
but to add more explanatory text to take the reader carefully through the
assumptions and implications of the theory,” he said.
But the authors say they fear that this approach
will be resisted by some journals that favour concise papers and where space
is in short supply.
An alternative solution is to put much of the
mathematical details in an appendix, which tends to be published online.
“Our analysis seems to show that for equations put
in an appendix there isn’t such an effect,” said Dr Fawcett.
“But there’s a big
risk that in doing that you are potentially hiding the maths away, so it's
important to state clearly the assumptions and implications in the main text
for everyone to see.”
Although the issue is likely to extend beyond
evolutionary biology, it may not be such a problem in other branches of
science where students and researchers tend to be trained in maths to a
greater degree, he added.
Continued in article
Jensen Comment
The causes of this asserted avoidance are no doubt very complicated and vary in
among individual instances. Some biologists might avoid biology quant papers
because they themselves are not sufficiently quant to comprehend the
mathematics. It would seem, however, that even quant biology papers have some
non-mathematics summaries that might be of interest to the non-quant biologists.
I would be inclined to believer that biologists avoid quant papers for other
reasons, especially some reasons that accounting teachers and practitioners most
often avoid accountics research studies (that are quant by definition). I think
the main reason for this avoidance is that biology and academic quants typically
do their research in Plato's Cave with "convenient"
assumptions that are too removed from the real and much more complicated world.
For example, the real world is seldom in a state of equilibrium or a "steady
state" needed to greatly simplify the mathematical derivations.
Bob Jensen's threads and illustrations of simplifying assumptions are at
Mathematical Analytics in Plato's Cave --- See Below
An Excellent Presentation on the Flaws of Finance, Particularly the Flaws
of Financial Theorists
A recent topic on the AECM listserv concerns the limitations of accounting
standard setters and researchers when it comes to understanding investors. One
point that was not raised in the thread to date is that a lot can be learned
about investors from the top financial analysts of the world --- their writings
and their conferences.
A Plenary Session Speech at a Chartered Financial Analysts Conference
Video: James Montier’s 2012 Chicago CFA Speech The
Flaws of Finance ---
http://cfapodcast.smartpros.com/web/live_events/Annual/Montier/index.html
Note that it takes over 15 minutes before James Montier begins
Major Themes
- The difference between physics versus finance models is that physicists
know the limitations of their models.
- Another difference is that components (e.g., atoms) of a physics model
are not trying to game the system.
- The more complicated the model in finance the more the analyst is trying
to substitute theory for experience.
- There's a lot wrong with Value at Risk (VaR) models that regulators
ignored.
- The assumption of market efficiency among regulators (such as Alan
Greenspan) was a huge mistake that led to excessively low interest rates and
bad behavior by banks and credit rating agencies.
- Auditors succumbed to self-serving biases of favoring their clients over
public investors.
- Banks were making huge gambles on other peoples' money.
- Investors themselves ignored risk such as poisoned CDO risks when they
should've known better. I love his analogy of black swans on a turkey farm.
- Why don't we see surprises coming (five
excellent reasons given here)?
- The only group of people who view the world realistically are the
clinically depressed.
- Model builders should stop substituting
elegance for reality.
- All financial theorists should be forced to
interact with practitioners.
- Practitioners need to abandon the myth of optimality before the fact.
Jensen Note
This also applies to abandoning the myth that we can set optimal accounting
standards.
- In the long term fundamentals matter.
- Don't get too bogged down in details at the expense of the big picture.
- Max Plank said science advances one funeral at a time.
- The speaker then entertains questions from the audience (some are very
good).
James Montier is a very good speaker from England!
Mr. Montier is a member of GMO’s asset allocation
team. Prior to joining GMO in 2009, he was co-head of Global Strategy at
Société Générale. Mr. Montier is the author of several books including
Behavioural Investing: A Practitioner’s Guide to Applying Behavioural
Finance; Value Investing: Tools and Techniques for Intelligent Investment;
and The Little Book of Behavioural Investing. Mr. Montier is a visiting
fellow at the University of Durham and a fellow of the Royal Society of
Arts. He holds a B.A. in Economics from Portsmouth University and an M.Sc.
in Economics from Warwick University
http://www.gmo.com/america/about/people/_departments/assetallocation.htm
There's a lot of useful information in this talk for accountics scientists.
Bob Jensen's threads on what went wrong with accountics research are at
http://faculty.trinity.edu/rjensen/theory01.htm#WhatWentWrong
How will World War III be fought to bring down the USA?
Target Breach Malware Partly Written in Russian
From the CFO Journal's Morning Ledger on January 17, 2014
Target
breach was part of broad attack
The holiday data
breach at Target appears to be part of a broad and
sophisticated international hacking campaign against multiple retailers,
the WSJ’s Danny Yadron reports.
Parts of the malicious computer code used against
Target’s credit-card readers had been on the Internet’s black market since
last spring and were partly written in
Russian. Both details suggest the attack
may have ties to organized crime in the former Soviet Union.
"Economics has met the enemy, and it is economics," by Ira Basen,
Globe and Mail, October 15, 2011 ---
http://www.theglobeandmail.com/news/politics/economics-has-met-the-enemy-and-it-is-economics/article2202027/page1/
Thank you Jerry Trites for the heads up.
After Thomas Sargent learned on Monday morning that
he and colleague Christopher Sims had been awarded the Nobel Prize in
Economics for 2011, the 68-year-old New York University professor struck an
aw-shucks tone with an interviewer from the official Nobel website: “We're
just bookish types that look at numbers and try to figure out what's going
on.”
But no one who'd followed Prof. Sargent's long,
distinguished career would have been fooled by his attempt at modesty. He'd
won for his part in developing one of economists' main models of cause and
effect: How can we expect people to respond to changes in prices, for
example, or interest rates? According to the laureates' theories, they'll do
whatever's most beneficial to them, and they'll do it every time. They don't
need governments to instruct them; they figure it out for themselves.
Economists call this the “rational expectations” model. And it's not just an
abstraction: Bankers and policy-makers apply these formulae in the real
world, so bad models lead to bad policy.
Which is perhaps why, by the end of that interview
on Monday, Prof. Sargent was adopting a more realistic tone: “We experiment
with our models,” he explained, “before we wreck the world.”
Rational-expectations theory and its corollary, the
efficient-market hypothesis, have been central to mainstream economics for
more than 40 years. And while they may not have “wrecked the world,” some
critics argue these models have blinded economists to reality: Certain the
universe was unfolding as it should, they failed both to anticipate the
financial crisis of 2008 and to chart an effective path to recovery.
The economic crisis has produced a crisis in the
study of economics – a growing realization that if the field is going to
offer meaningful solutions, greater attention must be paid to what is
happening in university lecture halls and seminar rooms.
While the protesters occupying Wall Street are not
carrying signs denouncing rational-expectations and efficient-market
modelling, perhaps they should be.
They wouldn't be the first young dissenters to call
economics to account. In June of 2000, a small group of elite graduate
students at some of France's most prestigious universities declared war on
the economic establishment. This was an unlikely group of student radicals,
whose degrees could be expected to lead them to lucrative careers in
finance, business or government if they didn't rock the boat. Instead, they
protested – not about tuition or workloads, but that too much of what they
studied bore no relation to what was happening outside the classroom walls.
They launched an online petition demanding greater
realism in economics teaching, less reliance on mathematics “as an end in
itself” and more space for approaches beyond the dominant neoclassical
model, including input from other disciplines, such as psychology, history
and sociology. Their conclusion was that economics had become an “autistic
science,” lost in “imaginary worlds.” They called their movement
Autisme-economie.
The students' timing is notable: It was the spring
of 2000, when the world was still basking in the glow of “the Great
Moderation,” when for most of a decade Western economies had been enjoying a
prolonged period of moderate but fairly steady growth.
Some economists were daring to think the
unthinkable – that their understanding of how advanced capitalist economies
worked had become so sophisticated that they might finally have succeeded in
smoothing out the destructive gyrations of capitalism's boom-and-bust cycle.
(“The central problem of depression prevention has been solved,” declared
another Nobel laureate, Robert Lucas of the University of Chicago, in 2003 –
five years before the greatest economic collapse in more than half a
century.)
The students' petition sparked a lively debate. The
French minister of education established a committee on economic education.
Economics students across Europe and North America began meeting and
circulating petitions of their own, even as defenders of the status quo
denounced the movement as a Trotskyite conspiracy. By September, the first
issue of the Post-Autistic Economic Newsletter was published in Britain.
As The Independent summarized the students'
message: “If there is a daily prayer for the global economy, it should be,
‘Deliver us from abstraction.'”
It seems that entreaty went unheard through most of
the discipline before the economic crisis, not to mention in the offices of
hedge funds and the Stockholm Nobel selection committee. But is it ringing
louder now? And how did economics become so abstract in the first place?
The great classical economists of the late 18th and
early 19th centuries had no problem connecting to the real world – the
Industrial Revolution had unleashed profound social and economic changes,
and they were trying to make sense of what they were seeing. Yet Adam Smith,
who is considered the founding father of modern economics, would have had
trouble understanding the meaning of the word “economist.”
What is today known as economics arose out of two
larger intellectual traditions that have since been largely abandoned. One
is political economy, which is based on the simple idea that economic
outcomes are often determined largely by political factors (as well as vice
versa). But when political-economy courses first started appearing in
Canadian universities in the 1870s, it was still viewed as a small offshoot
of a far more important topic: moral philosophy.
In The Wealth of Nations (1776), Adam Smith
famously argued that the pursuit of enlightened self-interest by individuals
and companies could benefit society as a whole. His notion of the market's
“invisible hand” laid the groundwork for much of modern neoclassical and
neo-liberal, laissez-faire economics. But unlike today's free marketers,
Smith didn't believe that the morality of the market was appropriate for
society at large. Honesty, discipline, thrift and co-operation, not
consumption and unbridled self-interest, were the keys to happiness and
social cohesion. Smith's vision was a capitalist economy in a society
governed by non-capitalist morality.
But by the end of the 19th century, the new field
of economics no longer concerned itself with moral philosophy, and less and
less with political economy. What was coming to dominate was a conviction
that markets could be trusted to produce the most efficient allocation of
scarce resources, that individuals would always seek to maximize their
utility in an economically rational way, and that all of this would
ultimately lead to some kind of overall equilibrium of prices, wages, supply
and demand.
Political economy was less vital because government
intervention disrupted the path to equilibrium and should therefore be
avoided except in exceptional circumstances. And as for morality, economics
would concern itself with the behaviour of rational, self-interested,
utility-maximizing Homo economicus. What he did outside the confines of the
marketplace would be someone else's field of study.
As those notions took hold, a new idea emerged that
would have surprised and probably horrified Adam Smith – that economics,
divorced from the study of morality and politics, could be considered a
science. By the beginning of the 20th century, economists were looking for
theorems and models that could help to explain the universe. One historian
described them as suffering from “physics envy.” Although they were dealing
with the behaviour of humans, not atoms and particles, they came to believe
they could accurately predict the trajectory of human decision-making in the
marketplace.
In their desire to have their field be recognized
as a science, economists increasingly decided to speak the language of
science. From Smith's innovations through John Maynard Keynes's work in the
1930s, economics was argued in words. Now, it would go by the numbers.
Continued in a long article
On July 14, 2006, Greg Wilson inquired about what the implications of poor
auditing are to investors and clients?
July 14, 2006 reply from Bob Jensen
Empirical evidence suggests that when an auditing firm begins to get a
reputation for incompetence and/or lack of independence its clients’ cost of
capital rises. This in fact was the case for the Arthur Andersen firm even
before it imploded. The firm’s reputation for bad audits and lack of
independence from Andersen Consulting, especially after the Waste Management
auditing scandal, was becoming so well known that some of its major clients
had already changed to another auditing firm in order to lower their cost of
capital.
Bob Jensen
July 14, 2006 reply from Ed Scribner
[escribne@NMSU.EDU]
I think the conventional wisdom is that poor audits
reduce the ability of information to reduce uncertainty, so investors charge
companies for this in the form of lower security prices.
In a footnote on p. 276 of the Watts and Zimmerman
"Market for Excuses" paper in the April 79 Accounting Review, WZ asserted
the following:
***
Share prices are unbiased estimates of the extent to which the auditor
monitors management and reduces agency costs... . The larger the
reduction in agency costs effected by an auditor (net of the auditor's
fees), the higher the value of the corporation's shares and bonds and,
ceteris paribus, the greater the demand for that auditor's services. If
the market observes the auditor failing to monitor management, it will
adjust downwards the share price of all firms who engage this auditor...
.
***
Sometime in the 1980s, Mike Kennelley tested this
assertion on the then-recent SEC censure of Peat Marwick. (I think his
article appeared in the Journal of Accounting and Economics, but I can't
find it at the moment.) The Watts/Zimmerman footnote suggests a negative
effect on all of Peat Marwick's client stock prices, but Mike, as I recall,
found a small positive effect.
Because agency theory seems to permit arguing any
side of any argument, a possible explanation was that the market interpreted
this adverse publicity as a wakeup call for Peat Marwick, causing it to
clean up its act so that its audits would be impeccable.
A couple of other examples of the empirical
research:
(1) Journal of Empirical Legal Studies Volume 1
Page 263 - July 2004 doi:10.1111/j.1740-1461.2004.00008.x Volume 1 Issue 2
Was Arthur Andersen Different? An Empirical
Examination of Major Accounting Firm Audits of Large Clients Theodore
Eisenberg1 and Jonathan R. Macey2
Enron and other corporate financial scandals
focused attention on the accounting industry in general and on Arthur
Andersen in particular. Part of the policy response to Enron, the
criminal prosecution of Andersen eliminated one of the few major audit
firms capable of auditing many large public corporations. This article
explores whether Andersen's performance, as measured by frequency of
financial restatements, measurably differed from that of other large
auditors. Financial restatements trigger significant negative market
reactions and their frequency can be viewed as a measure of accounting
performance. We analyze the financial restatement activity of
approximately 1,000 large public firms from 1997 through 2001. After
controlling for client size, region, time, and industry, we find no
evidence that Andersen's performance significantly differed from that of
other large accounting firms.
... Hiring an auditor, at least in theory,
allows the client company to "rent" the reputation of the accounting
firm, which rents its reputation for care, honesty, and integrity to its
clients.
... From the perspective of audit firms'
clients, good audits are good investments because they reduce the cost
of capital and increase shareholder wealth. Good audits also increase
management's credibility among the investment community. In theory, the
capital markets audit the auditors.
------------------------------------
(2) Journal of Accounting Research Volume 40 Page 1221 - September 2002
doi:10.1111/1475-679X.00087 Volume 40 Issue 4
Corporate Financial Reporting and the Market
for Independent Auditing: Contemporary Research Shredded Reputation: The
Cost of Audit Failure Paul K. Chaney & Kirk L. Philipich
In this article
we investigate the impact of the Enron audit failure on auditor
reputation. Specifically, we examine Arthur Andersen's clients' stock
market impact surrounding various dates on which Andersen's audit
procedures and independence were under severe scrutiny. On the three
days following Andersen's admission that a significant number of
documents had been shredded, we find that Andersen's other clients
experienced a statistically negative market reaction, suggesting that
investors downgraded the quality of the audits performed by Andersen. We
also find that audits performed by Andersen's Houston office suffered a
more severe decline in abnormal returns on this date. We are not able to
show that Andersen's independence was questioned by the amount of
non-audit fees charged to its clients.
Ed Scribner
New Mexico State University, USA
Bob Jensen's threads on fraudulent and incompetent auditing are at
http://faculty.trinity.edu/rjensen/fraud001.htm
Why smart people can be so stupid Or Rationality, Intelligence, and Levels
of Analysis in Cognitive Science:
Is Dysrationalia Possible?
The sure-thing principle is not the only rule of
rational thinking that humans have been shown to violate. A substantial research
literature–one comprising literally hundreds of empirical studies conducted over
nearly four decades–has firmly established that people’s responses often deviate
from the performance considered normative on many reasoning tasks. For example,
people assess probabilities incorrectly, they display confirmation bias, they
test hypotheses inefficiently, they violate the axioms of utility theory, they
do not properly calibrate degrees of belief, they overproject their own opinions
onto others, they display illogical framing effects, they uneconomically honor
sunk costs, they allow prior knowledge to become implicated in deductive
reasoning, and they display numerous other information processing biases.
Keith E. Stanovich, In R. J. Sternberg (Ed.), Why smart people can be
so stupid (pp. 124-158). New Haven, CT: Yale University Press,
ISBN-13: 9780300101706, September 2009
Jensen Comment
And all of these real-world complications are usually brushed aside by
analytical accountics researchers, because real people mess up the mathematics.
Volker Laux and D. Paul Newman, "Auditor Liability and Client
Acceptance Decisions," The Accounting Review, Vol. 85, No. 1, 2010
pp. 261–285
One of the dubious assumptions of the entire Laux and Newman analysis is
equilibrium of an audit firm's litigation payout for a particular client that
has a higher likelihood to fail. If a client has a higher than average
likelihood to fail then it most likely is not in an equilibrium state.
Another leap of faith is continuity in the payout and risk functions to a
point where second derivatives can be calculated of such firms. In reality such
functions are likely to be highly non-continuous and subject to serious break
points. It is not clear how such a model could ever be applied to a real world
audit client.
Another assumption is that the audit firm's ex ante utility function
and a client firm's utility function are respectively as follows:

 .
.
Yeah right. Have these utility functions ever been validated for any real
world client and auditor? As a matter of fact, what is the utility function of
any corporation that according to agency theory is a
nexus of contracts? My feeble mind cannot even imagine what a realistic
utility function looks like for a nexus of contracts.
I would instead contend that there is no audit firm utility function apart
from the interactions of the utilities of the major players in client
acceptance/retention decision and audit pricing decisions. For example, before
David Duncan was fired by Andersen, the decision to keep Enron as a client was
depended upon the interactive utility functions of David Duncan versus Carl Bass
versus Joseph Berardino. None of them
worked from a simplistic Andersen utility function such as the one shown in
Equation 20 above. Each worked interactively with each other in a very
complicated way that had Bass being released from the Enron audit and Berardino
buring his head in the sands of Lake Michigan.
The audit firm utility function, if it exists,
is based on the nexus of people rather than the nexus of contracts that we call
a "corporation."
The Laux and Newman paper also fails to include
the role of outside players in some decisions regarding risky players. A huge
outside player is the SEC that is often brought into the arena. Currently the
SEC is playing a role in the "merry-go-round of auditors" for a corporation
called Overstock.com that is currently working with the SEC to find an auditor.
See "Auditor Merry Go Round at Overstock.com," Big Four Blog, January 8,
2010 ---
http://www.bigfouralumni.blogspot.com/
Another leap of faith in the Laux and Newman paper is that auditor "liability environment" can be
decomposed into "three
components: (1) the strictness of the legal regime, defined as the probability
that the auditor is sued and found liable in case of an audit failure, (2)
potential damage payments from the auditor to investors and (3) other litigation
costs incurred by the auditor, labeled litigation frictions, such as attorneys’
fees or loss of reputation." It would seem that these three
components cannot be decomposed in real life without also accounting for the
nonlinear and possibly huge covariances.
A possible test of of this study might be reference to one case illustration
demonstrating that in at least one real world instance "an
increase in the potential damage payment actually leads to a reduction in the
client rejection rate." In the absence of such real world partial validation of
the analytical results, we are asked to accept a huge amount on unsupported
faith in untested assumptions inside Plato's Cave.
In finance mathematical analytics, a model derivation is on occasion put to
the test. A real world example of where assumptions break down is the
mathematical analytical model that is suspected of having contributed greatly to
the present economic crisis.
Can the 2008 investment banking failure be traced to a math error?
Recipe for Disaster: The Formula That Killed Wall Street ---
http://www.wired.com/techbiz/it/magazine/17-03/wp_quant?currentPage=all
Link forwarded by Jim Mahar ---
http://financeprofessorblog.blogspot.com/2009/03/recipe-for-disaster-formula-that-killed.html
Some highlights:
"For five years, Li's formula, known as a
Gaussian copula function, looked like an unambiguously positive
breakthrough, a piece of financial technology that allowed hugely
complex risks to be modeled with more ease and accuracy than ever
before. With his brilliant spark of mathematical legerdemain, Li made it
possible for traders to sell vast quantities of new securities,
expanding financial markets to unimaginable levels.
His method was adopted by everybody from bond
investors and Wall Street banks to ratings agencies and regulators. And
it became so deeply entrenched—and was making people so much money—that
warnings about its limitations were largely ignored.
Then the model fell apart." The article goes on to show that correlations
are at the heart of the problem.
"The reason that ratings agencies and investors
felt so safe with the triple-A tranches was that they believed there was
no way hundreds of homeowners would all default on their loans at the
same time. One person might lose his job, another might fall ill. But
those are individual calamities that don't affect the mortgage pool much
as a whole: Everybody else is still making their payments on time.
But not all calamities are individual, and
tranching still hadn't solved all the problems of mortgage-pool risk.
Some things, like falling house prices, affect a large number of people
at once. If home values in your neighborhood decline and you lose some
of your equity, there's a good chance your neighbors will lose theirs as
well. If, as a result, you default on your mortgage, there's a higher
probability they will default, too. That's called correlation—the degree
to which one variable moves in line with another—and measuring it is an
important part of determining how risky mortgage bonds are."
I would highly recommend reading the entire thing that gets much more
involved with the
actual formula etc.
The
“math error” might truly be have been an error or it might have simply been a
gamble with what was perceived as miniscule odds of total market failure.
Something similar happened in the case of the trillion-dollar disastrous 1993
collapse of Long Term Capital Management formed by Nobel Prize winning
economists and their doctoral students who took similar gambles that ignored the
“miniscule odds” of world market collapse -- -
http://faculty.trinity.edu/rjensen/FraudRotten.htm#LTCM
The rhetorical question is whether the failure is ignorance in model building or
risk taking using the model?
Also see
"In Plato's Cave: Mathematical models are a
powerful way of predicting financial markets. But they are fallible" The
Economist, January 24, 2009, pp. 10-14 ---
http://faculty.trinity.edu/rjensen/2008Bailout.htm#Bailout
Wall Street’s Math Wizards Forgot a Few Variables
What wasn’t recognized was the importance of a
different species of risk — liquidity risk,” Stephen Figlewski, a professor of
finance at the Leonard N. Stern School of Business at New York University, told
The Times. “When trust in counterparties is lost, and markets freeze up so there
are no prices,” he said, it “really showed how different the real world was from
our models.
DealBook, The New York Times, September 14, 2009 ---
http://dealbook.blogs.nytimes.com/2009/09/14/wall-streets-math-wizards-forgot-a-few-variables/
Bottom Line
My conclusion is that the mathematical analytics papers in general in TAR are
not adequately put to the test if the Senior Editor refuses to put commentaries
on published papers out to review. This policy discourages independent
researchers from even bothering to write commentaries on the published papers.
"Deductive reasoning," Phil Johnson-Laird, Wiley Interscience,
,2009 ---
http://www3.interscience.wiley.com/cgi-bin/fulltext/123228371/PDFSTART?CRETRY=1&SRETRY=0
This article begins with an account of logic,
and of how logicians formulate formal rules of inference for the sentential
calculus, which hinges on analogs of negation and the connectives if, or,
and and. It considers the various ways in which computer scientists have
written programs to prove the validity of
inferences in this and other domains. Finally,
it outlines the principal psychological theories of how human reasoners
carry out deductions. 2009 John Wiley & Sons, Ltd. WIREs Cogn Sci 2010
1 8–1
Audit Pricing in the Real World ---
See Appendix 3
Warnings from a Theoretical Physicist With an Interest in Economics and
Finance
"Beware of Economists (and accoutnics scientists) Peddling Elegant Models,"
by Mark Buchanan, Bloomberg, April 7, 2013 ---
http://www.bloomberg.com/news/2013-04-07/beware-of-economists-peddling-elegant-models.html
. . .
In one very practical and consequential area,
though, the allure of elegance has exercised a perverse and lasting
influence. For several decades, economists have sought to express the way
millions of people and companies interact in a handful of pretty equations.
The resulting mathematical structures, known as
dynamic stochastic general equilibrium models, seek to reflect our messy
reality without making too much actual contact with it. They assume that
economic trends emerge from the decisions of only a few “representative”
agents -- one for households, one for firms, and so on. The agents are
supposed to plan and act in a rational way, considering the probabilities of
all possible futures and responding in an optimal way to unexpected shocks.
Surreal Models
Surreal as such models might seem, they have played
a significant role in informing policy at the world’s largest central banks.
Unfortunately, they don’t work very well, and they proved spectacularly
incapable of accommodating the way markets and the economy acted before,
during and after the recent crisis.
Now, some economists are beginning to pursue a
rather obvious, but uglier, alternative. Recognizing that an economy
consists of the actions of millions of individuals and firms thinking,
planning and perceiving things differently, they are trying to model all
this messy behavior in considerable detail. Known as agent-based
computational economics, the approach is showing promise.
Take, for example, a 2012 (and still somewhat
preliminary)
study by a group of
economists, social scientists, mathematicians and physicists examining the
causes of the housing boom and subsequent collapse from 2000 to 2006.
Starting with data for the Washington D.C. area, the study’s authors built
up a computational model mimicking the behavior of more than two million
potential homeowners over more than a decade. The model included detail on
each individual at the level of race, income, wealth, age and marital
status, and on how these characteristics correlate with home buying
behavior.
Led by further empirical data, the model makes some
simple, yet plausible, assumptions about the way people behave. For example,
homebuyers try to spend about a third of their annual income on housing, and
treat any expected house-price appreciation as income. Within those
constraints, they borrow as much money as lenders’ credit standards allow,
and bid on the highest-value houses they can. Sellers put their houses on
the market at about 10 percent above fair market value, and reduce the price
gradually until they find a buyer.
The model captures things that dynamic stochastic
general equilibrium models do not, such as how rising prices and the
possibility of refinancing entice some people to speculate, buying
more-expensive houses than they otherwise would. The model accurately fits
data on the housing market over the period from 1997 to 2010 (not
surprisingly, as it was designed to do so). More interesting, it can be used
to probe the deeper causes of what happened.
Consider, for example, the assertion of some
prominent economists, such as
Stanford University’s
John Taylor, that the
low-interest-rate policies of the
Federal Reserve were
to blame for the housing bubble. Some dynamic stochastic general equilibrium
models can be used to support this view. The agent- based model, however,
suggests that
interest rates
weren’t the primary driver: If you keep rates at higher levels, the boom and
bust do become smaller, but only marginally.
Leverage Boom
A much more important driver might have been
leverage -- that is, the amount of money a homebuyer could borrow for a
given down payment. In the heady days of the housing boom, people were able
to borrow as much as 100 percent of the value of a house -- a form of easy
credit that had a big effect on housing demand. In the model, freezing
leverage at historically normal levels completely eliminates both the
housing boom and the subsequent bust.
Does this mean leverage was the culprit behind the
subprime debacle and the related global financial crisis? Not necessarily.
The model is only a start and might turn out to be wrong in important ways.
That said, it makes the most convincing case to date (see my
blog for more
detail), and it seems likely that any stronger case will have to be based on
an even deeper plunge into the messy details of how people behaved. It will
entail more data, more agents, more computation and less elegance.
If economists jettisoned elegance and got to work
developing more realistic models, we might gain a better understanding of
how crises happen, and learn how to anticipate similarly unstable episodes
in the future. The theories won’t be pretty, and probably won’t show off any
clever mathematics. But we ought to prefer ugly realism to beautiful
fantasy.
(Mark Buchanan, a theoretical physicist and the author of “The Social
Atom: Why the Rich Get Richer, Cheaters Get Caught and Your Neighbor Usually
Looks Like You,” is a Bloomberg View columnist. The opinions expressed are
his own.)
Jensen Comment
Bob Jensen's threads on the mathematical formula that probably led to the
economic collapse after mortgage lenders peddled all those poisoned mortgages
---
"What use is game theory?" by Steve Hsu, Information Processing,
May 4, 2011 ---
http://infoproc.blogspot.com/2011/05/what-use-is-game-theory.html
Fantastic
interview with game theorist Ariel Rubinstein on
Econtalk. I agree with Rubinstein that game theory has little predictive
power in the real world, despite the pretty mathematics. Experiments at RAND
(see, e.g., Mirowski's
Machine Dreams) showed early game theorists,
including Nash, that people don't conform to the idealizations in their
models. But this wasn't emphasized (Mirowski would claim it was deliberately
hushed up) until more and more experiments showed similar results. (Who
woulda thought -- people are "irrational"! :-)
Perhaps the most useful thing about game theory is that it requires you to
think carefully about decision problems. The discipline of this kind of
analysis is valuable, even if the models have limited applicability to real
situations.
Rubinstein discusses a number of topics, including raw intelligence vs
psychological insight and its importance in economics (see also
here). He has, in my opinion, a very developed and
mature view of what social scientists actually do, as opposed to what they
claim to do.
Continued in article
The problem is when the model created to represent
reality takes on a life of its own completely detached from the reality that it
is supposed to model that nonsense can easily ensue.
Was it Mark Twain who wrote: "The criterion of
understanding is a simple explanation."?
As quoted by Martin Weiss in a comment to the article below.
But a lie gets halfway around the world while the
truth is still tying its shoes
Mark Twain as quoted by PKB (in Mankato, MN) in a comment to the article below.
"US Net Investment Income," by Paul Krugman, The New York Times,
December 31, 2011 ---
http://krugman.blogs.nytimes.com/2011/12/31/us-net-investment-income/
Especially note the cute picture.
December 31, 2011 Comment by Wendell Murray
http://krugman.blogs.nytimes.com/2011/12/31/i-like-math/#postComment
Mathematics, like word-oriented languages, uses
symbols to represent concepts, so it is essentially the same as
word-oriented languages that everyone is comfortable with.
Because mathematics is much more precise and in most ways much simpler than
word-oriented languages, it is useful for modeling (abstraction from) of the
messiness of the real world.
The problem, as Prof. Krugman notes, is when the model created to represent
reality takes on a life of its own completely detached from the reality that
it is supposed to model that nonsense can easily ensue.
This is what has happened in the absurd conclusions often reached by those
who blindly believe in the infallibility of hypotheses such as the rational
expectations theory or even worse the completely peripheral concept of
so-called Ricardian equivalence. These abstractions from reality have value
only to the extent that they capture the key features of reality. Otherwise
they are worse than useless.
I think some academics and/or knowledgeless distorters of academic theories
in fact just like to use terms such as "Ricardian equivalence theorem"
because that term, for example, sounds so esoteric whereas the theorem
itself is not much of anything.
Ricardian Equivalence ---
http://en.wikipedia.org/wiki/Ricardian_equivalence
Jensen Comment
One of the saddest flaws of accountics science archival studies is the repeated
acceptance of the CAPM mathematics allowing the CAPM to "represent reality on a
life of its own" when in fact the CAPM is a seriously flawed representation of
investing reality ---
http://faculty.trinity.edu/rjensen/theory01.htm#AccentuateTheObvious
At the same time one of the things I dislike about the exceedingly left-wing
biased, albeit brilliant, Paul Krugman is his playing down of trillion dollar
deficit spending and his flippant lack of concern about $80 trillion in unfunded
entitlements. He just turns a blind eye toward risks of Zimbabwe-like inflation.
As noted below, he has a Nobel Prize in Economics but
"doesn't command respect in the profession".
Put another way, he's more of a liberal preacher than an economics teacher.
Paul Krugman ---
http://en.wikipedia.org/wiki/Paul_Krugman
Economics and policy recommendations
Economist and former
United States Secretary of the Treasury
Larry Summers has stated Krugman has a tendency to
favor more extreme policy recommendations because "it’s much more
interesting than agreement when you’re involved in commenting on rather than
making policy."
According to Harvard professor of economics
Robert Barro, Krugman "has never done any work in
Keynesian macroeconomics" and makes arguments that are politically
convenient for him.Nobel laureate
Edward Prescott has charged that Krugman "doesn't
command respect in the profession", as "no
respectable macroeconomist" believes that
economic stimulus works, though the number of
economists who support such stimulus is "probably a majority".
Bob Jensen's critique of analytical models in accountics science (Plato's
Cave) can be found at
http://faculty.trinity.edu/rjensen/TheoryTAR.htm#Analytics
Why Do Accountics Scientists Get Along So Well?
To a fault I've argued that accountics scientists do not challenge each other
or do replications and other validity tests of their published research ---
See below.
By comparison the real science game is much more a hard ball game of
replication, critical commentary, and other validity checking. Accountics
scientists have a long way to go in their quest to become more like real
scientists.
"Casualty of the Math Wars," by Scott Jaschik, Inside Higher Ed,
October 15, 2012 ---
http://www.insidehighered.com/news/2012/10/15/stanford-professor-goes-public-attacks-over-her-math-education-research
. . .
The
"math wars" have raged since the 1990s. A series
of reform efforts (of which Boaler's work is a part) have won support from
many scholars and a growing number of school districts. But a traditionalist
school (of which Milgram and Bishop are part) has pushed back, arguing that
rigor and standards are being sacrificed. Both sides accuse the other of
oversimplifying the other's arguments, and studies and op-eds from
proponents of the various positions appear regularly in education journals
and the popular press. Several mathematics education experts interviewed for
this article who are supportive of Boaler and her views stressed that they
did not view all, or even most, criticism from the "traditionalist" camp as
irresponsible.
The essay Boaler published Friday night noted that
there has been "spirited academic debate" about her ideas and those of
others in mathematics education, and she says that there is nothing wrong
with that.
"Milgram and Bishop have gone beyond the bounds of
reasoned discourse in a campaign to systematically suppress empirical
evidence that contradicts their stance," Boaler wrote. "Academic
disagreement is an inevitable consequence of academic freedom, and I welcome
it. However, responsible disagreement and academic bullying are not the same
thing. Milgram and Bishop have engaged in a range of tactics to discredit me
and damage my work which I have now decided to make public."
Some experts who have been watching the debate say
that the reason this dispute is important is because Boaler's work is not
based simply on a critique of traditional methods of teaching math, but
because she has data to back up her views.
Keith Devlin, director of the Human Sciences and
Technologies Advanced Research Institute at Stanford, said that he has
"enormous respect" for Boaler, although he characterized himself as someone
who doesn't know her well, but has read her work and is sympathetic to it.
He said that he shares her views, but that he does so "based on my own
experience and from reading the work of others," not from his own research.
So he said that while he has also faced "unprofessional" attacks when he has
expressed those views, he hasn't attracted the same level of criticism as
has Boaler.
Of her critics, Devlin said that "I suspect they
fear her because she brings hard data that threatens their view of how
children should be taught mathematics." He said that the criticisms of
Boaler reach "the point of character assassination."
Debating the Data
The Milgram/Bishop essay that Boaler said has
unfairly damaged her reputation is called
"A Close Examination of Jo Boaler's Railside Report,"
and appears on Milgram's Stanford website. ("Railside"
refers to one of the schools Boaler studied.) The piece says that Boaler's
claims are "grossly exaggerated," and yet expresses fear that they could be
influential and so need to be rebutted. Under federal privacy protection
requirements for work involving schoolchildren, Boaler agreed to keep
confidential the schools she studied and, by extension, information about
teachers and students. The Milgram/Bishop essay claims to have identified
some of those schools and says this is why they were able to challenge her
data.
Boaler said -- in her essay and in an interview --
that this puts her in a bind. She cannot reveal more about the schools
without violating confidentiality pledges, even though she is being accused
of distorting data. While the essay by Milgram and Bishop looks like a
journal article, Boaler notes that it has in fact never been published, in
contrast to her work, which has been subjected to peer review in multiple
journals and by various funding agencies.
Further, she notes that Milgram's and Bishop's
accusations were investigated by Stanford when Milgram in 2006 made a formal
charge of research misconduct against her, questioning the validity of her
data collection. She notes in her new essay that the charges "could have
destroyed my career." Boaler said that her final copy of the initial
investigation was deemed confidential by the university, but she provided a
copy of the conclusions, which rejected the idea that there had been any
misconduct.
Here is the conclusion of that report: "We
understand that there is a currently ongoing (and apparently passionate)
debate in the mathematics education field concerning the best approaches and
methods to be applied in teaching mathematics. It is not our task under
Stanford's policy to determine who is 'right' and who is 'wrong' in this
academic debate. We do note that Dr. Boaler's responses to the questions put
to her related to her report were thorough, thoughtful, and offered her
scientific rationale for each of the questions underlying the allegations.
We found no evidence of scientific misconduct or fraudulent behavior related
to the content of the report in question. In short, we find that the
allegations (such as they are) of scientific misconduct do not have
substance."
Even though the only body to examine the
accusations made by Milgram rejected them, and even though the Milgram/Bishop
essay has never been published beyond Milgram's website, the accusations in
the essay have followed Boaler all over as supporters of Milgram and Bishop
cite the essay to question Boaler's ethics. For example, an article she and
a co-author wrote about her research that was published in a leading journal
in education research, Teachers College Record, attracted
a comment that said the findings were
"imaginative" and asked if they were "a prime example of data cooking." The
only evidence offered: a link to the Milgram/Bishop essay.
In an interview, Boaler said that, for many years,
she has simply tried to ignore what she considers to be unprofessional,
unfair criticism. But she said she was prompted to speak out after thinking
about the fallout from an experience this year when Irish educational
authorities brought her in to consult on math education. When she wrote
an op-ed in The Irish Times, a commenter
suggested that her ideas be treated with "great skepticism" because they had
been challenged by prominent professors, including one at her own
university. Again, the evidence offered was a link to the Stanford URL of
the Milgram/Bishop essay.
"This guy Milgram has this on a webpage. He has it
on a Stanford site. They have a campaign that everywhere I publish, somebody
puts up a link to that saying 'she makes up data,' " Boaler said. "They are
stopping me from being able to do my job."
She said one reason she decided to go public is
that doing so gives her a link she can use whenever she sees a link to the
essay attacking her work.
Bishop did not respond to e-mail messages
requesting comment about Boaler's essay. Milgram via e-mail answered a few
questions about Boaler's essay. He said she inaccurately characterized a
meeting they had after she arrived at Stanford. (She said he discouraged her
from writing about math education.) Milgram denied engaging in "academic
bullying."
He said via e-mail that the essay was prepared for
publication in a journal and was scheduled to be published, but "the HR
person at Stanford has some reservations because it turned out that it was
too easy to do a Google search on some of the quotes in the paper and
thereby identify the schools involved. At that point I had so many other
things that I had to attend to that I didn't bother to make the
corrections." He also said that he has heard more from the school since he
wrote the essay, and that these additional discussions confirm his criticism
of Boaler's work.
In an interview Sunday afternoon, Milgram said that
by "HR" in the above quote, he meant "human research," referring to the
office at Stanford that works to protect human subjects in research. He also
said that since it was only those issues that prevented publication, his
critique was in fact peer-reviewed, just not published.
Further, he said that Stanford's investigation of
Boaler was not handled well, and that those on the committee considered the
issue "too delicate and too hot a potato." He said he stood behind
everything in the paper. As to Boaler's overall criticism of him, he said
that he would "have discussions with legal people, and I'll see if there is
an appropriate action to be taken, but my own inclination is to ignore it."
Milgram also rejected the idea that it was not
appropriate for him to speak out on these issues as he has. He said he first
got involved in raising questions about research on math education as the
request of an assistant in the office of Rod Paige, who held the job of U.S.
education secretary during the first term of President George W. Bush.
Ze'ev Wurman, a supporter of Milgram and Bishop,
and one who has posted the link to their article elsewhere, said he wasn't
bothered by its never having been published. "She is basically using the
fact that it was not published to undermine its worth rather than argue the
specific charges leveled there by serious academics," he said.
Critiques 'Without Merit'
E-mail requests for comment from several leading
figures in mathematics education resulted in strong endorsements of Boaler's
work and frustration at how she has been treated over the years.
Jeremy Kilpatrick, a professor of mathematics
education at the University of Georgia who has chaired commissions on the
subject for the National Research Council and the Rand Corporation, said
that "I have long had great respect for Jo Boaler and her work, and I have
been very disturbed that it has been attacked as faulty or disingenuous. I
have been receiving multiple e-mails from people who are disconcerted at the
way she has been treated by Wayne Bishop and Jim Milgram. The critiques by
Bishop and Milgram of her work are totally without merit and unprofessional.
I'm pleased that she has come forward at last to give her side of the story,
and I hope that others will see and understand how badly she has been
treated."
Alan H. Schoenfeld is the Elizabeth and Edward
Conner Professor of Education at the University of California at Berkeley,
and a past president of the American Educational Research Association and
past vice president of the National Academy of Education. He was reached in
Sweden, where he said his e-mail has been full of commentary about Boaler's
Friday post. "Boaler is a very solid researcher. You don't get to be a
professor at Stanford, or the Marie Curie Professor of Mathematics Education
at the University of Sussex [the position she held previously], unless you
do consistently high quality, peer-reviewed research."
Schoenfeld said that the discussion of Boaler's
work "fits into the context of the math wars, which have sometimes been
argued on principle, but in the hands of a few partisans, been vicious and
vitriolic." He said that he is on a number of informal mathematics education
networks, and that the response to Boaler's essay "has been swift and, most
generally, one of shock and support for Boaler." One question being asked,
he said, is why Boaler was investigated and no university has investigated
the way Milgram and Bishop have treated her.
A spokeswoman for Stanford said the following via
e-mail: "Dr. Boaler is a nationally respected scholar in the field of math
education. Since her arrival more than a decade ago, Stanford has provided
extensive support for Dr. Boaler as she has engaged in scholarship in this
field, which is one in which there is wide-ranging academic opinion. At the
same time, Stanford has carefully respected the fundamental principle of
academic freedom: the merits of a position are to be determined by scholarly
debate, rather than by having the university arbitrate or interfere in the
academic discourse."
Boaler in Her Own Words
Here is a YouTube video of Boaler discussing and
demonstrating her ideas about math education with a group of high school
students in Britain.
Continued in article
How Accountics Scientists Should Change:
"Frankly, Scarlett, after I get a hit for my resume in The Accounting Review
I just don't give a damn"
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
One more mission in what's left of my life will be to try to change this so that
we don't get along so well
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
Wikipedia is Fantastic Except in Accountancy
"Wikipedia, a Professor's Best Friend," by Dariusz Jemielniak,
Chronicle of Higher Education, October 13, 2014 ---
http://chronicle.com/article/Wikipedia-a-Professors-Best/149337/?cid=wc&utm_source=wc&utm_medium=en
Jensen Comment
I am a cheerleader for Wikipedia. However, one of my criticisms is that coverage
across academic disciplines is highly variable. For example, coverage of
economics and finance is fantastic. Coverage of accountancy can best be
described as lousy. It's a Pogo thing. When I look for the enemy I discover that
"He is us."
Disciplines covered extensively are generally strong in both theory and
academic debate, particularly philosophy and science. Accountancy is weak in
theory and the top academic research journals in
accounting will not publish replications or even commentaries. This
greatly limits anything interesting that can be posted to Wikipedia ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
Academic leaders in philosophy and science are nearly all covered extensively
in Wikipedia. Academic leaders in accountancy are rarely mentioned, and when
they are mentioned their Wikipedia modules are puny and boring.
What academic accounting leader has an extensive Wikipedia module? I've never
found a single one.
When I look up academic economists I not only find frequent Wikipedia
modules, virtually all of those modules contain summaries of their research and
summaries of controversies surrounding their research. I've never found a
Wikipedia article about an academic accounting researcher that contains
summaries of the controversies surrounding that professor's research.
Accounting research won't have much respect in the world until its leading
researchers are in Wikipedia, including summaries of controversies of their
research findings. The enemy is us.
Bob Jensen's threads on Wikipedia are at
http://faculty.trinity.edu/rjensen/Searchh.htm
Why Pick on The Accounting Review (TAR)?
The Accounting Review (TAR) since 1926 ---
http://faculty.trinity.edu/rjensen/395wpTAR/Web/TAR395wp.htm
Jensen Comment
Occasionally I receive messages questioning why I pick on TAR when in fact my
complaints are really with accountics scientists and accountics science in
general.
Accountics is the mathematical science of values.
Charles Sprague [1887] as quoted by McMillan [1998, p. 1]
http://faculty.trinity.edu/rjensen/395wpTAR/Web/TAR395wp.htm
Academic psychology and medical testing are both dogged by unreliability.
The reason is clear: we got probability wrong ---
https://aeon.co/essays/it-s-time-for-science-to-abandon-the-term-statistically-significant?utm_source=Aeon+Newsletter&utm_campaign=b8fc3425d2-Weekly_Newsletter_14_October_201610_14_2016&utm_medium=email&utm_term=0_411a82e59d-b8fc3425d2-68951505
Jensen Comment
In accountics science we got probability wrong as well, but who cares about
accountics science. The goal is to get research papers published. Nobody cares
about the reliability of the findings, because nobody in the real world cares
about the findings
How Accountics Scientists Should Change:
"Frankly, Scarlett, after I get a hit for my resume in The Accounting Review
I just don't give a damn"
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
How Well Do Anomalies in Finance and Accounting Replicate ---
https://replicationnetwork.com/2017/05/19/how-well-do-anomalies-in-finance-and-accounting-replicate/
“The anomalies literature is infested with
widespread p-hacking. We replicate the entire anomalies literature in
finance and accounting by compiling a largest-to-date data library that
contains 447 anomaly variables. With microcaps alleviated via New York Stock
Exchange breakpoints and value-weighted returns, 286 anomalies (64%)
including 95 out of 102 liquidity variables (93%) are insignificant at the
conventional 5% level. Imposing the cutoff t-value of three raises the
number of insignificance to 380 (85%). Even for the 161 significant
anomalies, their magnitudes are often much lower than originally reported.
Out of the 161, the q-factor model leaves 115 alphas insignificant (150 with
t < 3). In all, capital markets are more efficient than previously
recognized.”
How Accountics Scientists Should Change:
"Frankly, Scarlett, after I get a hit for my resume in The
Accounting Review I
just don't give a damn"
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
Bob Jensen's threads on the very sorry state of replicated research in
accountancy --- Scroll up to the table of contents of
this document
Validity of research outcomes is not a priority test of academic accountants
seeking mostly to add hit lines to resumes. Top journal editors (think The
Accounting Review) don't even want to publish readers comments on articles. If
TAR referees accept an article for publication it becomes truth ipso facto.
Elsevier and the 5 Diseases of Academic Research ---
https://www.elsevier.com/connect/5-diseases-ailing-research-and-how-to-cure-them
This article summarizes the “diseases” ailing
scientific research as identified in the article
“On
doing better science: From thrill of discovery to policy implications”
by John Antonakis, recently published in The Leadership Quarterly.
Various Elsevier associates then discuss how
they see these problems being addressed. Given the huge role that Elsevier
plays in academic publishing, their view of the problems of scientific
research/publishing, and their ideas regarding potential solutions, should
be of interest.
David Johnstone asked me to write a paper on the following:
"A Scrapbook on What's Wrong with the Past, Present and Future of Accountics
Science"
Bob Jensen
February 19, 2014
SSRN Download:
http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2398296
Abstract
For operational convenience I define accountics science as
research that features equations and/or statistical inference. Historically,
there was a heated debate in the 1920s as to whether the main research
journal of academic accounting, The Accounting Review (TAR) that
commenced in 1926, should be an accountics journal with articles that mostly
featured equations. Practitioners and teachers of college accounting won
that debate.
TAR articles and accountancy doctoral dissertations prior to
the 1970s seldom had equations. For reasons summarized below, doctoral
programs and TAR evolved to where in the 1990s there where having equations
became virtually a necessary condition for a doctoral dissertation and
acceptance of a TAR article. Qualitative normative and case method
methodologies disappeared from doctoral programs.
What’s really meant by “featured
equations” in doctoral programs is merely symbolic of the fact that North
American accounting doctoral programs pushed out most of the accounting to
make way for econometrics and statistics that are now keys to the kingdom
for promotion and tenure in accounting schools ---
http://faculty.trinity.edu/rjensen/Theory01.htm#DoctoralPrograms
The purpose of this paper is to make a case that the accountics science
monopoly of our doctoral programs and published research is seriously
flawed, especially its lack of concern about replication and focus on
simplified artificial worlds that differ too much from reality to creatively
discover findings of greater relevance to teachers of accounting and
practitioners of accounting. Accountics scientists themselves became a Cargo
Cult.
June 5, 2013 reply to a long
thread by Bob Jensen
Hi Steve,
As usual, these AECM threads between you, me, and Paul Williams resolve
nothing to date. TAR still has zero articles without equations unless such
articles are forced upon editors like the Kaplan article was forced upon you
as Senior Editor. TAR still has no commentaries about the papers it
publishes and the authors make no attempt to communicate and have dialog
about their research on the AECM or the AAA Commons.
I do hope that our AECM threads will continue and lead one day to when
the top academic research journals do more to both encourage (1) validation
(usually by speedy replication), (2) alternate methodologies, (3) more
innovative research, and (4) more interactive commentaries.
I remind you that Professor Basu's essay is only one of four essays
bundled together in Accounting Horizons on the topic of how to make
accounting research, especially the so-called Accounting Sciience or
Accountics Science or Cargo Cult science, more innovative.
The four essays in this bundle are summarized and extensively quoted at
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm#Essays
- "Framing the Issue of Research Quality in a Context of Research
Diversity," by Christopher S. Chapman ---
- "Accounting Craftspeople versus Accounting Seers: Exploring the
Relevance and Innovation Gaps in Academic Accounting Research," by
William E. McCarthy ---
- "Is Accounting Research Stagnant?" by Donald V. Moser ---
- Cargo Cult Science "How Can Accounting Researchers Become More
Innovative? by Sudipta Basu ---
I will try to keep drawing attention to these important essays and spend
the rest of my professional life trying to bring accounting research closer
to the accounting profession.
I also want to dispel the myth that accountics research is harder than
making research discoveries without equations. The hardest research I can
imagine (and where I failed) is to make a discovery that has a noteworthy
impact on the accounting profession. I always look but never find such
discoveries reported in TAR.
The easiest research is to purchase a database and beat it with an
econometric stick until something falls out of the clouds. I've searched for
years and find very little that has a noteworthy impact on the accounting
profession. Quite often there is a noteworthy impact on other members of the
Cargo Cult and doctoral students seeking to beat the same data with their
sticks. But try to find a practitioner with an interest in these academic
accounting discoveries?
Our latest thread leads me to such questions as:
- Is accounting research of inferior quality relative to other
disciplines like engineering and finance?
- Are there serious innovation gaps in academic accounting research?
- Is accounting research stagnant?
- How can accounting researchers be more innovative?
- Is there an "absence of dissent" in academic accounting research?
- Is there an absence of diversity in our top academic accounting
research journals and doctoral programs?
- Is there a serious disinterest (except among the Cargo Cult) and
lack of validation in findings reported in our academic accounting
research journals, especially TAR?
- Is there a huge communications gap between academic accounting
researchers and those who toil teaching accounting and practicing
accounting?
- Why do our accountics scientists virtually ignore the AECM and the
AAA Commons and the Pathways Commission Report?
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
One fall out of this thread is that I've been privately asked to write a
paper about such matters. I hope that others will compete with me in
thinking and writing about these serious challenges to academic accounting
research that never seem to get resolved.
Thank you Steve for sometimes responding in my threads on such issues in
the AECM.
Respectfully,
Bob Jensen
Rise in Research Cheating
"A Sharp Rise in Retractions Prompts Calls for Reform," by Carl Zimmer,
The New York Times, April 16, 2012 ---
http://www.nytimes.com/2012/04/17/science/rise-in-scientific-journal-retractions-prompts-calls-for-reform.html?_r=2&
In the fall of 2010, Dr. Ferric C. Fang made an
unsettling discovery. Dr. Fang, who is editor in chief of the journal
Infection and Immunity, found that one of his authors had doctored several
papers.
It was a new experience for him. “Prior to that
time,” he said in an interview, “Infection and Immunity had only retracted
nine articles over a 40-year period.”
The journal wound up retracting six of the papers
from the author, Naoki Mori of the University of the Ryukyus in Japan. And
it soon became clear that Infection and Immunity was hardly the only victim
of Dr. Mori’s misconduct. Since then, other scientific journals have
retracted two dozen of his papers, according to the watchdog blog Retraction
Watch.
“Nobody had noticed the whole thing was rotten,”
said Dr. Fang, who is a professor at the University of Washington School of
Medicine.
Dr. Fang became curious how far the rot extended.
To find out, he teamed up with a fellow editor at the journal, Dr. Arturo
Casadevall of the Albert Einstein College of Medicine in New York. And
before long they reached a troubling conclusion: not only that retractions
were rising at an alarming rate, but that retractions were just a
manifestation of a much more profound problem — “a symptom of a
dysfunctional scientific climate,” as Dr. Fang put it.
Dr. Casadevall, now editor in chief of the journal
mBio, said he feared that science had turned into a winner-take-all game
with perverse incentives that lead scientists to cut corners and, in some
cases, commit acts of misconduct.
“This is a tremendous threat,” he said.
Last month, in a pair of editorials in Infection
and Immunity, the two editors issued a plea for fundamental reforms. They
also presented their concerns at the March 27 meeting of the National
Academies of Sciences committee on science, technology and the law.
Members of the committee agreed with their
assessment. “I think this is really coming to a head,” said Dr. Roberta B.
Ness, dean of the University of Texas School of Public Health. And Dr. David
Korn of Harvard Medical School agreed that “there are problems all through
the system.”
No one claims that science was ever free of
misconduct or bad research. Indeed, the scientific method itself is intended
to overcome mistakes and misdeeds. When scientists make a new discovery,
others review the research skeptically before it is published. And once it
is, the scientific community can try to replicate the results to see if they
hold up.
But critics like Dr. Fang and Dr. Casadevall argue
that science has changed in some worrying ways in recent decades —
especially biomedical research, which consumes a larger and larger share of
government science spending.
In October 2011, for example, the journal Nature
reported that published retractions had increased tenfold over the past
decade, while the number of published papers had increased by just 44
percent. In 2010 The Journal of Medical Ethics published a study finding the
new raft of recent retractions was a mix of misconduct and honest scientific
mistakes.
Several factors are at play here, scientists say.
One may be that because journals are now online, bad papers are simply
reaching a wider audience, making it more likely that errors will be
spotted. “You can sit at your laptop and pull a lot of different papers
together,” Dr. Fang said.
But other forces are more pernicious. To survive
professionally, scientists feel the need to publish as many papers as
possible, and to get them into high-profile journals. And sometimes they cut
corners or even commit misconduct to get there.
To measure this claim, Dr. Fang and Dr. Casadevall
looked at the rate of retractions in 17 journals from 2001 to 2010 and
compared it with the journals’ “impact factor,” a score based on how often
their papers are cited by scientists. The higher a journal’s impact factor,
the two editors found, the higher its retraction rate.
The highest “retraction index” in the study went to
one of the world’s leading medical journals, The New England Journal of
Medicine. In a statement for this article, it questioned the study’s
methodology, noting that it considered only papers with abstracts, which are
included in a small fraction of studies published in each issue. “Because
our denominator was low, the index was high,” the statement said.
Continued in article
Bob Jensen's threads on cheating by faculty are at
http://faculty.trinity.edu/rjensen/Plagiarism.htm#ProfessorsWhoPlagiarize
August 14, 2013 reply from Dennis Huber
Hmmmm. I wonder. Does accounting research culture
also need to be reformed?
August 14, 2013 reply from Bob Jensen
Hi Dennis,
Academics have debated the need for reform in academic accounting
research for decades. There are five primary areas of recommended reform,
but those areas overlap a great deal.
One area of suggested reform is to make it less easy to cheat and commit
undetected errors in academic accounting research by forcing/encouraging
replication, which is part and parcel to quality control in real science ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
A second area of improvement would turn accountics science from a pseudo
science into a real science. Real science does not stop inferring causality
from correlation when the causality data needed is not contained in the
databases studied empirically with econometric models.
Real scientists granulate deeper and deeper for causal factors to test
whether correlations are spurious. Accountics scientists seldom granulate
beyond their purchased databases ---
http://www.cs.trinity.edu/~rjensen/temp/AccounticsGranulationCurrentDraft.pdf
A third area of improvement would arise if accountics scientists were
forced to communicate their research findings better with accounting
teachers and practitioners. Accountics scientists just do not care about
such communications and should be forced to communicate in other venues such
as having publication in a Tech Corner of the AAA Commons ---
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm#Commons
A fourth area of improvement would be expand research methods of
accountics science to take on more interesting topics that are not so
amenable to traditional quantitative and statistical modeling. See Cargo
Cult mentality criticisms of accountics scients at
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm#Essays
It might be argued that accountics scientists don't replicate their findings
because nobody gives a damn about their findings ---
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm#CargoCult
That's taking the criticisms too far. I find lots of accountics science
findings interesting. It's just that accountics scientists ignore topics
that I find more interesting --- particularly topics of interest to
accounting practitioners.
A fifth and related problem is that academic accounting inventors are
rare in comparison with academic inventors in science and engineering ---
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm#Inventors
I summarize how academic accounting researchers should change at
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
Shame on you Richard. You claimed a totally incorrect reason for
not having any interest in the Pathways Commission Report. It is totally
incorrect to assume that the PC Report resolutions apply only to the CPA
profession.
Did you ever read the PC Report?
http://commons.aaahq.org/files/0b14318188/Pathways_Commission_Final_Report_Complete.pdf
Perhaps you just never read as far as Page 109 of the PC Report
quoted below:
Accounting Profession
1. The need to enhance the bilateral
relationship between the practice community and academe.
From the perspective of the
profession, one impediment to change has been the lack of a consistent
relationship between a broadly defined profession (i.e.,
public, private, government) and a broadly defined academy—large
and small public and private institutions. This impediment can be broken
down into three subparts. First, the Commission recommends the organizations
and individuals in the practice community work with accounting educators to
provide access to their internal training seminars, so faculty can remain
current with the workings of the profession. These organizations also need
to develop internship-type opportunities for interested faculty. Second, the
practice community and regulators need to reduce the barriers academics have
in obtaining research data. All stakeholders must work together to determine
how to overcome the privacy, confidentiality, and regulatory issues that
impede a greater number of researchers from obtaining robust data needed for
many of these research projects. Having access to this data could be
instrumental in helping the academy provide timely answers to the profession
on the impact of policy decisions on business practice. Third, the
profession and the academy need to share pedagogy best practices and
resources, especially with respect to rapidly changing educational delivery
models as both are essential segments of the lifelong educational pathway of
accounting professionals.
Conversely, academia is not without
fault in the development of this relationship. The Commission recommends
that more institutions, possibly through new accreditation standards, engage
more practitioners as executives in residence in the classroom. These
individuals can provide a different perspective on various topics and thus
might better explain what they do, how they do it, and why they do it.
Additionally, the Commission recommends institutions utilize accounting
professionals through department advisory boards that can assist the
department in the development of its curriculum.
Jensen Comment
I contend that you are simply another accountics scientist member of the Cargo
Cult looking for feeble luddite excuses to run for cover from the Pathways
Commission resolutions, especially resolutions to conduct more clinical research
and add diversity to the curricula of accounting doctoral programs.
Thank you for this honesty. But have you ever looked at the Pathways Commission
Report?
Have you ever looked at the the varied professionals who generated this report
and support its resolutions? In addition to CPA firms and universities, many
of the Commissioners come from major employers of Tuck School graduates
including large and small corporations and consulting firms.
The Report is located at
http://commons.aaahq.org/files/0b14318188/Pathways_Commission_Final_Report_Complete.pdf
The Pathways Commission was made up of representatives of all segments of
accounting academe, industrial accounting, and not-for-profit accounting. This
Commission never intended its resolutions to apply only to only public
accounting, which by the way includes tax accounting where you do most of your
research. You're grasping at straws here Richard!
Most accountics Cargo Cult scientists are silent and smug with respect to the
Pathways Commission Report, especially it's advocacy of clinical research and
research methods extending beyond GLM data mining of commercial databases that
the AAA leadership itself is admitting has grown stale and lacks innovation ---
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm#Essays
This is a perfect opportunity for me to recall the cargo plane scene from a
movie called Mondo Cane ---
http://en.wikipedia.org/wiki/Mondo_cane
Sudipta Basu picked up on the Cargo Cult analogy to stagnation of
accountics science research over the past few decades.
"How Can Accounting Researchers Become
More Innovative? by Sudipta Basu, Accounting Horizons, December 2012,
Vol. 26, No. 4, pp. 851-87 ---
http://aaajournals.org/doi/full/10.2308/acch-10311
We fervently hope that the
research pendulum will soon swing back from the narrow lines of
inquiry that dominate today's leading journals to a rediscovery
of the richness of what accounting research can be. For that to
occur, deans and the current generation of academic accountants
must give it a push.�
Michael H. Granof and Stephen A. Zeff (2008)
Rather than clinging to the
projects of the past, it is time to explore questions and engage
with ideas that transgress the current accounting research
boundaries. Allow your values to guide the formation of your
research agenda. The passion will inevitably follow �
Joni J. Young (2009)
. . .
Is Academic Accounting a “Cargo Cult Science”?
In a commencement address at Caltech titled “Cargo
Cult Science,” Richard Feynman (1974) discussed “science, pseudoscience, and
learning how not to fool yourself.” He argued that despite great efforts at
scientific research, little progress was apparent in school education.
Reading and mathematics scores kept declining, despite schools adopting the
recommendations of experts. Feynman (1974, 11) dubbed fields like these
“Cargo Cult Sciences,” explaining the term as follows:
In the South Seas there is a Cargo Cult of people.
During the war they saw airplanes land with lots of good materials, and they
want the same things to happen now. So they've arranged to make things like
runways, to put fires along the sides of the runways, to make a wooden hut
for a man to sit in, with two wooden pieces on his head like headphones and
bars of bamboo sticking out like antennas—he's the controller—and they wait
for the airplanes to land. They're doing everything right. The form is
perfect. It looks exactly the way it looked before. But it doesn't work.
No airplanes land. So I call
these things Cargo Cult Science, because they follow all the apparent
precepts and forms of scientific investigation, but they're missing
something essential, because the planes don't land.
Feynman (1974) argued that the key distinction
between a science and a Cargo Cult Science is scientific integrity: “[T]he
idea is to give all of the information to help others judge the value of
your contribution; not just the information that leads to judgment in one
particular direction or another.” In other words, papers should not be
written to provide evidence for one's hypothesis, but rather to “report
everything that you think might make it invalid.” Furthermore, “you should
not fool the layman when you're talking as a scientist.”
Even though more and more detailed rules are
constantly being written by the SEC, FASB, IASB, PCAOB, AICPA, and other
accounting experts (e.g., Benston et al. 2006), the number and severity of
accounting scandals are not declining, which is Feynman's (1969) hallmark of
a pseudoscience. Because accounting standards often reflect
standard-setters' ideology more than research into the effectiveness of
different alternatives, it is hardly surprising that accounting quality has
not improved. Even preliminary research findings can be transformed
journalistically into irrefutable scientific results by the political
process of accounting standard-setting. For example, the working paper
results of Frankel et al. (2002) were used to justify the SEC's longstanding
desire to ban non-audit services in the Sarbanes-Oxley Act of 2002, even
though the majority of contemporary and subsequent studies found different
results (Romano 2005). Unfortunately, the ability to bestow status by
invitation to select conferences and citation in official documents (e.g.,
White 2005) may let standard-setters set our research and teaching agendas
(Zeff 1989). Academic Accounting and the “Cult of Statistical Significance”
Ziliak and McCloskey (2008) argue that, in trying
to mimic physicists, many biologists and social scientists have become
devotees of statistical significance, even though most articles in physics
journals do not report statistical significance. They argue that statistical
tests are typically used to infer whether a particular effect exists, rather
than to measure the magnitude of the effect, which usually has more
practical import. While early empirical accounting researchers such as Ball
and Brown (1968) and Beaver (1968) went to great lengths to estimate how
much extra information reached the stock market in the earnings announcement
month or week, subsequent researchers limited themselves to answering
whether other factors moderated these effects. Because accounting theories
rarely provide quantitative predictions (e.g., Kinney 1986), accounting
researchers perform nil hypothesis significance testing rituals, i.e., test
unrealistic and atheoretical null hypotheses that a particular coefficient
is exactly zero.15 While physicists devise experiments to measure the mass
of an electron to the accuracy of tens of decimal places, accounting
researchers are still testing the equivalent of whether electrons have mass.
Indeed, McCloskey (2002) argues that the “secret sins of economics” are that
economics researchers use quantitative methods to produce qualitative
research outcomes such as (non-)existence theorems and statistically
significant signs, rather than to predict and measure quantitative (how
much) outcomes.
Practitioners are more interested in magnitudes
than existence proofs, because the former are more relevant in decision
making. Paradoxically, accounting research became less useful in the real
world by trying to become more scientific (Granof and Zeff 2008). Although
every empirical article in accounting journals touts the statistical
significance of the results, practical significance is rarely considered or
discussed (e.g., Lev 1989). Empirical articles do not often discuss the
meaning of a regression coefficient with respect to real-world decision
variables and their outcomes. Thus, accounting research results rarely have
practical implications, and this tendency is likely worst in fields with the
strongest reliance on statistical significance such as financial reporting
research.
Ziliak and McCloskey (2008) highlight a deeper
concern about over-reliance on statistical significance—that it does not
even provide evidence about whether a hypothesis is true or false. Carver
(1978) provides a memorable example of drawing the wrong inference from
statistical significance:
What is the probability of obtaining a dead person
(label this part D) given that the person was hanged (label this part H);
this is, in symbol form, what is P(D|H)? Obviously, it will be very high,
perhaps 0.97 or higher. Now, let us reverse the question. What is the
probability that a person has been hanged (H), given that the person is dead
(D); that is, what is P(H|D)? This time the probability will undoubtedly be
very low, perhaps 0.01 or lower. No one would be likely to make the mistake
of substituting the first estimate (0.97) for the second (0.01); that is, to
accept 0.97 as the probability that a person has been hanged given that the
person is dead. Even though this seems to be an unlikely mistake, it is
exactly the kind of mistake that is made with interpretations of statistical
significance testing—by analogy, calculated estimates of P(D|H) are
interpreted as if they were estimates of P(H|D), when they clearly are not
the same.
As Cohen (1994) succinctly explains, statistical
tests assess the probability of observing a sample moment as extreme as
observed conditional on the null hypothesis being true, or P(D|H0), where D
represents data and H0 represents the null hypothesis. However, researchers
want to know whether the null hypothesis is true, conditional on the sample,
or P(H0|D). We can calculate P(H0|D) from P(D|H0) by applying Bayes'
theorem, but that requires knowledge of P(H0), which is what researchers
want to discover in the first place. Although Ziliak and McCloskey (2008)
quote many eminent statisticians who have repeatedly pointed out this basic
logic, the essential point has not entered the published accounting
literature.
In my view, restoring relevance to mathematically
guided accounting research requires changing our role model from applied
science to engineering (Colander 2011).16 While science aims at finding
truth through application of institutionalized best practices with little
regard for time or cost, engineering seeks to solve a specific problem using
available resources, and the engineering method is “the strategy for causing
the best change in a poorly understood or uncertain situation within the
available resources” (Koen 2003). We should move to an experimental approach
that simulates real-world applications or field tests new accounting methods
in particular countries or industries, as would likely happen by default if
accounting were not monopolized by the IASB (Dye and Sunder 2001). The
inductive approach to standard-setting advocated by Littleton (1953) is
likely to provide workable solutions to existing problems and be more useful
than an axiomatic approach that starts from overly simplistic first
principles.
To reduce the gap between academe and practice and
stimulate new inquiry, AAA should partner with the FEI or Business
Roundtable to create summer, semester, or annual research internships for
accounting professors and Ph.D. students at corporations and audit firms.17
Accounting professors who have served as visiting scholars at the SEC and
FASB have reported positively about their experience (e.g., Jorgensen et al.
2007), and I believe that such practice internships would provide
opportunities for valuable fieldwork that supplements our experimental and
archival analyses. Practice internships could be an especially fruitful way
for accounting researchers to spend their sabbaticals.
Another useful initiative would be to revive the
tradition of The Accounting Review publishing papers that do not rely on
statistical significance or mathematical notation, such as case studies,
field studies, and historical studies, similar to the Journal of Financial
Economics (Jensen et al. 1989).18 A separate editor, similar to the book
reviews editor, could ensure that appropriate criteria are used to evaluate
qualitative research submissions (Chapman 2012). A co-editor from practice
could help ensure that the topics covered are current and relevant, and help
reverse the steep decline in AAA professional membership. Encouraging
diversity in research methods and topics is more likely to attract new
scholars who are passionate and intrinsically care about their research,
rather than attracting only those who imitate current research fads for
purely instrumental career reasons.
The relevance of accounting journals can be
enhanced by inviting accomplished guest authors from outside accounting. The
excellent April 1983 issue of The Accounting Review contains a section
entitled “Research Perspectives from Related Disciplines,” which includes
essays by Robert Wilson (Decision Sciences), Michael Jensen and Stephen Ross
(Finance and Economics), and Karl Weick (Organizational Behavior) that were
based on invited presentations at the 1982 AAA Annual Meeting. The
thought-provoking essays were discussed by prominent accounting academics
(Robert Kaplan, Joel Demski, Robert Libby, and Nils Hakansson); I still use
Jensen (1983) to start each of my Ph.D. courses. Academic outsiders bring
new perspectives to familiar problems and can often reframe them in ways
that enable solutions (Tullock 1966).
I still lament that no accounting journal editor
invited the plenary speakers—Joe Henrich, Denise Schmandt-Besserat, Michael
Hechter, Eric Posner, Robert Lucas, and Vernon Smith—at the 2007 AAA Annual
Meeting to write up their presentations for publication in accounting
journals. It is rare that Nobel Laureates and U.S. Presidential Early Career
Award winners address AAA annual meetings.20 I strongly urge that AAA annual
meetings institute a named lecture given by a distinguished researcher from
a different discipline, with the address published in The Accounting Review.
This would enable cross-fertilization of ideas between accounting and other
disciplines. Several highly cited papers published in the Journal of
Accounting and Economics were written by economists (Watts 1998), so this
initiative could increase citation flows from accounting journals to other
disciplines.
HOW CAN WE MAKE U.S. ACCOUNTING JOURNALS MORE
READABLE AND INTERESTING?
Even the greatest discovery will have little impact
if other people cannot understand it or are unwilling to make the effort.
Zeff (1978) says, “Scholarly writing need not be abstruse. It can and should
be vital and relevant. Research can succeed in illuminating the dark areas
of knowledge and facilitating the resolution of vexing problems—but only if
the report of research findings is communicated to those who can carry the
findings further and, in the end, initiate change.” If our journals put off
readers, then our research will not stimulate our students or induce change
in practice (Dyckman 1989).
Michael Jensen (1983, 333–334) addressed the 1982
AAA Annual Meeting saying:
Unfortunately, there exists in the profession an
unwarranted bias toward the use of mathematics even in situations where it
is unproductive or useless. One manifestation of this is the common use of
the terms “rigorous” or “analytical” or even “theoretical” as identical with
‘‘mathematical.” None of these links is, of course, correct. Mathematical is
not the same as rigorous, nor is it the same as analytical or theoretical.
Propositions can be logically rigorous without being mathematical, and
analysis does not have to take the form of symbols and equations. The
English sentence and paragraph will do quite well for many analytical
purposes. In addition, the use of mathematics does not prevent the
commission of errors—even egregious ones.
Unfortunately, the top accounting journals
demonstrate an increased “tyranny of formalism” that “develops when
mathematically inclined scholars take the attitude that if the analytical
language is not mathematics, it is not rigorous, and if a problem cannot be
solved with the use of mathematics, the effort should be abandoned” (Jensen
1983, 335). Sorter (1979) acidly described the transition from normative to
quantitative research: “the golden age of empty blindness gave way in the
sixties to bloated blindness calculated to cause indigestion. In the
sixties, the wonders of methodology burst upon the minds of accounting
researchers. We entered what Maslow described as a mean-oriented age.
Accountants felt it was their absolute duty to regress, regress and
regress.” Accounting research increasingly relies on mathematical and
statistical models with highly stylized and unrealistic assumptions. As
Young (2006) demonstrates, the financial statement “user” in accounting
research and regulation bears little resemblance to flesh-and-blood
individuals, and hence our research outputs often have little relevance to
the real world.
Figure 1 compares how frequently accountants and
members of ten other professions are cited in The New York Times in the late
1990s (Ellenberg 2000). These data are juxtaposed with the numbers employed
in each profession during 1996 using U.S. census data. Accountants are cited
less frequently relative to their numbers than any profession except
computer programmers. One possibility is that journalists cannot detect
anything interesting in accounting journals. Another possibility is that
university public relations staffs are consistently unable to find an
interesting angle in published accounting papers that they can pitch to
reporters. I have little doubt that the obscurantist tendencies in
accounting papers make it harder for most outsiders to understand what
accounting researchers are saying or find interesting.
Accounting articles have also become much longer
over time, and I am regularly asked to review articles with introductions
that are six to eight pages long, with many of the paragraphs cut-and-pasted
from later sections. In contrast, it took Watson and Crick (1953) just one
journal page to report the double-helix structure of DNA. Einstein (1905)
took only three journal pages to derive his iconic equation E = mc2. Since
even the best accounting papers are far less important than these classics
of 20th century science, readers waste time wading through academic bloat
(Sorter 1979). Because the top general science journals like Science and
Nature place strict word limits on articles that differ by the expected
incremental contribution, longer scientific papers signal better quality.21
Unfortunately, accounting journals do not restrict length, which encourages
bloated papers. Another driver of length is the aforementioned trend toward
greater rigor in the review process (Ellison 2002).
My first suggestion for making published accounting
articles less tedious and boring is to impose strict word limits and to
revive the “Notes” sections for shorter contributions. Word limits force
authors to think much harder about how to communicate their essential ideas
succinctly and greatly improve writing. Similarly, I would encourage
accounting journals to follow Nature and provide guidelines for informative
abstracts.22 A related suggestion is to follow the science journals, and
more recently, The American Economic Review, by introducing online-only
appendices to report the lengthy robustness sections that are demanded by
persnickety reviewers.23 In addition, I strongly encourage AAA journals to
require authors to post online with each journal article the data sets and
working computer code used to produce all tables as a condition for
publication, so that other independent researchers can validate and
replicate their studies (Bernanke 2004; McCullough and McKitrick 2009).24
This is important because recent surveys of science and management
researchers reveal that data fabrication, data falsification, and other
violations in published studies is far from rare (Martinson et al. 2005;
Bedeian et al. 2010).
I also urge that authors report results graphically
rather than in tables, as recommended by numerous statistical experts (e.g.,
Tukey 1977; Chambers et al. 1983; Wainer 2009). For example, Figure 2 shows
how the data in Figure 1 can be displayed more effectively without taking up
more page space (Gelman et al. 2002). Scientific papers routinely display
results in figures with confidence intervals rather than tables with
standard errors and p-values, and accounting journals should adopt these
practices to improve understandability. Soyer and Hogarth (2012) show
experimentally that even well-trained econometricians forecast more slowly
and inaccurately when given tables of statistical results than when given
equivalent scatter plots. Most accounting researchers cannot recognize the
main tables of Ball and Brown (1968) or Beaver (1968) on sight, but their
iconic figures are etched in our memories. The figures in Burgstahler and
Dichev (1997) convey their results far more effectively than tables would.
Indeed, the finance professoriate was convinced that financial markets are
efficient by the graphs in Fama et al. (1969), a highly influential paper
that does not contain a single statistical test! Easton (1999) argues that
the 1990s non-linear earnings-return relation literature would likely have
been developed much earlier if accounting researchers routinely plotted
their data. Since it is not always straightforward to convert tables into
graphs (Gelman et al. 2002), I recommend that AAA pay for new editors of AAA
journals to take courses in graphical presentation.
I would also recommend that AAA award an annual
prize for the best figure or graphic in an accounting journal each year. In
addition to making research articles easier to follow, figures ease the
introduction of new ideas into accounting textbooks. Economics is routinely
taught with diagrams and figures to aid intuition—demand and supply curves,
IS-LM analysis, Edgeworth boxes, etc. (Blaug and Lloyd 2010). Accounting
teachers would benefit if accounting researchers produced similar education
tools. Good figures could also be used to adorn the cover pages of our
journals similar to the best science journals; in many disciplines, authors
of lead articles are invited to provide an illustration for the cover page.
JAMA (Journal of the American Medical Association) reproduces paintings
depicting doctors on its cover (Southgate 1996); AAA could print paintings
of accountants and accounting on the cover of The Accounting Review, perhaps
starting with those collected in Yamey (1989). If color printing costs are
prohibitive, we could imitate the Journal of Political Economy back cover
and print passages from literature where accounting and accountants play an
important role, or even start a new format by reproducing cartoons
illustrating accounting issues. The key point is to induce accountants to
pick up each issue of the journal, irrespective of the research content.
I think that we need an accounting journal to “fill
a gap between the general-interest press and most other academic journals,”
similar to the Journal of Economics Perspectives (JEP).25 Unlike other
economics journals, JEP editors and associate editors solicit articles from
experts with the goal of conveying state-of-the-art economic thinking to
non-specialists, including students, the lay public, and economists from
other specialties.26 The journal explicitly eschews mathematical notation or
regression results and requires that results be presented either graphically
or as a table of means. In response to the question “List the three
economics journals (broadly defined) that you read most avidly when a new
issue appears,” a recent survey of U.S. economics professors found that
Journal of Economics Perspectives was their second favorite economics
journal (Davis et al. 2011), which suggests that an unclaimed niche exists
in accounting. Although Accounting Horizons could be restructured along
these lines to better reach practitioners, it might make sense to start a
new association-wide journal under the AAA aegis.
CONCLUSION
I believe that accounting is one of the most
important human innovations. The invention of accounting records was likely
indispensable to the emergence of agriculture, and ultimately, civilization
(e.g., Basu and Waymire 2006). Many eminent historians view double-entry
bookkeeping as indispensable for the Renaissance and the emergence of
capitalism (e.g., Sombart 1919; Mises 1949; Weber 1927), possibly via
stimulating the development of algebra (Heeffer 2011). Sadly, accounting
textbooks and the top U.S. accounting journals seem uninterested in whether
and how accounting innovations changed history, or indeed in understanding
the history of our current practices (Zeff 1989).
In short, the accounting academy embodies a
“tragedy of the commons” (Hardin 1968) where strong extrinsic incentives to
publish in “top” journals have led to misdirected research efforts. As Zeff
(1983) explains, “When modeling problems, researchers seem to be more
affected by technical developments in the literature than by their potential
to explain phenomena. So often it seems that manuscripts are the result of
methods in search of questions rather than questions in search of methods.”
Solving common problems requires strong collective action by the social
network of accounting researchers using self-governing mechanisms (e.g.,
Ostrom 1990, 2005). Such initiatives should occur at multiple levels (e.g.,
school, association, section, region, and individual) to have any chance of
success.
While accounting research has made advances in
recent decades, our collective progress seems slow, relative to the hard
work put in by so many talented researchers. Instead of letting financial
economics and psychology researchers and accounting standard-setters choose
our research methods and questions, we should return our focus to addressing
fundamental issues in accounting. As important, junior researchers should be
encouraged to take risks and question conventional academic wisdom, rather
than blindly conform to the party line. For example, the current FASB–IASB
conceptual framework “remains irreparably flawed” (Demski 2007), and
accounting researchers should take the lead in developing alternative
conceptual frameworks that better fit what accounting does (e.g., Ijiri
1983; Ball 1989; Dickhaut et al. 2010). This will entail deep historical and
cross-cultural analyses rather than regression analyses on machine-readable
data. Deliberately attacking the “fundamental and frequently asked
questions” in accounting will require innovations in research outlooks and
methods, as well as training in the history of accounting thought. It is
shameful that we still cannot answer basic questions like “Why did anyone
invent recordkeeping?” or “Why is double-entry bookkeeping beautiful?”
Bravo to Professor Basu for having the guts address the Cargo
Cult in this manner!
Respectfully,
Bob Jenesen
Major problems in accountics science:
Problem 1 --- Control Over Research Methods Allowed in Doctoral
Programs and Leading
Academic Accounting Research Journals
Accountics scientists control the leading accounting research journals and
only allow archival (data mining), experimental, and analytical research
methods into those journals. Their referees shun other methods like case
method research, field studies, accounting history studies, commentaries,
and criticisms of accountics science.
This is the major theme of Anthony Hopwood, Paul Williams, Bob Sterling, Bob
Kaplan, Steve Zeff, Dan Stone, and others ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm#Appendix01
Since there are so many other accounting research journals in academe and
in the practitioner profession, why single out TAR and the other very "top"
journals because they refuse to publish any articles without equations
and/or statistical inference tables. Accounting researchers have hundreds of
other alternatives for publishing their research.
I'm critical of TAR referees because they're symbolic of today's many
problems with the way the accountics scientists have taken over the research
arm of accounting higher education. Over the past five decades they've taken
over all AACSB doctoral programs with a philosophy that "it's our way or
the highway" for students seeking PhD or DBA degrees ---
http://faculty.trinity.edu/rjensen/Theory01.htm#DoctoralPrograms
In
the United States, following the Gordon/Howell and Pierson reports in the
1950s, our accounting doctoral programs and leading academic journals bet
the farm on the social sciences without taking the due cautions of realizing
why the social sciences are called "soft sciences." They're soft because
"not everything that can be counted, counts. And not everything that counts
can be counted."
Be Careful What You
Wish For
Academic accountants wanted to become more respectable on their campuses by
creating accountics scientists in literally all North American accounting
doctoral programs. Accountics scientists virtually all that our PhD and DBA
programs graduated over the ensuing decades and they took on an elitist
attitude that it really did not matter if their research became ignored by
practitioners and those professors who merely taught accounting.
One of my complaints
with accountics scientists is that they appear to be unconcerned that they
are not not real scientists. In real science the primary concern in
validity, especially validation by replication. In accountics science
validation and replication are seldom of concern. Real scientists react to
their critics. Accountics scientists ignore their critics.
Another complaint is
that accountics scientists only take on research that they can model. The
ignore the many problems, particularly problems faced by the accountancy
profession, that they cannot attack with equations and statistical
inference.
"Research
on Accounting Should Learn From the Past" by Michael H. Granof and
Stephen A. Zeff, Chronicle of Higher Education, March 21, 2008
The
unintended consequence has been that interesting and researchable
questions in accounting are essentially being ignored.
By confining the major thrust in research to phenomena that can be
mathematically modeled or derived from electronic databases, academic
accountants have failed to advance the profession in ways that are
expected of them and of which they are capable.
Academic research has unquestionably broadened the views of standards
setters as to the role of accounting information and how it affects the
decisions of individual investors as well as the capital markets.
Nevertheless, it has had scant influence on the standards themselves.
Continued in
article
Problem 2 --- Paranoia Regarding Validity Testing and Commentaries on
their Research
This is the major theme of Bob Jensen, Paul Williams, Joni Young and
others
574 Shields Against Validity Challenges in Plato's Cave ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
Problem 3 --- Lack of Concern over Being Ignored by Accountancy Teachers and Practitioners
Accountics scientists only communicate through their research journals that
are virtually ignored by most accountancy teachers and practitioners. Thus
they are mostly gaming in Plato's Cave and having little impact on the
outside world, which is a major criticism raised by then AAA President Judy
Rayburn and Roger Hermanson and others
http://faculty.trinity.edu/rjensen/395wpTAR/Web/TAR395wp.htm
Also see
http://faculty.trinity.edu/rjensen/theory01.htm#WhatWentWrong
Some accountics scientists have even
warned against doing research for the practicing profession as a
"vocational virus."
Joel
Demski steers us away from the clinical side of the accountancy
profession by saying we should avoid that pesky “vocational virus.”
(See below).
The (Random House) dictionary defines
"academic" as "pertaining to areas of study that are not primarily
vocational or applied , as the humanities or pure mathematics."
Clearly, the short answer to the question is no, accounting is not
an academic discipline.
Joel Demski, "Is Accounting an Academic Discipline?"
Accounting Horizons, June 2007, pp. 153-157
Statistically there are a few youngsters
who came to academia for the joy of learning, who are yet relatively
untainted by the vocational virus.
I urge you to nurture your taste for learning, to follow your joy.
That is the path of scholarship, and it is the only one with any
possibility of turning us back toward the academy.
Joel Demski, "Is Accounting an Academic Discipline?
American Accounting Association Plenary Session" August 9, 2006 ---
http://faculty.trinity.edu/rjensen//theory/00overview/theory01.htm
Too
many accountancy doctoral programs have immunized themselves against
the “vocational virus.” The problem lies not in requiring doctoral
degrees in our leading colleges and universities. The problem is
that we’ve been neglecting the clinical needs of our profession.
Perhaps the real underlying reason is that our clinical problems are
so immense that academic accountants quake in fear of having to make
contributions to the clinical side of accountancy as opposed to the
clinical side of finance, economics, and psychology.
Problem 4 --- Ignoring Critics: The Accountics Science Wall of Silence
Leading scholars critical of accountics science included Bob Anthony,
Charles Christiensen, Anthony Hopwood, Paul Williams Roger Hermanson, Bob
Sterling, Jane Mutchler, Judy Rayburn, Bob Kaplan, Steve Zeff, Joni Young,
Bob Sterling, Dan Stone, Bob Jensen, and many others. The most frustrating
thing for these critics is that accountics scientists are content with being
the highest paid faculty on their campuses and their monopoly control of
accounting PhD programs (limiting outputs of graduates)
to a point where they literally ignore they critics and rarely, if ever,
respond to criticisms.
See
http://faculty.trinity.edu/rjensen/395wpTAR/Web/TAR395wp.htm
"Frankly, Scarlett, after I get a hit for my resume in The
Accounting Review I just don't give a damn"
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
Hi David,
Separately and independently, both
Steve Kachelmeier (Texas) and Bob Kaplan (Harvard) singled out
the Hunton and Gold (2010) TAR article as being an excellent
paradigm shift model in the sense that the data supposedly was
captured by practitioners with the intent of jointly working
with academic experts in collecting and analyzing the data
---
If that data had subsequently not been
challenged for integrity (by whom is secret) that Hunton and Gold
(2010) research us the type of thing we definitely would like to see
more of in accountics research.
Unfortunately, this excellent example may
have been a bit like Lance Armstrong being such a winner because he did
not playing within the rules.
For Jim Hunton maybe the world did
end on December 21, 2012
"Following Retraction, Bentley
Professor Resigns," Inside Higher Ed, December 21, 2012 ---
http://www.insidehighered.com/quicktakes/2012/12/21/following-retraction-bentley-professor-resigns
James E. Hunton, a
prominent accounting professor at Bentley University, has resigned
amid an investigation of the retraction of an article of which he
was the co-author, The Boston Globe reported. A spokeswoman cited
"family and health reasons" for the departure, but it follows the
retraction of an article he co-wrote in the journal Accounting
Review. The university is investigating the circumstances that led
to the journal's decision to retract the piece.
An Accounting Review Article
is Retracted
One of the
article that Dan mentions has been retracted, according to
http://aaajournals.org/doi/abs/10.2308/accr-10326?af=R
Retraction: A Field
Experiment Comparing the Outcomes of Three Fraud Brainstorming
Procedures: Nominal Group, Round Robin, and Open Discussion
James E. Hunton,
Anna Gold Bentley University and Erasmus University Erasmus
University This article was originally published in 2010 in The
Accounting Review 85 (3) 911–935; DOI:
10/2308/accr.2010.85.3.911
The authors
confirmed a misstatement in the article and were unable to provide
supporting information requested by the editor and publisher.
Accordingly, the article has been retracted.
Jensen Comment
The TAR article retraction in no way detracts from this study being a
model to shoot for in order to get accountics researchers more involved
with the accounting profession and using their comparative advantages to
analyze real world data that is more granulated that the usual practice
of beating purchased databases like Compustat with econometric sticks
and settling for correlations rather than causes.
Respectfully,
Bob Jensen
Some Comments About Accountics Science Versus Real Science
This is the lead article in the May 2013 edition of The Accounting Review
"On Estimating Conditional Conservatism
Authors
Ray Ball (The University of Chicago)
S. P. Kothari )Massachusetts Institute of Technology)
Valeri V. Nikolaev (The University of Chicago)
The Accounting Review, Volume 88, No. 3, May 2013, pp. 755-788
The concept of conditional conservatism (asymmetric
earnings timeliness) has provided new insight into financial reporting and
stimulated considerable research since Basu (1997). Patatoukas and Thomas
(2011) report bias in firm-level cross-sectional asymmetry estimates that
they attribute to scale effects. We do not agree with their advice that
researchers should avoid conditional conservatism estimates and inferences
from research based on such estimates. Our theoretical and empirical
analyses suggest the explanation is a correlated omitted variables problem
that can be addressed in a straightforward fashion, including fixed-effects
regression. Correlation between the expected components of earnings and
returns biases estimates of how earnings incorporate the information
contained in returns. Further, the correlation varies with returns, biasing
asymmetric timeliness estimates. When firm-specific effects are taken into
account, estimates do not exhibit the bias, are statistically and
economically significant, are consistent with priors, and behave as a
predictable function of book-to-market, size, and leverage.
. . .
We build on and provide a different interpretation
of the anomalous evidence reported by PT. We begin by replicating their
[Basu (1997). Patatoukas and Thomas (2011)] results. We then provide
evidence that scale-related effects are not the explanation. We control for
scale by sorting observations into relatively narrow portfolios based on
price, such that within each portfolio approximately 99 percent of the
cross-sectional variation in scale is eliminated. If scale effects explain
the anomalous evidence, then it would disappear within these portfolios, but
the estimated asymmetric timeliness remains considerable. We conclude that
the data do not support the scale-related explanation.4 It thus becomes
necessary to look for a better explanation.
Continued in article
Jensen Comment
The good news is that the earlier findings were replicated. This is not common
in accountics science research. The bad news is that such replications took 16
years and two years respectively. And the probability that TAR will publish a
one or more commentaries on these findings is virtually zero.
How does this differ from real science?
In real science most findings are replicated before or very quickly after
publication of scientific findings. And interest is in the reproducible results
without also requiring an extension of the research for publication of the
replication outcomes.
In accountics science there is little incentive to perform exact replications
since top accountics science journals neither demand such replications nor will
they publish (even in commentaries) replication outcomes. A necessary condition
to publish replication outcomes in accountics science is the extend the research
into new frontiers.
How long will it take for somebody to replicate these May 2013 findings of
Ball, Kothari, and Nikolaev? If the past is any indicator of the future the BKN
findings will never be replicated. If they are replicated it will most likely
take years before we receive notice of such replication in an extension of the
BKN research published in 2013.
CONCLUSION from
http://faculty.trinity.edu/rjensen/395wpTAR/Web/TAR395wp.htm
In the first 40 years of
TAR, an accounting “scholar” was first and foremost an expert on accounting.
After 1960, following the Gordon and Howell Report, the perception of what
it took to be a “scholar” changed to quantitative modeling. It became
advantageous for an “accounting” researcher to have a degree in mathematics,
management science, mathematical economics, psychometrics, or econometrics.
Being a mere accountant no longer was sufficient credentials to be deemed a
scholarly researcher. Many doctoral programs stripped much of the accounting
content out of the curriculum and sent students to mathematics and social
science departments for courses. Scholarship on accounting standards became
too much of a time diversion for faculty who were “leading scholars.”
Particularly relevant in this regard is Dennis Beresford’s address to the
AAA membership at the 2005 Annual AAA Meetings in San Francisco:
In my eight years in teaching I’ve concluded that way too many of
us don’t stay relatively up to date on professional issues. Most of
us have some experience as an auditor, corporate accountant, or in some
similar type of work. That’s great, but things change quickly these days.
Beresford [2005]
Jane Mutchler made a similar appeal for accounting professors
to become more involved in the accounting profession when she was President
of the AAA [Mutchler, 2004, p. 3].
In the last 40 years, TAR’s
publication preferences shifted toward problems amenable to scientific
research, with esoteric models requiring accountics skills in place of
accounting expertise. When Professor Beresford attempted to publish his
remarks, an Accounting Horizons referee’s report to him contained the
following revealing reply about “leading scholars” in accounting research:
1. The paper provides specific recommendations for things that
accounting academics should be doing to make the accounting profession
better. However (unless the author believes that academics' time is a free
good) this would presumably take academics' time away from what they are
currently doing. While following the author's advice might make the
accounting profession better, what is being made worse? In other words,
suppose I stop reading current academic research and start reading news
about current developments in accounting standards. Who is made better off
and who is made worse off by this reallocation of my time? Presumably my
students are marginally better off, because I can tell them some new stuff
in class about current accounting standards, and this might possibly have
some limited benefit on their careers. But haven't I made my colleagues in
my department worse off if they depend on me for research advice, and
haven't I made my university worse off if its academic reputation suffers
because I'm no longer considered a leading scholar? Why does making
the accounting profession better take precedence over everything else an
academic does with their time?
As quoted in Jensen [2006a]
The above quotation illustrates the consequences of editorial
policies of TAR and several other leading accounting research journals. To
be considered a “leading scholar” in accountancy, one’s research must employ
mathematically-based economic/behavioral theory and quantitative modeling.
Most TAR articles published in the past two decades support this contention.
But according to AAA President Judy Rayburn and other recent AAA presidents,
this scientific focus may not be in the best interests of accountancy
academicians or the accountancy profession.
In terms of citations, TAR
fails on two accounts. Citation rates are low in practitioner journals
because the scientific paradigm is too narrow, thereby discouraging
researchers from focusing on problems of great interest to practitioners
that seemingly just do not fit the scientific paradigm due to lack of
quality data, too many missing variables, and suspected non-stationarities.
TAR editors are loath to open TAR up to non-scientific methods so that
really interesting accounting problems are neglected in TAR. Those
non-scientific methods include case method studies, traditional historical
method investigations, and normative deductions.
In the other account, TAR
citation rates are low in academic journals outside accounting because the
methods and techniques being used (like CAPM and options pricing models)
were discovered elsewhere and accounting researchers are not sought out for
discoveries of scientific methods and models. The intersection of models and
topics that do appear in TAR seemingly are borrowed models and uninteresting
topics outside the academic discipline of accounting.
We close with a quotation
from Scott McLemee demonstrating that what happened among accountancy
academics over the past four decades is not unlike what happened in other
academic disciplines that developed “internal dynamics of esoteric
disciplines,” communicating among themselves in loops detached from their
underlying professions. McLemee’s [2006] article stems from Bender [1993].
“Knowledge and competence increasingly developed out of the
internal dynamics of esoteric disciplines rather than within the context of
shared perceptions of public needs,” writes Bender. “This is not to say that
professionalized disciplines or the modern service professions that imitated
them became socially irresponsible. But their contributions to society began
to flow from their own self-definitions rather than from a reciprocal
engagement with general public discourse.”
Now, there is a definite note of sadness in Bender’s narrative –
as there always tends to be in accounts
of the
shift from Gemeinschaft to Gesellschaft.
Yet it is also clear that the transformation from
civic to disciplinary professionalism was necessary.
“The new disciplines offered relatively precise subject matter and
procedures,” Bender concedes, “at a time when both were greatly confused.
The new professionalism also promised guarantees of competence —
certification — in an era when criteria of intellectual authority were vague
and professional performance was unreliable.”
But in the epilogue to Intellect and Public Life,
Bender suggests that the process eventually went too far. “The risk now is
precisely the opposite,” he writes. “Academe is threatened by the twin
dangers of fossilization and scholasticism (of three types: tedium, high
tech, and radical chic). The agenda for the next decade, at least as I see
it, ought to be the opening up of the disciplines, the ventilating of
professional communities that have come to share too much and that have
become too self-referential.”
For the good of the AAA membership and
the profession of accountancy in general, one hopes that the changes in
publication and editorial policies at TAR proposed by President Rayburn
[2005, p. 4] will result in the “opening up” of topics and research methods
produced by “leading scholars.”
The purpose of this document is to focus on Problem 2 above. Picking on TAR
is merely symbolic of my concerns with the larger problem of the what I view are
much larger problems caused by the take over of the research arm of academic
accountancy.
Epistemologists present several challenges to Popper's arguments
"Separating the Pseudo From Science," by Michael D. Gordon, Chronicle
of Higher Education, September 17, 2012 ---
http://chronicle.com/article/Separating-the-Pseudo-From/134412/
Hi Pat,
Certainly expertise and dedication to students rather than any college degree is
what's important in teaching.
However, I would not go so far as to detract from the research (discovery of new
knowledge) mission of the university by taking all differential pay incentives
away from researchers who, in addition to teaching, are taking on the drudge
work and stress of research and refereed publication.
Having said that, I'm no longer in favor of the tenure system since in most
instances it's more dysfunctional than functional for long-term research and
teaching dedication. In fact, it's become more of an exclusive club that gets
away with most anything short of murder.
My concern with accounting and business is how we define "research,"
Empirical and analytical research that has zero to say about causality is given
too much priority in pay, release time, and back slapping.
"How Non-Scientific Granulation Can Improve Scientific Accountics"
http://www.cs.trinity.edu/~rjensen/temp/AccounticsGranulationCurrentDraft.pdf
By Bob Jensen
This essay takes off from the following quotation:
A recent accountics science study suggests
that audit firm scandal with respect to someone else's audit may be a reason
for changing auditors.
"Audit Quality and Auditor Reputation: Evidence from Japan," by Douglas J.
Skinner and Suraj Srinivasan, The Accounting Review, September 2012,
Vol. 87, No. 5, pp. 1737-1765.
Our conclusions are subject
to two caveats. First, we find that clients switched away from ChuoAoyama in
large numbers in Spring 2006, just after Japanese regulators announced the
two-month suspension and PwC formed Aarata. While we interpret these events
as being a clear and undeniable signal of audit-quality problems at
ChuoAoyama, we cannot know for sure what drove these switches
(emphasis added). It
is possible that the suspension caused firms to switch auditors for reasons
unrelated to audit quality. Second, our analysis presumes that audit quality
is important to Japanese companies. While we believe this to be the case,
especially over the past two decades as Japanese capital markets have
evolved to be more like their Western counterparts, it is possible that
audit quality is, in general, less important in Japan
(emphasis added)
.
Richard Feynman Creates a Simple Method for Telling Science From
Pseudoscience (1966) ---
http://www.openculture.com/2016/04/richard-feynman-creates-a-simple-method-for-telling-science-from-pseudoscience-1966.html
By Feynman's standard standard accountics science is pseudoscience --
We Should Not Accept Scientific Results That Have Not
Been Repeated ---
http://nautil.us/blog/-we-should-not-accept-scientific-results-that-have-not-been-repeated
Jensen Comment
Accountics researchers get a pass since they're not really scientists and
virtually nobody is interested in replicating academic accounting research
findings published in leading academic accounting research journals that
discourage both commentaries and replication studies ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
Having said this I often cite accountics research findings
myself as if they were truth. Sometimes they're all I've got. Sigh!
Econometrics: Is it Time for a Journal of Insignificant Results ---
http://davegiles.blogspot.com/2017/03/a-journal-of-insignificant-economic.html
P-Value --- https://en.wikipedia.org/wiki/P-value
ASA = American Statistical Association
The ASA's statement on p-values: context, process, and purpose ---
http://amstat.tandfonline.com/doi/abs/10.1080/00031305.2016.1154108
Learn to p-Hack Like the Pros! ---
https://replicationnetwork.com/2016/10/19/schonbrodt-p-hacking-for-pros/
"Lies, Damn Lies, and Financial Statistics," by Peter Coy, Bloomberg,
April 10, 2017 ---
https://www.bloomberg.com/news/articles/2017-04-06/lies-damn-lies-and-financial-statistics
Early in January in a Chicago hotel, Campbell Harvey
gave a rip-Harvey’s term for torturing the
data until it confesses is “p-hacking,” a reference to the p-value,
a measure of statistical significance. P-hacking
is also known as overfitting, data-mining—or data-snooping, the coinage of
Andrew Lo, director of MIT’s Laboratory of Financial Engineering. Says Lo:
“The more you search over the past, the more likely it is you are going to
find exotic patterns that you happen to like or focus on. Those patterns are
least likely to repeat.”snorting presidential address to the American
Finance Association, the world’s leading society for research on financial
economics. To get published in journals, he said, there’s a powerful
temptation to torture the data until it confesses—that is, to conduct round
after round of tests in search of a finding that can be claimed to be
statistically significant. Said Harvey, a professor at Duke University’s
Fuqua School of Business: “Unfortunately, our standard testing methods are
often ill-equipped to answer the questions that we pose.” He exhorted the
group: “We are not salespeople. We are scientists!”
The problems Harvey
identified in academia are as bad or worse in the investing world.
Mass-market products such as exchange-traded funds are being concocted using
the same flawed statistical techniques you find in scholarly journals. Most
of the empirical research in finance is likely false, Harvey wrote in a
paper with a Duke colleague, Yan Liu, in 2014. “This implies that half the
financial products (promising outperformance) that companies are selling to
clients are false.”
. . .
In the wrong hands, though, backtesting can go
horribly wrong. It once found that the best predictor of the S&P 500, out of
all the series in a batch of United Nations data, was butter production in
Bangladesh. The nerd webcomic xkcd by Randall Munroe captures the
ethos perfectly: It features a woman claiming jelly beans cause acne. When a
statistical test shows no evidence of an effect, she revises her claim—it
must depend on the flavor of jelly bean. So the statistician tests 20
flavors. Nineteen show nothing. By chance there’s a high correlation between
jelly bean consumption and acne breakouts for one flavor. The final panel of
the cartoon is the front page of a newspaper: “Green Jelly Beans Linked to
Acne! 95% Confidence. Only 5% Chance of Coincidence!”
It’s worse for financial data because researchers
have more knobs to twist in search of a prized “anomaly”—a subtle pattern in
the data that looks like it could be a moneymaker. They can vary the period,
the set of securities under consideration, or even the statistical method.
Negative findings go in a file drawer; positive ones get submitted to a
journal (tenure!) or made into an ETF whose performance we rely on for
retirement. Testing out-of-sample data to keep yourself honest helps, but it
doesn’t cure the problem. With enough tests, eventually by chance even your
safety check will show the effect you want.
Continued in article
Bob Jensen's threads on p-values ---
http://faculty.trinity.edu/rjensen/theory01.htm#WhatWentWrong
Few things are as dangerous as economists with physics envy
---
https://aeon.co/ideas/few-things-are-as-dangerous-as-economists-with-physics-envy?utm_source=Aeon+Newsletter&utm_campaign=a541f10483-EMAIL_CAMPAIGN_2018_02_05&utm_medium=email&utm_term=0_411a82e59d-a541f10483-68951505
Journal of Accounting Research: Publication by
Research Design Rather than Research Results
by Colleen Flaherty
Inside Higher Ed
February 8, 2018
https://www.insidehighered.com/news/2018/02/08/two-journals-experiment-registered-reports-agreeing-publish-articles-based-their
Accountants aren’t known for taking risks. So a new
experiment from Journal of Accounting Research stands out: an
upcoming
conference issue
will include only papers that were accepted
before the authors knew what their results would be. That’s very different
from the traditional academic publication process, in which papers are
published -- or not -- based largely on their results.
The new
approach, known as “registered reports,” has developed a following in the
sciences in light of the so-called
reproducibility crisis.
But JAR is the first accounting journal to try it.
At the same time, The Review of Financial Studies is breaking similar
ground in business.
“This is what good accountants do -- we make reports trusted and worthy of
that trust,” said Robert Bloomfield, Nicholas H. Noyes Professor of
Management at Cornell University and guest editor of JAR’s registered
reports-based issue.
Beyond registered reports, JAR will publish a paper -- led by
Bloomfield -- about the process. The article’s name, “No System Is Perfect:
Understanding How Registration-Based Editorial Processes Affect
Reproducibility and Investment in Research Quality,” gives away its central
finding: that registered reports have their virtues but aren’t a panacea for
research-quality issues.
“Registration is a different system that has its benefits, but one of the
costs,” Bloomfield said, “is that the quality of the research article does
improve with what we call follow-up investment -- or all the stuff people do
after they’ve seen their results.”
In the life
sciences and some social science fields, concerns about the reproducibility
of results have yielded calls for increased data transparency. There are
also calls to rethink the editorial practices and academic incentives that
might encourage questionable research practices. QRPs, as such practices are
known, include rounding up P values to the
arguably arbitrary “P<0.05” threshold suggesting
statistical significance and publishing results that don't support a flashy
hypothesis in the trash (the “file drawer effect").
Some of those
calls have yielded results. The American Journal of Political Science,
for example, has a
Replication & Verification Policy
incorporating reproducibility and data sharing into the academic publication
process. Science established Transparency and Openness Promotion
guidelines
regarding data availability and more, to which hundreds of journals have
signed on. And the Center for Open Science continues to do important work in
this area. Some 91 journals use the registered reports publishing format
either as a regular submission option or as part of a single special
issue, according to
information
from the center. Other journals offer some features of the format.
Bloomfield said he’d been following such developments for years and talked
to pre-registration proponents in the sciences before launching his project
at JAR, where he is a member of the editorial board. To begin, he
put out a call for papers explaining the registration-based editorial
process, or REP. Rather than submitting finished articles, authors submitted
proposals to gather and analyze data. Eight of the most well-designed
proposals asking important questions, out of 71 total, were accepted
and guaranteed publication -- regardless of whether the results supported
their hypotheses, and as long as authors followed their plans.
Bloomfield and his co-authors also held a conference on the process and
surveyed authors who had published both registered papers and traditional
papers. They found that the registered-paper authors significantly increased
their up-front “investment” in planning, data gathering and analysis, such
as by proposing challenging experimental settings and bigger data sets. Yet,
as Bloomfield pointed out, registration tended to reduce follow-up work on
data once results were known. That is, a lot of potentially valuable data
that would have been explored further in a traditional paper may have been
left on the table here.
In all, the editorial process shift makes individual results more
reproducible, the paper says, but leaves articles “less thorough and
refined.” Bloomfield and his co-authors suggest that pre-registration could
be improved by encouraging certain forms of follow-up investment in papers
without risking “overstatement” of significance.
Feedback from individual authors is instructive.
“The stakes of the proposal process motivated a greater degree of front-end
collaboration for the author team,” wrote one conference participant whose
registered paper was accepted by JAR. “The public nature made us more
comfortable presenting a widely-attended proposal workshop. Finally, the
proposal submission process provided valuable referee feedback.
Collectively, this created a very tight theoretical design. In short, the
challenges motivated idealized behavior.”
Asked about how pre-registration compares to traditional publication, the
participant said, “A greater degree of struggle to concisely communicate our
final study.” Pilot testing everything but the main theory would have been a
good idea, in retrospect, the respondent said, since “in our effort to
follow the registered report process, I now believe we were overly
conservative.”
Bloomfield also asked respondents how researchers choose which measures and
analysis to report and highlight, and what effect it has on
traditional published research. Over, participants said this kind of
"discretion" was a good thing, in that it was exercised to make more
readable of coherent research.. But some suggested the pressure to publish
was at work.
“This is a huge problem,” said one respondent. “What does it give the
co-author team to provide no-results tests, for example, in the publishing
process?” Another said, “Only significant results tend to get published.
Potentially meaningful non-results may be overlooked.” Similarly, one
participant said, “I find it amazing how just about every study in the top
tier has like a 100 hypothesis support rate -- not healthy.” Yet another
said that “experiments are costly. I think people use this discretion to get
something publishable from all of the time and effort that goes into an
experiment.”
Bloomfield’s paper poses but doesn’t answer certain logistical questions
about what might happen if pre-registration spreads further. Should editors
be more willing to publish short papers that flesh out results left on the
table under REP, for example, it asks. What about replications of papers
whose reproducibility was potentially undermined by traditional publishing?
And how should authors be “credited” for publishing under REP, such as when
their carefully designed studies don’t lead to positive results?
Over all, the paper says, editors could improve both the registered and
traditional editorial processes by identifying studies that are “better
suited to each process, allowing slightly more discretion under REP and
slightly less under [the traditional process], clarifying standards under
REP, and demanding more transparency" in traditional processes.
The Review of Financial Studies
has organized two upcoming issues to include registered reports on certain
themes: financial technology in 2018 and climate finance in 2019. Financial
technology authors will present at Cornell next month.
Andrew Karolyi, associate dean for academic affairs at Cornell’s Samuel
Curtis Johnson Graduate School of Management and the journal’s executive
editor, has described the registration process as one that transfers
academic risk from the researcher to the journal.
Asked if he thought registration would gain a foothold in business, Karolyi
said via email that other journals in his field are following RFS’s
experiments.
“There is more work curating these initiatives, but I had a great passion
for it so I think less about the work than the outcome,” he said. “I want to
believe I and my editorial team did our homework and that we designed the
experiments well. Time will tell, of course.”
Continued in article
Jensen Comment
Academic (accountics) accounting research results are no longer of much interest
as evidenced by the lack of interest of the practicing profession in the
esoteric accounting research journals and the lack of interest of the editors of
those journals in encouraging either commentaries or replications ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
How Accountics "Scientists" Should
Change:
"Frankly, Scarlett, after I get a hit for my resume in The Accounting Review
I just don't give a damn"
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
This new initiative in academic accounting research is a a
good thing, but as Woodrow Wilson said years ago"
"It's easier to move a cemetary than to change a university curriculum (or
accounting research journals) or simple (unrealistic) experiments using students
as surrogates of real-life decision makers."
What went wrong with accountics research ---
http://faculty.trinity.edu/rjensen/theory01.htm#WhatWentWrong
Academic accounting researchers just don't like to leave the
campus to collect research data. They prefer to analyze data that purchase and
cannot control at collection points. They worship at the alters of p-values
generated by regression software.
"In Japan, Research Scandal Prompts Questions," by David McNeill,
Chronicle of Higher Education, June 30, 2014 ---
http://chronicle.com/article/In-Japan-Research-Scandal/147417/?cid=at&utm_source=at&utm_medium=en
. . .
Ms. Obokata’s actions "lead us to the conclusion
that she sorely lacks, not only a sense of research ethics, but also
integrity and humility as a scientific researcher,"
a
damning report concluded. The release of the
report sent Ms. Obokata, who admits mistakes but not ill intent, to the
hospital in shock for a week. Riken has dismissed all her appeals, clearing
the way for disciplinary action, which she has pledged to fight.
In June the embattled researcher
agreed to retract both Nature
papers—under duress, said her lawyer. On July 2,
Nature released a statement from her and
the other authors officially retracting the papers.
The seismic waves from Ms. Obokata’s rise and
vertiginous fall continue to reverberate. Japan’s top universities are
rushing to install antiplagiarism software and are combing through old
doctoral theses amid accusations that they are honeycombed with similar
problems.
The affair has sucked in some of Japan’s most
revered professors, including Riken’s president, Ryoji Noyori, a Nobel
laureate, and Shinya Yamanaka, credited with creating induced pluripotent
stem cells. Mr. Yamanaka, a professor at Kyoto University who is also a
Nobel laureate, in April denied claims that he too had manipulated images in
a 2000 research paper on embryonic mouse stem cells, but he was forced to
admit that, like Ms. Obokata, he could not find lab notes to support his
denial.
The scandal has triggered questions about the
quality of science in a country that still punches below its international
weight in cutting-edge research. Critics say Japan’s best universities have
churned out hundreds of poor-quality Ph.D.’s. Young researchers are not
taught how to keep detailed lab notes, properly cite data, or question
assumptions, said Sukeyasu Yamamoto, a former physicist at the University of
Massachusetts at Amherst and now an adviser to Riken. "The problems we see
in this episode are all too common," he said.
Hung Out to Dry?
Ironically, Riken was known as a positive
discriminator in a country where just one in seven university researchers
are women—the lowest share in the developed world. The organization was
striving to push young women into positions of responsibility, say other
professors there. "The flip side is that they overreacted and maybe went a
little too fast," said Kathleen S. Rockland, a neurobiologist who once
worked at Riken’s Brain Science Institute. "That’s a pity because they were
doing a very good job."
Many professors, however, accuse the institute of
hanging Ms. Obokata out to dry since the problems in her papers were
exposed. Riken was under intense pressure to justify its budget with
high-profile results. Japan’s news media have focused on the role of Yoshiki
Sasai, deputy director of the Riken Center and Ms. Obokata’s supervisor, who
initially promoted her, then insisted he had no knowledge of the details of
her research once the problems were exposed.
Critics noted that even the head of the inquiry
into Ms. Obokata’s alleged misconduct was forced to admit in April that he
had posted "problematic" images in a 2007 paper published in Oncogene.
Shunsuke Ishii, a molecular geneticist, quit the investigative committee.
Continued in article
Bob Jensen's threads on professors who cheat ---
http://faculty.trinity.edu/rjensen/Plagiarism.htm#ProfessorsWhoPlagiarize
"Over half of psychology studies fail
reproducibility test." "Study delivers bleak verdict on validity of psychology
experiment results." "Psychology is a discipline in crisis."
"How to Fix Psychology’s Replication Crisis," by Brian D. Earp and Jim
A.C. Everett, Chronicle of Higher Education, October 25, 2015 ---
http://chronicle.com/article/How-to-Fix-Psychology-s/233857?cid=at&utm_source=at&utm_medium=en&elq=ffdd5e32cd6c4add86ab025b68705a00&elqCampaignId=1697&elqaid=6688&elqat=1&elqTrackId=ffd568b276aa4a30804c90824e34b8d9
These and other similar headlines
followed the results of a large-scale initiative called the
Reproducibility Project, recently
published in Science magazine,
which appeared to show that a majority of findings from a
sample of 100 psychology studies did not hold up when
independent labs attempted to replicate them. (A similar
initiative is underway
in cancer biology and other
fields: Challenges with replication are
not unique to psychology.)
Headlines tend
to run a little hot. So the media’s dramatic response to the
Science paper was not entirely surprising given the
way these stories typically go. As it stands, though, it is
not at all clear what these replications mean. What the
experiments actually yielded in most cases was a different
statistical value or a smaller effect-size estimate compared
with the original studies, rather than positive evidence
against the existence of the underlying phenomenon.
This
is an important distinction. Although it would be nice if it
were otherwise, the data points we collect in psychology
don’t just hold up signs saying, "there’s an effect here" or
"there isn’t one." Instead, we have to make inferences based
on statistical estimates, and we should expect those
estimates to vary over time. In the typical scenario, an
initial estimate turns out to be on the high end (that’s why
it
ends up getting published in the
first place — it looks impressive), and then subsequent
estimates are a bit more down to earth.
. . .
To make the point a slightly different way: While
it is in everyone’s interest that high-quality, direct replications of key
studies in the field are conducted (so that we can know what degree of
confidence to place in previous findings), it is not typically in any
particular researcher’s interest to spend her time conducting such
replications.
As Huw Green, a Ph.D. student at the City
University of New York, recently put it, the "real crisis in psychology
isn’t that studies don’t replicate, but that we usually don’t even try."
What is needed is a "structural solution" —
something that has the power to resolve collective-action problems like the
one we’re describing. In simplest terms, if everyone is forced to cooperate
(by some kind of regulation), then no single individual will be at a
disadvantage compared to her peers for doing the right thing.
There are lots of ways of pulling this off — and we
don’t claim to have a perfect solution. But here is one idea.
As we proposed in a recent paper, graduate students in
psychology should be required to conduct, write up, and submit for
publication a high-quality replication attempt
of at least one key finding from the literature (ideally focusing on the
area of their doctoral research), as a condition of receiving their Ph.D.s.
Of course, editors
would need to agree to publish these kinds of submissions, and fortunately
there are a growing number — led by journals like PLoS ONE — that are
willing to do just that.
. . .
Since our
paper
was featured several weeks ago in
Nature, we’ve begun to get some constructive
feedback. As one psychologist wrote to us in an email
(paraphrased):
Your proposed
solution would only apply to some fields of psychology. It’s
not a big deal to ask students to do cheap replication
studies involving, say, pen-and-paper surveys — as is common
in social psychology. But to replicate an experiment
involving sensitive populations (babies, for instance, or
people with clinical disorders) or fancy equipment like an
fMRI machine, you would need a dedicated lab, a team of
experimenters, and several months of hard work — not to
mention the money to pay for all of this!
That much is
undoubtedly true. Expensive, time-consuming studies with
hard-to-recruit participants would not be replicated very
much if our proposal were taken up.
But that is
exactly the way things are now — so the problem would not be
made any worse. On the other hand, there are literally
thousands of studies that can be tested relatively cheaply,
at a skill level commensurate with a graduate student’s
training, which would benefit from being replicated. In
other words, having students perform replications as part of
their graduate work is very unlikely to make the problem of
not having enough replications any worse, but it has great
potential to help make it better.
Beyond
this, there is a pedagogical benefit. As Michael C. Frank
and Rebecca Saxe
have written: In their own
courses, they have found "that replicating cutting-edge
results is exciting and fun; it gives students the
opportunity to make real scientific contributions (provided
supervision is appropriate); and it provides object lessons
about the scientific process, the importance of reporting
standards, and the value of openness."
At the end of the day,
replication is indispensable.
It is a key part of the scientific enterprise; it helps us determine how
much confidence to place in published findings; and it will advance our
knowledge in the long run.
Continued in article
Jensen Comments
Accountics is the
mathematical science of values.
Charles Sprague [1887] as quoted by McMillan [1998, p. 1]
In accountics science I'm not aware of a single exacting replication of the
type discussed above of a published behavioral accounting research study.
Whether those findings constitute "truth" really does not matter much because
the practicing profession ignores accountics science behavior studies as
irrelevant and academics are only interested in the research methodologies
rather than the findings.
For example, years ago the FASB engaged Tom Dyckman and Bob Jensen to work
with the academic FASB member Bob Sprouse in evaluating research proposals to
study (with FASB funding) the post hoc impact of FAS 13 on the practicing
profession. In doing so the FASB said that both capital markets empiricism and
analytical research papers were acceptable but that the FASB had no interest in
behavioral studies. The implication was that behavioral studies were of little
interest too the FASB for various reasons, the main reason is that the tasks in
behavioral research were too artificial and removed from decision making in
real-world settings.
Interestingly both Tom and Bob had written doctoral theses that entailed
behavioral experiments in artificial settings. Tom used students as subjects,
and Bob used financial analysts doing, admittedly, artificial tasks. However,
neither Dyckman nor Jensen had much interest in subsequently conducting
behavioral experiments when they were professors. Of course in this FAS 13
engagement Dyckman and Jensen were only screening proposals submitted by other
researchers.
Accountics science research journals to my knowledge still will not publish
replications of behavioral experiments that only replicate and do not extend the
findings. Most like The Accounting Review, will not publish replications
of any kind. Accountics scientists have never
considered replication is indispensable at
the end of the day.
Bob Jensen's threads on the lack of replication in accountics science in
general ---
http://faculty.trinity.edu/rjensen/TheoryTar.htm
A Blast posted to SSRN on August 21, 2015
"Is There Any Scientific Basis for Accounting? Implications for Practice,
Research and Education,"
SSRN, August 21, 2015
Authors
Sudipta Basu, Temple University
- Department of Accounting
Link
http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2649263
Abstract:
This essay is based on a keynote speech at the 2014
Journal of International Accounting Research (JIAR) Conference. That talk
was built upon a 2009 American Accounting Association (AAA) annual meeting
panel presentation titled “Is there any scientific legitimacy to what we
teach in Accounting 101?” I evaluate whether accounting practice,
regulation, research and teaching have a strong underlying scientific basis.
I argue that recent accounting research, regulation and teaching are often
based on unscientific ideology but that evolved accounting practice embeds
scientific laws even if accountants are largely unaware of them. Accounting
researchers have an opportunity to expand scientific inquiry in accounting
by improving their research designs and exploring uses of accounting outside
formal capital markets using field studies and experiments.
Related literature, including an earlier essay by Sudipta Basu ---
Scroll down at
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm#Essays
"Introduction for Essays on the State of
Accounting Scholarship," Gregory B. Waymire, Accounting Horizons,
December 2012, Vol. 26, No. 4, pp. 817-819 ---
"Framing the Issue of Research Quality in
a Context of Research Diversity," by Christopher S. Chapman,
Accounting Horizons, December 2012, Vol. 26, No. 4, pp. 821-831
"Accounting Craftspeople versus
Accounting Seers: Exploring the Relevance and Innovation Gaps in Academic
Accounting Research," by William E. McCarthy, Accounting Horizons,
December 2012, Vol. 26, No. 4, pp. 833-843
"Is Accounting Research Stagnant?" by
Donald V. Moser, Accounting Horizons, December 2012, Vol. 26, No. 4,
pp. 845-850
"How Can Accounting Researchers Become
More Innovative? by Sudipta Basu,
Accounting Horizons, December 2012, Vol. 26, No. 4, pp. 851-87
A Blast from the Past from 1997
"A Comparison of Dividend, Cash Flow, and Earnings Approaches to Equity
Valuation,"
SSRN, March 31, 1997
Authors
Stephen H. Penman, Columbia Business School - Department of Accounting
Theodore Sougiannis, University of Illinois at Urbana-Champaign - Department
of Accountancy
Abstract:
Standard formulas for valuing the equity of going
concerns require prediction of payoffs "to infinity" but practical analysis
requires that they be predicted over finite horizons. This truncation
inevitably involves (often troublesome) "terminal value" calculations. This
paper contrasts dividend discount techniques, discounted cash flow analysis,
and techniques based on accrual earnings when applied to a finite-horizon
valuation. Valuations based on average ex-post payoffs over various
horizons, with and without terminal value calculations, are compared with
(ex-ante) market prices to give an indication of the error introduced by
each technique in truncating the horizon. Comparisons of these errors show
that accrual earnings techniques dominate free cash flow and dividend
discounting approaches. Further, the relevant accounting features of
techniques that make them less than ideal for finite horizon analysis are
discovered. Conditions where a given technique requires particularly long
forecasting horizons are identified and the performance of the alternative
techniques under those conditions is examined.
Link
http://papers.ssrn.com/sol3/papers.cfm?abstract_id=15043
Jensen Comment
It's good to teach accounting and finance students at all levels some of the
prize-winning literature (accountics scientists are always giving themselves
awards) in this type of valuation along with the reasons why these accountics
science models deriving equity valuation estimates from financial statements
have very little validity.
The main reason of course is that so many variables contributing to equity
valuation are not quantified in the financial statements, particularly
intangibles and contingencies.
"Don’t Over-Rely on Historical Data to Forecast Future Returns," by
Charles Rotblut and William Sharpe, AAII Journal, October 2014 ---
http://www.aaii.com/journal/article/dont-over-rely-on-historical-data-to-forecast-future-returns?adv=yes
Jensen Comment
The same applies to not over-relying on historical data in valuation. My
favorite case study that I used for this in
teaching is the following:
Questrom vs. Federated Department Stores, Inc.: A Question of Equity Value," by
University of Alabama faculty members by Gary Taylor, William Sampson,
and Benton Gup, May 2001 edition of Issues in Accounting Education ---
http://faculty.trinity.edu/rjensen/roi.htm
Jensen Comment
I want to especially thank David Stout,
Editor of the May 2001 edition of Issues in Accounting Education.
There has been something special in all the editions edited by David, but
the May edition is very special to me. All the articles in that edition are
helpful, but I want to call attention to three articles that I will use
intently in my graduate Accounting Theory course.
- "Questrom vs. Federated Department Stores, Inc.: A Question of
Equity Value," by University of Alabama faculty members Gary Taylor,
William Sampson, and Benton Gup, pp. 223-256.
This is perhaps the best short case that I've ever read. It will
undoubtedly help my students better understand weighted average cost of
capital, free cash flow valuation, and the residual income model. The
three student handouts are outstanding. Bravo to Taylor, Sampson, and
Gup.
- "Using the Residual-Income Stock Price Valuation Model to Teach and
Learn Ratio Analysis," by Robert Halsey, pp. 257-276.
What a follow-up case to the Questrom case mentioned above! I have long
used the Dupont Formula in courses and nearly always use the excellent
paper entitled "Disaggregating the ROE: A
New Approach," by T.I. Selling and C.P. Stickney,
Accounting Horizons, December 1990, pp. 9-17. Halsey's paper guides
students through the swamp of stock price valuation using the residual
income model (which by the way is one of the few academic accounting
models that has had a major impact on accounting practice, especially
consulting practice in equity valuation by CPA firms).
- "Developing Risk Skills: An Investigation of Business Risks and
Controls at Prudential Insurance Company of America," by Paul Walker,
Bill Shenkir, and Stephen Hunn, pp. 291
I will use this case to vividly illustrate the "tone-at-the-top"
importance of business ethics and risk analysis. This is case is easy
to read and highly informative.
"There Are Many Stock Market
Valuation Models, And Most Of Them Stink," by Ed Yardeni, Dr. Ed's Blog
via Business Insider, December 4, 2014 ---
http://www.businessinsider.com/low-rates-high-valuation-2014-12
Does low inflation justify higher valuation
multiples? There are many valuation models for stocks. They mostly don’t
work very well, or at least not consistently well. Over the years, I’ve come
to conclude that valuation, like beauty, is in the eye of the beholder.
For many investors, stocks look increasingly
attractive the lower that inflation and interest rates go. However, when
they go too low, that suggests that the economy is weak, which wouldn’t be
good for profits. Widespread deflation would almost certainly be bad for
profits. It would also pose a risk to corporations with lots of debt, even
if they could refinance it at lower interest rates. Let’s review some of the
current valuation metrics, which we monitor in our Stock
Market Valuation Metrics & Models:
(1) Reversion to the mean. On Tuesday, the
forward P/E of the S&P 500 was 16.1. That’s above its historical average of
13.7 since 1978.
(2) Rule of 20. One rule of thumb is that the forward P/E of the
S&P 500 should be close to 20 minus the y/y CPI inflation rate. On this
basis, the rule’s P/E was 18.3 during October.
(3) Misery Index. There has been an inverse relationship between
the S&P 500’s forward P/E and the Misery Index, which is just the sum of the
inflation rate and the unemployment rate. The index fell to 7.4% during
October. That’s the lowest reading since April 2008, and arguably justifies
the market’s current lofty multiple.
(4) Market-cap ratios. The ratio of the S&P 500 market cap to
revenues rose to 1.7 during Q3, the highest since Q1-2002. That’s identical
to the reading for the ratio of the market cap of all US equities to nominal
GDP.
Today's Morning Briefing: Inflating
Inflation. (1) Dudley expects Fed to hit inflation target next
year. (2) It all depends on resource utilization. (3) What if demand-side
models are flawed? (4) Supply-side models explain persistence of
deflationary pressures. (5) Inflationary expectations falling in TIPS
market. (6) Bond market has gone global. (7) Valuation and beauty contests.
(8) Rule of 20 says stocks still cheap. (9) Other valuation models find no
bargains. (10) Cheaper stocks abroad, but for lots of good reasons. (11) US
economy humming along. (More
for subscribers.)
Accountics Scientists Failing to Communicate on the AAA Commons
"Frankly, Scarlett, after I get a hit for my resume in The Accounting Review
I just don't give a damn ."
www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
Instead of p-values, the journal will require
“strong descriptive statistics, including effect size.
"Science Isn’t Broken: It’s just a hell of a lot harder than we give it
credit for." by Christie Aschwanden, Nate Silver's 5:38 Blog, August
19, 2015 ---
http://fivethirtyeight.com/features/science-isnt-broken/
If you follow the headlines, your confidence in
science may have taken a hit lately.
. . .
Taken together, headlines like these might suggest
that science is a shady enterprise that spits out a bunch of dressed-up
nonsense. But I’ve spent months investigating the problems hounding science,
and I’ve learned that the headline-grabbing cases of misconduct and fraud
are mere distractions. The state of our science is strong, but it’s plagued
by a universal problem: Science is hard — really fucking hard.
If we’re going to rely on science as a means for
reaching the truth — and it’s still the best tool we have — it’s important
that we understand and respect just how difficult it is to get a rigorous
result. I could pontificate about all the reasons why science is arduous,
but instead I’m going to let you experience one of them for yourself.
Welcome to the wild world of p-hacking.
. . .
f you tweaked the
variables until you proved that Democrats are good for the economy,
congrats; go vote for Hillary Clinton with a sense of purpose. But don’t go
bragging about that to your friends. You could have proved the same for
Republicans.
The data in our
interactive tool can be narrowed and expanded (p-hacked) to make either
hypothesis appear correct. That’s
because answering even a simple scientific question — which party is
correlated with economic success — requires lots of choices that can shape
the results. This doesn’t mean that science is unreliable. It just means
that it’s more challenging than we sometimes give it credit for.
Which political
party is best for the economy seems like a pretty straightforward question.
But as you saw, it’s much easier to get a
result
than it is to get an answer.
The variables in
the data sets you used to test your hypothesis had 1,800 possible
combinations. Of these, 1,078 yielded a publishable p-value,
but that doesn’t mean they showed that
which party was in office had a strong effect on the economy. Most of them
didn’t.
The p-value reveals
almost nothing about the strength of the evidence, yet a p-value of 0.05 has
become the ticket to get into many journals. “The dominant method used [to
evaluate evidence] is the p-value,” said Michael Evans, a statistician at
the University of Toronto, “and the p-value is well known not to work very
well.”
Scientists’
overreliance on p-values has led at least one journal to decide it has had
enough of them. In February, Basic and Applied Social Psychology announced
that it will no longer publish p-values. “We believe that the p < .05 bar is
too easy to pass and sometimes serves as an excuse for lower quality
research,”
the editors wrote in their announcement.
Instead of p-values,
the journal will require “strong descriptive statistics, including effect
sizes.”
Continued in article
Bob Jensen's threads on statistical mistakes ---
http://www.cs.trinity.edu/~rjensen/temp/AccounticsScienceStatisticalMistakes.htm
Bob Jensen's threads on replication and critical commentary ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
The limits of mathematical and statistical analysis
From the CFO Journal's Morning Ledger on April 18, 2014
The limits of social engineering
Writing in MIT
Technology Review, tech reporter Nicholas
Carr pulls from a new
book by one of MIT’s noted data scientists to explain why he thinks Big Data
has its limits, especially when applied to understanding society. Alex
‘Sandy’ Pentland, in his book “Social Physics: How Good Ideas Spread – The
Lessons from a New Science,” sees a mathematical modeling of society made
possible by new technologies and sensors and Big Data processing power. Once
data measurement confirms “the innate tractability of human beings,”
scientists may be able to develop models to predict a person’s behavior. Mr.
Carr sees overreach on the part of Mr. Pentland. “Politics is messy because
society is messy, not the other way around,” Mr. Carr writes, and any
statistical model likely to come from such research would ignore the
history, politics, class and messy parts associated with humanity. “What big
data can’t account for is what’s most unpredictable, and most interesting,
about us,” he concludes.
Jensen Comment
The sad state of accountancy and many doctoral programs in the 21st Century is
that virtually all of them in North America only teach the methodology and
technique of analyzing enormous archived databases with statistical tools or the analytical
modeling of artificial worlds based on dubious assumptions to simplify reality
---
http://faculty.trinity.edu/rjensen/Theory01.htm#DoctoralPrograms
The Pathways Commission sponsored by the American Accounting Association
strongly proposes adding non-quantitative alternatives to doctoral programs but
I see zero evidence of any progress in that direction.
The main problem is that it's just much easier to avoid
having to collect data by beating purchased databases with econometric sticks
until something, usually an irrelevant something, falls out of the big data
piñata.
"A Scrapbook on What's Wrong with the Past, Present and Future of
Accountics Science"
Bob Jensen Jensen
February 19, 2014
SSRN Download:
http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2398296
From the Stanford University Encyclopedia of Philosophy
Science and Pseudo-Science ---
http://plato.stanford.edu/entries/pseudo-science/
The demarcation between science and pseudoscience
is part of the larger task to determine which beliefs are epistemically
warranted. The entry clarifies the specific nature of pseudoscience in
relation to other forms of non-scientific doctrines and practices. The major
proposed demarcation criteria are discussed and some of their weaknesses are
pointed out. In conclusion, it is emphasized that there is much more
agreement in particular issues of demarcation than on the general criteria
that such judgments should be based upon. This is an indication that there
is still much important philosophical work to be done on the demarcation
between science and pseudoscience.
1. The purpose of demarcations
2. The “science” of pseudoscience
3. The “pseudo” of pseudoscience
3.1 Non-, un-, and pseudoscience
3.2 Non-science posing as science
3.3 The doctrinal component
3.4 A wider sense of pseudoscience
3.5 The objects of demarcation 3.6 A time-bound demarcation
4. Alternative demarcation criteria
4.1 The logical positivists
4.2 Falsificationism
4.3 The criterion of puzzle-solving
4.4 Criteria based on scientific progress
4.5 Epistemic norms 4.6 Multi-criterial approaches
5. Unity in diversity Bibliography
Bibliography of philosophically informed
literature on pseudosciences and contested doctrines
Other Internet resources Related Entries
Cited Works
- Agassi, Joseph (1991). “Popper's demarcation of
science refuted”, Methodology and Science, 24: 1–7.
- Baigrie, B.S. (1988). “Siegel on the Rationality
of Science”, Philosophy of Science, 55: 435–441.
- Bartley III, W. W. (1968). “Theories of
demarcation between science and metaphysics”, pp. 40–64 in Imre Lakatos and
Alan Musgrave (eds.), Problems in the Philosophy of Science, Proceedings
of the International Colloquium in the Philosophy of Science, London 1965,
volume 3, Amsterdam: North-Holland Publishing Company.
- Bunge, Mario (1982). “Demarcating Science from
Pseudoscience”, Fundamenta Scientiae, 3: 369–388.
- Bunge, Mario (2001). “Diagnosing pseudoscience”,
pp. 161–189 in Mario Bunge, Philosophy in Crisis. The Need for
Reconstruction,Amherst, N.Y.; Prometheus Books.
- Carlson, Shawn (1985). “A Double Blind Test of
Astrology”, Nature, 318: 419–425.
- Cioffi, Frank (1985). “Psychoanalysis,
pseudoscience and testability”, pp 13–44 in Gregory Currie and Alan
Musgrave, (eds.) Popper and the Human Sciences, Dordrecht: Martinus
Nijhoff Publishers, Dordrecht.
- Culver, Roger and Ianna, Philip (1988).
Astrology: True or False. 1988, Buffalo: Prometheus Books.
- Derksen, A.A. (1993). “The seven sins of
pseudoscience”, Journal for General Philosophy of Science, 24:
17–42.
- Derksen, A.A. (2001). “The seven strategies of the
sophisticated pseudoscience: a look into Freud's rhetorical tool box”,
Journal for General Philosophy of Science, 32: 329–350.
- Dolby, R.G.A. (1987). “Science and pseudoscience:
the case of creationism”, Zygon, 22: 195–212.
- Dupré, John (1993). The Disorder of Things:
Metaphysical Foundations of the Disunity of Science, Harvard: Harvard
University Press.
- Dutch, Steven I (1982). “Notes on the nature of
fringe science”, Journal of Geological Education, 30: 6–13.
- Feleppa, Robert (1990). “Kuhn, Popper, and the
Normative Problem of Demarcation”, pp. 140–155 in Patrick Grim (ed.)
Philosophy of Science and the Occult, 2nd ed, Albany: State
University of New York Press.
- Fuller, Steve (1985). “The demarcation of science:
a problem whose demise has been greatly exaggerated”, Pacific
Philosophical Quarterly, 66: 329–341.
- Gardner, Martin (1957). Fads and Fallacies in
the Name of Science, Dover 1957. (Expanded version of his In the
Name of Science, 1952.)
- Glymour, Clark and Stalker, Douglas (1990).
“Winning through Pseudoscience”, pp 92–103 in Patrick Grim (ed.)
Philosophy of Science and the Occult, 2nd ed, Albany: State
University of New York Press.
- Grove , J.W. (1985). “Rationality at Risk: Science
against Pseudoscience”, Minerva, 23: 216–240.
- Gruenberger, Fred J. (1964). “A measure for
crackpots”, Science, 145: 1413–1415.
- Hansson, Sven Ove (1983). Vetenskap och
ovetenskap, Stockholm: Tiden.
- Hansson, Sven Ove (1996). “Defining
Pseudoscience”, Philosophia Naturalis, 33: 169–176.
- Hansson, Sven Ove (2006). “Falsificationism
Falsified”, Foundations of Science, 11: 275–286.
- Hansson, Sven Ove (2007). “Values in Pure and
Applied Science”, Foundations of Science, 12: 257–268.
- Kitcher, Philip (1982). Abusing Science. The
Case Against Creationism, Cambridge, MA: MIT Press.
- Kuhn, Thomas S (1974). “Logic of Discovery or
Psychology of Research?”, pp. 798–819 in P.A. Schilpp, The Philosophy of
Karl Popper, The Library of Living Philosophers, vol xiv, book ii. La
Salle: Open Court.
- Lakatos, Imre (1970). “Falsification and the
Methodology of Research program, pp 91–197 in Imre Lakatos and Alan Musgrave
(eds.) Criticism and the Growth of Knowledge. Cambridge: Cambridge
University Press.
- Lakatos, Imre (1974a). “Popper on Demarcation and
Induction”, pp. 241–273 in P.A. Schilpp, The Philosophy of Karl Popper,
The Library of Living Philosophers, vol xiv, book i. La Salle: Open Court.
- Lakatos, Imre (1974b). “Science and
pseudoscience”, Conceptus, 8: 5–9.
- Lakatos, Imre (1981). “Science and pseudoscience”,
pp. 114–121 in S Brown et al. (eds.) Conceptions of Inquiry: A
Reader London: Methuen.
- Langmuir, Irving ([1953] 1989). “Pathological
Science”, Physics Today, 42/10: 36–48.
- Laudan, Larry (1983). “The demise of the
demarcation problem”, pp. 111–127 in R.S. Cohan and L. Laudan (eds.),
Physics, Philosophy, and Psychoanalysis, Dordrecht: Reidel.
- Lugg, Andrew (1987). “Bunkum, Flim-Flam and
Quackery: Pseudoscience as a Philosophical Problem” Dialectica, 41:
221–230.
- Lugg, Andrew (1992). “Pseudoscience as nonsense”,
Methodology and Science, 25: 91–101.
- Mahner, Martin (2007). “Demarcating Science from
Non-Science”, pp 515-575 in Theo Kuipers (ed.) Handbook of the
Philosophy of Science: General Philosophy of Science – Focal Issues,
Amsterdam: Elsevier.
- Mayo, Deborah G. (1996). “Ducks, rabbits and
normal science: Recasting the Kuhn's-eye view of Popper's demarcation of
science”, British Journal for the Philosophy of Science, 47:
271–290.
- Merton, Robert K. ([1942] 1973). “Science and
Technology in a Democratic Order”, Journal of Legal and Political
Sociology, 1: 115–126, 1942. Reprinted as “The Normative Structure of
Science”, pp. 267–278 in Robert K Merton, The Sociology of Science.
Theoretical and Empirical Investigations, Chicago: University of
Chicago Press.
- Morris, Robert L. (1987). “Parapsychology and the
Demarcation Problem”, Inquiry, 30: 241–251.
- Popper, Karl (1962). Conjectures and
refutations. The growth of scientific knowledge, New York: Basic Books.
- Popper, Karl (1974) “Reply to my critics”, pp.
961–1197 in P.A. Schilpp, The Philosophy of Karl Popper, The
Library of Living Philosophers, vol xiv, book ii. La Salle: Open Court.
- Popper, Karl (1976). Unended Quest
London: Fontana.
- Popper, Karl (1978). “Natural Selection and the
Emergence of the Mind”, Dialectica, 32: 339–355.
- Popper, Karl ([1989] 1994). “Falsifizierbarkeit,
zwei Bedeutungen von”, pp. 82–86 in Helmut Seiffert and Gerard Radnitzky,
Handlexikon zur Wissenschaftstheorie, 2nd edition
München:Ehrenwirth GmbH Verlag.
- Radner, Daisie and Michael Radner (1982).
Science and Unreason, Belmont CA: Wadsworth.
- Reisch, George A. (1998). “Pluralism, Logical
Empiricism, and the Problem of Pseudoscience”, Philosophy of Science,
65: 333–348.
- Rothbart, Daniel (1990) “Demarcating Genuine
Science from Pseudoscience”, pp 111–122 in Patrick Grim, ed, Philosophy
of Science and the Occult, 2nd ed, Albany: State University
of New York Press.
- Ruse, Michael (1977). “Karl Popper's Philosophy of
Biology”, Philosophy of Science, 44: 638–661.
- Ruse, Michael (ed.) (1996). But is it science?
The philosophical question in the creation/evolution controversy,
Prometheus Books.
- Ruse, Michael (2000). “Is evolutionary biology a
different kind of science?”, Aquinas, 43: 251–282.
- Settle, Tom (1971). The Rationality of Science
versus the Rationality of Magic”, Philosophy of the Social Sciences,
1: 173–194.
- Siitonen, Arto (1984). “Demarcation of science
from the point of view of problems and problem-stating”, Philosophia
Naturalis, 21: 339–353.
- Thagard, Paul R. (1978). “Why Astrology Is a
Pseudoscience”, PSA, 1: 223–234.
- Thagard, Paul R. (1988). Computational
Philosophy of Science, Cambridge, MA: MIT Press.
- Vollmer, Gerhard (1993). Wissenschaftstheorie
im Einsatz, Beiträge zu einer selbstkritischen Wissenschaftsphilosophie
Stuttgart: Hirzel Verlag.
Paul Feyerabend ---
http://plato.stanford.edu/entries/feyerabend/
William Thomas Ziemba ---
http://www.williamtziemba.com/WilliamZiemba-ShortCV.pdf
Thomas M. Cover ---
http://en.wikipedia.org/wiki/Thomas_M._Cover
On June 15, 2013 David Johnstone wrote the following:
Dear all,
I worked on the logic and philosophy of hypothesis tests in the early 1980s
and discovered a very large literature critical of standard forms of
testing, a little of which was written by philosophers of science (see the
more recent book by Howson and Urbach) and much of which was written by
statisticians. At this point philosophy of science was warming up on
significance tests and much has been written since. Something I have
mentioned to a few philosophers however is how far behind the pace
philosophy of science is in regard to all the new finance and decision
theory developed in finance (e.g. options logic, mean-variance as an
expression of expected utility). I think that philosophers would get a rude
shock on just how clever and rigorous all this thinking work in “business”
fields is. There is also wonderfully insightful work on betting-like
decisions done by mathematicians, such as Ziemba and Cover, that has I think
rarely if ever surfaced in the philosophy of science (“Kelly betting” is a
good example). So although I believe modern accounting researchers should
have far more time and respect for ideas from the philosophy of science, the
argument runs both ways.
Jensen Comment
Note that in the above "cited works" there are no cited references in statistics
such as Ziemba and Cover or the better known statistical theory and statistical
science references.
This suggests somewhat the divergence of statistical theory from philosophy
theory with respect to probability and hypothesis testing. Of course probability
and hypothesis testing are part and parcel to both science and pseudo-science.
Statistical theory may accordingly be a subject that divides pseudo-science and
real science.
Etymology provides us with an obvious
starting-point for clarifying what characteristics pseudoscience has in
addition to being merely non- or un-scientific. “Pseudo-” (ψευδο-) means
false. In accordance with this, the Oxford English Dictionary (OED) defines
pseudoscience as follows:
“A pretended or spurious science; a collection of
related beliefs about the world mistakenly regarded as being based on
scientific method or as having the status that scientific truths now
have.”
June 16, 2013 reply from Marc
Dupree
Let me try again, better organized this time.
You (Bob) have referenced sources that include
falsification and demarcation. A good idea. Also, AECM participants discuss
hypothesis testing and Phi-Sci topics from time to time.
I didn't make my purpose clear. My purpose is to
offer that falsification and demarcation are still relevant to empirical
research, any empirical research.
So,
What is falsification in mathematical form?
Why does falsification not demarcate science from
non-science?
And for fun: Did Popper know falsification didn't
demarcate science from non-science?
Marc
June 17, 2013 reply form Bob
Jensen
Hi Marc,
Falsification in science generally requires
explanation. You really have not falsified a theory
or proven a theory if all you can do is demonstrate
an unexplained correlation. In pseudo-science
empiricism a huge problem is that virtually all our
databases are not granulated sufficiently to
possibly explain the discovered correlations or
discovered predictability that cannot be explained
---
http://www.cs.trinity.edu/~rjensen/temp/AccounticsGranulationCurrentDraft.pdf
Mathematics is
beautiful in many instances because theories are
formulated in a way where finding a counter example
ipso facto destroys the theory. This is not
generally the case in the empirical sciences where
exceptions (often outliers) arise even when causal
mechanisms have been discovered. In genetics those
exceptions are often mutations that infrequently but
persistently arise in nature.
The key difference between
pseudo-science and real-science, as I pointed out
earlier in this thread, lies in explanation versus
prediction (the F-twist) or causation versus
correlation. When a research study concludes there
is a correlation that cannot be explained we are
departing from a scientific discovery. For an
example, see
Researchers pinpoint how smoking
causes osteoporosis ---
http://medicalxpress.com/news/2013-06-osteoporosis.html
Data mining research in
particular suffers from inability to find causes if the
granulation needed for discovery of causation just is not
contained in the databases. I've hammered on this one with a
Japanese research data mining accountics research
illustration (from TAR) ----
"How Non-Scientific Granulation Can Improve Scientific
Accountics"
http://www.cs.trinity.edu/~rjensen/temp/AccounticsGranulationCurrentDraft.pdf
Another huge problem in accountics
science and empirical finance is statistical significance testing of
correlation coefficients with enormous data mining samples. For
example R-squared coefficients of 0.001 are deemed statistically
significant if the sample sizes are large enough :
My threads on Deidre McCloskey (the Cult of Statistical
Significance) and my own talk are at
http://www.cs.trinity.edu/~rjensen/temp/DeirdreMcCloskey/StatisticalSignificance01.htm
A problem with real-science is that there's
a distinction between the evolution of a theory and the ultimate
discovery of the causal mechanisms. In the evolution of a theory there
may be unexplained correlations or explanations that have not yet been
validated (usually by replication). But genuine scientific discoveries
entail explanation of phenomena. We like to think of physics and
chemistry are real-sciences. In fact they deal a lot with unexplained
correlations before theories can finally be explained.
Perhaps a difference between a pseudo-science
(like accountics science) versus chemistry (a real-science) is that real
scientists are never satisfied until they can explain causality to the
satisfaction of their peers.
Accountics scientists are generally satisfied with correlations and
statistical inference tests that cannot explain root causes:
http://www.cs.trinity.edu/~rjensen/temp/AccounticsGranulationCurrentDraft.pdf
Of course science is replete with
examples of causal explanations that are later falsified or
demonstrated to be incomplete. But the focus is on the causal
mechanisms and not mere correlations.
In Search of the Theory of Everything
"Physics’s pangolin: Trying to resolve the stubborn
paradoxes of their field, physicists craft ever more
mind-boggling visions of reality," by Margaret Wertheim,
AEON Magazine, June 2013 ---
http://www.aeonmagazine.com/world-views/margaret-wertheim-the-limits-of-physics/
Of course social scientists complain
that the problem in social science research is that the physicists
stole all the easy problems.
Respectfully,
Bob Jensen
"Is Economics a Science," by Robert Shiller, QFinance, November
8, 2013 --- Click
Here
http://www.qfinance.com/blogs/robert-j.
shiller/2013/11/08/nobel-is-economics-a-science?utm_source=November+2013+email&utm_medium=Email&utm_content=Blog2&utm_campaign=EmailNov13
NEW HAVEN – I am one of the winners of this year’s
Nobel Memorial Prize in Economic Sciences, which
makes me acutely aware of criticism of the prize by those who claim that
economics – unlike chemistry, physics, or medicine, for which
Nobel Prizes are also
awarded – is not a science. Are they right?
One problem with economics is that it is
necessarily focused on policy, rather than discovery of fundamentals. Nobody
really cares much about economic data except as a guide to policy: economic
phenomena do not have the same intrinsic fascination for us as the internal
resonances of the atom or the functioning of the vesicles and other
organelles of a living cell. We judge economics by what it can produce. As
such, economics is rather more like engineering than physics, more practical
than spiritual.
There is no Nobel Prize for engineering, though
there should be. True,
the chemistry prize this year looks a bit like an
engineering prize, because it was given to three researchers – Martin
Karplus, Michael Levitt, and Arieh Warshel – “for the development of
multiscale models of complex chemical systems” that underlie the computer
programs that make nuclear magnetic resonance hardware work. But the Nobel
Foundation is forced to look at much more such practical, applied material
when it considers the economics prize.
The problem is that, once we focus on economic
policy, much that is not science comes into play.
Politics becomes involved, and political posturing
is amply rewarded by public attention. The Nobel Prize is designed to reward
those who do not play tricks for attention, and who, in their sincere
pursuit of the truth, might otherwise be slighted.
The pursuit of truth
Why is it called a prize in “economic sciences”, rather than just
“economics”? The other prizes are not awarded in the “chemical sciences” or
the “physical sciences”.
Fields of endeavor that use “science” in their
titles tend to be those that get masses of people emotionally involved and
in which crackpots seem to have some purchase on public opinion. These
fields have “science” in their names to distinguish them from their
disreputable cousins.
The term political science first became popular in
the late eighteenth century to distinguish it from all the partisan tracts
whose purpose was to gain votes and influence rather than pursue the truth.
Astronomical science was a common term in the late nineteenth century, to
distinguish it from astrology and the study of ancient myths about the
constellations. Hypnotic science was also used in the nineteenth century to
distinguish the scientific study of hypnotism from witchcraft or religious
transcendentalism.
Crackpot counterparts
There was a need for such terms back then, because their crackpot
counterparts held much greater sway in general discourse. Scientists had to
announce themselves as scientists.
In fact, even the
term chemical science enjoyed some popularity in the nineteenth century – a
time when the field sought to distinguish itself from alchemy and the
promotion of quack nostrums. But the need to use that term to distinguish
true science from the practice of impostors was already fading by the time
the
Nobel Prizes were launched in 1901.
Similarly, the terms astronomical science and
hypnotic science mostly died out as the twentieth century progressed,
perhaps because belief in the occult waned in respectable society. Yes,
horoscopes still persist in popular newspapers, but they are there only for
the severely scientifically challenged, or for entertainment; the idea that
the stars determine our fate has lost all intellectual currency. Hence there
is no longer any need for the term “astronomical science.”
Pseudoscience?
Critics of “economic sciences” sometimes refer to the development of a
“pseudoscience” of economics, arguing that it uses the trappings of science,
like dense mathematics, but only for show. For example, in his 2004 book, Fooled
by Randomness, Nassim Nicholas Taleb said of
economic sciences:
“You can disguise charlatanism under the weight of
equations, and nobody can catch you since there is no such thing as a
controlled experiment.”
But physics is not without such critics, too. In his 2004 book,
The Trouble with Physics: The Rise of String Theory, The Fall of a Science,
and What Comes Next, Lee Smolin reproached
the physics profession for being seduced by beautiful and elegant theories
(notably string theory) rather than those that can be tested by
experimentation. Similarly, in his 2007 book,
Not Even Wrong: The Failure of String Theory and the Search for Unity in
Physical Law, Peter Woit accused physicists
of much the same sin as mathematical economists are said to commit.
Exposing the charlatans
My belief is that
economics is somewhat more vulnerable than the
physical sciences to models whose validity will never be clear, because the
necessity for approximation is much stronger than in the physical sciences,
especially given that the
models describe people rather than magnetic resonances
or fundamental particles. People can just change their
minds and behave completely differently. They even have neuroses and
identity problems -
complex phenomena that the field of behavioral economics is finding relevant
to understand economic outcomes.
But all the mathematics in economics is not, as
Taleb suggests, charlatanism.
Economics has an important quantitative side,
which cannot be escaped. The challenge has been to combine its mathematical
insights with the kinds of adjustments that are needed to make its models
fit the economy’s irreducibly human element.
The advance of behavioral economics is not
fundamentally in conflict with mathematical economics, as some seem to
think, though it may well be in conflict with some currently fashionable
mathematical economic models. And, while economics presents its own
methodological problems, the basic challenges facing researchers are not
fundamentally different from those faced by researchers in other fields. As
economics develops, it will broaden its repertory of methods and sources of
evidence, the science will become stronger, and the charlatans will be
exposed.
Bob Jensen's threads on Real Science versus Pseudo Science ---
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
"A Pragmatist Defence of Classical Financial Accounting Research," by
Brian A. Rutherford, Abacus, Volume 49, Issue 2, pages 197–218, June 2013
---
http://onlinelibrary.wiley.com/doi/10.1111/abac.12003/abstract
The reason for the disdain in which classical
financial accounting research has come to held by many in the scholarly
community is its allegedly insufficiently scientific nature. While many have
defended classical research or provided critiques of post-classical
paradigms, the motivation for this paper is different. It offers an
epistemologically robust underpinning for the approaches and methods of
classical financial accounting research that restores its claim to
legitimacy as a rigorous, systematic and empirically grounded means of
acquiring knowledge. This underpinning is derived from classical
philosophical pragmatism and, principally, from the writings of John Dewey.
The objective is to show that classical approaches are capable of yielding
serviceable, theoretically based solutions to problems in accounting
practice.
Jensen Comment
When it comes to "insufficient scientific nature" of classical accounting
research I should note yet once again that accountics science never attained the
status of real science where the main criteria are scientific searches for
causes and an obsession with replication (reproducibility) of findings.
Accountics science is overrated because it only achieved the status of a
psuedo science ---
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm#Pseudo-Science
"Research
on Accounting Should Learn From the Past" by Michael H. Granof and Stephen
A. Zeff, Chronicle of Higher Education, March 21, 2008
The unintended consequence has been that interesting and researchable questions
in accounting are essentially being ignored.
By confining the major thrust in research to phenomena that can be
mathematically modeled or derived from electronic databases, academic
accountants have failed to advance the profession in ways that are expected of
them and of which they are capable.
Academic research has unquestionably broadened the views of standards setters as
to the role of accounting information and how it affects the decisions of
individual investors as well as the capital markets. Nevertheless, it has had
scant influence on the standards themselves.
Continued
in article
"Research on Accounting Should Learn From the Past,"
by Michael H. Granof and
Stephen A. Zeff, Chronicle of Higher Education, March 21, 2008
. . .
The narrow focus of today's research has also resulted in a disconnect between
research and teaching. Because of the difficulty of conducting publishable
research in certain areas — such as taxation, managerial accounting, government
accounting, and auditing — Ph.D. candidates avoid choosing them as specialties.
Thus, even though those areas are central to any degree program in accounting,
there is a shortage of faculty members sufficiently knowledgeable to teach them.
To be sure, some accounting research, particularly that pertaining to the
efficiency of capital markets, has found its way into both the classroom and
textbooks — but mainly in select M.B.A. programs and the textbooks used in those
courses. There is little evidence that the research has had more than a marginal
influence on what is taught in mainstream accounting courses.
What needs to be done? First, and most significantly, journal editors,
department chairs, business-school deans, and promotion-and-tenure committees
need to rethink the criteria for what constitutes appropriate accounting
research. That is not to suggest that they should diminish the importance of the
currently accepted modes or that they should lower their standards. But they
need to expand the set of research methods to encompass those that, in other
disciplines, are respected for their scientific standing. The methods include
historical and field studies, policy analysis, surveys, and international
comparisons when, as with empirical and analytical research, they otherwise meet
the tests of sound scholarship.
Second, chairmen, deans, and promotion and merit-review committees must expand
the criteria they use in assessing the research component of faculty
performance. They must have the courage to establish criteria for what
constitutes meritorious research that are consistent with their own
institutions' unique characters and comparative advantages, rather than
imitating the norms believed to be used in schools ranked higher in magazine and
newspaper polls. In this regard, they must acknowledge that accounting
departments, unlike other business disciplines such as finance and marketing,
are associated with a well-defined and recognized profession. Accounting
faculties, therefore, have a special obligation to conduct research that is of
interest and relevance to the profession. The current accounting model was
designed mainly for the industrial era, when property, plant, and equipment were
companies' major assets. Today, intangibles such as brand values and
intellectual capital are of overwhelming importance as assets, yet they are
largely absent from company balance sheets. Academics must play a role in
reforming the accounting model to fit the new postindustrial environment.
Third, Ph.D. programs must ensure that young accounting researchers are
conversant with the fundamental issues that have arisen in the accounting
discipline and with a broad range of research methodologies. The accounting
literature did not begin in the second half of the 1960s. The books and articles
written by accounting scholars from the 1920s through the 1960s can help to
frame and put into perspective the questions that researchers are now studying.
Continued in article
How accountics scientists should change ---
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
June 5, 2013 reply to a long
thread by Bob Jensen
Hi Steve,
As usual, these AECM threads between you, me, and Paul Williams resolve
nothing to date. TAR still has zero articles without equations unless such
articles are forced upon editors like the Kaplan article was forced upon you
as Senior Editor. TAR still has no commentaries about the papers it
publishes and the authors make no attempt to communicate and have dialog
about their research on the AECM or the AAA Commons.
I do hope that our AECM threads will continue and lead one day to when
the top academic research journals do more to both encourage (1) validation
(usually by speedy replication), (2) alternate methodologies, (3) more
innovative research, and (4) more interactive commentaries.
I remind you that Professor Basu's essay is only one of four essays
bundled together in Accounting Horizons on the topic of how to make
accounting research, especially the so-called Accounting Sciience or
Accountics Science or Cargo Cult science, more innovative.
The four essays in this bundle are summarized and extensively quoted at
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm#Essays
- "Framing the Issue of Research Quality in a Context of Research
Diversity," by Christopher S. Chapman ---
- "Accounting Craftspeople versus Accounting Seers: Exploring the
Relevance and Innovation Gaps in Academic Accounting Research," by
William E. McCarthy ---
- "Is Accounting Research Stagnant?" by Donald V. Moser ---
- Cargo Cult Science "How Can Accounting Researchers Become More
Innovative? by Sudipta Basu ---
I will try to keep drawing attention to these important essays and spend
the rest of my professional life trying to bring accounting research closer
to the accounting profession.
I also want to dispel the myth that accountics research is harder than
making research discoveries without equations. The hardest research I can
imagine (and where I failed) is to make a discovery that has a noteworthy
impact on the accounting profession. I always look but never find such
discoveries reported in TAR.
The easiest research is to purchase a database and beat it with an
econometric stick until something falls out of the clouds. I've searched for
years and find very little that has a noteworthy impact on the accounting
profession. Quite often there is a noteworthy impact on other members of the
Cargo Cult and doctoral students seeking to beat the same data with their
sticks. But try to find a practitioner with an interest in these academic
accounting discoveries?
Our latest thread leads me to such questions as:
- Is accounting research of inferior quality relative to other
disciplines like engineering and finance?
- Are there serious innovation gaps in academic accounting research?
- Is accounting research stagnant?
- How can accounting researchers be more innovative?
- Is there an "absence of dissent" in academic accounting research?
- Is there an absence of diversity in our top academic accounting
research journals and doctoral programs?
- Is there a serious disinterest (except among the Cargo Cult) and
lack of validation in findings reported in our academic accounting
research journals, especially TAR?
- Is there a huge communications gap between academic accounting
researchers and those who toil teaching accounting and practicing
accounting?
- Why do our accountics scientists virtually ignore the AECM and the
AAA Commons and the Pathways Commission Report?
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
One fall out of this thread is that I've been privately asked to write a
paper about such matters. I hope that others will compete with me in
thinking and writing about these serious challenges to academic accounting
research that never seem to get resolved.
Thank you Steve for sometimes responding in my threads on such issues in
the AECM.
Respectfully,
Bob Jensen
June 16, 2013 message from Bob
Jensen
Hi Marc,
The mathematics of falsification is essentially the same as
the mathematics of proof negation.
If mathematics is a science it's
largely a science of counter examples.
Regarding real-real science versus
pseudo-science, one criterion is that of explanation (not just
prediction) that satisfies a community of scholars. One of the best
examples of this are the exchanges between two Nobel economists ---
Milton Friedman versus Herb Simon.
From
http://www.cs.trinity.edu/~rjensen/temp/DeirdreMcCloskey/StatisticalSignificance01.htm
Jensen Comment
Interestingly, two Nobel economists slugged out the very essence
of theory some years back. Herb Simon insisted that the purpose
of theory was to explain. Milton Friedman went off on the
F-Twist tangent saying that it was enough if a theory merely
predicted. I lost some (certainly not all) respect for Friedman
over this. Deidre, who knew Milton, claims that deep in his
heart, Milton did not ultimately believe this to the degree that
it is attributed to him. Of course Deidre herself is not a great
admirer of Neyman, Savage, or Fisher.
Friedman's essay "The
Methodology of Positive Economics"
(1953) provided the
epistemological pattern for his
own subsequent research and to a degree that of the Chicago
School. There he argued that economics as science
should be free of value judgments for it to be objective.
Moreover, a useful economic theory should be judged not by
its descriptive realism but by its simplicity and
fruitfulness as an engine of prediction. That is, students
should measure the accuracy of its predictions, rather than
the 'soundness of its assumptions'. His argument was part of
an ongoing debate among such statisticians as
Jerzy Neyman,
Leonard Savage, and
Ronald Fisher.
Stanley Wong, 1973. "The 'F-Twist'
and the Methodology of Paul Samuelson," American Economic Review,
63(3) pp. 312-325. Reprinted in J.C. Wood & R.N. Woods, ed., 1990,
Milton Friedman: Critical Assessments, v. II, pp. 224- 43.
http://www.jstor.org/discover/10.2307/1914363?uid=3739712&uid=2129&uid=2&uid=70&uid=4&uid=3739256&sid=21102409988857
Respectfully,
Bob Jensen
June 18, 2013 reply to David Johnstone by Jagdish Gangolly
David,
Your call for a dialogue between statistics and
philosophy of science is very timely, and extremely important considering
the importance that statistics, both in its probabilistic and
non-probabilistic incarnations, has gained ever since the computational
advances of the past three decades or so. Let me share a few of my
conjectures regarding the cause of this schism between statistics and
philosophy, and consider a few areas where they can share in mutual
reflection. However, reflection in statistics, like in accounting of late
and unlike in philosophy, has been on short order for quite a while. And it
is always easier to pick the low hanging fruit. Albert Einstein once
remarked, ""I have little patience with scientists who take a board of wood,
look for the thinnest part and drill a great number of holes where drilling
is easy".
1.
Early statisticians were practitioners of the art,
most serving as consultants of sorts. Gosset worked for Guiness, GEP Box did
most of his early work for Imperial Chemical Industries (ICI), Fisher worked
at Rothamsted Experimental Station, Loeve was an actuary at University of
Lyon... As practitioners, statisticians almost always had their feet in one
of the domains in science: Fisher was a biologist, Gossett was a chemist,
Box was a chemist, ... Their research was down to earth, and while
statistics was always regarded the turf of mathematicians, their status
within mathematics was the same as that of accountants in liberal arts
colleges today, slightly above that of athletics. Of course, the individuals
with stature were expected to be mathematicians in their own right.
All that changed with the work of Kolmogorov (1933,
Moscow State, http://www.socsci.uci.edu/~bskyrms/bio/readings/kolmogorov_theory_of_probability_small.pdf),
Loeve (1960, Berkeley), Doob(1953, Illinois), and Dynkin(1963, Moscow State
and Cornell). They provided mathematical foundations for earlier work of
practitioners, and especially Kolmogorov provided axiomatic foundations for
probability theory. In the process, their work unified statistics into a
coherent mass of knowledge. (Perhaps there is a lesson here for us
accountants). A collateral effect was the schism in the field between the
theoreticians and the practitioners (of which we accountants must be wary)
that has continued to this date. We can see a parallel between accounting
and statistics here too.
2.
Early controversies in statistics had to do with
embedding statistical methods in decision theory (Fisher was against, Neyman
and Pearson were for it), and whether the foundations for statistics had to
be deductive or inductive (frequentists were for the former, Bayesians were
for the latter). These debates were not just technical, and had
underpinnings in philosophy, especially philosophy of mathematics (after
all, the early contributors to the field were mathematicians: Gauss, Fermat,
Pascal, Laplace, deMoivre, ...). For example, when the Fisher-Neyman/Pearson
debates had ranged, Neyman was invited by the philosopher Jakko Hintikka to
write a paper for the journal Synthese ( "Frequentist probability and
Frequentist statistics", 1977).
3.
Since the early statisticians were practitioners,
their orientation was usually normative: in sample theory, regression,
design of experiments,.... The mathematisation of statistics and later work
of people like Tukey, raised the prominence of descriptive (especially
axiomatic) in the field. However, the recent developments in datamining have
swung the balance again in favour of the normative.
4. Foundational issues in statistics have always
been philosophical. And treatment of probability has been profoundly
philosophical (see for example http://en.wikipedia.org/wiki/Probability_interpretations).
Regards,
Jagdish
June 18, 2018 reply from David Johnstone
Dear Jagdish, as usual your knowledge and
perspectives are great to read.
In reply to your points: (1) the early development
of statistics by Gossett and Fisher was as a means to an end, i.e. to design
and interpret experiments that helped to resolve practical issues, like
whether fertilizers were effective and different genetic strains of crops
were superior. This left results testable in the real world laboratory, by
the farmers, so the pressure to get it right rather than just publish was
on. Gossett by the way was an old fashioned English scholar who spent as
much time fishing and working in his workshop as doing mathematics. This
practical bent comes out in his work.
(2) Neman’s effort to make statistics “deductive”
was always his weak point, and he went to great lengths to evade this issue.
I wrote a paper on Neyman’s interpretations of tests, as in trying to
understand him I got frustrated by his inconsistency and evasiveness over
his many papers. In more than one place, he wrote that to “accept” the null
is to “act as if it is true”, and to reject it is to “act as if it is
false”. This is ridiculous in scientific contexts, since to act as if
something is decided 100% you would never draw another sample - your work
would be done on that hypothesis.
(3) On the issue of normative versus descriptive,
as in accounting research, Harold Jeffreys had a great line in his book, “he
said that if we observe a child add 2 and 2 to get 5, we don’t change the
laws of arithmetic”. He was very anti learning about the world by watching
people rather than doing abstract theory. BTW I own his personal copy of his
3rd edition. A few years ago I went to buy this book on Bookfinder, and
found it available in a secondhand bookshop in Cambridge. I rand them
instantly when I saw that they said whose book it was, and they told me that
Mrs Jeffreys had just died and Harold’s books had come in, and that the 1st
edition was sold the day before.
(4) I adore your line that “Foundational issues in
statistics have always been philosophical”. .... So must they be in
accounting, in relation to how to construct income and net assets measures
that are sound and meaningful. Note however that just because we accept
something needs philosophical footing doesn’t mean that we will find or
agree on that footing. I recently received a comment on a paper of mine from
an accounting referee. The comment was basically that the effect of
information on the cost of capital “could not be revealed by philosophy”
(i.e. by probability theory etc.). Rather, this is an empirical issue. Apart
from ignoring all the existing theory on this matter in accounting and
finance, the comment is symptomatic of the way that “empirical findings”
have been elevated to the top shelf, and theory, or worse, “thought pieces”,
are not really science. There is so much wrong with this extreme but common
view, including of course that every empirical finding stands on a model or
a priori view. Indeed, remember that every null hypothesis that was ever
rejected might have been rejected because the model (not the hypothesis) was
wrong. People naively believe that a bad model or bad experimental design
just reduces power (makes it harder to reject the null) but the mathematical
fact is that it can go either way, and error in the model or sample design
can make rejection of the null almost certain.
Thank you for your interesting thoughts Jagdish,
David
From Bob Jensen's threads on the Cult of Statistical Significance ---
http://www.cs.trinity.edu/~rjensen/temp/DeirdreMcCloskey/StatisticalSignificance01.htm
The Cult of Statistical Significance: How Standard Error Costs Us Jobs,
Justice, and Lives ---
http://www.cs.trinity.edu/~rjensen/temp/DeirdreMcCloskey/StatisticalSignificance01.htm
Page 15
The doctor who cannot distinguish statistical significance from
substantive significance, an F-statistic from a heart attach, is like an
economist who ignores opportunity cost---what statistical theorists call
the loss function. The doctors of "significance" in medicine and economy
are merely "deciding what to say rather than what to do" (Savage 1954,
159). In the 1950s Ronald Fisher published an article and a book that
intended to rid decision from the vocabulary of working
statisticians (1955, 1956). He was annoyed by the rising authority in
highbrow circles of those he called "the Neymanites."
Continued on Page 15
pp. 28-31
An example is provided regarding how Merck manipulated statistical
inference to keep its killing pain killer Vioxx from being pulled from
the market.
Page 31
Another story. The Japanese government in June 2005 increased the limit
on the number of whales that may be annually killed in the
Antarctica---from around 440 annually to over 1,000 annually. Deputy
Commissioner Akira Nakamae explained why: "We will implement JARPS-2
[the plan for the higher killing] according to the schedule, because the
sample size is determined in order to get statistically significant
results" (Black 2005). The Japanese hunt for the whales, they claim, in
order to collect scientific data on them. That and whale steaks. The
commissioner is right: increasing sample size, other things equal, does
increase the statistical significance of the result. It is, fter all, a
mathematical fact that statistical significance increases, other things
equal, as sample size increases. Thus the theoretical standard error of
JAEPA-2, s/SQROOT(440+560) [given for example the simple mean formula],
yields more sampling precision than the standard error JARPA-1,
s/SQROOT(440). In fact it raises the significance level to Fisher's
percent cutoff. So the Japanese government has found a formula for
killing more whales, annually some 560 additional victims, under the
cover of getting the conventional level of Fisherian statistical
significance for their "scientific" studies.
pp. 250-251
The textbooks are wrong. The teaching is wrong. The seminar you just
attended is wrong. The most prestigious journal in your scientific field
is wrong.
You are searching, we know, for ways to avoid
being wrong. Science, as Jeffreys said, is mainly a series of
approximations to discovering the sources of error. Science is a
systematic way of reducing wrongs or can be. Perhaps you feel frustrated
by the random epistemology of the mainstream and don't know what to do.
Perhaps you've been sedated by significance and lulled into silence.
Perhaps you sense that the power of a Roghamsted test against a
plausible Dublin alternative is statistically speaking low but you feel
oppressed by the instrumental variable one should dare not to wield.
Perhaps you feel frazzled by what Morris Altman (2004) called the
"social psychology rhetoric of fear," the deeply embedded path
dependency that keeps the abuse of significance in circulation. You want
to come out of it. But perhaps you are cowed by the prestige of
Fisherian dogma. Or, worse thought, perhaps you are cynically willing
to be corrupted if it will keep a nice job
June 25, 2013 reply from Marc Dupree
An excerpt:
Evidential Variety as a Basis for Inference
The logical composition of the two systems of probability—
mathematical, on the one hand, and causative, on the
other—reveals the systems’ relative strengths and
weaknesses. The mathematical system is most suitable for
decisions that implicate averages. Gambling is a para-
digmatic example of those decisions. At the same time, this
system em- ploys relatively lax standards for identifying
causes and effects. Moreover, it weakens the reasoner’s
epistemic grasp of her individual case by requir- ing her to
abstract away from the case’s specifics. This requirement is
im- posed by the system’s epistemically unfounded rules that
make individual cases look similar to each other despite the
uniqueness of each case. On the positive side, however, the
mathematical system allows a person to concep- tualize her
probabilistic assessments in the parsimonious and
standardized language of numbers. This conceptual framework
enables people to form and communicate their assessments of
probabilities with great precision.
The causative system of probability is not suitable for
gambling. It as- sociates probability with the scope, or
variety, of the evidence that confirms the underlying
individual occurrence. The causative system also employs
rigid standards for establishing causation. Correspondingly,
it disavows in- stantial multiplicity as a basis for
inferences and bans all other factual as- sumptions that do
not have epistemic credentials. These features improve
people’s epistemic grasps of their individual cases. The
causative system has a shortcoming: its unstructured and
“noisy” taxonomy. This system in- structs people to
conceptualize their probability assessments in the ordinary
day-to-day language. This conceptual apparatus is
notoriously imprecise. The causative system therefore has
developed no uniform metric for grada- tion of
probabilities.142
On balance, the causative system outperforms mathematical
probabili- ty in every area of fact-finding for which it was
designed. This system enables people to perform an
epistemically superior causation analysis in both scientific
and daily affairs. Application of the causative system also
improves people’s ability to predict and reconstruct
specific events. The mathematical system, in contrast, is a
great tool for understanding averages and distributions of
multiple events. However, when it comes to an as- sessment
of an individual event, the precision of its estimates of
probability becomes illusory. The causative system
consequently becomes decisively superior.
Marc
I hope Jim K will comment on how "research in business schools is becoming
increasingly distanced from the reality of business"
"In 2008 Hopwood commented on a number of issues," by Jim Martin, MAAW
Blog, June 26, 2013 ---
http://maaw.blogspot.com/2013/06/in-2008-hopwood-commented-on-number-of.html
The first issue below is related to the one
addressed by Bennis and O'Toole. According to Hopwood, research in
business schools is becoming increasingly distanced from the reality of
business. The worlds of practice and research have become ever more
separated. More and more accounting and finance researchers know less and
less about accounting and finance practice. Other professions such as
medicine have avoided this problem so it is not an inevitable development.
Another issue has to do with the status of
management accounting. Hopwood tells us that the term management accountant
is no longer popular and virtually no one in the U.S. refers to themselves
as a management accountant. The body of knowledge formally associated with
the term is now linked to a variety of other concepts and job titles. In
addition, management accounting is no longer an attractive subject to
students in business schools. This is in spite of the fact that many
students will be working in positions where a knowledge of management
control and systems design issues will be needed. Unfortunately, the present
positioning and image of management accounting does not make this known.
Continued in article
June 29, 2013 reply from Zane Swanson
Hi Bob,
A key word of incentive comes up as it relates to
the practitioner motivator of the nature of accounting and financing
research. The AICPA does give an educator award at the AAA convention and so
it isn't as though the practitioners don't care about accounting
professorship activity.
Maybe, the "right"' type of incentive needs to be
designed. For example, it was not so many years ago that firms developed
stock options to align interests of management and investors. Perhaps, a
similar option oriented award could be designed to align the interests of
research professors and practitioners. Theoretically, practitioners could
vest a set of professors for research publications in a pool for a
particular year and then grant the exercise of the option several years
later with the attainment of a practitioner selected goal level (like HR
performance share awards). This approach could meet your calls to get
researchers to write "real world" papers and to have follow up replications
to prove the point.
However, there are 2 road blocks to this approach.
1 is money for the awards. 2 is determining what the practitioner
performance features would be.
You probably would have to determine what
practitioners want in terms of research or this whole line of discussion is
moot.
The point of this post is: Determining research
demand solely by professors choices does not look like it is addressing your
"real world" complaints.
Respectfully,
Zane
June 29, 2013 reply from Bob Jensen
Hi Zane,
I had a very close friend (now dead) in the Engineering Sciences
Department at Trinity University. I asked him why engineering professors
seemed to be much closer to their profession than many other departments in
the University. He said he thought it was primarily that doctoral students
chose engineering because they perhaps were more interested in being problem
solvers --- and their profession provided them with an unlimited number of
professional problems to be solved. Indeed the majority of Ph.D. graduates
in engineering do not even join our Academy. The ones that do are not a
whole lot different from the Ph.D. engineers who chose to go into industry
except that engineering professors do more teaching.
When they take up research projects, engineering professors tend to be
working with government (e.g., the EPA) and and industry (e.g., Boeing) to
help solve problems. In many instances they work on grants, but many
engineering professors are working on industry problems without grants.
In contrast, accounting faculty don't like to work with practitioners to
solve problems. In fact accounting faculty don't like to leave the campus to
explore new problems and collect data. The capital markets accounting
researchers purchase their databases and them mine the data. The behavioral
accounting researchers study their students as surrogates for real world
decision makers knowing full well that students are almost always poor
surrogates. The analytical accounting researchers simply assume the world
away. They don't set foot off campus except to go home at night. I know
because I was one of them for nearly all of my career.
Academic accounting researchers submit very little original research work
to journals that practitioners read. Even worse a hit in an accounting
practitioner journal counts very little for promotion and tenure especially
when the submission itself may be too technical to interest any of our AAA
journal editors, e.g., an editor told me that the AAA membership was just
not interested in technical articles on valuing interest rate swaps, I had
to get two very technical papers on accounting for derivative financial
instruments published in a practitioner journal (Derivatives Reports)
because I was told that these papers were just too technical for AAA journal
readers.
Our leading accountics science researchers have one goal in mind ---
getting a hit in TAR, JAR, or JAE or one of the secondary academic
accounting research journals that will publish accountics research. They
give little or no priority to finding and helping to solve problems that
practitioners want solved. They have little interest in leaving the ivory
tower to collect their own messy real-world data.
Awards and even research grants aren't the answer to making accounting
professors more like engineering, medical, and law professors. We need to
change the priorities of TAR, JAR, JAE, and other top academic accounting
research journals where referees ask hard questions about how the practice
of the profession is really helped by the research findings of virtually all
submitted articles.
In short, we need to become better problem solvers in a way like
engineering, medical, and law professors are problem solvers on the major
problems of their professions. A great start would be to change the
admissions criteria of our top accounting research journals.
Respectfully,
Bob Jensen
Avoiding applied research for practitioners and failure to attract practitioner
interest in academic research journals ---
"Why business ignores the business schools," by Michael Skapinker
Some ideas for applied research ---
http://faculty.trinity.edu/rjensen/theory01.htm#AcademicsVersusProfession
Essays on the (mostly sad) State of Accounting Scholarship ---
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm#Essays
Sue Haka, former AAA President, commenced a thread on the AAA Commons
entitled
"Saving Management Accounting in the Academy,"
---
http://commons.aaahq.org/posts/98949b972d
A succession of comments followed.
The latest comment (from James Gong) may be of special interest to some of
you.
Ken Merchant is a former faculty member from Harvard University who form many
years now has been on the faculty at the University of Southern California.
Here are my two cents. First, on the teaching side,
the management accounting textbooks fail to cover new topics or issues. For
instance, few textbooks cover real options based capital budgeting, product
life cycle management, risk management, and revenue driver analysis. While
other disciplines invade management accounting, we need to invade their
domains too. About five or six years ago, Ken Merchant had written a few
critical comments on Garrison/Noreen textbook for its lack of breadth. Ken's
comments are still valid. Second, on the research and publication side,
management accounting researchers have disadvantage in getting data and
publishing papers compared with financial peers. Again, Ken Merchant has an
excellent discussion on this topic at an AAA annual conference.
Bob Jensen's threads on what went wrong in the Accounting Academy
How did academic accounting research become a pseudo science?
http://faculty.trinity.edu/rjensen/theory01.htm#WhatWentWrong ---
June 30, 2013 reply from Zane Swanson
Hi Bob,
You have expressed your concerns articulately and passionately. However,
in terms of creating value to society in general, your "action plan" of
getting the "top" of the profession (editors) to take steps appears
unlikely. As you pointed out, the professors who create articles do it with
resources immediately under their control in the most expeditious fashion in
order to get tenure, promotion and annual raises. The editors take what
submissions are given. Thus, it is an endless cycle (a closed loop, a
complete circle). As you noted the engineering profession has different
culture with a "make it happen" objective real world. In comparison with
accounting, the prospect of "only" accounting editors from the top dictating
research seems questionable. Your critique suggests that the "entire"
accounting research culture needs a paradigm shift of real world action
consequences in order to do what you want. The required big data shift is
probably huge and is a reason that I suggested starting an options alignment
mechanism of interests of practitioners and researchers.
Respectfully,
Zane
June 30, 2013 reply from Bob Jensen
You may be correct that a paradigm shift in accountics research is
just not feasible given the generations of econometrics,
psychometrics. and mathematical accountics researchers that
virtually all of the North American doctoral programs have produced.
I think Anthony Hopwood, Paul Williams, and others agree with you that
it will take a paradigm shift that just is not going to happen in our
leading journals like TAR, JAR, JAE, CAR, etc. Paul, however, thinks we
are making some traction, especially since virtually all AAA presidents
since Judy Rayburn have made appeals fro a paradigm shift plus the
strong conclusions of the Pathways Commission Report. However, that
report seems to have fallen on deaf ears as far as accountics scientists
are concerned.
Other historical scholars like Steve Zeff, Mike Granfof, Bob Kaplan, Judy
Rayburn, Sudipta Basu, and think that we can wedge these top journals to
just be a bit more open to alternative research methods like were used in
the past when practitioners took a keen interest in TAR and even submitted
papers to be published in TAR --- alternative methods like case studies,
field studies, and normative studies without equations.
"We fervently hope that the research pendulum will soon swing back from
the narrow lines of inquiry that dominate today's leading journals to a
rediscovery of the richness of what accounting research can be. For that to
occur, deans and the current generation of academic accountants must
give it a push."
Granof and Zeff ---
http://www.trinity.edu/rjensen/TheoryTAR.htm#Appendix01
Michael H. Granof is a professor of accounting at the McCombs School of
Business at the University of Texas at Austin. Stephen A. Zeff is a
professor of accounting at the Jesse H. Jones Graduate School of Management
at Rice University.
Accounting Scholarship that Advances Professional Knowledge
and Practice
Robert S. Kaplan
The Accounting Review, March 2011, Volume 86, Issue 2,
Recent accounting scholarship has used
statistical analysis on asset prices, financial reports and disclosures,
laboratory experiments, and surveys of practice. The research has
studied the interface among accounting information, capital markets,
standard setters, and financial analysts and how managers make
accounting choices. But as accounting scholars have focused on
understanding how markets and users process accounting data, they have
distanced themselves from the accounting process itself. Accounting
scholarship has failed to address important measurement and valuation
issues that have arisen in the past 40 years of practice. This gap is
illustrated with missed opportunities in risk measurement and management
and the estimation of the fair value of complex financial securities.
This commentary encourages accounting scholars to devote more resources
to obtaining a fundamental understanding of contemporary and future
practice and how analytic tools and contemporary advances in accounting
and related disciplines can be deployed to improve the professional
practice of accounting. ©2010 AAA
The videos of the three plenary speakers at the 2010 Annual Meetings in San
Francisco are now linked at
http://commons.aaahq.org/hives/531d5280c3/posts?postTypeName=session+video
I think the video is only available to AAA members.
Hi David,
Separately and independently, both
Steve Kachelmeier (Texas) and Bob Kaplan (Harvard) singled out
the Hunton and Gold (2010) TAR article as being an excellent
paradigm shift model in the sense that the data supposedly was
captured by practitioners with the intent of jointly working
with academic experts in collecting and analyzing the data
---
If that data had subsequently not been
challenged for integrity (by whom is secret) that Hunton and Gold
(2010) research us the type of thing we definitely would like to see
more of in accountics research.
Unfortunately, this excellent example may
have been a bit like Lance Armstrong being such a winner because he did
not playing within the rules.
For Jim Hunton maybe the world did
end on December 21, 2012
"Following Retraction, Bentley
Professor Resigns," Inside Higher Ed, December 21, 2012 ---
http://www.insidehighered.com/quicktakes/2012/12/21/following-retraction-bentley-professor-resigns
James E. Hunton, a
prominent accounting professor at Bentley University, has resigned
amid an investigation of the retraction of an article of which he
was the co-author, The Boston Globe reported. A spokeswoman cited
"family and health reasons" for the departure, but it follows the
retraction of an article he co-wrote in the journal Accounting
Review. The university is investigating the circumstances that led
to the journal's decision to retract the piece.
An Accounting Review Article
is Retracted
One of the
article that Dan mentions has been retracted, according to
http://aaajournals.org/doi/abs/10.2308/accr-10326?af=R
Retraction: A Field
Experiment Comparing the Outcomes of Three Fraud Brainstorming
Procedures: Nominal Group, Round Robin, and Open Discussion
James E. Hunton,
Anna Gold Bentley University and Erasmus University Erasmus
University This article was originally published in 2010 in The
Accounting Review 85 (3) 911–935; DOI:
10/2308/accr.2010.85.3.911
The authors
confirmed a misstatement in the article and were unable to provide
supporting information requested by the editor and publisher.
Accordingly, the article has been retracted.
Jensen Comment
The TAR article retraction in no way detracts from this study being a
model to shoot for in order to get accountics researchers more involved
with the accounting profession and using their comparative advantages to
analyze real world data that is more granulated that the usual practice
of beating purchased databases like Compustat with econometric sticks
and settling for correlations rather than causes.
Respectfully,
Bob Jensen
"Why the “Maximizing Shareholder Value” Theory of Corporate Governance is
Bogus," Naked Capitalism, October 21, 2013 ---
http://www.nakedcapitalism.com/2013/10/why-the-maximizing-shareholder-value-theory-of-corporate-governance-is-bogus.html
. . .
So how did this “the last shall come first” thinking become established?
You can blame it all on economists, specifically Harvard Business
School’s Michael Jensen. In other words, this idea did not come out of
legal analysis, changes in regulation, or court decisions. It was simply
an academic theory that went mainstream. And to add insult to injury,
the version of the Jensen formula that became popular was its worst
possible embodiment.
A terrific 2010 paper by Frank Dobbin and Jiwook
Jung, “The
Misapplication of Mr. Michael Jensen: How Agency Theory Brought Down the
Economy and Might Do It Again,” explains how this line of thinking
went mainstream. I strongly suggest you read it in full, but I’ll give a
brief recap for the time-pressed.
In the 1970s, there was a great deal of hand-wringing in America as
Japanese and German manufacturers were eating American’s lunch. That led
to renewed examination of how US companies were managed, with lots of
theorizing about what went wrong and what the remedies might be. In
1976, Jensen and William Meckling asserted that the problem was that
corporate executives served their own interests rather than those of
shareholders, in other words, that there was an agency problem.
Executives wanted to build empires while shareholders wanted profits to
be maximized.
I strongly suspect that if Jensen and Meckling had not come out with
this line of thinking, you would have gotten something similar to
justify the actions of the leveraged buyout kings, who were just getting
started in the 1970s and were reshaping the corporate landscape by the
mid-1980s. They were doing many of the things Jensen and Meckling
recommended: breaking up multi-business companies, thinning out
corporate centers, and selling corporate assets (some of which were
clearly excess, like corporate art and jet collection, while other sales
were simply to increase leverage, like selling corporate office
buildings and leasing them back). In other words, a likely reason that
Jensen and Meckling’s theory gained traction was it appeared to validate
a fundamental challenge to incumbent managements. (Dobbin and Jung
attribute this trend, as pretty much everyone does, to Jensen because he
continued to develop it. What really put it on the map was a 1990
Harvard Business Review article, “It’s
Not What You Pay CEOs, but How,” that led to an explosion in the use
of option-based pay and resulted in a huge increase in CEO pay relative
to that of average workers.)
To forestall takeovers, many companies implemented the measures an
LBO artist might take before his invading army arrived: sell off
non-core divisions, borrow more, shed staff.
The problem was to the extent that the Jensen/Meckling prescription
had merit, only the parts that helped company executives were adopted.
Jensen didn’t just call on executives to become less ministerial and
more entrepreneurial; they also called for more independent and engaged
boards to oversee and discipline top managers, and more equity-driven
pay, both options and other equity-linked compensation, to make
management more sensitive to both upside and downside risks.
Over the next two decades, companies levered up, became more
short-term oriented, and executive pay levels exploded. As Dobbin and
Jung put it, “The result of the changes promoted by agency theory was
that by the late 1990s, corporate America’s leaders were drag racing
without the brakes.”
The paper proceeds to analyze in considerable detail how three of the
major prescriptions of “agency theory” aka “executives and boards should
maximize value,” namely, pay for (mythical) performance,
dediversification, and greater reliance on debt all increased risk. And
the authors also detail how efforts to improve oversight were
ineffective.
But the paper also makes clear that this vision of how companies
should be run was simply a new management fashion, as opposed to any
sort of legal requirement:
Organizational institutionalists have long argued that new
management practices diffuse through networks of firms like fads
spread through high schools….In their models, new paradigms are
socially constructed as appropriate solutions to perceived problems
or crises….Expert groups that stand to gain from having their
preferred strategies adopted by firms then enter the void, competing
to have their model adopted….
And as Dobbin and Jung point out, the parts of the Jensen formula
that got adopted were the one that had constituents. The ones that
promoted looting and short-termism had obvious followings. The ones for
prudent management didn’t.
And consider the implications of Jensen’s prescriptions, of pushing
companies to favor shareholders, when they actually stand at the back of
the line from a legal perspective. The result is that various agents
(board compensation consultants, management consultants, and cronyistic
boards themselves) have put incentives in place for CEOs to favor
shareholders over parties that otherwise should get better treatment. So
is it any surprise that companies treat employees like toilet paper,
squeeze vendors, lobby hard for tax breaks and to weaken regulations,
and worse, like fudge their financial reports? Jensen himself, in 2005,
repudiated his earlier prescription precisely because it led to fraud.
From
an interview with the New York Times:
Q. So the maximum stock price is the holy grail?
A. Absolutely not. Warren Buffett says he worries as much when
one of his companies becomes overvalued as undervalued. I agree.
Overvalued equity is managerial heroin – it feels really great when
you start out; you’re feted on television; investment bankers vie to
float new issues.
But it doesn’t take long before the elation and ecstasy turn into
enormous pain. The market starts demanding increased earnings and
revenues, and the managers begin to say: “Holy Moley! How are we
going to generate the returns?” They look for legal loopholes in the
accounting, and when those don’t work, even basically honest people
move around the corner to outright fraud.
If they hold a lot of stock or options themselves, it is like
pouring gasoline on a fire. They fudge the numbers and hope they can
sell the stock or exercise the options before anything hits the fan.
Q. Are you suggesting that executives be rewarded for driving
down the price of the stock?
A. I’m saying they should be rewarded for being honest. A C.E.O.
should be able to tell investors, “Listen, this company isn’t worth
its $70 billion market cap; it’s really worth $30 billion, and
here’s why.”
But the board would fire that executive immediately. I guess it
has to be preventative – if executives would present the market with
realistic numbers rather than overoptimistic expectations, the stock
price would stay realistic. But I admit, we scholars don’t yet know
the real answer to how to make this happen.
So having led Corporate America in the wrong direction, Jensen
‘fesses up no one knows the way out. But if executives weren’t
incentivized to take such a topsy-turvey shareholder-driven view of the
world, they’d weigh their obligations to other constituencies, including
the community at large, along with earning shareholders a decent return.
But it’s now become so institutionalized it’s hard to see how to move to
a more sensible regime. For instance, analysts regularly try pressuring
Costco to pay its workers less, wanting fatter margins. But the
comparatively high wages are
an integral part of Costco’s formula: it reduces costly staff
turnover and employee pilferage. And Costco’s upscale members report
they prefer to patronize a store they know treats workers better than
Walmart and other discounters. If managers with an established,
successful formulas still encounter pressure from the Street to strip
mine their companies, imagine how hard it is for struggling companies or
less secure top executives to implement strategies that will take a
while to reap rewards. I’ve been getting reports from McKinsey from the
better part of a decade that they simply can’t get their clients to
implement new initiatives if they’ll dent quarterly returns.
This governance system is actually in crisis, but the extraordinary
profit share that companies have managed to achieve by squeezing workers
and the asset-goosing success of post-crisis financial policies have
produced an illusion of health. But porcine maquillage only improves
appearances; it doesn’t mask the stench of gangrene. Nevertheless,
executives have successfully hidden the generally unhealthy state of
their companies. As long as they have cheerleading analysts, complacent
boards and the Fed protecting their back, they can likely continue to
inflict more damage, using “maximizing shareholder value” canard as the
cover for continuing rent extraction.
Read more at
http://www.nakedcapitalism.com/2013/10/why-the-maximizing-shareholder-value-theory-of-corporate-governance-is-bogus.html#ehj10weqAL2vdXkh.99
So how did this “the last shall come first” thinking become established?
You can blame it all on economists, specifically Harvard Business
School’s Michael Jensen. In other words, this idea did not come out of
legal analysis, changes in regulation, or court decisions. It was simply
an academic theory that went mainstream. And to add insult to injury,
the version of the Jensen formula that became popular was its worst
possible embodiment.
A terrific 2010 paper by Frank Dobbin and Jiwook
Jung, “The
Misapplication of Mr. Michael Jensen: How Agency Theory Brought Down the
Economy and Might Do It Again,” explains how this line of thinking
went mainstream. I strongly suggest you read it in full, but I’ll give a
brief recap for the time-pressed.
In the 1970s, there was a great deal of hand-wringing in America as
Japanese and German manufacturers were eating American’s lunch. That led
to renewed examination of how US companies were managed, with lots of
theorizing about what went wrong and what the remedies might be. In
1976, Jensen and William Meckling asserted that the problem was that
corporate executives served their own interests rather than those of
shareholders, in other words, that there was an agency problem.
Executives wanted to build empires while shareholders wanted profits to
be maximized.
I strongly suspect that if Jensen and Meckling had not come out with
this line of thinking, you would have gotten something similar to
justify the actions of the leveraged buyout kings, who were just getting
started in the 1970s and were reshaping the corporate landscape by the
mid-1980s. They were doing many of the things Jensen and Meckling
recommended: breaking up multi-business companies, thinning out
corporate centers, and selling corporate assets (some of which were
clearly excess, like corporate art and jet collection, while other sales
were simply to increase leverage, like selling corporate office
buildings and leasing them back). In other words, a likely reason that
Jensen and Meckling’s theory gained traction was it appeared to validate
a fundamental challenge to incumbent managements. (Dobbin and Jung
attribute this trend, as pretty much everyone does, to Jensen because he
continued to develop it. What really put it on the map was a 1990
Harvard Business Review article, “It’s
Not What You Pay CEOs, but How,” that led to an explosion in the use
of option-based pay and resulted in a huge increase in CEO pay relative
to that of average workers.)
To forestall takeovers, many companies implemented the measures an
LBO artist might take before his invading army arrived: sell off
non-core divisions, borrow more, shed staff.
The problem was to the extent that the Jensen/Meckling prescription
had merit, only the parts that helped company executives were adopted.
Jensen didn’t just call on executives to become less ministerial and
more entrepreneurial; they also called for more independent and engaged
boards to oversee and discipline top managers, and more equity-driven
pay, both options and other equity-linked compensation, to make
management more sensitive to both upside and downside risks.
Over the next two decades, companies levered up, became more
short-term oriented, and executive pay levels exploded. As Dobbin and
Jung put it, “The result of the changes promoted by agency theory was
that by the late 1990s, corporate America’s leaders were drag racing
without the brakes.”
The paper proceeds to analyze in considerable detail how three of the
major prescriptions of “agency theory” aka “executives and boards should
maximize value,” namely, pay for (mythical) performance,
dediversification, and greater reliance on debt all increased risk. And
the authors also detail how efforts to improve oversight were
ineffective.
But the paper also makes clear that this vision of how companies
should be run was simply a new management fashion, as opposed to any
sort of legal requirement:
Organizational institutionalists have long argued that new
management practices diffuse through networks of firms like fads
spread through high schools….In their models, new paradigms are
socially constructed as appropriate solutions to perceived problems
or crises….Expert groups that stand to gain from having their
preferred strategies adopted by firms then enter the void, competing
to have their model adopted….
And as Dobbin and Jung point out, the parts of the Jensen formula
that got adopted were the one that had constituents. The ones that
promoted looting and short-termism had obvious followings. The ones for
prudent management didn’t.
And consider the implications of Jensen’s prescriptions, of pushing
companies to favor shareholders, when they actually stand at the back of
the line from a legal perspective. The result is that various agents
(board compensation consultants, management consultants, and cronyistic
boards themselves) have put incentives in place for CEOs to favor
shareholders over parties that otherwise should get better treatment. So
is it any surprise that companies treat employees like toilet paper,
squeeze vendors, lobby hard for tax breaks and to weaken regulations,
and worse, like fudge their financial reports? Jensen himself, in 2005,
repudiated his earlier prescription precisely because it led to fraud.
From
an interview with the New York Times:
Q. So the maximum stock price is the holy grail?
A. Absolutely not. Warren Buffett says he worries as much when
one of his companies becomes overvalued as undervalued. I agree.
Overvalued equity is managerial heroin – it feels really great when
you start out; you’re feted on television; investment bankers vie to
float new issues.
But it doesn’t take long before the elation and ecstasy turn into
enormous pain. The market starts demanding increased earnings and
revenues, and the managers begin to say: “Holy Moley! How are we
going to generate the returns?” They look for legal loopholes in the
accounting, and when those don’t work, even basically honest people
move around the corner to outright fraud.
If they hold a lot of stock or options themselves, it is like
pouring gasoline on a fire. They fudge the numbers and hope they can
sell the stock or exercise the options before anything hits the fan.
Q. Are you suggesting that executives be rewarded for driving
down the price of the stock?
A. I’m saying they should be rewarded for being honest. A C.E.O.
should be able to tell investors, “Listen, this company isn’t worth
its $70 billion market cap; it’s really worth $30 billion, and
here’s why.”
But the board would fire that executive immediately. I guess it
has to be preventative – if executives would present the market with
realistic numbers rather than overoptimistic expectations, the stock
price would stay realistic. But I admit, we scholars don’t yet know
the real answer to how to make this happen.
So having led Corporate America in the wrong direction, Jensen
‘fesses up no one knows the way out. But if executives weren’t
incentivized to take such a topsy-turvey shareholder-driven view of the
world, they’d weigh their obligations to other constituencies, including
the community at large, along with earning shareholders a decent return.
But it’s now become so institutionalized it’s hard to see how to move to
a more sensible regime. For instance, analysts regularly try pressuring
Costco to pay its workers less, wanting fatter margins. But the
comparatively high wages are
an integral part of Costco’s formula: it reduces costly staff
turnover and employee pilferage. And Costco’s upscale members report
they prefer to patronize a store they know treats workers better than
Walmart and other discounters. If managers with an established,
successful formulas still encounter pressure from the Street to strip
mine their companies, imagine how hard it is for struggling companies or
less secure top executives to implement strategies that will take a
while to reap rewards. I’ve been getting reports from McKinsey from the
better part of a decade that they simply can’t get their clients to
implement new initiatives if they’ll dent quarterly returns.
This governance system is actually in crisis, but the extraordinary
profit share that companies have managed to achieve by squeezing workers
and the asset-goosing success of post-crisis financial policies have
produced an illusion of health. But porcine maquillage only improves
appearances; it doesn’t mask the stench of gangrene. Nevertheless,
executives have successfully hidden the generally unhealthy state of
their companies. As long as they have cheerleading analysts, complacent
boards and the Fed protecting their back, they can likely continue to
inflict more damage, using “maximizing shareholder value” canard as the
cover for continuing rent extraction.
Read more at
http://www.nakedcapitalism.com/2013/10/why-the-maximizing-shareholder-value-theory-of-corporate-governance-is-bogus.html#ehj10weqAL2vdXkh.99
So how did this “the last shall come first” thinking become established?
You can blame it all on economists, specifically Harvard Business
School’s Michael Jensen. In other words, this idea did not come out of
legal analysis, changes in regulation, or court decisions. It was simply
an academic theory that went mainstream. And to add insult to injury,
the version of the Jensen formula that became popular was its worst
possible embodiment.
A terrific 2010 paper by Frank Dobbin and Jiwook
Jung, “The
Misapplication of Mr. Michael Jensen: How Agency Theory Brought Down the
Economy and Might Do It Again,” explains how this line of thinking
went mainstream. I strongly suggest you read it in full, but I’ll give a
brief recap for the time-pressed.
In the 1970s, there was a great deal of hand-wringing in America as
Japanese and German manufacturers were eating American’s lunch. That led
to renewed examination of how US companies were managed, with lots of
theorizing about what went wrong and what the remedies might be. In
1976, Jensen and William Meckling asserted that the problem was that
corporate executives served their own interests rather than those of
shareholders, in other words, that there was an agency problem.
Executives wanted to build empires while shareholders wanted profits to
be maximized.
I strongly suspect that if Jensen and Meckling had not come out with
this line of thinking, you would have gotten something similar to
justify the actions of the leveraged buyout kings, who were just getting
started in the 1970s and were reshaping the corporate landscape by the
mid-1980s. They were doing many of the things Jensen and Meckling
recommended: breaking up multi-business companies, thinning out
corporate centers, and selling corporate assets (some of which were
clearly excess, like corporate art and jet collection, while other sales
were simply to increase leverage, like selling corporate office
buildings and leasing them back). In other words, a likely reason that
Jensen and Meckling’s theory gained traction was it appeared to validate
a fundamental challenge to incumbent managements. (Dobbin and Jung
attribute this trend, as pretty much everyone does, to Jensen because he
continued to develop it. What really put it on the map was a 1990
Harvard Business Review article, “It’s
Not What You Pay CEOs, but How,” that led to an explosion in the use
of option-based pay and resulted in a huge increase in CEO pay relative
to that of average workers.)
To forestall takeovers, many companies implemented the measures an
LBO artist might take before his invading army arrived: sell off
non-core divisions, borrow more, shed staff.
The problem was to the extent that the Jensen/Meckling prescription
had merit, only the parts that helped company executives were adopted.
Jensen didn’t just call on executives to become less ministerial and
more entrepreneurial; they also called for more independent and engaged
boards to oversee and discipline top managers, and more equity-driven
pay, both options and other equity-linked compensation, to make
management more sensitive to both upside and downside risks.
Over the next two decades, companies levered up, became more
short-term oriented, and executive pay levels exploded. As Dobbin and
Jung put it, “The result of the changes promoted by agency theory was
that by the late 1990s, corporate America’s leaders were drag racing
without the brakes.”
The paper proceeds to analyze in considerable detail how three of the
major prescriptions of “agency theory” aka “executives and boards should
maximize value,” namely, pay for (mythical) performance,
dediversification, and greater reliance on debt all increased risk. And
the authors also detail how efforts to improve oversight were
ineffective.
But the paper also makes clear that this vision of how companies
should be run was simply a new management fashion, as opposed to any
sort of legal requirement:
Organizational institutionalists have long argued that new
management practices diffuse through networks of firms like fads
spread through high schools….In their models, new paradigms are
socially constructed as appropriate solutions to perceived problems
or crises….Expert groups that stand to gain from having their
preferred strategies adopted by firms then enter the void, competing
to have their model adopted….
And as Dobbin and Jung point out, the parts of the Jensen formula
that got adopted were the one that had constituents. The ones that
promoted looting and short-termism had obvious followings. The ones for
prudent management didn’t.
And consider the implications of Jensen’s prescriptions, of pushing
companies to favor shareholders, when they actually stand at the back of
the line from a legal perspective. The result is that various agents
(board compensation consultants, management consultants, and cronyistic
boards themselves) have put incentives in place for CEOs to favor
shareholders over parties that otherwise should get better treatment. So
is it any surprise that companies treat employees like toilet paper,
squeeze vendors, lobby hard for tax breaks and to weaken regulations,
and worse, like fudge their financial reports? Jensen himself, in 2005,
repudiated his earlier prescription precisely because it led to fraud.
From
an interview with the New York Times:
Q. So the maximum stock price is the holy grail?
A. Absolutely not. Warren Buffett says he worries as much when
one of his companies becomes overvalued as undervalued. I agree.
Overvalued equity is managerial heroin – it feels really great when
you start out; you’re feted on television; investment bankers vie to
float new issues.
But it doesn’t take long before the elation and ecstasy turn into
enormous pain. The market starts demanding increased earnings and
revenues, and the managers begin to say: “Holy Moley! How are we
going to generate the returns?” They look for legal loopholes in the
accounting, and when those don’t work, even basically honest people
move around the corner to outright fraud.
If they hold a lot of stock or options themselves, it is like
pouring gasoline on a fire. They fudge the numbers and hope they can
sell the stock or exercise the options before anything hits the fan.
Q. Are you suggesting that executives be rewarded for driving
down the price of the stock?
A. I’m saying they should be rewarded for being honest. A C.E.O.
should be able to tell investors, “Listen, this company isn’t worth
its $70 billion market cap; it’s really worth $30 billion, and
here’s why.”
But the board would fire that executive immediately. I guess it
has to be preventative – if executives would present the market with
realistic numbers rather than overoptimistic expectations, the stock
price would stay realistic. But I admit, we scholars don’t yet know
the real answer to how to make this happen.
So having led Corporate America in the wrong direction, Jensen
‘fesses up no one knows the way out. But if executives weren’t
incentivized to take such a topsy-turvey shareholder-driven view of the
world, they’d weigh their obligations to other constituencies, including
the community at large, along with earning shareholders a decent return.
But it’s now become so institutionalized it’s hard to see how to move to
a more sensible regime. For instance, analysts regularly try pressuring
Costco to pay its workers less, wanting fatter margins. But the
comparatively high wages are
an integral part of Costco’s formula: it reduces costly staff
turnover and employee pilferage. And Costco’s upscale members report
they prefer to patronize a store they know treats workers better than
Walmart and other discounters. If managers with an established,
successful formulas still encounter pressure from the Street to strip
mine their companies, imagine how hard it is for struggling companies or
less secure top executives to implement strategies that will take a
while to reap rewards. I’ve been getting reports from McKinsey from the
better part of a decade that they simply can’t get their clients to
implement new initiatives if they’ll dent quarterly returns.
This governance system is actually in crisis, but the extraordinary
profit share that companies have managed to achieve by squeezing workers
and the asset-goosing success of post-crisis financial policies have
produced an illusion of health. But porcine maquillage only improves
appearances; it doesn’t mask the stench of gangrene. Nevertheless,
executives have successfully hidden the generally unhealthy state of
their companies. As long as they have cheerleading analysts, complacent
boards and the Fed protecting their back, they can likely continue to
inflict more damage, using “maximizing shareholder value” canard as the
cover for continuing rent extraction.
Read more at
http://www.nakedcapitalism.com/2013/10/why-the-maximizing-shareholder-value-theory-of-corporate-governance-is-bogus.html#ehj10weqAL2vdXkh.99
So how did this “the last shall come first” thinking become established? You
can blame it all on economists, specifically Harvard Business School’s
Michael Jensen. In other words, this idea did not come out of legal
analysis, changes in regulation, or court decisions. It was simply an
academic theory that went mainstream. And to add insult to injury, the
version of the Jensen formula that became popular was its worst possible
embodiment.
A
terrific 2010 paper by Frank Dobbin and Jiwook Jung,
“The
Misapplication of Mr. Michael Jensen: How Agency Theory Brought Down the
Economy and Might Do It Again,”
explains how this line of thinking went mainstream. I strongly suggest you
read it in full, but I’ll give a brief recap for the time-pressed.
In the 1970s, there was a great deal of hand-wringing in America as Japanese
and German manufacturers were eating American’s lunch. That led to renewed
examination of how US companies were managed, with lots of theorizing about
what went wrong and what the remedies might be. In 1976, Jensen and William
Meckling asserted that the problem was that corporate executives served
their own interests rather than those of shareholders, in other words, that
there was an agency problem. Executives wanted to build empires while
shareholders wanted profits to be maximized.
I
strongly suspect that if Jensen and Meckling had not come out with this line
of thinking, you would have gotten something similar to justify the actions
of the leveraged buyout kings, who were just getting started in the 1970s
and were reshaping the corporate landscape by the mid-1980s. They were doing
many of the things Jensen and Meckling recommended: breaking up
multi-business companies, thinning out corporate centers, and selling
corporate assets (some of which were clearly excess, like corporate art and
jet collection, while other sales were simply to increase leverage, like
selling corporate office buildings and leasing them back). In other words, a
likely reason that Jensen and Meckling’s theory gained traction was it
appeared to validate a fundamental challenge to incumbent managements.
(Dobbin and Jung attribute this trend, as pretty much everyone does, to
Jensen because he continued to develop it. What really put it on the map was
a 1990 Harvard Business Review article,
“It’s
Not What You Pay CEOs, but How,”
that
led to an explosion in the use of option-based pay and resulted in a huge
increase in CEO pay relative to that of average workers.)
To forestall takeovers, many companies implemented the measures an LBO
artist might take before his invading army arrived: sell off non-core
divisions, borrow more, shed staff.
The problem was to the extent that the Jensen/Meckling prescription had
merit, only the parts that helped company executives were adopted. Jensen
didn’t just call on executives to become less ministerial and more
entrepreneurial; they also called for more independent and engaged boards to
oversee and discipline top managers, and more equity-driven pay, both
options and other equity-linked compensation, to make management more
sensitive to both upside and downside risks.
Over the next two decades, companies levered up, became more short-term
oriented, and executive pay levels exploded. As Dobbin and Jung put it, “The
result of the changes promoted by agency theory was that by the late 1990s,
corporate America’s leaders were drag racing without the brakes.”
The paper proceeds to analyze in considerable detail how three of the major
prescriptions of “agency theory” aka “executives and boards should maximize
value,” namely, pay for (mythical) performance, dediversification, and
greater reliance on debt all increased risk. And the authors also detail how
efforts to improve oversight were ineffective.
But the paper also makes clear that this vision of how companies should be
run was simply a new management fashion, as opposed to any sort of legal
requirement:
Organizational institutionalists have long argued that new management
practices diffuse through networks of firms like fads spread through high
schools….In their models, new paradigms are socially constructed as
appropriate solutions to perceived problems or crises….Expert groups that
stand to gain from having their preferred strategies adopted by firms then
enter the void, competing to have their model adopted….
And as Dobbin and Jung point out, the parts of the Jensen formula that got
adopted were the one that had constituents. The ones that promoted looting
and short-termism had obvious followings. The ones for prudent management
didn’t.
And
consider the implications of Jensen’s prescriptions, of pushing companies to
favor shareholders, when they actually stand at the back of the line from a
legal perspective. The result is that various agents (board compensation
consultants, management consultants, and cronyistic boards themselves) have
put incentives in place for CEOs to favor shareholders over parties that
otherwise should get better treatment. So is it any surprise that companies
treat employees like toilet paper, squeeze vendors, lobby hard for tax
breaks and to weaken regulations, and worse, like fudge their financial
reports? Jensen himself, in 2005, repudiated his earlier prescription
precisely because it led to fraud. From
an interview with the New York
Times:
Q. So the maximum stock price is the holy grail?
A. Absolutely not. Warren Buffett says he worries as much when one of his
companies becomes overvalued as undervalued. I agree. Overvalued equity is
managerial heroin – it feels really great when you start out; you’re feted
on television; investment bankers vie to float new issues.
But it doesn’t take long before the elation and ecstasy turn into enormous
pain. The market starts demanding increased earnings and revenues, and the
managers begin to say: “Holy Moley! How are we going to generate the
returns?” They look for legal loopholes in the accounting, and when those
don’t work, even basically honest people move around the corner to outright
fraud.
If they hold a lot of stock or options themselves, it is like pouring
gasoline on a fire. They fudge the numbers and hope they can sell the stock
or exercise the options before anything hits the fan.
Q. Are you suggesting that executives be rewarded for driving down the price
of the stock?
A. I’m saying they should be rewarded for being honest. A C.E.O. should be
able to tell investors, “Listen, this company isn’t worth its $70 billion
market cap; it’s really worth $30 billion, and here’s why.”
But the board would fire that executive immediately. I guess it has to be
preventative – if executives would present the market with realistic numbers
rather than overoptimistic expectations, the stock price would stay
realistic. But I admit, we scholars don’t yet know the real answer to how to
make this happen.
So
having led Corporate America in the wrong direction, Jensen ‘fesses up no
one knows the way out. But if executives weren’t incentivized to take such a
topsy-turvey shareholder-driven view of the world, they’d weigh their
obligations to other constituencies, including the community at large, along
with earning shareholders a decent return. But it’s now become so
institutionalized it’s hard to see how to move to a more sensible regime.
For instance, analysts regularly try pressuring Costco to pay its workers
less, wanting fatter margins. But the
comparatively high wages are an integral part of
Costco’s formula:
it
reduces costly staff turnover and employee pilferage. And Costco’s upscale
members report they prefer to patronize a store they know treats workers
better than Walmart and other discounters. If managers with an established,
successful formulas still encounter pressure from the Street to strip mine
their companies, imagine how hard it is for struggling companies or less
secure top executives to implement strategies that will take a while to reap
rewards. I’ve been getting reports from McKinsey from the better part of a
decade that they simply can’t get their clients to implement new initiatives
if they’ll dent quarterly returns.
This governance system is actually in crisis, but the extraordinary profit
share that companies have managed to achieve by squeezing workers and the
asset-goosing success of post-crisis financial policies have produced an
illusion of health. But porcine maquillage only improves appearances; it
doesn’t mask the stench of gangrene. Nevertheless, executives have
successfully hidden the generally unhealthy state of their companies. As
long as they have cheerleading analysts, complacent boards and the Fed
protecting their back, they can likely continue to inflict more damage,
using “maximizing shareholder value” canard as the cover for continuing rent
extraction.
Read more at
http://www.nakedcapitalism.com/2013/10/why-the-maximizing-shareholder-value-theory-of-corporate-governance-is-bogus.html#ehj10weqAL2vdXkh.99
Jensen Comment
Mike Jensen was the headliner at the 2013 American Accounting Association Annual
Meetings. AAA members can watch various videos by him and about him at the AAA
Commons Website.
Actually Al Rappaport at Northwestern may have been more influential in
spreading the word about creating shareholder value ---
Rappaport, Alfred
(1998).
Creating Shareholder Value: A guide for managers and investors. New
York: The Free Press. pp. 13–29.
It would be interesting if Mike Jensen and/or Al
Rappaport wrote rebuttals to this article.
Bob Jensen's threads on triple-bottom
reporting ---
http://faculty.trinity.edu/rjensen/Theory02.htm#TripleBottom
Bob Jensen's threads on theory are at
http://faculty.trinity.edu/rjensen/Theory01.htm
Purpose of Theory:
Prediction Versus Explanation
Hi Steve and Jagdish,
Buried in the 2011Denver presentation by Greg Waymire is a lament about two of
my hot buttons. Greg mentions the lack of replication (shall we call them
reproductions?) in findings (harvests) published in academic accounting
research journals. Secondly, he mentions the lack of commentary and debate
concerning these these findings. It seems that there's not a whole lot of
interest (debate) about those findings among practitioners or in our academy ---
http://commons.aaahq.org/hives/629d926370/summary
At long last we are making progress in finally getting the attention of the
American Accounting Association leaders regarding how to broaden research
methods and topics of study (beyond financial reporting) in academic accounting
research. The AAA Executive Committee now has annual retreats devoted to this
most serious hole that accountics researchers have dug (Steve calls it a "dig"
in the message from Jagdish) us into over the past four decades.
Change in academic accounting research will come very slowly. Paul Williams
blames the slowness of change on the accountics scientist-conspired monopoly.
I'm less inclined to blame the problem of conspiracy. I think the biggest
problem is that accountics research in capital markets studies is so much easier
since the data is provided like manna from heaven from CRSP, Compustat,
AuditAnalytics, etc. No added scientific effort to collect data is required by
accountics scientists. At CERN, however, physics scientists had to collect
new data to cast doubt on prevailing speed of light theory.
Two years ago, at a meeting, I encountered one of my former students who
eventually entered a leading accounting PhD program and was completing his
dissertation. When I asked him why he was doing a traditional accountics-science
dissertation he admitted that this was much easier than having to collect his
own data.
Now more to the point concerning the messaging of Jagdish and Steve is my
message earlier this week about the physics of economics in general.
Purpose of Theory:
Prediction Versus Explanation
"Milton Friedman's grand illusion," by Mark Buchanan, The Physics
of Finance: A look at economics and finance through the lens of physics,
September 16, 2011 ---
http://physicsoffinance.blogspot.com/2011/09/milton-friedmans-grand-illusion.html
Three years ago I wrote
an Op-Ed for the New York Times on the need for
radical change in the way economists model whole economies. Today's General
Equilibrium models -- and their slightly more sophisticated cousins, Dynamic
Stochastic General Equilibrium models -- make assumptions with no basis in
reality. For example, there is no financial sector in these model economies.
They generally assume that the diversity of behaviour of all an economy's
many firms and consumers can be ignored and simply included as the average
behaviour of a few "representative" agents.
I argued then that it was about time economists started using far more
sophisticated modeling tools, including agent based models, in which the
diversity of interactions among economic agents can be included along with a
financial sector. The idea is to model the simpler behaviours of agents as
well as you can and let the macro-scale complex behaviour of the economy
emerge naturally out of them, without making any restrictive assumptions
about what kinds of things can or cannot happen in the larger economy. This
kind of work is going forward rapidly. For some detail, I recommend
this talk earlier this month by Doyne Farmer.
After that Op-Ed I received quite a number of emails from economists
defending the General Equilibrium approach. Several of them mentioned Milton
Friedman in their defense, saying that he had shown long ago that one
shouldn't worry about the realism of the assumptions in a theory, but only
about the accuracy of its predictions. I eventually found the paper to which
they were referring, a classic in economic history which has exerted a huge
influence over economists over the past half century. I recently re-read the
paper and wanted to make a few comments on Friedman's main argument. It
rests entirely, I think, on a devious or slippery use of words which makes
it possible to give a sensible sounding argument for what is actually a
ridiculous proposition.
The paper is entitled
The Methodology of Positive Economics and was
first published in 1953. It's an interesting paper and enjoyable to read.
Essentially, it seems, Friedman's aim is to argue for scientific standards
for economics akin to those used in physics. He begins by making a clear
definition of what he means by "positive economics," which aims to be free
from any particular ethical position or normative judgments. As he wrote,
positive economics deals with...
"what is," not with "what ought to be." Its task
is to provide a system of generalizations that can be used to make
correct predictions about the consequences of any change in
circumstances. Its performance is to be judged by the precision, scope,
and conformity with experience of the predictions it yields.
Friedman then asks how one should judge the validity
of a hypothesis, and asserts that...
...the only relevant test of the validity of a
hypothesis is comparison of its predictions with experience. The
hypothesis is rejected if its predictions are contradicted ("frequently"
or more often than predictions from an alternative hypothesis); it is
accepted if its predictions are not contradicted; great confidence is
attached to it if it has survived many opportunities for contradiction.
Factual evidence can never "prove" a hypothesis; it can only fail to
disprove it, which is what we generally mean when we say, somewhat
inexactly, that the hypothesis has been "confirmed" by experience."
So far so good. I think most scientists would see the
above as conforming fairly closely to their own conception of how science
should work (and of course this view is closely linked to views made famous
by Karl Popper).
Next step: Friedman goes on to ask how one chooses between several
hypotheses if they are all equally consistent with the available evidence.
Here too his initial observations seem quite sensible:
...there is general agreement that relevant
considerations are suggested by the criteria "simplicity" and
"fruitfulness," themselves notions that defy completely objective
specification. A theory is "simpler" the less the initial knowledge
needed to make a prediction within a given field of phenomena; it is
more "fruitful" the more precise the resulting prediction, the wider the
area within which the theory yields predictions, and the more additional
lines for further research it suggests.
Again, right in tune I think with the practice and
views of most scientists. I especially like the final point that part of the
value of a hypothesis also comes from how well it stimulates creative
thinking about further hypotheses and theories. This point is often
overlooked.
Friedman's essay then shifts direction. He argues that the processes and
practices involved in the initial formation of a hypothesis, and in the
testing of that hypothesis, are not as distinct as people often think,
Indeed, this is obviously so. Many scientists form a hypothesis and try to
test it, then adjust the hypothesis slightly in view of the data. There's an
ongoing evolution of the hypothesis in correspondence with the data and the
kinds of experiments of observations which seem interesting.
To this point, Friedman's essay says nothing that wouldn't fit into any
standard discussion of the generally accepted philosophy of science from the
1950s. But this is where it suddenly veers off wildly and attempts to
support a view that is indeed quite radical. Friedman mentions the
difficulty in the social sciences of getting
new evidence with which to test an hypothesis by looking at its
implications. This difficulty, he suggests,
... makes it tempting to suppose that other, more
readily available, evidence is equally relevant to the validity of the
hypothesis-to suppose that hypotheses have not only "implications" but
also "assumptions" and that the conformity of these "assumptions" to
"reality" is a test of the validity of the hypothesis different from or
additional to the test by implications. This widely held view is
fundamentally wrong and productive of much mischief.
Having raised this idea that assumptions are not part
of what should be tested, Friedman then goes on to attack very strongly the
idea that a theory should strive at all to have realistic assumptions.
Indeed, he suggests, a theory is actually superior insofar as its
assumptions are unrealistic:
In so far as a theory can be said to have
"assumptions" at all, and in so far as their "realism" can be judged
independently of the validity of predictions, the relation between the
significance of a theory and the "realism" of its "assumptions" is
almost the opposite of that suggested by the view under criticism. Truly
important and significant hypotheses will be found to have "assumptions"
that are wildly inaccurate descriptive representations of reality, and,
in general, the more significant the theory, the more unrealistic the
assumptions... The reason is simple. A hypothesis is important if it
"explains" much by little,... To be important, therefore, a hypothesis
must be descriptively false in its assumptions...
This is the statement that the economists who wrote to
me used to defend unrealistic assumptions in General Equilibrium theories.
Their point was that having unrealistic assumptions isn't just not a
problem, but is a positive strength for a theory. The more unrealistic the
better, as Friedman argued (and apparently proved, in the eyes of some
economists).
Now, what is wrong with Friedman's argument, if anything? I think the key
issue is his use of the provocative terms such as "unrealistic" and "false"
and "inaccurate" in places where he actually means "simplified,"
"approximate" or "incomplete." He switches without warning between these
two different meanings in order to make the conclusion seem unavoidable, and
profound, when in fact it is simply not true, or something we already
believe and hardly profound at all.
To see the problem, take a simple example in physics. Newtonian dynamics
describes the motions of the planets quite accurately (in many cases) even
if the planets are treated as point masses having no extension, no rotation,
no oceans and tides, mountains, trees and so on. The great triumph of
Newtonian dynamics (including his law of gravitational attraction) is it's
simplicity -- it asserts that out of all the many details that could
conceivably influence planetary motion, two (mass and distance) matter most
by far. The atmosphere of the planet doesn't matter much, nor does the
amount of sunlight it reflects. The theory of course goes further to
describe how other details do matter if one considers planetary motion in
more detail -- rotation does matter, for example, because it generates tides
which dissipate energy, taking energy slowly away from orbital motion.
But I don't think anyone would be tempted to say that Newtonian dynamics is
a powerful theory because it is descriptively false in its assumptions. It's
assumptions are actually descriptively simple -- that planets and The Sun
have mass, and that a force acts between any two masses in proportion to the
product of their masses and in inverse proportional to the distance between
them. From these assumptions one can work out predictions for details of
planetary motion, and those details turn out to be close to what we see. The
assumptions are simple and plausible, and this is what makes the theory so
powerful when it turns out to make powerful and accurate predictions.
Indeed, if those same predictions came out of a theory with obviously false
assumptions -- all planets are perfect cubes, etc. -- it would be less
powerful by far because it would be less believable. It's ability to make
predictions would be as big a mystery as the original phenomenon of
planetary motion itself -- how can a theory that is so obviously not in tune
with reality still make such accurate predictions?
So whenever Friedman says "descriptively false" I think you can instead
write "descriptively simple", and clarify the meaning by adding a phrase of
the sort "which identify the key factors which matter most." Do that
replacement in Friedman's most provocative phrase from above and you have
something far more sensible:
A hypothesis is important if it "explains" much by
little,... To be important, therefore, a hypothesis must be
descriptively simple in its assumptions. It must identify the key
factors which matter most...
That's not quite so bold, however, and it doesn't create a license for
theorists to make any assumptions they want without being criticized if
those assumptions stray very far from reality.Continued in article
Jensen Comment
Especially note the comments at the end of this article.
My favorite is the following:
Herbert Simon (1963) countered Friedman by stating the
purpose of scientific theories is not to make predictions, but to explain
things - predictions are then tests of whether the explanations are correct.
Both Friedman and Simon's views are better directed
to a field other than economics. The data
at some point will always expose the frailest of assumptions; while the lack
of repeatable results supports futility in the explanation of heterogeneous
agents.
That's perceptive. Scientists should just steer clear of economics. Economics
is so complex it is better suited to astrologists.
"How Non-Scientific Granulation Can
Improve Scientific Accountics"
http://www.cs.trinity.edu/~rjensen/temp/AccounticsGranulationCurrentDraft.pdf
By Bob Jensen
This essay takes off from the following quotation:
A recent accountics science study suggests
that audit firm scandal with respect to someone else's audit may be a reason
for changing auditors.
"Audit Quality and Auditor Reputation: Evidence from Japan," by Douglas J.
Skinner and Suraj Srinivasan, The Accounting Review, September 2012,
Vol. 87, No. 5, pp. 1737-1765.
Our conclusions are subject
to two caveats. First, we find that clients switched away from ChuoAoyama in
large numbers in Spring 2006, just after Japanese regulators announced the
two-month suspension and PwC formed Aarata. While we interpret these events
as being a clear and undeniable signal of audit-quality problems at
ChuoAoyama, we cannot know for sure what drove these switches
(emphasis added).
It is possible that the suspension caused firms to switch auditors for
reasons unrelated to audit quality. Second, our analysis presumes that audit
quality is important to Japanese companies. While we believe this to be the
case, especially over the past two decades as Japanese capital markets have
evolved to be more like their Western counterparts, it is possible
that audit quality is, in general, less important in Japan
(emphasis added) .
Monty Hall Paradox Video ---
http://www.youtube.com/watch?v=mhlc7peGlGg
Monty Hall Paradox Explanation ---
http://en.wikipedia.org/wiki/Monte_Hall_paradox
Jensen Comment
Of course the paradox in real life decision making, that takes it out of the
real of the Monty Hall solutions and game theory in general, is that in the real
world the probabilities of finding what's behind closed doors are unknown.
An alternate solution when probabilities are unknown for paths leading to
closed doors is the Robert Frost solution to choose the door least opened.---
http://faculty.trinity.edu/rjensen/tidbits/2007/tidbits070905.htm
What the Monty Hall Paradox teaches us, at least symbolically, is that
sometimes the most obvious common sense solutions to problems are not
necessarily optimal. The geniuses in life discover better solutions that most of
would consider absurd at the time --- such as that time is relative and not
absolute ---
http://en.wikipedia.org/wiki/Theory_of_relativity
Richard Sansing forwarded the link
http://en.wikipedia.org/wiki/Principle_of_restricted_choice_(bridge)
Thank You Dana Hermanson
I think Dana Hermanson should be applauded for adding diversity to research
methods during his service as Senior Editor of Accounting Horizons.
Before Dana took over Accounting Horizons (AH) had succumbed to being a
clone of The Accounting Review (TAR) in a manner totally inconsistent
with its original charter.
There's nothing wrong with equations per se, and they serve a vital
function in research.
But must having them be a necessary condition?
How long has it been since a mainline TAR paper was published without
equations?
How long will it take for a mainline TAR paper to be published that does
not have equations?
Fortunately, thanks to Dana, some papers can be once again published in AH
that are not replete with equations.
Steve Zeff had
the guts to admit the divergence of Accounting Horizons from its original
charter in his excellent presentation in San Francisco on August 4, 2010
following a plenary session at the AAA Annual Meetings.
Steve compared
the missions of the Accounting Horizons with performances since AH
was inaugurated. Bob Mautz faced the daunting tasks of being the first Senior
Editor of AH and of setting the missions of that journal for the future
in the spirit dictated by the AAA Executive Committee at the time and of Jerry
Searfoss (Deloitte) and others providing seed funding for starting up AH.
Steve Zeff first put up a list of
the AH missions as laid out by Bob Mautz in the first issues of AH:
Mautz, R. K. 1987. Editorial.
Accounting Horizons (September): 109-111.
Mautz, R. K. 1987. Editorial:
Expectations: Reasonable or ridiculous? Accounting Horizons
(December): 117-120.
Steve Zeff then
discussed the early successes of AH in meeting these missions followed by
mostly years of failure in terms of meeting the original missions laid out by
Bob Mautz ---
http://fisher.osu.edu/departments/accounting-and-mis/the-accounting-hall-of-fame/membership-in-hall/robert-kuhn-mautz/
Steve's PowerPoint slides are at
http://www.cs.trinity.edu/~rjensen/temp/ZeffCommentOnAccountingHorizons.ppt
Steve’s
conclusion was that AH became more like TAR rather than the
practitioner-academy marriage journal that was originally intended. And yes,
Steve did analyze the AH Commentaries as well as the mainline articles in
reaching this conclusion.
In my viewpoint, Steve's 2010 worry about Accounting Horizons was
largely remedied by Dana Hermanson.
Firstly Dana promoted normative commentaries that, in my opinion, would never
have been accepted for publication in The Accounting Review. Examples are
provided at
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm#Essays
Secondly I will point to a recent Accounting Horizons paper (see
below) that, in my opinion, would have zero chance of being published in The
Accounting Review. This is because it uses normative research methodology
that is not acceptable to the TAR Team unless this normative logic is dressed up
as an analytical research paper complete with equations and proofs. For an
example of one such normative paper all dressed up with equations and proofs,
see the Laux and Newman paper discussed at
http://faculty.trinity.edu/rjensen/TheoryTAR.htm#Analytics
An Example of an Excellent Normative-Method Research Paper That's Not
Dressed Up in Equations and Proofs
The excellent paper that would have to be dressed up with equations and proofs
for publication in TAR is the following paper accepted by Dana Hermanson for
Accounting Horizons. I should note that what makes analytical papers
generally normative is that they are usually built upon hypothetical, untested,
and often unrealistic assumptions that serve as starting points in the analysis.
The analytical conclusions, like normative conclusions in general, all hinge on
the starting point assumptions, axioms, and postulates. For example it is
extremely common to assume equilibrium conditions that really do not exist in
the real world. And analytical researchers assume such things as utility
functions that are assumed from thin air. Analytical conclusions as well as
normative conclusions in general can be of great interest and relevance in spite
of limitations of assumptions. Robustness, however, depends upon the sensitivity
of those conclusions to the underlying assumptions. This also applies to the
paper below.
"Should Repurchase Transactions be Accounted for as Sales or Loans?"
by Justin Chircop , Paraskevi Vicky Kiosse , and Ken Peasnell,
Accounting Horizons, December 2012, Vol. 26, No. 4, pp. 657-679.
http://aaajournals.org/doi/full/10.2308/acch-50176
In this paper, we discuss the accounting for
repurchase transactions, drawing on how repurchase agreements are
characterized under U.S. bankruptcy law, and in light of the recent
developments in the U.S. repo market. We conclude that the current
accounting rules, which require the recording of most such transactions as
collateralized loans, can give rise to opaqueness in a firm's financial
statements because they incorrectly characterize the economic substance of
repurchase agreements. Accounting for repurchase transactions as sales and
the concurrent recognition of a forward, as “Repo 105” transactions were
accounted for by Lehman Brothers, has furthermore overlooked merits. In
particular, such a method provides a more comprehensive and transparent
picture of the economic substance of such transactions.
. . .
CONCLUSION
This paper suggests that the current method of
accounting for repos is deficient in the sense of ignoring key aspects of
the economics of such transactions. Moreover, as shown in the case of Lehman
Brothers, under current regulations it may be relatively easy for a firm to
design a repo in such a way to accomplish a preferred accounting treatment.
For example, a firm wishing to account for a
repo as a sale may easily design a bilateral repo with the option not to
repurchase the assets should a particular highly unlikely event occur.
Such an option would make the repo eligible for sale accounting under
SFAS140. In this regard, a standard uniform method of accounting for all
repos would reduce the risk of such accounting arbitrage.
Various factors not considered in this paper have
probably played a part in the current position adopted by the standard
setters regarding repos, including the drive for convergence in accounting
standards and the fact that participants in the repo market may be
“unaccustomed to treating [repurchase] transactions as sales, and a change
to sale treatment would have a substantial impact on their reported
financial position” (FASB 2000). It would be a pity if the concerns
associated with the circumstances surrounding Lehman's use of Repo 105
prevented proper consideration being given to the possibility of treating
all repos in the same manner, one that will reflect the key economic and
legal features of repurchase agreements. As lawyers say, hard cases make bad
law. But in this case, the Lehman's accounting for its Repo 105 transactions
does substantially reflect the economics and legal considerations involved,
that is, a sale of an asset with an associated obligation to return a
substantially similar asset at the end of the agreement. An alternative
approach would be to stick with the current measurement rules but provide
additional disclosures. We have offered some tentative suggestions as to
what kinds of additional disclosures are needed.
Jensen Comment
Thank you Dana Hermanson for resetting Accounting Horizons on a course
consistent with its original charges. We can only hope the new AH editors
Paul Griffin and Arnold Wright will carry on with this change of course that's
consistent with the resolutions of the Pathways Commission Report ---
http://commons.aaahq.org/files/0b14318188/Pathways_Commission_Final_Report_Complete.pdf
By the way the above AH paper changed my thinking about repo
accounting where, until now, I've been entirely negative about recording Repo
105/109 transactions as sales ---
http://faculty.trinity.edu/rjensen/ecommerce/eitf01.htm#Repo
January 24, 2013 reply from Dana Hernonson
Bob,
I hope all is well. A colleague forwarded the
material below to me.
I greatly appreciate the kind words. I should point
out, though, that my co-editor, Terry Shevlin, deserves a great deal of the
credit. Terry handled all of the papers on the financial side of the house
at Horizons, and he was extremely open to a variety of contributions. I
believe that Terry fully embraced the mission of Horizons.
Thanks again, and please feel free to share this
email with others.
Dana
Dana Hermanson
Sent from my iPhone
Increasing Complexity of the World and Its Mathematical Models
Growing Knowledge: The Evolution of Research ---
http://www.growingknowledge.bl.uk/
Note the link to "New Ways of doing research"
Accountics Worshippers Please Take Note
"A Nobel Lesson: Economics is Getting Messier," by Justin Fox, Harvard
Business Review Blog, October 11, 2010 ---
Click Here
http://blogs.hbr.org/fox/2010/10/nobel-lesson-economics-messier.html?referral=00563&cm_mmc=email-_-newsletter-_-daily_alert-_-alert_date&utm_source=newsletter_daily_alert&utm_medium=email&utm_campaign=alert_date
When Peter Diamond was a graduate student at MIT in
the early 1960s, he spent much of his time studying the elegant new models
of perfectly functioning markets that were all the rage in those days. Most
important of all was the
general equilibrium model assembled in the 1950s
by Kenneth Arrow and Gerard Debreu, often referred to as the mathematical
proof of the existence of Adam Smith's "invisible hand." Working through the
Arrow-Debreu proofs was a major part of the MIT grad student experience. At
least, that's what Diamond told me a few years ago. (If I ever find the
notes of that conversation, I'll offer up some quotes.)
Diamond certainly learned well. In a long career
spent almost entirely at MIT, he became known for
work of staggering theoretical sophistication. As
economist Steven Levitt put it today:
He wrote the kind of papers that I would have to
read four or five times to get a handle on what he was doing, and even then,
I couldn't understand it all.
But Diamond wasn't out to further prove the
perfection of markets. He was trying instead to show how, with the injection
of the tiniest bit of reality, the perfect-market models he'd learned so
well in grad school began to break down. Today he won a third of the
Sveriges Riksbank Prize in Economic Sciences in Memory
of Alfred Nobel (it's not technically a "Nobel
Prize"), mainly for a paper he wrote in 1971 that explored how the injection
of friction between buyers and sellers, in the form of what he called
"search costs," prices would end up at a level far removed from what a
perfect competition model would predict. The two economists who shared the
prize with him, Dale Mortensen of Northwestern University and Christopher
Pissarides of the London School of Economics, later elaborated on this
insight with regard to job markets (as did Diamond).
The exact practical implications of this work can be a little hard to
define — although Catherine Rampell makes a
valiant and mostly successful effort in The New
York Times. What this year's prize does clearly indicate is that the Nobel
committee believes economic theory is messy and getting messier (no, I
didn't come up with this insight on my own; my colleague Tim Sullivan had to
nudge me). The last Nobel awarded for an all-encompassing mathematical
theory of how the economic world fits together was to
Robert Lucas in 1995 for his work on rational
expectations. Since then (with the arguable exceptions of the prizes awarded
to
Robert Merton and Myron Scholes in 1997 for options-pricing
and to Fynn Kydland and Edward Prescott in 2004 for
real-business-cycle theory) the Nobel crew has chosen to honor either
interesting economic side projects or work that muddies the elegance of
those grand postwar theories of rational actors buying and selling under
conditions of perfect competition.
The 2001 prize for work exploring the impact on
markets of asymmetric information, awarded to George Akerlof, Michael Spence
and Joseph Stiglitz, was probably most similar to this year's model (and,
not coincidentally, Akerlof and Stiglitz were also MIT grad students in the
1960s).
The implications of messier economics are
interesting to contemplate. The core insight of mainstream economics — that
incentives matter — continues to hold up well. And on the whole, markets
appear to do a better job of channeling those incentives to useful ends than
any other form of economic organization. But beyond that, the answers one
can derive from economic theory — especially answers that address the
functioning of the entire economy — are complicated and often contradictory.
Meaning that sometimes we non-economists are just going to have to figure
things out for ourselves.
Jensen Comment
Not mentioned but certainly implied is the increased complexity of replicating
and validating empirical models in terms of assumptions, missing variables, and
data error. Increasing complexity will affect accountics researchers less since
replicating and validating is of less concern among accountics researchers ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
"Is Modern Portfolio Theory Dead? Come On," by Paul Pfleiderer,
TechCrunch, August 11, 2012 ---
http://techcrunch.com/2012/08/11/is-modern-portfolio-theory-dead-come-on/
A few weeks ago, TechCrunch published a piece
arguing software is better at investing than 99% of human investment
advisors. That post, titled
Thankfully, Software Is Eating The Personal Investing World,
pointed out the advantages of engineering-driven
software solutions versus emotionally driven human judgment. Perhaps not
surprisingly, some commenters (including some financial advisors) seized the
moment to call into question one of the foundations of software-based
investing, Modern Portfolio Theory.
Given the doubts raised by a small but vocal
chorus, it’s worth spending some time to ask if we need a new investing
paradigm and if so, what it should be. Answering that question helps show
why MPT still is the best investment methodology out there; it enables the
automated, low-cost investment management offered by a new wave of Internet
startups including
Wealthfront
(which I advise),
Personal Capital,
Future Advisor
and SigFig.
The basic questions being raised about MPT run
something like this:
- Hasn’t recent experience – i.e., the financial
crisis — shown that diversification doesn’t work?
- Shouldn’t we primarily worry about “Black
Swan” events and unforeseen risk?
- Don’t these unknown unknowns mean we must
develop a new approach to investing?
Let’s begin by briefly laying out the key insights
of MPT.
MPT is based in part on the assumption that most
investors don’t like risk and need to be compensated for bearing it. That
compensation comes in the form of higher average returns. Historical data
strongly supports this assumption. For example, from 1926 to 2011 the
average (geometric) return on U.S. Treasury Bills was 3.6%. Over the same
period the average return on large company stocks was 9.8%; that on small
company stocks was 11.2% ( See 2012 Ibbotson Stocks, Bonds, Bills and
Inflation (SBBI) Valuation Yearbook, Morningstar, Inc., page 23. ). Stocks,
of course, are much riskier than Treasuries, so we expect them to have
higher average returns — and they do.
One of MPT’s key insights is that while investors
need to be compensated to bear risk, not all risks are rewarded. The market
does not reward risks that can be “diversified away” by holding a bundle of
investments, instead of a single investment. By recognizing that not all
risks are rewarded, MPT helped establish the idea that a diversified
portfolio can help investors earn a higher return for the same amount of
risk.
To understand which risks can be diversified away,
and why, consider Zynga. Zynga hit $14.69 in March and has since dropped to
less than $2 per share. Based on what’s happened over the past few months,
the major risks associated with Zynga’s stock are things such as delays in
new game development, the fickle taste of consumers and changes on Facebook
that affect users’ engagement with Zynga’s games.
For company insiders, who have much of their wealth
tied up in the company, Zynga is clearly a risky investment. Although those
insiders are exposed to huge risks, they aren’t the investors who determine
the “risk premium” for Zynga. (A stock’s risk premium is the extra return
the stock is expected to earn that compensates for the stock’s risk.)
Rather, institutional funds and other large
investors establish the risk premium by deciding what price they’re willing
to pay to hold Zynga in their diversified portfolios. If a Zynga game is
delayed, and Zynga’s stock price drops, that decline has a miniscule effect
on a diversified shareholder’s portfolio returns. Because of this, the
market does not price in that particular risk. Even the overall turbulence
in many Internet stocks won’t be problematic for investors who are well
diversified in their portfolios.
Modern Portfolio Theory focuses on constructing
portfolios that avoid exposing the investor to those kinds of unrewarded
risks. The main lesson is that investors should choose portfolios that lie
on the Efficient Frontier, the mathematically defined curve that describes
the relationship between risk and reward. To be on the frontier, a portfolio
must provide the highest expected return (largest reward) among all
portfolios having the same level of risk. The Internet startups construct
well-diversified portfolios designed to be efficient with the right
combination of risk and return for their clients.
Now let’s ask if anything in the past five years
casts doubt on these basic tenets of Modern Portfolio Theory. The answer is
clearly, “No.” First and foremost, nothing has changed the fact that there
are many unrewarded risks, and that investors should avoid these risks. The
major risks of Zynga stock remain diversifiable risks, and unless you’re
willing to trade illegally on inside information about, say, upcoming
changes to Facebook’s gaming policies, you should avoid holding a
concentrated position in Zynga.
The efficient frontier is still the desirable place
to be, and it makes no sense to follow a policy that puts you in a position
well below that frontier.
Most of the people who say that “diversification
failed” in the financial crisis have in mind not the diversification gains
associated with avoiding concentrated investments in companies like Zynga,
but the diversification gains that come from investing across many different
asset classes, such as domestic stocks, foreign stocks, real estate and
bonds. Those critics aren’t challenging the idea of diversification in
general – probably because such an effort would be nonsensical.
True, diversification across asset classes didn’t
shelter investors from 2008’s turmoil. In that year, the S&P 500 index fell
37%, the MSCI EAFE index (the index of developed markets outside North
America) fell by 43%, the MSCI Emerging Market index fell by 53%, the Dow
Jones Commodities Index fell by 35%, and the Lehman High Yield Bond Index
fell by 26%. The historical record shows that in times of economic distress,
asset class returns tend to move in the same direction and be more highly
correlated. These increased correlations are no doubt due to the increased
importance of macro factors driving corporate cash flows. The increased
correlations limit, but do not eliminate, diversification’s value. It would
be foolish to conclude from this that you should be undiversified. If a seat
belt doesn’t provide perfect protection, it still makes sense to wear one.
Statistics show it’s better to wear a seatbelt than to not wear one.
Similarly, statistics show diversification reduces risk, and that you are
better off diversifying than not.
Timing the market
The obvious question to ask anyone who insists
diversification across asset classes is not effective is: What is the
alternative? Some say “Time the market.” Make sure you hold an asset class
when it is earning good returns, but sell as soon as things are about to go
south. Even better, take short positions when the outlook is negative. With
a trustworthy crystal ball, this is a winning strategy. The potential gains
are huge. If you had perfect foresight and could time the S&P 500
on a daily basis, you could have turned $1,000 on Jan. 1, 2000, into
$120,975,000 on Dec. 31, 2009, just by going in and out of the market. If
you could also short the market when appropriate, the gains would have been
even more spectacular!
Sometimes, it seems someone may have a fairly
reliable crystal ball. Consider John Paulson, who in 2007 and 2008 seemed so
prescient in profiting from the subprime market’s collapse. It appears,
however, that Mr. Paulson’s crystal ball became less reliable after his
stunning success in 2007. His Advantage Plus fund experienced more than a
50% loss in 2011. Separating luck from skill is often difficult.
Some people try to come up with a way to time the
market based on historical data. In fact a large number of strategies will
work well “in the back test.” The question is whether any system is reliable
enough to use for future investing.
There are at least three reasons to be cautious
about substituting a timing system for diversification.
- First, a timing system that does not work can
impose significant transaction costs (including avoidable adverse tax
consequences) on the investor for no gain.
- Second, an ill-founded timing strategy
generally exposes the investor to risk that is unrewarded. In other
words, it puts the investor below the frontier, which is not a good
place to be.
- Third, a timing system’s success may create
the seeds of its own destruction. If too many investors blindly follow
the strategy, prices will be driven to erase any putative gains that
might have been there, turning the strategy into a losing proposition.
Also, a timing strategy designed to “beat the market” must involve
trading into “good” positions and away from “bad” ones. That means there
must be a sucker (or several suckers) available to take on the other
(losing) sides. (No doubt in most cases each party to the trade thinks
the sucker is on the other side.)
Black Swans
What about those Black Swans? Doesn’t MPT ignore
the possibility that we can be surprised by the unexpected? Isn’t it
impossible to measure risk when there are unknown unknowns?
Most people recognize that financial markets are
not like simple games of chance where risk can be quantified precisely. As
we’ve seen (e.g., the “Black Monday” stock market crash of 1987 and the
“flash crash” of 2010), the markets can produce extreme events that hardly
anyone contemplated as a possibility. As opposed to poker, where we always
draw from the same 52-card deck, in financial markets, asset returns are
drawn from changing distributions as the world economy and financial
relationships change.
Some Black Swan events turned out to have limited
effects on investors over the long term. Although the market dropped
precipitously in October 1987, it was close to fully recovered in June 1988.
The flash crash was confined to a single day.
This is not to say that all “surprise” events are transitory. The Great
Depression followed the stock market crash of 1929, and the effects of the
financial crisis in 2007 and 2008 linger on five years later.
The question is, how should we respond to
uncertainties and Black Swans? One sensible way is to be more diligent in
quantifying the risks we can see. For example, since extreme events don’t
happen often, we’re likely to be misled if we base our risk assessment on
what has occurred over short time periods. We shouldn’t conclude that just
because housing prices haven’t gone down over 20 years that a housing
decline is not a meaningful risk. In the case of natural disasters like
earthquakes, tsunamis, asteroid strikes and solar storms, the long run could
be very long indeed. While we can’t capture all risks by looking far back in
time, taking into account long-term data means we’re less likely to be
surprised.
Some people suggest you should respond to the risk
of unknown unknowns by investing very conservatively. This means allocating
most of the portfolio to “safe assets” and significantly reducing exposure
to risky assets, which are likely to be affected by Black Swan surprises.
This response is consistent with MPT. If you worry about Black Swans, you
are, for all intents and purposes, a very risk-averse investor. The MPT
portfolio position for very risk-averse investors is a position on the
efficient frontier that has little risk.
The cost of investing in a low-risk position is a
lower expected return (recall that historically the average return on stocks
was about three times that on U.S. Treasuries), but maybe you think that’s a
price worth paying. Can everyone take extremely conservative positions to
avoid Black Swan risk? This clearly won’t work, because some investors must
hold risky assets. If all investors try to avoid Black Swan events, the
prices of those risky assets will fall to a point where the forecasted
returns become too large to ignore.
Continued in article
Jensen Comment
All quant theories and strategies in finance are based upon some foundational
assumptions that in rare instances turn into the
Achilles'
heel of the entire superstructure. The classic example is the wonderful
theory and arbitrage strategy of Long Term Capital Management (LTCM) formed by
the best quants in finance (two with Nobel Prizes in economics). After
remarkable successes one nickel at a time in a secret global arbitrage strategy
based heavily on the Black-Scholes Model, LTCM placed a trillion dollar bet that
failed dramatically and became the only hedge fund that nearly imploded all of
Wall Street. At a heavy cost, Wall Street investment bankers pooled billions of
dollars to quietly shut down LTCM ---
http://faculty.trinity.edu/rjensen/FraudRotten.htm#LTCM
So what was the Achilles heal of the arbitrage strategy of LTCM? It was an
assumption that a huge portion of the global financial market would not collapse
all at once. Low and behold, the Asian financial markets collapsed all at once
and left LTCM naked and dangling from a speculative cliff.
There is a tremendous (one of the best
videos I've ever seen on the Black-Scholes Model) PBS Nova video called
"Trillion Dollar Bet" explaining why LTCM
collapsed. Go to
http://www.pbs.org/wgbh/nova/stockmarket/
This video is in the media libraries on most college campuses. I highly
recommend showing this video to students. It is extremely well done and
exciting to watch.
One of the more interesting summaries is the Report of The President’s
Working Group on Financial Markets, April 1999 ---
http://www.ustreas.gov/press/releases/reports/hedgfund.pdf
The principal
policy issue arising out of the events surrounding the near collapse of LTCM
is how to constrain excessive leverage. By increasing the chance that
problems at one financial institution could be transmitted to other
institutions, excessive leverage can increase the likelihood of a general
breakdown in the functioning of financial markets. This issue is not limited
to hedge funds; other financial institutions are often larger and more
highly leveraged than most hedge funds.
What went wrong at Long Term Capital
Management? ---
http://www.killer-essays.com/Economics/euz220.shtml
The video and above reports, however, do not delve into the tax shelter
pushed by Myron Scholes and his other LTCM partners. A nice summary of the tax
shelter case with links to other documents can be found at
http://www.cambridgefinance.com/CFP-LTCM.pdf
The above August 27,
2004 ruling by Judge Janet Bond Arterton rounds out the "Trillion Dollar Bet."
The classic and enormous scandal was
Long Term Capital led by Nobel Prize winning Merton and Scholes (actually the
blame is shared with their devoted doctoral students). There is a tremendous
(one of the best videos I've ever seen on the Black-Scholes Model) PBS Nova
video ("Trillion Dollar Bet") explaining why LTC collapsed. Go to
http://www.pbs.org/wgbh/nova/stockmarket/
Another illustration of the Achilles' heel of a popular mathematical theory
and strategy is the 2008 collapse mortgage-backed CDO financial risk bonds based
upon David Li's Gaussian copula function of risk diversification in portfolios.
The Achilles' heel was the assumption that the real estate bubble would not
burst to a point where millions of subprime mortgages would all go into default
at roughly the same time.
Can the 2008 investment banking failure be traced to a math error?
Recipe for Disaster: The Formula That Killed Wall Street ---
http://www.wired.com/techbiz/it/magazine/17-03/wp_quant?currentPage=all
Link forwarded by Jim Mahar ---
http://financeprofessorblog.blogspot.com/2009/03/recipe-for-disaster-formula-that-killed.html
Some highlights:
"For five years, Li's formula, known as a
Gaussian copula function, looked like an unambiguously positive
breakthrough, a piece of financial technology that allowed hugely
complex risks to be modeled with more ease and accuracy than ever
before. With his brilliant spark of mathematical legerdemain, Li made it
possible for traders to sell vast quantities of new securities,
expanding financial markets to unimaginable levels.
His method was adopted by everybody from bond
investors and Wall Street banks to ratings agencies and regulators. And
it became so deeply entrenched—and was making people so much money—that
warnings about its limitations were largely ignored.
Then the model fell apart." The article goes on to show that correlations
are at the heart of the problem.
"The reason that ratings agencies and investors
felt so safe with the triple-A tranches was that they believed there was
no way hundreds of homeowners would all default on their loans at the
same time. One person might lose his job, another might fall ill. But
those are individual calamities that don't affect the mortgage pool much
as a whole: Everybody else is still making their payments on time.
But not all calamities are individual, and
tranching still hadn't solved all the problems of mortgage-pool risk.
Some things, like falling house prices, affect a large number of people
at once. If home values in your neighborhood decline and you lose some
of your equity, there's a good chance your neighbors will lose theirs as
well. If, as a result, you default on your mortgage, there's a higher
probability they will default, too. That's called correlation—the degree
to which one variable moves in line with another—and measuring it is an
important part of determining how risky mortgage bonds are."
I would highly recommend reading the entire thing that gets much more
involved with the
actual formula etc.
The
“math error” might truly be have been an error or it might have simply been a
gamble with what was perceived as miniscule odds of total market failure.
Something similar happened in the case of the trillion-dollar disastrous 1993
collapse of Long Term Capital Management formed by Nobel Prize winning
economists and their doctoral students who took similar gambles that ignored the
“miniscule odds” of world market collapse -- -
http://faculty.trinity.edu/rjensen/FraudRotten.htm#LTCM
The rhetorical question is whether the failure is ignorance in model building or
risk taking using the model?
"In Plato's Cave:
Mathematical models are a powerful way of predicting financial markets. But they
are fallible" The Economist, January 24, 2009, pp. 10-14 ---
http://www.economist.com/specialreports/displaystory.cfm?story_id=12957753
ROBERT RUBIN was Bill Clinton’s treasury
secretary. He has worked at the top of Goldman Sachs and Citigroup. But he
made arguably the single most influential decision of his long career in
1983, when as head of risk arbitrage at Goldman he went to the MIT Sloan
School of Management in Cambridge, Massachusetts, to hire an economist
called Fischer Black.
A decade earlier Myron Scholes, Robert
Merton and Black had explained how to use share prices to calculate the
value of derivatives. The Black-Scholes options-pricing model was more than
a piece of geeky mathematics. It was a manifesto, part of a revolution that
put an end to the anti-intellectualism of American finance and transformed
financial markets from bull rings into today’s quantitative powerhouses.
Yet, in a roundabout way, Black’s approach also led to some of the late
boom’s most disastrous lapses.
Derivatives markets are not new, nor are
they an exclusively Western phenomenon. Mr Merton has described how Osaka’s
Dojima rice market offered forward contracts in the 17th century and
organised futures trading by the 18th century. However, the growth of
derivatives in the 36 years since Black’s formula was published has taken
them from the periphery of financial services to the core.
In “The Partnership”, a history of Goldman
Sachs, Charles Ellis records how the derivatives markets took off. The
International Monetary Market opened in 1972; Congress allowed trade in
commodity options in 1976; S&P 500 futures launched in 1982, and options on
those futures a year later. The Chicago Board Options Exchange traded 911
contracts on April 26th 1973, its first day (and only one month before
Black-Scholes appeared in print). In 2007 the CBOE’s volume of contracts
reached almost 1 trillion.
Trading has exploded partly because
derivatives are useful. After America came off the gold standard in 1971,
businesses wanted a way of protecting themselves against the movements in
exchange rates, just as they sought protection against swings in interest
rates after Paul Volcker, Mr Greenspan’s predecessor as chairman of the Fed,
tackled inflation in the 1980s. Equity options enabled investors to lay off
general risk so that they could concentrate on the specific types of
corporate risk they wanted to trade.
The other force behind the explosion in
derivatives trading was the combination of mathematics and computing. Before
Black-Scholes, option prices had been little more than educated guesses. The
new model showed how to work out an option price from the known price-behaviour
of a share and a bond. It is as if you had a formula for working out the
price of a fruit salad from the prices of the apples and oranges that went
into it, explains Emanuel Derman, a physicist who later took Black’s job at
Goldman. Confidence in pricing gave buyers and sellers the courage to pile
into derivatives. The better that real prices correlate with the unknown
option price, the more confidently you can take on any level of risk. “In a
thirsty world filled with hydrogen and oxygen,” Mr Derman has written,
“someone had finally worked out how to synthesise H2O.”
Poetry in Brownian motion Black-Scholes is
just a model, not a complete description of the world. Every model makes
simplifications, but some of the simplifications in Black-Scholes looked as
if they would matter. For instance, the maths it uses to describe how share
prices move comes from the equations in physics that describe the diffusion
of heat. The idea is that share prices follow some gentle random walk away
from an equilibrium, rather like motes of dust jiggling around in Brownian
motion. In fact, share-price movements are more violent than that.
Over the years the “quants” have found
ways to cope with this—better ways to deal with, as it were, quirks in the
prices of fruit and fruit salad. For a start, you can concentrate on the
short-run volatility of prices, which in some ways tends to behave more like
the Brownian motion that Black imagined. The quants can introduce sudden
jumps or tweak their models to match actual share-price movements more
closely. Mr Derman, who is now a professor at New York’s Columbia University
and a partner at Prisma Capital Partners, a fund of hedge funds, did some of
his best-known work modelling what is called the “volatility smile”—an
anomaly in options markets that first appeared after the 1987 stockmarket
crash when investors would pay extra for protection against another imminent
fall in share prices.
The fixes can make models complex and
unwieldy, confusing traders or deterring them from taking up new ideas.
There is a constant danger that behaviour in the market changes, as it did
after the 1987 crash, or that liquidity suddenly dries up, as it has done in
this crisis. But the quants are usually pragmatic enough to cope. They are
not seeking truth or elegance, just a way of capturing the behaviour of a
market and of linking an unobservable or illiquid price to prices in traded
markets. The limit to the quants’ tinkering has been not mathematics but the
speed, power and cost of computers. Nobody has any use for a model which
takes so long to compute that the markets leave it behind.
The idea behind quantitative finance is to
manage risk. You make money by taking known risks and hedging the rest. And
in this crash foreign-exchange, interest-rate and equity derivatives models
have so far behaved roughly as they should.
A muddle of mortgages Yet the idea behind
modelling got garbled when pools of mortgages were bundled up into
collateralised-debt obligations (CDOs). The principle is simple enough.
Imagine a waterfall of mortgage payments: the AAA investors at the top catch
their share, the next in line take their share from what remains, and so on.
At the bottom are the “equity investors” who get nothing if people default
on their mortgage payments and the money runs out.
Despite the theory, CDOs were hopeless, at
least with hindsight (doesn’t that phrase come easily?). The cash flowing
from mortgage payments into a single CDO had to filter up through several
layers. Assets were bundled into a pool, securitised, stuffed into a CDO,
bits of that plugged into the next CDO and so on and on. Each source of a
CDO had interminable pages of its own documentation and conditions, and a
typical CDO might receive income from several hundred sources. It was a
lawyer’s paradise.
This baffling complexity could hardly be
more different from an equity or an interest rate. It made CDOs impossible
to model in anything but the most rudimentary way—all the more so because
each one contained a unique combination of underlying assets. Each CDO would
be sold on the basis of its own scenario, using central assumptions about
the future of interest rates and defaults to “demonstrate” the payouts over,
say, the next 30 years. This central scenario would then be “stress-tested”
to show that the CDO was robust—though oddly the tests did not include a 20%
fall in house prices.
This was modelling at its most feeble.
Derivatives model an unknown price from today’s known market prices. By
contrast, modelling from history is dangerous. There was no guarantee that
the future would be like the past, if only because the American housing
market had never before been buoyed up by a frenzy of CDOs. In any case,
there are not enough past housing data to form a rich statistical picture of
the market—especially if you decide not to include the 1930s nationwide fall
in house prices in your sample.
Neither could the models take account of
falling mortgage-underwriting standards. Mr Rajan of the University of
Chicago says academic research suggests mortgage originators, keen to
automate their procedures, stopped giving potential borrowers lengthy
interviews because they could not easily quantify the firmness of someone’s
handshake or the fixity of their gaze. Such things turned out to be better
predictors of default than credit scores or loan-to-value ratios, but the
investors at the end of a long chain of securities could not monitor lending
decisions.
The issuers of CDOs asked rating agencies
to assess their quality. Although the agencies insist that they did a
thorough job, a senior quant at a large bank says that the agencies’ models
were even less sophisticated than the issuers’. For instance, a BBB tranche
in a CDO might pay out in full if the defaults remained below 6%, and not at
all once they went above 6.5%. That is an all-or-nothing sort of return,
quite different from a BBB corporate bond, say. And yet, because both shared
the same BBB rating, they would be modelled in the same way.
Issuers like to have an edge over the
rating agencies. By paying one for rating the CDOs, some may have laid
themselves open to a conflict of interest. With help from companies like
Codefarm, an outfit from Brighton in Britain that knew the agencies’ models
for corporate CDOs, issuers could build securities with any risk profile
they chose, including those made up from lower-quality ingredients that
would nevertheless win AAA ratings. Codefarm has recently applied for
administration.
There is a saying on Wall Street that the
test of a product is whether clients will buy it. Would they have bought
into CDOs had it not been for the dazzling performance of the quants in
foreign-exchange, interest-rate and equity derivatives? There is every sign
that the issuing banks believed their own sales patter. The banks so liked
CDOs that they held on to a lot of their own issues, even when the idea
behind the business had been to sell them on. They also lent buyers much of
the money to bid for CDOs, certain that the securities were a sound
investment. With CDOs in deep trouble, the lenders are now suffering.
Modern finance is supposed to be all about
measuring risks, yet corporate and mortgage-backed CDOs were a leap in the
dark. According to Mr Derman, with Black-Scholes “you know what you are
assuming when you use the model, and you know exactly what has been swept
out of view, and hence you can think clearly about what you may have
overlooked.” By contrast, with CDOs “you don’t quite know what you are
ignoring, so you don’t know how to adjust for its inadequacies.”
Now that the world has moved far beyond
any of the scenarios that the CDO issuers modelled, investors’ quantitative
grasp of the payouts has fizzled into blank uncertainty. That makes it hard
to put any value on them, driving away possible buyers. The trillion-dollar
bet on mortgages has gone disastrously wrong. The hope is that the
trillion-dollar bet on companies does not end up that way too.
Continued in article
Closing Jensen Comment
So is portfolio diversification theory dead? I hardly think so. But if any
lesson is to be learned is that we should question those critical underlying
assumptions in Plato's Cave before worldwide strategies are implemented that
overlook the Achilles' heel of those critical underlying assumptions.
Ockham’s (or Occam's) Razor (Law of Parsimony and Succinctness) ---
http://en.wikipedia.org/wiki/Ockham's_razor
"Razoring Ockham’s razor," by Massimo Pigliucci, Rationally
Speaking, May 6, 2011 ---
http://rationallyspeaking.blogspot.com/2011/05/razoring-ockhams-razor.html
Scientists, philosophers and skeptics alike are
familiar with the idea of Ockham’s razor, an epistemological principle
formulated in a number of ways by the English Franciscan friar and
scholastic
philosopher William of Ockham (1288-1348).
Here is one version of it, from the pen of its originator:
Frustra fit per plura quod potest
fieri per pauciora. [It is futile to do with more things that which can
be done with fewer] (Summa Totius Logicae)
Philosophers often refer to this as
the principle of economy, while scientists tend to call it parsimony.
Skeptics invoke it every time they wish to dismiss out of hand claims of
unusual phenomena (after all, to invoke the “unusual” is by definition
unparsimonious, so there).
There is a problem with all of this, however, of
which I was reminded recently while reading an old paper by my colleague
Elliot Sober, one of the most prominent contemporary philosophers of
biology. Sober’s article is provocatively entitled “Let’s razor Ockham’s
razor” and it is available for download from
his web site.
Let me begin by reassuring you that Sober didn’t
throw the razor in the trash. However, he cut it down to size, so to
speak. The obvious question to ask about Ockham’s razor is: why? On what
basis are we justified to think that, as a matter of general practice,
the simplest hypothesis is the most likely one to be true? Setting aside
the surprisingly difficult task of operationally defining “simpler” in
the context of scientific hypotheses (it can be done, but only
in certain domains,
and it ain’t straightforward), there doesn’t seem
to be any particular logical or metaphysical reason to believe that the
universe is a simple as it could be.
Indeed, we know it’s not. The history
of science is replete with examples of simpler (“more elegant,” if you
are aesthetically inclined) hypotheses that had to yield to more clumsy
and complicated ones. The Keplerian idea of elliptical planetary orbits
is demonstrably more complicated than the Copernican one of circular
orbits (because it takes more parameters to define an ellipse than a
circle), and yet, planets do in fact run around the gravitational center
of the solar system in ellipses, not circles.
Lee Smolin (in his delightful
The Trouble with Physics)
gives us a good history of 20th century physics,
replete with a veritable cemetery of hypotheses that people thought
“must” have been right because they were so simple and beautiful, and
yet turned out to be wrong because the data stubbornly contradicted
them.
In Sober’s paper you will find a
discussion of two uses of Ockham’s razor in biology, George Williams’
famous critique of group selection, and “cladistic” phylogenetic
analyses. In the first case, Williams argued that individual- or
gene-level selective explanations are preferable to group-selective
explanations because they are more parsimonious. In the second case,
modern systematists use parsimony to reconstruct the most likely
phylogenetic relationships among species, assuming that a smaller number
of independent evolutionary changes is more likely than a larger number.
Part of the problem is that we do
have examples of both group selection (not many, but they are there),
and of non-parsimonious evolutionary paths, which means that at best
Ockham’s razor can be used as a first approximation heuristic, not as a
sound principle of scientific inference.
And it gets worse before it gets
better. Sober cites Aristotle, who chided Plato for hypostatizing The
Good. You see, Plato was always running around asking what makes for a
Good Musician, or a Good General. By using the word Good in all these
inquiries, he came to believe that all these activities have something
fundamental in common, that there is a general concept of Good that gets
instantiated in being a good musician, general, etc. But that, of
course, is nonsense on stilts, since what makes for a good musician has
nothing whatsoever to do with what makes for a good general.
Analogously, suggests Sober, the
various uses of Ockham’s razor have no metaphysical or logical universal
principle in common — despite what many scientists, skeptics and even
philosophers seem to think. Williams was correct, group selection is
less likely than individual selection (though not impossible), and the
cladists are correct too that parsimony is usually a good way to
evaluate competitive phylogenetic hypotheses. But the two cases (and
many others) do not share any universal property in common.
What’s going on, then? Sober’s solution is to
invoke the famous
Duhem thesis.**
Pierre Duhem suggested in 1908 that, as Sober puts
it: “it is wrong to think that hypothesis H makes predictions about
observation O; it is the conjunction of H&A [where A is a set of
auxiliary hypotheses] that issues in testable consequences.”
This means that, for instance, when astronomer
Arthur Eddington “tested”
Einstein’s General Theory of Relativity during a
famous 1919 total eclipse of the Sun — by showing that the Sun’s
gravitational mass was indeed deflecting starlight by exactly the amount
predicted by Einstein — he was not, strictly speaking doing any such
thing. Eddington was testing Einstein’s theory given a set of
auxiliary hypotheses, a set that included independent estimates of
the mass of the sun, the laws of optics that allowed the telescopes to
work, the precision of measurement of stellar positions, and even the
technical processing of the resulting photographs. Had Eddington failed
to confirm the hypotheses this would not (necessarily) have spelled the
death of Einstein’s theory (since confirmed
in many other ways).
The failure could have resulted from the failure
of any of the auxiliary hypotheses instead.
This is both why there is no such
thing as a “crucial” experiment in science (you always need to repeat
them under a variety of conditions), and why naive Popperian
falsificationism is wrong (you can never falsify a hypothesis directly,
only the H&A complex can be falsified).
What does this have to do with
Ockham’s razor? The Duhem thesis explains why Sober is right, I think,
in maintaining that the razor works (when it does) given certain
background assumptions that are bound to be discipline- and
problem-specific. So, for instance, Williams’ reasoning about group
selection isn’t correct because of some generic logical property of
parsimony (as Williams himself apparently thought), but because — given
the sorts of things that living organisms and populations are, how
natural selection works, and a host of other biological details — it is
indeed much more likely than not that individual and not group selective
explanations will do the work in most specific instances. But that set
of biological reasons is quite different from the set that
cladists use in justifying their use of parsimony to reconstruct
organismal phylogenies. And needless to say, neither of these two sets
of auxiliary assumptions has anything to do with the instances of
successful deployment of the razor by physicists, for example.
Continued in article
Note the comments that follow
Bob Jensen's threads on theory are at
http://faculty.trinity.edu/rjensen/Theory01.htm
"You Might Already Know This ... ," by Benedict Carey, The New York
Times, January 10, 2011 ---
http://www.nytimes.com/2011/01/11/science/11esp.html?_r=1&src=me&ref=general
In recent weeks, editors at a respected
psychology journal have been taking heat from
fellow scientists for deciding to accept a research report that claims to
show the existence of extrasensory perception.
The report, to be published this year in
The Journal of Personality and Social Psychology,
is not likely to change many minds. And the scientific critiques of the
research methods and data analysis of its author, Daryl J. Bem (and the peer
reviewers who urged that his paper be accepted), are not winning over many
hearts.
Yet
the episode has
inflamed one of the longest-running debates in science. For decades, some
statisticians have argued that the standard technique used to analyze data
in much of social science and medicine overstates many study findings —
often by a lot. As a result, these experts say, the literature is littered
with positive findings that do not pan out: “effective” therapies that are
no better than a placebo; slight biases that do not affect behavior;
brain-imaging correlations that are meaningless.
By incorporating statistical techniques that are
now widely used in other sciences —
genetics, economic modeling, even wildlife
monitoring — social scientists can correct for such problems, saving
themselves (and, ahem, science reporters) time, effort and embarrassment.
“I was delighted that this ESP paper was accepted
in a mainstream science journal, because it brought this whole subject up
again,” said James Berger, a statistician at
Duke University. “I was on a mini-crusade about
this 20 years ago and realized that I could devote my entire life to it and
never make a dent in the problem.”
In recent weeks, editors at a respected
psychology journal have been taking heat from
fellow scientists for deciding to accept a research report that claims to
show the existence of extrasensory perception.
The report, to be published this year in
The Journal of Personality and Social Psychology,
is not likely to change many minds. And the scientific critiques of the
research methods and data analysis of its author, Daryl J. Bem (and the peer
reviewers who urged that his paper be accepted), are not winning over many
hearts.
Yet
the episode has inflamed one of the
longest-running debates in science. For decades, some statisticians have
argued that the standard technique used to analyze data in much of social
science and medicine overstates many study findings — often by a lot. As a
result, these experts say, the literature is littered with positive findings
that do not pan out: “effective” therapies that are no better than a
placebo; slight biases that do not affect behavior; brain-imaging
correlations that are meaningless.
By incorporating statistical techniques that are
now widely used in other sciences —
genetics, economic modeling, even wildlife
monitoring — social scientists can correct for such problems, saving
themselves (and, ahem, science reporters) time, effort and embarrassment.
“I was delighted that this ESP paper was accepted
in a mainstream science journal, because it brought this whole subject up
again,” said James Berger, a statistician at
Duke University. “I was on a mini-crusade about
this 20 years ago and realized that I could devote my entire life to it and
never make a dent in the problem.”
The statistical approach that has dominated the
social sciences for almost a century is called significance testing. The
idea is straightforward. A finding from any well-designed study — say, a
correlation between a personality trait and the risk of depression — is
considered “significant” if its probability of occurring by chance is less
than 5 percent.
This arbitrary cutoff makes sense when the effect
being studied is a large one — for example, when measuring the so-called
Stroop effect. This effect predicts that naming the color of a word is
faster and more accurate when the word and color match (“red” in red
letters) than when they do not (“red” in blue letters), and is very strong
in almost everyone.
“But if the true effect of what you are measuring
is small,” said Andrew Gelman, a professor of statistics and political
science at
Columbia University, “then by necessity anything
you discover is going to be an overestimate” of that effect.
Consider the following experiment. Suppose there
was reason to believe that a coin was slightly weighted toward heads. In a
test, the coin comes up heads 527 times out of 1,000.
Is this significant evidence that the coin is
weighted?
Classical analysis says yes. With a fair coin, the
chances of getting 527 or more heads in 1,000 flips is less than 1 in 20, or
5 percent, the conventional cutoff. To put it another way: the experiment
finds evidence of a weighted coin “with 95 percent confidence.”
Yet many statisticians do not buy it. One in 20 is
the probability of getting any number of heads above 526 in 1,000 throws.
That is, it is the sum of the probability of flipping 527, the probability
of flipping 528, 529 and so on.
But the experiment did not find all of the numbers
in that range; it found just one — 527. It is thus more accurate, these
experts say, to calculate the probability of getting that one number — 527 —
if the coin is weighted, and compare it with the probability of getting the
same number if the coin is fair.
Statisticians can show that this ratio cannot be
higher than about 4 to 1, according to Paul Speckman, a statistician, who,
with Jeff Rouder, a psychologist, provided the example. Both are at the
University of Missouri and said that the simple
experiment represented a rough demonstration of how classical analysis
differs from an alternative approach, which emphasizes the importance of
comparing the odds of a study finding to something that is known.
The point here, said Dr. Rouder, is that 4-to-1
odds “just aren’t that convincing; it’s not strong evidence.”
And yet classical significance testing “has been
saying for at least 80 years that this is strong evidence,” Dr. Speckman
said in an e-mail.
The critics have been crying foul for half that
time. In the 1960s, a team of statisticians led by Leonard Savage at the
University of Michigan showed that the classical
approach could overstate the significance of the finding by a factor of 10
or more. By that time, a growing number of statisticians were developing
methods based on the ideas of the
18th-century English mathematician Thomas Bayes.
Bayes devised a way to update the probability for a
hypothesis as new evidence comes in.
So in evaluating the strength of a given finding,
Bayesian (pronounced BAYZ-ee-un) analysis incorporates known probabilities,
if available, from outside the study.
It might be called the “Yeah, right” effect. If a
study finds that kumquats reduce the risk of heart disease by 90 percent,
that a treatment cures alcohol addiction in a week, that sensitive parents
are twice as likely to give birth to a girl as to a boy, the Bayesian
response matches that of the native skeptic: Yeah, right. The study findings
are weighed against what is observable out in the world.
In at least one area of medicine — diagnostic
screening tests — researchers already use known probabilities to evaluate
new findings. For instance, a new lie-detection test may be 90 percent
accurate, correctly flagging 9 out of 10 liars. But if it is given to a
population of 100 people already known to include 10 liars, the test is a
lot less impressive.
It correctly identifies 9 of the 10 liars and
misses one; but it incorrectly identifies 9 of the other 90 as lying.
Dividing the so-called true positives (9) by the total number of people the
test flagged (18) gives an accuracy rate of 50 percent. The “false
positives” and “false negatives” depend on the known rates in the
population.
Continued in article
What went wrong with accountics research ---
http://faculty.trinity.edu/rjensen/Theory01.htm#WhatWentWrong
It ain’t what we don’t know that gives us trouble,
it’s what we know that just ain’t so.
Josh Billings
Interesting Quotation for Accountics Researchers Who Tend Not to Check for
Validity With Replication Efforts
"On Early Warning Signs," by George Sugihara. December 20, 2010 ---
http://seedmagazine.com/content/article/on_early_warning_signs/
Thank you Miguel.
. . .
Nonlinear systems, however, are not so well
behaved. They can appear stationary for a long while, then without anything
changing, they exhibit jumps in variability—so-called “heteroscedasticity.”
For example, if one looks at the range of economic variables over the past
decade (daily market movements, GDP changes, etc.), one might guess that
variability and the universe of possibilities are very modest. This was the
modus operandi of normal risk management. As a consequence, the likelihood
of some of the large moves we saw in 2008, which happened over so many
consecutive days, should have been less than once in the age of the
universe.
Our problem is that the scientific desire to
simplify has taken over, something that Einstein warned against when he
paraphrased Occam: “Everything should be made as simple as possible, but not
simpler.” Thinking of natural and economic systems as essentially stable and
decomposable into parts is a good initial hypothesis, current observations
and measurements do not support that hypothesis—hence our continual
surprise. Just as we like the idea of constancy, we are stubborn to change.
The 19th century American humorist Josh Billings, perhaps, put it best: “It
ain’t what we don’t know that gives us trouble, it’s what we know that just
ain’t so.”
Continued in article
Is anecdotal evidence irrelevant?
A subscriber to the AECM that we hear from quite often asked me to elaborate on
the nature of anecdotal evidence. My reply may be of interest to other
subscribers to the AECM.
Hi XXXXX,
Statistical inference ---
http://en.wikipedia.org/wiki/Statistical_inference
Anecdotal Evidence ---
http://en.wikipedia.org/wiki/Anecdotal_evidence
Humanities research is nearly always anecdotal. History research, for example,
delves through original correspondence (letters, memos, and now email messages)
of great people in history to discover more about causes of events in history.
This, however, is anecdotal research, and there are greatly varying degrees of
the quality of such historical anecdotal evidence.
Legal research is generally anecdotal, although court cases often use
statistical inference studies as part, but not all, of the total evidence
packages in the court cases.
Scientific research is both inferential and anecdotal. Anecdotal evidence often
provides the creative ideas for hypotheses that are later put to more rigorous
tests.
National Center for Case Study Teaching in Science ---
http://sciencecases.lib.buffalo.edu/cs/
But between the anecdote and the truly random sample is evidence that is neither
totally anecdotal nor rigorously scientific. For example, it's literally
impossible to identify the population of tax cheaters in the underground
cash-only economy. Hence, from a strictly inferential standpoint it's impossible
to conduct truly random samples on such unknown populations.
Nevertheless, the IRS and other researchers do conduct various types of
"anecdotal investigations" of how people cheat on their taxes, including
cheating in the underground cash-only economy. One approach is the IRS policy of
conducting a samplings (not random) of full audits designed not so much to
collect revenue or punish wrong doers as to discover how people comply with tax
rules and devise legal or illegal ploys for avoiding or deferring taxes. This is
anecdotal research.
In both instances of mine that you refer to I provided only anecdotal evidence
that I called "cases." In fact, virtually all case studies are anecdotal in the
sense that the statistical inference tests are not generally feasible ---
http://www.trinity.edu/rjensen/000aaa/thetools.htm#Cases
However, it is common knowledge that there's a vast underground cash-only
economy. And the court records are clogged with cases of persons who got caught
cheating on welfare, cheating on taxes, receiving phony disability insurance
settlements and Social Security payments, etc. But these court cases are
probably only the tip of the icebergs in terms of the millions more who get away
with cheating in the cash-only underground economy.
The problem with
accountics research published in TAR, JAR, and JAE is that it requires
statistical inference or analytics based upon assumed (usually unrealistic or
unproven) assumptions. The net result has been very sophisticated research
findings that are of little interest to the profession because the research
methodology and unrealistic assumptions limit
accountics
research to mostly uninteresting problems. Analytical
accountics
research problems are sometimes interesting problems but these
accountics
research findings are usually no better than or even worse than anecdotal
evidence due to unrealistic and unproven assumptions ---
http://www.trinity.edu/rjensen/TheoryTAR.htm
It is obvious that
accountics researchers have limited themselves to mostly uninteresting
problems. In real science, scientists demand that interesting research findings
be replicated. Since
accountics scientists almost never demand or even encourage (by
publishing replications) that their studies be replicated this is
prima
facie evidence of
the lack of relevance of
accountics research findings since accountics researchers themselves do
not demand replications.
AAA leaders are now having retreats focused on how to make
accountics
research more relevant to the academic world (read that accounting teachers) and
professional world ---
http://aaahq.org/pubs/AEN/2012/AEN_Winter12_WEB.pdf
Anecdotal research in accounting generally focuses on the more interesting
problems than accountics
research. But anecdotal findings are not easily extrapolated to general
conclusions. Anecdotal evidence often builds up to where it becomes more and
more convincing. For example, it did not take long in the early 1990s to
discover that companies were entering into hundreds of billions and then
trillions in interest rate swaps because there were no domestic or international
accounting rules for even disclosing interest rate swaps let alone booking them.
In many instances companies were entering into such swaps for off-balance sheet
financing (OBSF).
As the anecdotal evidence on swap
OBSF mounted like
grains of sand, the Director of the SEC told the Chairman of the
FASB that the
three major problems to be addressed by the
FASB were to be
"derivatives, derivatives, and derivatives." And the leading problems of
derivatives was that forward contracts and swaps (portfolios of forward
contracts) were not even disclosed let alone booked.
Without having a single
accountics study of interest rate swaps amongst the mountain of anecdotal
evidence of OBSF
cheating with interest rate swaps we soon had
FAS 133 that
required the booking of interest rate swaps and at least quarterly resets of the
carrying values of these swaps to fair market value --- that is the power of
anecdotal evidence rather than
accountics
evidence.
In a similar manner, the IRS is making inroads on reducing tax cheating in the
underground economy using evidence piled up from anecdotal rather than strictly
scientific research. For example, a huge step was made when the IRS commenced to
require and code 1099 information into IRS computers. Before then, for example,
most professors who received small consulting fees and
honoraria forgot
about such fees when they filed their taxes. Now they're reminded after December
31 when they receive their copies of the 1099 forms files with the IRS.
But I can assure you based upon my anecdotal evidence, that the underground
economy still is alive and thriving in San Antonio when it comes to the type of
"cash only" labor that I list at
http://www.cs.trinity.edu/~rjensen/temp/TaxNoTax.htm
And I can assure you of this without knowing about a single
accountics study
of the underground cash-only economy that this economy is alive and thriving.
Mountains of anecdotal evidence reveal that the underground economy greatly
inhibits the prevention of cheating on taxes, welfare, disability claims,
Medicaid, etc.
Interestingly, however, the underground cash-only economy often makes it easier
to for poor people to attain the American Dream.
Case Studies in Gaming the Income
Tax Laws
http://www.cs.trinity.edu/~rjensen/temp/TaxNoTax.htm
Question
What would be the best way to reduce cheating on taxes, welfare, Medicaid, etc.?
Answer
Go to a cashless society that is now technically feasible but politically
impossible since members of Congress themselves thrive on cheating in the
underground cash-only economy.
Respectfully,
Bob Jensen
"A Pragmatist Defence of Classical Financial Accounting Research," by
Brian A. Rutherford, Abacus, Volume 49, Issue 2, pages 197–218, June 2013
---
http://onlinelibrary.wiley.com/doi/10.1111/abac.12003/abstract
The reason for the disdain in which classical
financial accounting research has come to held by many in the scholarly
community is its allegedly insufficiently scientific nature. While many have
defended classical research or provided critiques of post-classical
paradigms, the motivation for this paper is different. It offers an
epistemologically robust underpinning for the approaches and methods of
classical financial accounting research that restores its claim to
legitimacy as a rigorous, systematic and empirically grounded means of
acquiring knowledge. This underpinning is derived from classical
philosophical pragmatism and, principally, from the writings of John Dewey.
The objective is to show that classical approaches are capable of yielding
serviceable, theoretically based solutions to problems in accounting
practice.
Jensen Comment
When it comes to "insufficient scientific nature" of classical accounting
research I should note yet once again that accountics science never attained the
status of real science where the main criteria are scientific searches for
causes and an obsession with replication (reproducibility) of findings.
Accountics science is overrated because it only achieved the status of a
psuedo science ---
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm#Pseudo-Science
"Research
on Accounting Should Learn From the Past" by Michael H. Granof and Stephen
A. Zeff, Chronicle of Higher Education, March 21, 2008
The unintended consequence has been that interesting and researchable questions
in accounting are essentially being ignored.
By confining the major thrust in research to phenomena that can be
mathematically modeled or derived from electronic databases, academic
accountants have failed to advance the profession in ways that are expected of
them and of which they are capable.
Academic research has unquestionably broadened the views of standards setters as
to the role of accounting information and how it affects the decisions of
individual investors as well as the capital markets. Nevertheless, it has had
scant influence on the standards themselves.
Continued
in article
"Research on Accounting Should Learn From the Past,"
by Michael H. Granof and
Stephen A. Zeff, Chronicle of Higher Education, March 21, 2008
. . .
The narrow focus of today's research has also resulted in a disconnect between
research and teaching. Because of the difficulty of conducting publishable
research in certain areas — such as taxation, managerial accounting, government
accounting, and auditing — Ph.D. candidates avoid choosing them as specialties.
Thus, even though those areas are central to any degree program in accounting,
there is a shortage of faculty members sufficiently knowledgeable to teach them.
To be sure, some accounting research, particularly that pertaining to the
efficiency of capital markets, has found its way into both the classroom and
textbooks — but mainly in select M.B.A. programs and the textbooks used in those
courses. There is little evidence that the research has had more than a marginal
influence on what is taught in mainstream accounting courses.
What needs to be done? First, and most significantly, journal editors,
department chairs, business-school deans, and promotion-and-tenure committees
need to rethink the criteria for what constitutes appropriate accounting
research. That is not to suggest that they should diminish the importance of the
currently accepted modes or that they should lower their standards. But they
need to expand the set of research methods to encompass those that, in other
disciplines, are respected for their scientific standing. The methods include
historical and field studies, policy analysis, surveys, and international
comparisons when, as with empirical and analytical research, they otherwise meet
the tests of sound scholarship.
Second, chairmen, deans, and promotion and merit-review committees must expand
the criteria they use in assessing the research component of faculty
performance. They must have the courage to establish criteria for what
constitutes meritorious research that are consistent with their own
institutions' unique characters and comparative advantages, rather than
imitating the norms believed to be used in schools ranked higher in magazine and
newspaper polls. In this regard, they must acknowledge that accounting
departments, unlike other business disciplines such as finance and marketing,
are associated with a well-defined and recognized profession. Accounting
faculties, therefore, have a special obligation to conduct research that is of
interest and relevance to the profession. The current accounting model was
designed mainly for the industrial era, when property, plant, and equipment were
companies' major assets. Today, intangibles such as brand values and
intellectual capital are of overwhelming importance as assets, yet they are
largely absent from company balance sheets. Academics must play a role in
reforming the accounting model to fit the new postindustrial environment.
Third, Ph.D. programs must ensure that young accounting researchers are
conversant with the fundamental issues that have arisen in the accounting
discipline and with a broad range of research methodologies. The accounting
literature did not begin in the second half of the 1960s. The books and articles
written by accounting scholars from the 1920s through the 1960s can help to
frame and put into perspective the questions that researchers are now studying.
Continued in article
How accountics scientists should change ---
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
Statistical Inference Versus Substantive Inference
A scholar named with the commentary name Centurian comments as follows
following the following article
"One Economist's Mission to Redeem the Field of Finance," by Robert
Schiller, Chronicle of Higher Education, April 8, 2012 ---
http://chronicle.com/article/Robert-Shillers-Mission-to/131456/
Economics as a "science" is no different than
Sociology, Psychology, Criminal Justice, Political Science, etc.,etc.. To
those in the "hard sciences" [physics, biology, chemistry, mathematics],
these "soft sciences" are dens of thieves. Thieves who have stolen the
"scientific method" and abused it.
These soft sciences all apply the scientific method
to biased and insufficient data sets, then claim to be "scientific", then
assert their opinions and biases as scientific results. They point to
"correlations". Correlations which are made even though they know they do
not know all the forces/factors involved nor the ratio of effect from the
forces/factors.
They know their mathematical formulas and models
are like taking only a few pieces of evidence from a crime scene and then
constructing an elaborate "what happened" prosecution and defense. Yet
neither side has any real idea, other than in the general sense, what
happened. They certainly have no idea what all the factors or human
behaviors were involved, nor the true motives.
Hence the growing awareness of the limitations of
all the quantitative models that led to the financial crisis/financial WMDs
going off.
Take for example the now thoroughly discredited
financial and economic models that claimed validity through the use of the
same mathematics used to make atomic weapons; Monte Carlo simulation. MC
worked on the Manhattan Project because real scientists, who obeyed the laws
of science when it came to using data, were applying the mathematics to a
valid data set.
Economists and Wall Street Quants threw out the
data set disciplines of science. The Quant's of Wall Street and those
scientists who claimed the data proved man made global warming share the
same sin of deception. Why? For the same reason, doing so allowed them to
continue their work in the lab. They got to continue to experiment and "do
science". Science paid for by those with a deep vested financial interest in
the the false correlations proclaimed by these soft science dogmas.
If you take away a child's crayons and give him oil
paints used by Michelangelo, you're not going to get the Sistine Chapel.
You're just going to get a bigger mess.
If Behavioral Finance proves anything it is how far
behind the other Social Sciences economists really are. And if the
"successes" of the Social Sciences are any indication, a lot bigger messes
are waiting down the road.
Centurion
"The Standard Error of Regressions," by Deirdre N. McCloskey and Stephen T.
Ziliak, Journal of Economic Literature, 1996, pp. 97-114
THE IDEA OF statistical significance is old, as old
as Cicero writing on forecasts (Cicero, De Divinatione, I. xiii. 23). In
1773 Laplace used it to test whether comets came from outside the solar
system (Elizabeth Scott 1953, p. 20). The first use of the very word
"significance" in a statistical context seems to be John Venn's, in 1888,
speaking of differences expressed in units of probable error,
They inform us which of the differences in the
above tables are permanent and significant, in the sense that we may be
tolerably confident that if we took another similar batch we should find
a similar difference; and which are merely transient and insignificant,
in the sense that another similar batch is about as likely as not to
reverse the conclusion we have obtained. (Venn, quoted in Lancelot
Hogben 1968, p. 325).
Statistical significance has been much used since
Venn, and especially since Ronald Fisher. The problem, and our main point,
is that a difference can be permanent (as Venn put it) without being
"significant" in o ther senses, such as for science or policy. And a
difference can be significant for science or policy and yet be insignificant
statistically, ignored by the less thoughtful researchers.
In the 1930s Jerzy Neyman and Egon S. Pearson, and
then more explicitly Abraham Wald, argued that actual investigations should
depend on substantive not merely statistical significance. In 1933 Neyman
and Pearson wrote of type I and type II errors:
Is it more serious to convict an innocent man
or to acquit a guilty? That will depend on the consequences of the
error; is the punishment death or fine; what is the danger to the
community of released criminals; what are the current ethical views on
punishment? From the point of view of mathematical theory all that we
can do is to show how the risk of errors may be controlled and minimised.
The use of these statistical tools in any given case, in determining
just how the balance should be struck, must be left to the investigator.
(Neyman and Pearson 1933, p. 296; italics supplied)
Wald went further:
The question as to how the form of the weight [that is, loss]
function . . . should be determined, is not a mathematical or
statistical one. The statistician who wants to test certain hypotheses
must first determine the relative importance of all possible errors,
which will depend on the special purposes of his investigation. (1939,
p. 302, italics supplied)
To date no empirical studies have been undertaken
measuring the use of statistical significance in economics. We here examine
the alarming hypothesis that ordinary usage in economics takes statistical
significance to be the same as economic significance. We compare statistical
best practice against leading textbooks of recent decades and against the
papers using regression analysis in the 1980s in the American Economic
Review.
An Example
. . .
V. Taking the Con Out of Confidence Intervals
In a squib published in the American Economic
Review in 1985 one of us claimed that "[r]oughly three-quarters of the
contributors to the American Economic Review misuse the test of statistical
significance" (McCloskey 1985, p. 201). The full survey confirms the claim,
and in some matters strengthens it.
We would not assert that every economist
misunderstands statistical significance, only that most do, and these some
of the best economic scientists. By way of contrast to what most understand
statistical significance to be capable of saying, Edward Lazear and Robert
Michael wrote 17 pages of empirical economics in the AER, using ordinary
least squares on two occasions, without a single mention of statistical
significance (AER Mar. 1980, pp. 96-97, pp. 105-06). This is notable
considering they had a legitimate sample, justifying a discussion of
statistical significance were it relevant to the scientific questions they
were asking. Estimated coefficients in the paper are interpreted carefully,
and within a conversation in which they ask how large is large (pp. 97, 101,
and throughout).
The low and falling cost of calculation, together
with a widespread though unarticulated realization that after all the
significance test is not crucial to scientific questions, has meant that
statistical significance has been valued at its cost. Essentially no one
believes a finding of statistical significance or insignificance.
This is bad for the temper of the field. My
statistical significance is a "finding"; yours is an ornamented prejudice.
Continued in article
Jensen at the 2012 AAA Meetings?
http://aaahq.org/AM2012/program.cfm
A Forthcoming AAA Plenary Session to Note
Sudipta Basu called my attention to the 2012 AAA annual meeting website that
now lists the plenary speakers.
See:
http://aaahq.org/AM2012/Speakers.cfm
In particular note the following speaker
Deirdre McCloskey Distinguished Professor of
Economics, History, English, and Communication, University of Illinois at
Chicago ---
http://www.deirdremccloskey.com/
Deirdre McCloskey teaches economics, history,
English, and communication at the University of Illinois at Chicago. A
well-known economist and historian and rhetorician, she has written sixteen
books and around 400 scholarly pieces on topics ranging from technical
economics and statistics to transgender advocacy and the ethics of the
bourgeois virtues. She is known as a "conservative" economist,
Chicago-School style (she taught for 12 years there), but protests that "I'm
a literary, quantitative, postmodern, free-market, progressive Episcopalian,
Midwestern woman from Boston who was once a man. Not 'conservative'! I'm a
Christian libertarian."
Her latest book, Bourgeois Dignity: Why
Economics Can't Explain the Modern World (University of Chicago Press,
2010), which argues that an ideological change rather than saving or
exploitation is what made us rich, is the second in a series of four on The
Bourgeois Era. The first was The Bourgeois Virtues: Ethics for an Age of
Commerce (2006), asking if a participant in a capitalist economy can still
have an ethical life (briefly, yes). With Stephen Ziliak she wrote in
2008, The Cult of Statistical
Significance (2008), which criticizes the
proliferation of tests of "significance," and was in 2011 the basis of a
Supreme Court decision.
Professor Basu called my attention to the plan for Professor McCloskey to
discuss accountics science with a panel in a concurrent session following her
plenary session. I had not originally intended to attend the 2012 AAA meetings
because of my wife's poor health. But the chance to be in the program with
Professor McCloskey on the topic of accountics science is just too tempting. My
wife is now insisting that I go to these meetings and that she will come along
along with me. One nice thing for us is that Southwest flies nonstop from
Manchester to Baltimore with no stressful change of flights for her.
I think I am going to accept Professor Basu's kind invitation to be on this
panel.
I think we are making progress against the "Cult of Statistical
Significance."
2012 AAA Meeting Plenary
Speakers and Response Panel Videos ---
http://commons.aaahq.org/hives/20a292d7e9/summary
I think you have to be a an AAA member and log into the AAA Commons to view
these videos.
Bob Jensen is an obscure speaker following the handsome Rob Bloomfield
in the 1.02 Deirdre McCloskey Follow-up Panel—Video ---
http://commons.aaahq.org/posts/a0be33f7fc
My
threads on Deidre McCloskey and my own talk are at
http://www.cs.trinity.edu/~rjensen/temp/DeirdreMcCloskey/StatisticalSignificance01.htm
September 13, 2012 reply
from Jagdish Gangolly
Bob,
Thanks you so much for posting this.
What a wonderful speaker Deidre McCloskey! Reminded
me of JR Hicks who also was a stammerer. For an economist, I was amazed by
her deep and remarkable understanding of statistics.
It was nice to hear about Gossett, perhaps the only
human being who got along well with both Karl Pearson and R.A. Fisher,
getting along with the latter itself a Herculean feat.
Gosset was helped in the mathematical derivation of
small sample theory by Karl Pearson, he did not appreciate its importance,
it was left to his nemesis R.A. Fisher. It is remarkable that he could work
with these two giants who couldn't stand each other.
In later life Fisher and Gosset parted ways in that
Fisher was a proponent of randomization of experiments while Gosset was a
proponent of systematic planning of experiments and in fact proved
decisively that balanced designs are more precise, powerful and efficient
compared with Fisher's randomized experiments (see
http://sites.roosevelt.edu/sziliak/files/2012/02/William-S-Gosset-and-Experimental-Statistics-Ziliak-JWE-2011.pdf
)
I remember my father (who designed experiments in
horticulture for a living) telling me the virtues of balanced designs at the
same time my professors in school were extolling the virtues of
randomisation.
In Gosset we also find seeds of Bayesian thinking
in his writings.
While I have always had a great regard for Fisher
(visit to the tree he planted at the Indian Statistical Institute in
Calcutta was for me more of a pilgrimage), I think his influence on the
development of statistics was less than ideal.
Regards,
Jagdish
Jagdish S. Gangolly
Department of Informatics College of Computing & Information
State University of New York at Albany
Harriman Campus, Building 7A, Suite 220
Albany, NY 12222 Phone: 518-956-8251, Fax: 518-956-8247
Hi Jagdish,
You're one of the few people who can really appreciate Deidre's scholarship in
history, economics, and statistics. When she stumbled for what seemed like
forever trying to get a word out, it helped afterwards when trying to remember
that word.
Interestingly, two Nobel economists slugged out the very essence of theory some
years back. Herb Simon insisted that the purpose of theory was to explain.
Milton Friedman went off on the F-Twist tangent saying that it was enough if a
theory merely predicted. I lost some (certainly not all) respect for Friedman
over this. Deidre, who knew Milton, claims that deep in his heart, Milton did
not ultimately believe this to the degree that it is attributed to him. Of
course Deidre herself is not a great admirer of Neyman, Savage, or Fisher.
Friedman's essay
"The
Methodology of Positive Economics" (1953) provided
the
epistemological pattern for his own subsequent
research and to a degree that of the Chicago School. There he argued that
economics as science should be free of value judgments for it to be
objective. Moreover, a useful economic theory should be judged not by its
descriptive realism but by its simplicity and fruitfulness as an engine of
prediction. That is, students should measure the accuracy of its
predictions, rather than the 'soundness of its assumptions'. His argument
was part of an ongoing debate among such statisticians as
Jerzy Neyman,
Leonard Savage, and
Ronald Fisher.
.
"Milton Friedman's grand illusion," by Mark Buchanan, The
Physics of Finance: A look at economics and finance through the lens of physics,
September 16, 2011 ---
http://physicsoffinance.blogspot.com/2011/09/milton-friedmans-grand-illusion.html
Many of us on the AECM are not great admirers of positive economics ---
http://faculty.trinity.edu/rjensen/theory02.htm#PostPositiveThinking
Everyone
is entitled to their own opinion, but not their own facts.
Senator Daniel Patrick Moynihan --- FactCheck.org ---
http://www.factcheck.org/
Then again, maybe we're all
entitled to our own facts!
"The Power of Postpositive
Thinking," Scott McLemee,
Inside Higher Ed, August 2, 2006 ---
http://www.insidehighered.com/views/2006/08/02/mclemee
In particular,
a dominant trend in critical theory was the rejection of the concept of
objectivity as something that rests on a more or less naive
epistemology: a simple belief that “facts” exist in some pristine state
untouched by “theory.” To avoid being naive, the dutiful student learned
to insist that, after all, all facts come to us embedded in various
assumptions about the world. Hence (ta da!) “objectivity” exists only
within an agreed-upon framework. It is relative to that framework. So it
isn’t really objective....
What Mohanty
found in his readings of the philosophy of science were much less naïve,
and more robust, conceptions of objectivity than the straw men being
thrashed by young Foucauldians at the time. We are not all prisoners of
our paradigms. Some theoretical frameworks permit the discovery of new
facts and the testing of interpretations or hypotheses. Others do not.
In short, objectivity is a possibility and a goal — not just in the
natural sciences, but for social inquiry and humanistic research as
well.
Mohanty’s major
theoretical statement on PPR arrived in 1997 with Literary Theory and
the Claims of History: Postmodernism, Objectivity, Multicultural
Politics (Cornell University Press). Because poststructurally
inspired notions of cultural relativism are usually understood to be
left wing in intention, there is often a tendency to assume that
hard-edged notions of objectivity must have conservative implications.
But Mohanty’s work went very much against the current.
“Since the
lowest common principle of evaluation is all that I can invoke,” wrote
Mohanty, complaining about certain strains of multicultural relativism,
“I cannot — and consequently need not — think about how your space
impinges on mine or how my history is defined together with yours. If
that is the case, I may have started by declaring a pious political
wish, but I end up denying that I need to take you seriously.”
PPR did
not require throwing out the multicultural baby with the relativist
bathwater, however. It meant developing ways to think about cultural
identity and its discontents. A number of Mohanty’s students and
scholarly colleagues have pursued the implications of postpositive
identity politics.
I’ve written elsewhere
about Moya, an associate professor of English at Stanford University who
has played an important role in developing PPR ideas about identity. And
one academic critic has written
an interesting review essay
on early postpositive scholarship — highly recommended for anyone with a
hankering for more cultural theory right about now.
Not everybody
with a sophisticated epistemological critique manages to turn it into a
functioning think tank — which is what started to happen when people in
the postpositive circle started organizing the first Future of Minority
Studies meetings at Cornell and Stanford in 2000. Others followed at the
University of Michigan and at the University of Wisconsin in Madison.
Two years ago FMS applied for a grant from Mellon Foundation, receiving
$350,000 to create a series of programs for graduate students and junior
faculty from minority backgrounds.
The FMS Summer
Institute, first held in 2005, is a two-week seminar with about a dozen
participants — most of them ABD or just starting their first
tenure-track jobs. The institute is followed by a much larger colloquium
(the part I got to attend last week). As schools of thought in the
humanities go, the postpositivists are remarkably light on the in-group
jargon. Someone emerging from the Institute does not, it seems, need a
translator to be understood by the uninitated. Nor was there a dominant
theme at the various panels I heard.
Rather, the
distinctive quality of FMS discourse seems to derive from a certain very
clear, but largely unstated, assumption: It can be useful for scholars
concerned with issues particular to one group to listen to the research
being done on problems pertaining to other groups.
That sounds
pretty simple. But there is rather more behind it than the belief that
we should all just try to get along. Diversity (of background, of
experience, of disciplinary formation) is not something that exists
alongside or in addition to whatever happens in the “real world.” It is
an inescapable and enabling condition of life in a more or less
democratic society. And anyone who wants it to become more democratic,
rather than less, has an interest in learning to understand both its
inequities and how other people are affected by them.
A case in point
might be the findings discussed by Claude Steele, a professor of
psychology at Stanford, in a panel on Friday. His paper reviewed some of
the research on “identity contingencies,” meaning “things you have to
deal with because of your social identity.” One such contingency is what
he called “stereotype threat” — a situation in which an individual
becomes aware of the risk that what you are doing will confirm some
established negative quality associated with your group. And in keeping
with the threat, there is a tendency to become vigilant and defensive.
Steele did not
just have a string of concepts to put up on PowerPoint. He had research
findings on how stereotype threat can affect education. The most
striking involved results from a puzzle-solving test given to groups of
white and black students. When the test was described as a game, the
scores for the black students were excellent — conspicuously higher, in
fact, than the scores of white students. But in experiments where the
very same puzzle was described as an intelligence test, the results were
reversed. The black kids scores dropped by about half, while the graph
for their white peers spiked.
The only
variable? How the puzzle was framed — with distracting thoughts about
African-American performance on IQ tests creating “stereotype threat” in
a way that game-playing did not.
Steele also
cited an experiment in which white engineering students were given a
mathematics test. Just beforehand, some groups were told that Asian
students usually did really well on this particular test. Others were
simply handed the test without comment. Students who heard about their
Asian competitors tended to get much lower scores than the control
group.
Extrapolate
from the social psychologist’s experiments with the effect of a few
innocent-sounding remarks — and imagine the cumulative effect of more
overt forms of domination. The picture is one of a culture that is
profoundly wasteful, even destructive, of the best abilities of many of
its members.
“It’s not easy
for minority folks to discuss these things,” Satya Mohanty told me on
the final day of the colloquium. “But I don’t think we can afford to
wait until it becomes comfortable to start thinking about them. Our
future depends on it. By ‘our’ I mean everyone’s future. How we enrich
and deepen our democratic society and institutions depends on the
answers we come up with now.”
Earlier this year, Oxford
University Press published a major new work on postpositivist theory,
Visible Identities: Race, Gender, and the Self,by Linda Martin
Alcoff, a professor of philosophy at Syracuse University. Several essays
from the book are available at
the author’s
Web site.
A scholar going by the name of Centurian comments following the following
article
"One Economist's Mission to Redeem the Field of Finance," by Robert
Schiller, Chronicle of Higher Education, April 8, 2012 ---
http://chronicle.com/article/Robert-Shillers-Mission-to/131456/
Economics as a "science" is no different than
Sociology, Psychology, Criminal Justice, Political Science, etc.,etc.. To
those in the "hard sciences" [physics, biology, chemistry, mathematics],
these "soft sciences" are dens of thieves. Thieves who have stolen the
"scientific method" and abused it.
These soft sciences all apply the scientific method
to biased and insufficient data sets, then claim to be "scientific", then
assert their opinions and biases as scientific results. They point to
"correlations". Correlations which are made even though they know they do
not know all the forces/factors involved nor the ratio of effect from the
forces/factors.
They know their mathematical formulas and models
are like taking only a few pieces of evidence from a crime scene and then
constructing an elaborate "what happened" prosecution and defense. Yet
neither side has any real idea, other than in the general sense, what
happened. They certainly have no idea what all the factors or human
behaviors were involved, nor the true motives.
Hence the growing awareness of the limitations of
all the quantitative models that led to the financial crisis/financial WMDs
going off.
Take for example the now thoroughly discredited
financial and economic models that claimed validity through the use of the
same mathematics used to make atomic weapons; Monte Carlo simulation. MC
worked on the Manhattan Project because real scientists, who obeyed the laws
of science when it came to using data, were applying the mathematics to a
valid data set.
Economists and Wall Street Quants threw out the
data set disciplines of science. The Quant's of Wall Street and those
scientists who claimed the data proved man made global warming share the
same sin of deception. Why? For the same reason, doing so allowed them to
continue their work in the lab. They got to continue to experiment and "do
science". Science paid for by those with a deep vested financial interest in
the the false correlations proclaimed by these soft science dogmas.
If you take away a child's crayons and give him oil
paints used by Michelangelo, you're not going to get the Sistine Chapel.
You're just going to get a bigger mess.
If Behavioral Finance proves anything it is how far
behind the other Social Sciences economists really are. And if the
"successes" of the Social Sciences are any indication, a lot bigger messes
are waiting down the road.
Centurion
High Hopes Dashed for a Change in Policy of TAR Regarding Commentaries on
Previously Published Research
In a recent merry-go-round of private correspondence with the current Senior
Editor of TAR, Steve Kachelmeier, I erroneously concluded that TAR was relaxing
its policy of discouraging commentaries focused recent papers published in TAR,
including commentaries that focus on having replicated the original studies.
I went so far on the AECM Listserv as to suggest that a researcher replicate
a recent research study reported in TAR and then seek to have the replication
results published in TAR in some form such as a commentary or abstract or as a
full paper.
Steve Kachelmeier was deeply upset by my circulated idea and quickly
responded with a clarification that amounts to flatly denying any change in
policy. Steve sent the following clarification to distribute on the AECM
Listserv and at my Website:
Low Hopes for Less Inbreeding in the Stable of TAR Referees
When browsing some of my 8,000+ comments on the AAA Commons, I ran across this
old tidbit that relates to our more current AECM messaging on journal
refereeing.
I even liked the "Dear Sir, Madame, or Other"
beginning.
I assume that "Other" is for the benefit of Senator Boxer from
California.
Letter From Frustrated Authors,
by R.L. Glass, Chronicle of Higher
Education, May 21, 2009 ---
http://chronicle.com/forums/index.php?topic=60573.0
This heads up was sent to me by Ed Scribner at New Mexico State
Dear Sir, Madame, or Other:
Enclosed is our latest version of Ms.
#1996-02-22-RRRRR, that is the re-re-re-revised revision of our paper. Choke
on it. We have again rewritten the entire manuscript from start to finish.
We even changed the g-d-running head! Hopefully, we have suffered enough now
to satisfy even you and the bloodthirsty reviewers.
I shall skip the usual point-by-point
description of every single change we made in response to the critiques.
After all, it is fairly clear that your anonymous reviewers are less
interested in the details of scientific procedure than in working out their
personality problems and sexual frustrations by seeking some kind of
demented glee in the sadistic and arbitrary exercise of tyrannical power
over hapless authors like ourselves who happen to fall into their clutches.
We do understand that, in view of the misanthropic psychopaths you have on
your editorial board, you need to keep sending them papers, for if they were
not reviewing manuscripts they would probably be out mugging little old
ladies or clubbing baby seals to death. Still, from this batch of reviewers,
C was clearly the most hostile, and we request that you not ask him to
review this revision. Indeed, we have mailed letter bombs to four or five
people we suspected of being reviewer C, so if you send the manuscript back
to them, the review process could be unduly delayed.
Some of the reviewers’ comments we could
not do anything about. For example, if (as C suggested) several of my recent
ancestors were indeed drawn from other species, it is too late to change
that. Other suggestions were implemented, however, and the paper has been
improved and benefited. Plus, you suggested that we shorten the manuscript
by five pages, and we were able to accomplish this very effectively by
altering the margins and printing the paper in a different font with a
smaller typeface. We agree with you that the paper is much better this way.
One perplexing problem was dealing with
suggestions 13–28 by reviewer B. As you may recall (that is, if you even
bother reading the reviews before sending your decision letter), that
reviewer listed 16 works that he/she felt we should cite in this paper.
These were on a variety of different topics, none of which had any relevance
to our work that we could see. Indeed, one was an essay on the
Spanish–American war from a high school literary magazine. The only common
thread was that all 16 were by the same author, presumably someone whom
reviewer B greatly admires and feels should be more widely cited. To handle
this, we have modified the Introduction and added, after the review of the
relevant literature, a subsection entitled “Review of Irrelevant Literature”
that discusses these articles and also duly addresses some of the more
asinine suggestions from other reviewers.
We hope you will be pleased with this
revision and will finally recognize how urgently deserving of publication
this work is. If not, then you are an unscrupulous, depraved monster with no
shred of human decency. You ought to be in a cage. May whatever heritage you
come from be the butt of the next round of ethnic jokes. If you do accept
it, however, we wish to thank you for your patience and wisdom throughout
this process, and to express our appreciation for your scholarly insights.
To repay you, we would be happy to review some manuscripts for you; please
send us the next manuscript that any of these reviewers submits to this
journal.
Assuming you accept this paper, we would
also like to add a footnote acknowledging your help with this manuscript and
to point out that we liked the paper much better the way we originally
submitted it, but you held the editorial shotgun to our heads and forced us
to chop, reshuffle, hedge, expand, shorten, and in general convert a meaty
paper into stir-fried vegetables. We could not – or would not – have done it
without your input.
-- R.L. Glass
Computing Trends,
1416 Sare Road Bloomington, IN 47401 USA
E-mail address:
rglass@acm.org
December 30, 2011 reply from Steve
Kachelmeier
This letter perpetuates the sense that "reviewers"
are malicious outsiders who stand in the way of good scholarship. It fails
to recognize that reviewers are simply peers who have experience and
expertise in the area of the submission. The Accounting Review asks about
600 such experts to review each year -- hardly a small set.
While I have seen plenty of bad reviews in my
editorial experience, I also sense that it is human nature to impose a
self-serving double standard about reviewing. Too many times when we receive
a negative review, the author concludes that this is because the reviewer
does not have the willingness or intelligence to appreciate good scholarship
or even read the paper carefully. But when the same author is asked to
evaluate a different manuscript and writes a negative review, it is because
the manuscript is obviously flawed. Psychologists have long studied
self-attributions, including the persistent sense that when one experiences
a good thing, it is because one is good, and when one experiences a bad
thing, it is because others are being malicious. My general sense is that
manucripts are not as good as we sense they are as authors and are not as
bad as we sense they are as reviewers. I vented on these thoughts in a 2004
JATA Supplement commentary. It was good therapy for me at the time.
The reviewers are us.
Steve
December 31, 2011 reply from Bob Jensen
Hi Steve,
Thank you for that sobering reply.
I will repeat a tidbit that I posted some years back --- it might've been in
reply to a message from you.
When I was a
relatively young PhD and still full of myself, the Senior Editor,
Charlie Griffin, of The Accounting Review sent me a rather
large number of accountics science papers to referee (there weren't
many accountics science referees available 1968-1970). I think it
was at a 1970 AAA Annual Meeting that I inadvertently overheard
Charlie tell somebody else that he was not sending any more TAR
submissions to Bob Jensen because "Jensen rejects every submission."
My point in telling you this is that having only one or two referees
can really be unfair if the referees are still full of themselves.
Bob Jensen
December 31, 2011 reply from Jim Peters
The attribution bias to which Steve refers also
creates an upward (I would say vicious) cycle for research standards. Here
is how it works. When an author gets a negative review, because of the
attribution problem, they also infer that the standards for publication have
gone up (because, they must have since their work is solid). Then, when that
same author is asked to review a paper, they tend to apply the new, higher
standards that they miss-attributed to the recent review they received. A
sort of "they did it to me, I am going to do it to them," but not
vindictively, just in an effort to apply current standards. Of course, the
author of the paper they are reviewing makes their own miss-attribution to
higher standards and, when that author is asked to review a paper, the cycle
repeats. The other psychological phenomena at work here is lack of
self-insight. Most humans have very poor self-insight as to why they do
things. They make emotional decisions and then rationalize them. Thus, the
reviewers involved are probably unaware of what they are doing. Although a
few may indeed be vindictive. The blind review process isn't very blind
given that most papers are shopped at seminars and other outlets before they
are submitted for publication and there tend to some self-serving patterns
in citations. Thus, a certain level of vindictiveness is possible.
When I was a PhD student, I asked Harry Evans to
define the attributes of a good paper in an effort to establish some form of
objective standard I could shoot for. His response was similar to the old
response about pornography. In essence, I know a good paper when I see it,
but I cannot define attributes of a good paper in advance. I may have missed
something in my 20+ years, but I have never seen any effort to establish
written, objective standards for publishability of academic research. So, we
all still are stuck with the cycle where authors try to infer what they
standards are from reviews.
Jim
January 1, 2012 reply from Dan Stone
I've given lots of thought to why peer review, as
now exists in many disciplines (including accounting), so frequently fails
to improve research, and generates so extensive a waste of authorial
resources. After almost thirty years of working within this system, as an
editor, author and reviewer, I offer 10 reasons why peer review, as is often
constructed, frequently fails to improve manuscripts, and often diminishes
their contribution:
1. authors devote thousands of hours to
thoroughly understanding an issue,
2. most reviewers devote a few hours to
understanding the authors' manuscript,
3. most reviewers are asked to review outside
of their primary areas of expertise. For example, today, I am reviewing
a paper that integrates two areas of theory. I know one and not the
other. Hence, reviewers, relative to authors, are almost universally
ignorant relative to the manuscript,
4. reviewers are anonymous, meaning
unaccountable for their frequently idiotic, moronic comments. Editors
generally know less about topical areas than do reviewers, hence idiotic
reviewers comments are generally allowed to stand as fact and truth.
5. reviewers are rewarded for publishing (as
AUTHORS) but receive only the most minimal of rewards for reviewing
(sometimes an acknowledgement from the editor),
6. editors are too busy to review papers, hence
they spend even fewer hours than authors on manuscripts,
7. most editors are deeply entrenched in the
status quo, that is one reason they are selected to be editors. Hence,
change to this deeply flaws systems is glacial if at all
8. reviewers are (often erroneously) told that
they are experts by editors,
9. humans naturally overestimate their own
competence, (called the overconfidence bias),
10 hence, reviewers generally overestimate
their own knowledge of the manuscript.
The result is the wasteful system that is now in
place at most (though certainly not all) journals. There are many easy
suggestions for improving this deeply flawed system -- most importantly to
demand reviewer accountability. I've given citations earlier to this list of
articles citing the deeply flaws state of peer review and suggesting
improvements. But see point #7.
In short, when I speak as a reviewer, where I am
comparatively ignorant, my words are granted the status of absolute truth
but when I speak as an author, where I am comparatively knowledgable, I must
often listen to babbling fools, whose words are granted the status of
absolute truth.
That's a very bad system -- which could be easily
reformed -- but for the entrenched interests of those who benefit from the
status quo. (see the research cited in "The Social Construction of Research
Advice: The American Accounting Association Plays Miss Lonelyhearts" for
more about those entrenched interests).
Best,
Dan S.
January 1, 2011 reply from Bob Jensen
Thanks Dan for such a nice summary. Personal
anecdote - my respect for Dan went way up years ago when he was the editor
and overrode my rejection of a paper. While I stand by my critique of the
paper, Dan had the courtesy to make his case to me and I respected his
judgment. What constitutes "publishable" is highly subjective and in some
cases, we need to lower the rigor bar a little to expose new approaches. As
I recall, I did work with the author of the paper after Dan accepted it to
help clean it up a bit.
Dan - you state that the fixes are relatively easy,
but don't provide details. In my little hyper-optimistic world, a fix would
create an air of cooperation between editors, authors, and reviewers to work
together to extract the best from research and expose it to the general
public. This is about 180 degrees from what I perceive is the current
gatekeeper emphasis on "what can I find to hang a rejection on?"
I saw a study years ago, the reference for I would
have a hell of a time finding again, that tracked the publications in major
journals per PhD in different disciplines in business and over time. For all
disciplines, the rate steady fell over time and accounting had by far the
lowest rate. It would be simple math to calculate the number of articles
published in top journals each year over time, which doesn't seem to
increase, and the number of PhDs in accounting, which does. Simple math may
indicate we have a problem of suppressing good work simply because of a lack
of space.
Jim
January 1, 2011 reply from Steve Kachelmeier
Dan has listed 10 reasons why peer review fails to
improve manuscripts. To the contrary, in my experience, at least for those
manuscripts that get published, I can honestly say that, on average, they
are discernably better after the review process than before. So, warts and
all, I am not nearly as critical of the process in general as are some
others. I will attempt to offer constructive, well-intended replies to each
of Dan's 10 criticisms.
Dan's point 1.: Authors devote thousands of hours
to thoroughly understanding an issue,
SK's counterpoint: I guess I don't understand why
this observation is a reason why reviews fail to improve manuscripts. Is the
implication that, because authors spend so much time understanding an issue,
the author's work cannot possibly be improved by mere reviewers?
2. Most reviewers devote a few hours to
understanding the authors' manuscript,
SK's counterpont: This seems a corollary to the
oft-heard "lazy reviewer" complaint. Let us concede that reviewers sometimes
(or even often) do not spend as much time on a manuscript as we would like
to see. Even if this is true, I would submit that the reviewer spends more
time on the paper than does the typical reader, post publication. So if the
reviewer "doesn't get it," chances are that the casual reader won't get it
either.
3. Most reviewers are asked to review outside of
their primary areas of expertise. For example, today, I am reviewing a paper
that integrates two areas of theory. I know one and not the other. Hence,
reviewers, relative to authors, are almost universally ignorant relative to
the manuscript,
SK's counterpoint: As I see it, the editor's
primary responsibility is to avoid this criticism. I can honestly say that
we did our best at The Accounting Review during my editorship to choose
qualified reviewers. It is easier said than done, but I employed a 20-hour
RA (and my understanding is that Harry Evans does the same) simply to
research submissions in a dispassionate manner and suggest names of
well-qualified potential reviewers with no obvious axes to grind. In a
literal sense, it is of course true that the author knows the most about the
author's research. But that, to me, does not justifiy the assertion that
"most reviewrs are asked to review outside of their primary areas of
expertise." That is, Dan's anecdote notwithstanding, I simply disagree with
the assertion. Also, a somewhat inconvenient truth I have uncovered as
editor is that too much reviewer expertise is not necessarily a good thing
for the author. As in most things, moderation is the key.
4. reviewers are anonymous, meaning unaccountable
for their frequently idiotic, moronic comments. Editors generally know less
about topical areas than do reviewers, hence idiotic reviewers comments are
generally allowed to stand as fact and truth.
SK's counterpoint: To say that reviewers are
"idiotic" and "moronic" is to say that professors in general are idiotic and
moronic. After all, who do you think does the reviews? To be sure, authors
often perceive a reviewer's comments as "idiotic and moronic." Similarly,
have you ever reviewed a manuscript that you perceived as "idiotic and
moronic"? This is self-serving bias on self-attributions, plain as simple.
As I've said before, my general sense is that the reviews we receive are not
as bad as we think, and the manuscripts we submit are not as good as we
think. As to the assertion that "editors generally know less about topical
areas than do reviewers," of course that is true (in general), which is why
we have a peer review system!
5. Reviewers are rewarded for publishing (as
AUTHORS) but receive only the most minimal of rewards for reviewing
(sometimes an acknowledgement from the editor),
SK's counterpoint: I'm reluctant to tag the word
"counterpoint" on this one, because I agree that the reward system is
somewhat warped when it comes to reviewing. Bad reviewers get off the hook
(because editors wise-up and stop asking them), so they can then sometimes
free-ride on the system. Conversely, good reviewers get rewarded with many
more review requests, proving that no good deed goes unpunished. At least I
tried to take baby steps to remedy this problem by publishing the names of
the nearly 500 ad hoc reviewers TAR asks each year, and in addition,
starting in November 2011, I started publishing an "honor roll" of our most
prolific and timely reviewers.
6. Editors are too busy to review papers, hence
they spend even fewer hours than authors on manuscripts,
SK's counterpoint: Why is this a criticisim of the
review process? It is precisely because editors have limited time that the
editor delegates much of the evalation process to experts in the area of the
submission. Consider the alternatives. An alternative that is not on the
table is for the editor to pour in many hours/days/weeks on each submission,
as there are only 24 hours in the day. So that leaves the alternative of a
dictatorial editor who accepts whatever fits the editor's taste and rejects
whatever is inconsistent with that taste, reviewers be damned. This is the
"benevolent dictator" model to those who like the editor's tastes, but as I
said in my November 2011 TAR editorial, the editorial dictator who is
benevolent to some will surely be malevolent to others. Surely there is a
critical role for editorial judgment, particularly when the reviewers are
split, but a wholesale substitution of the editor's tastes in lieu of
evaluations by experts would make things worse, in my opinion. More
precisely, some would clearly be better off under such a system, but many
others would be worse off.
7. Most editors are deeply entrenched in the status
quo, that is one reason they are selected to be editors. Hence, change to
this deeply flaws systems is glacial if at all
SK's counterpoint: Is the implication here that
editors are more entrenched in the "status quo" than are professors in
general? If that is true, then a peer review system that forces the editor's
hand by holding the editor accountable to the peer reviewers would serve as
a check and balance on the editor's "entrenchment," right? So I really don't
see why this point is a criticism of the review process. If we dispensed
with peer review and gave editors full power, then "entrenched" editors
could perpetuate their entrenched tastes forever.
8. Reviewers are (often erroneously) told that they
are experts by editors,
SK's counterpoint: Sometimes, as TAR editor, I
really wished I could reveal reviewer names to a disgruntled author, if only
to prove to the person that the two reviewers were chosen for their
expertise and sympathy to both the topic and the method of the submission.
But of course I could not do that. A system without reviewer anonymity could
solve that problem, but would undoutedly introduce deeper problems of
strategic behavior and tit-for-tat rewards and retaliations. So reviews are
anonymous, and authors can persist in their belief that the reviewer must be
incompetent, because otherwise how could the reviewer possibly not like my
submission. But let me back off here and add that many reviews are less
constructive and less helpful than an editor would like to see. Point taken.
That is why, in my opinon, a well-functioning peer review system must
solicit two expert opinions. When the reviewers disagree, that is when the
editor must step in and exercise reasoned judgment, often on the side of the
more positive reviewer. Let's just say that if I rejected every manuscript
with split reviews over the past three years, TAR would have had some very
thin issues.
9. Humans naturally overestimate their own
competence, (called the overconfidence bias),
SK's counterpoint: Yes, and this is why we tend to
be so impressed with our own research and so critical of review reports.
10 Hence, reviewers generally overestimate their
own knowledge of the manuscript.
SK's counterpoint: Let's grant this one. But, if I
may borrow from Winston Churchill, "Democracy is the worst form of
government except for all those other forms that have been tried from time
to time." Is a peer review system noisy? Absolutely! Are peer reviews always
of high quality? No way! Are reviews sometimes petty and overly harsh? You
bet! But is a peer review system better than other forms of journal
governance, such as editorial dictatorship or a "power" system that lets the
most powerful authors bully their way in? I think so. Editors have very
important responsibilities to choose reviewers wisely and to make tough
judgment calls at the margin, especially when two reviewers disagree. But
dispensing with the system would only make things worse, in my opinion. I
again return to the most fundamental truism of this process -- the reviewers
are us. If you are asking that we dispense with these "idiotic, moronic"
reports, than what you are really asking is that professors have less
control over the process to which professors submit. Now that I'm back to
being a regular professor again, I'm unwilling to cede that authority.
Just my two cents. Happy New Year to all,
Steve K.
January 1, 2012 reply from Bob Jensen
Hi Dan,
My biggest complaint with the refereeing process as we know it is that
anonymous referees are not accountable for their decisions. I always find it
odd that in modern times we deplore tenure black balling where senior
faculty can vote secretly and anonymously to deny tenure to a candidate
without having to justify their reasons. And yet when it comes to rejecting
a candidate's attempt to publish, we willingly accept a black ball system in
the refereeing processes.
Granted, we hope that referees will communicate reasons for rejection,
but there's no requirement to do so, and many of the reasons given are vague
statements such as "this does not meet the quality standards of the
journal."
More importantly, the referees are anonymous which allows them to be
superficial or just plain wrong without having to be accountable.
On the other side of the coin I can see reasons for anonymity. Otherwise
the best qualified reviewers may reject invitations to become referees
because they don't want to be personally judged for doing the journal a
favor by lending their expertise to the refereeing process. Referees should
not be forced into endless debates about the research of somebody else.
I've long advocated a compromise. I think that referee reports should be
anonymous. I also think referee reports along with author responses should
be made available in electronic form in an effort to make the entire
refereeing process more transparent (without necessarily naming the
referees). For example, each published Accounting Review paper could be
linked to the electronic file of referee, author, and editor comments
leading up to the publication of the article.
Rejected manuscripts are more problematic. Authors should have discretion
about publishing their working papers along with referee and editor
communications. However, I think the practice of electronic publishing of
rejected papers along with referee communications should become a more
common practice. One of the benefits might be to make referees be more
careful when reviewing manuscripts even if their rejection reports do not
mention names of the referees.
The AAA Executive Committee is usually looking for things that can be
done to improve scholarship and research among AAA members. One thing I
propose is that the AAA leadership take on the task of how to improve the
refereeing process of all refereed AAA journals. One of the objectives
concerns ways of making the refereeing process more transparent.
Lastly, I think the AAA leadership should work toward encouraging
commentaries on published working papers that indirectly allow scholars to
question the judgments of the referees and authors. As it stands today, AAA
publications are not challenged like they are in many journals of other
scholarly disciplines ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm#TARversusAMR
Respectfully,
Bob Jensen
Hi Dan, Jim, and Steve and others,
One added consideration in this "debate" about top accountics science
research journal refereeing is the inbreeding that has taken in a very large
stable of referees that virtually excludes practitioners. Ostensibly this is
because practitioners more often than not cannot read the requisite equations in
submitted manuscripts. But I often suspect that this is also because of fear
about questions and objections that practitioner scholars might raise in the
refereeing process.
Sets of accountics science referees are very inbred largely because editors
do not invite practitioner "evaluators" into the gene pool. Think of how things
might've been different if practitioner scholars suggested more ideas to
accountics science authors and, horrors, demanded something that some
submissions be more relevant to the professions.
Think of how Kaplan's criticism of accounting science research publications
might've changed if accountics science referees were not so inbred in having
accountics science "faculty is as evaluators
(referees) of, but not creators or originators of,
business practice. (Pfeffer 2007, 1335)."
"Accounting Scholarship that Advances Professional Knowledge and Practice,"
AAA Presidential Scholar Address by Robert S. Kaplan, The Accounting Review,
March 2011, pp. 372-373 (emphasis added)
I am less pessimistic than Schön about whether
rigorous research can inform professional practice (witness the important
practical significance of the Ohlson accounting-based valuation model and
the Black-Merton-Scholes options pricing model), but I concur with the
general point that academic scholars spend too much time at the top of
Roethlisberger’s knowledge tree and too little time performing systematic
observation, description, and classification, which are at the foundation of
knowledge creation. Henderson �1970, 67–68� echoes the benefits from a more
balanced approach based on the experience of medical professionals:
both theory and practice are necessary
conditions of understanding, and the method of Hippocrates is the only
method that has ever succeeded widely and generally. The first element
of that method is hard, persistent, intelligent, responsible,
unremitting labor in the sick room, not in the library … The second
element of that method is accurate observation of things and events,
selection, guided by judgment born of familiarity and experience, of the
salient and the recurrent phenomena, and their classification and
methodical exploitation. The third element of that method is the
judicious construction of a theory … and the use thereof … [T]he
physician must have, first, intimate, habitual, intuitive familiarity
with things, secondly, systematic knowledge of things, and thirdly an
effective way of thinking about things.
More recently, other observers of business
school research have expressed concerns about the gap that has opened up in
the past four decades between academic scholarship and professional
practice.
Examples include: Historical role of business
schools and their faculty is as
evaluators of, but not creators or originators of, business practice.
(Pfeffer 2007, 1335) Our journals are replete with an examination of
issues that no manager would or should ever care about, while concerns
that are important to practitioners are being ignored. (Miller et al.
2009, 273)
In summary, while much has been accomplished during
the past four decades through the application of rigorous social science
research methods to accounting issues, much has also been overlooked. As I
will illustrate later in these remarks, we have missed big opportunities to
both learn from innovative practice and to apply innovations from other
disciplines to important accounting issues. By focusing on these
opportunities, you will have the biggest potential for a highly successful
and rewarding career.
Integrating Practice and Theory: The Experience
of Other Professional Schools
Other professional schools, particularly medicine, do not disconnect
scholarly activity from practice. Many scholars in medical and public health
schools do perform large-scale statistical studies similar to those done by
accounting scholars. They estimate reduced-form statistical models on
cross-sectional and longitudinal data sets to discover correlations between
behavior, nutrition, and health or sickness. Consider, for example,
statistical research on the effects of smoking or obesity on health, and of
the correlations between automobile accidents and drivers who have consumed
significant quantities of alcoholic beverages. Such large-scale statistical
studies are at the heart of the discipline of epidemiology.
Some scholars in public health schools also
intervene in practice by conducting large-scale field experiments on real
people in their natural habitats to assess the efficacy of new health and
safety practices, such as the use of designated drivers to reduce
alcohol-influenced accidents. Few academic accounting scholars, in contrast,
conduct field experiments on real professionals working in their actual jobs
(Hunton and Gold [2010] is an exception). The large-scale statistical
studies and field experiments about health and sickness are invaluable, but,
unlike in accounting scholarship, they represent only one component in the
research repertoire of faculty employed in professional schools of medicine
and health sciences.
Many faculty in medical schools (and also in
schools of engineering and science) continually innovate. They develop new
treatments, new surgeries, new drugs, new instruments, and new radiological
procedures. Consider, for example, the angiogenesis innovation, now
commercially represented by Genentech’s Avastin drug, done by Professor
Judah Folkman at his laboratories in Boston Children’s Hospital (West et al.
2005). Consider also the dozens of commercial innovations and new companies
that flowed from the laboratories of Robert Langer at MIT (Bowen et al.
2005) and George Whiteside at Harvard University (Bowen and Gino 2006).
These academic scientists were intimately aware of gaps in practice that
they could address and solve by applying contemporary engineering and
science. They produced innovations that delivered better solutions in actual
clinical practices. Beyond contributing through innovation, medical school
faculty often become practice thought-leaders in their field of expertise.
If you suffer from a serious, complex illness or injury, you will likely be
referred to a physician with an appointment at a leading academic medical
school. How often, other than for expert testimony, do leading accounting
professors get asked for advice on difficult measurement and valuation
issues arising in practice?
One study (Zucker and Darby 1996) found that
life-science academics who partner with industry have higher academic
productivity than scientists who work only in their laboratories in medical
schools and universities. Those engaged in practice innovations work on more
important problems and get more rapid feedback on where their ideas work or
do not work.
These examples illustrate that some of the best
academic faculty in schools of medicine, engineering, and science, attempt
to improve practice, enabling their professionals to be more effective and
valuable to society. Implications for Accounting Scholarship To my letter
writer, just embarking on a career as an academic accounting professor, I
hope you can contribute by attempting to become the accounting equivalent of
an innovative, worldclass accounting surgeon, inventor, and thought-leader;
someone capable of advancing professional practice, not just evaluating it.
I do not want you to become a “JAE” �Just Another Epidemiologist �. My
vision for the potential in your 40� year academic career at a professional
school is to develop the knowledge, skills, and capabilities to be at the
leading edge of practice. You, as an academic, can be more innovative than a
consultant or a skilled practitioner. Unlike them, you can draw upon
fundamental advances in your own and related disciplines and can integrate
theory and generalizable conceptual frameworks with skilled practice. You
can become the accounting practice leader, the “go-to” person, to whom
others make referrals for answering a difficult accounting or measurement
question arising in practice.
But enough preaching! My teaching is most effective
when I illustrate ideas with actual cases, so let us explore several
opportunities for academic scholarship that have the potential to make
important and innovative contributions to professional practice.
Continued in article
Added Jensen Comment
Of course I'm not the first one to suggest that accountics science referees are
inbred. This has been the theme of other AAA presidential scholars (especially
Anthony Hopwood), Paul Williams, Steve Zeff, Joni Young, and many, many others
that accountics scientists have refused to listen to over past decades.
"The Absence of Dissent," by Joni J. Young,
Accounting and the Public Interest 9 (1), 2009 ---
Click Here
ABSTRACT:
The persistent malaise in accounting research continues to resist remedy.
Hopwood (2007) argues that revitalizing academic accounting cannot be
accomplished by simply working more diligently within current paradigms.
Based on an analysis of articles published in Auditing: A Journal of
Practice & Theory, I show that this paradigm block is not confined to
financial accounting research but extends beyond the work appearing in the
so-called premier U.S. journals. Based on this demonstration I argue that
accounting academics must tolerate (and even encourage) dissent for
accounting to enjoy a vital research academy. ©2009 American Accounting
Association
We could try to revitalize accountics scientists by expanding the gene pools
of inbred referees.
The problem is when the model created to represent
reality takes on a life of its own completely detached from the reality that it
is supposed to model that nonsense can easily ensue.
Was it Mark Twain who wrote: "The criterion of
understanding is a simple explanation."?
As quoted by Martin Weiss in a comment to the article below.
But a lie gets halfway around the world while the
truth is still tying its shoes
Mark Twain as quoted by PKB (in Mankato, MN) in a comment to the article below.
"US Net Investment Income," by Paul Krugman, The New York Times,
December 31, 2011 ---
http://krugman.blogs.nytimes.com/2011/12/31/us-net-investment-income/
Especially note the cute picture.
December 31, 2011 Comment by Wendell Murray
http://krugman.blogs.nytimes.com/2011/12/31/i-like-math/#postComment
Mathematics, like word-oriented languages, uses
symbols to represent concepts, so it is essentially the same as
word-oriented languages that everyone is comfortable with.
Because mathematics is much more precise and in most ways much simpler than
word-oriented languages, it is useful for modeling (abstraction from) of the
messiness of the real world.
The problem, as Prof. Krugman notes, is when the model created to represent
reality takes on a life of its own completely detached from the reality that
it is supposed to model that nonsense can easily ensue.
This is what has happened in the absurd conclusions often reached by those
who blindly believe in the infallibility of hypotheses such as the rational
expectations theory or even worse the completely peripheral concept of
so-called Ricardian equivalence. These abstractions from reality have value
only to the extent that they capture the key features of reality. Otherwise
they are worse than useless.
I think some academics and/or knowledgeless distorters of academic theories
in fact just like to use terms such as "Ricardian equivalence theorem"
because that term, for example, sounds so esoteric whereas the theorem
itself is not much of anything.
Ricardian Equivalence ---
http://en.wikipedia.org/wiki/Ricardian_equivalence
Jensen Comment
One of the saddest flaws of accountics science archival studies is the repeated
acceptance of the CAPM mathematics allowing the CAPM to "represent reality on a
life of its own" when in fact the CAPM is a seriously flawed representation of
investing reality ---
http://faculty.trinity.edu/rjensen/theory01.htm#AccentuateTheObvious
At the same time one of the things I dislike about the exceedingly left-wing
biased, albeit brilliant, Paul Krugman is his playing down of trillion dollar
deficit spending and his flippant lack of concern about $80 trillion in unfunded
entitlements. He just turns a blind eye toward risks of Zimbabwe-like inflation.
As noted below, he has a Nobel Prize in Economics but
"doesn't command respect in the profession".
Put another way, he's more of a liberal preacher than an economics teacher.
Paul Krugman ---
http://en.wikipedia.org/wiki/Paul_Krugman
Economics and policy recommendations
Economist and former
United States Secretary of the Treasury
Larry Summers has stated Krugman has a tendency to
favor more extreme policy recommendations because "it’s much more
interesting than agreement when you’re involved in commenting on rather than
making policy."
According to Harvard professor of economics
Robert Barro, Krugman "has never done any work in
Keynesian macroeconomics" and makes arguments that are politically
convenient for him.Nobel laureate
Edward Prescott has charged that Krugman "doesn't
command respect in the profession", as "no
respectable macroeconomist" believes that
economic stimulus works, though the number of
economists who support such stimulus is "probably a majority".
Bob Jensen's critique of analytical models in accountics science (Plato's
Cave) can be found at
http://faculty.trinity.edu/rjensen/TheoryTAR.htm#Analytics
Bob Jensen's threads on higher education controversies are at
http://www.trinity.edu/rjensen/HigherEdControversies.htm
Clarification of Policy With Respect to Publishing in The
Accounting Review (TAR)
by Steve Kachelmeier, Senior Editor, January 8, 2010
|
I have become aware of a recent post by Bob
Jensen challenging readers to put me “to the test” to see if The
Accounting Review really is open to publishing replications. I
would like to comment on my view (and experience) regarding
replications, but first, I cannot help but to comment on the belief
implicit in statements such as Bob’s that journals have policies
controlled by “gatekeepers” regarding what we will or will not
publish.
As I have tried to explain in many public
forums over the past several months, journals -- and particularly
association-based journals such as The Accounting Review --
are not controlled by editorial gatekeepers so much as they are
controlled by scholarly communities. If you want to know what a
journal will publish, do not ask the editor or think that you are
putting the editor “to the test.” Rather, take your case to two
experts known as “Reviewer A” and “Reviewer B.” And just who are
these reviewers? For the first time, to my knowledge, The
Accounting Review has published the names of all 574 people who
kindly submitted one or more manuscript reviews to TAR during
the journal’s fiscal year from June 1, 2008 to May 31, 2009. These
include 124 members of the Editorial Advisory and Review Board
(named in the inside cover pages) plus an additional 450 experts who
served as ad hoc reviewers and who are thanked by name in an
appendix to the Annual Report and Editorial Commentary published in
the November 2009 issue. The reader who scans the many pages of
names in this appendix will see individuals from a wide variety of
topical and methodological interests and from a wide variety of
backgrounds and affiliations. The “gatekeepers” are us.
From the experience of reading several hundred
reviews submitted by these experts, I can attest that the most
common reason a reviewer recommends rejection is the perception that
a submitted manuscript does not offer a sufficient incremental
contribution to justify publication in The Accounting Review.
This observation has important implications for Professor Jensen’s
passion about publishing replications. Yes, we want to see
integrity in research, but we also want to see interesting and
meaningful incremental contributions. The key to a successful
replication, if the goal is a top-tier publication, is to do more
than merely repeat another author’s work. Rather, one must advance
that work, extending the original insights to new settings if the
replication corroborates the earlier findings, and investigating the
reasons for any differences if the replication does not corroborate
earlier findings. The Accounting Review publishes
replications of those varieties on a regular basis.
In an analogy I will borrow from an article
written by Nobel Laureate Vernon Smith, if one wants to replicate my
assertion that it is currently 11:03 a.m., it is best not to simply
ask to see my watch to confirm that I read it correctly. Rather,
look at your own watch. If we agree, we learn something about the
generality and hence the validity of my assertion. If we disagree,
you can help us investigate why.
Steven Kachelmeier
Senior Editor, The Accounting Review |
Steve's 2010 Update on TAR ---
http://www.cs.trinity.edu/~rjensen/temp/TheoryAnnual
ReportTAR_2010.pdf
Jensen Comment
My reaction is that the Senior Editor of TAR has extreme power on deciding
whether or not to encourage submissions in the form of commentaries
and short abstracts of replication studies. It is my understanding that Steve himself decided, when he
became Senior Editor, not to publish anything other than original research
papers. I assume anything like a short commentary is not even sent out for
review since Steve told me that he decided not to publish commentaries in TAR.
Consider any one the many lab experiments published in TAR while Steve was
the Senior Editor. Where is there any evidence of any independent replication? My contention is that requiring "incremental contributions"
as a necessary condition for publication absolutely discourages replications
that are so vital to scientific inquiry. Decisions regarding tenure, promotion,
and performance compensation in the academy rely very heavily on publication of
research in top journals. If replication studies take time, effort, and
resources they are likely to be avoided if there's only a miniscule chance of
publication.
Steve's 2010 Update on TAR ---
http://www.cs.trinity.edu/~rjensen/temp/TheoryAnnual
ReportTAR_2010.pdf
"Case Study Research in Accounting," by David J. Cooper and Wayne
Morgan, Accounting Horizons 22 (2), 159 (2008) ---
http://link.aip.org/link/ACHXXX/v22/i2/p159/s1
SYNOPSIS: We describe case study research and
explain its value for developing theory and informing practice. While
recognizing the complementary nature of many research methods, we stress the
benefits of case studies for understanding situations of uncertainty,
instability, uniqueness, and value conflict. We introduce the concept of
phronesis—the analysis of what actions are practical and rational in a
specific context—and indicate the value of case studies for developing, and
reflecting on, professional knowledge. Examples of case study research in
managerial accounting, auditing, and financial accounting illustrate the
strengths of case studies for theory development and their potential for
generating new knowledge. We conclude by disputing common misconceptions
about case study research and suggesting how barriers to case study research
may be overcome, which we believe is an important step in making accounting
research more relevant. ©2008 American Accounting Association
References citing The Accounting Review (3 references out of 89)
---
http://aaapubs.aip.org/getabs/servlet/GetabsServlet?prog=normal&id=ACHXXX000022000002000159000001&idtype=cvips&gifs=yes
Case
Chow, C. W. 1983. The impacts of accounting
regulation on bondholder and shareholder wealth: The case of the securities
acts. The Accounting Review 58 (3): 485–520.
Critical Comments About Accountics Science Dominance of Accounting
Research (not a case)
Hopwood, A. G. 2007. Whither accounting
research?
The Accounting Review 82 (5): 1365–1374.
Field Study
Merchant, K., and J-F. Manzoni. 1989. The
achievability of budget targets in profit centers: A field study. The
Accounting Review 64 (3): 539–558.
Jensen Comment
Firstly, I think this article is living proof of how slow the process can be in
accounting research between the submission of an article and its eventual
publication:
Submitted January 2005; accepted January 2008; published 12 June 2008
Of course delays can be caused by the authors as well as the referees.
Secondly, the above article demonstrates that case researchers must be very
discouraged about submitting case research to The Accounting Review
(TAR). The 89 references to the Cooper and Morgan article are mostly to
published accounting cases and occasional field studies. From TAR they cite only
one 1983 case and one 1989 field study. There have been some cases and field
studies published in TAR since the Cooper and Morgan paper was published by
Accounting Horizons in 2008. The following outcomes are reported by TAR
Senior Editor Steve Kachelmeier 2009-2010:
2009: Seven cases and field studies were submitted to TAR and Zero were
published by TAR
2010: Steve stopped reporting on cases and field study submissions, but he did
report that 95% accepted submissions were analytical, empirical-archival, and
experimental. The other 5% are called "Other" and presumably include accounting
history, normative, editorial, death tributes, cases, field studies, and
everything else.
I think it is safe to conclude that there's epsilon incentive for case
researchers to submit their cases for publication in TAR, a sentiment that seems
to run throughout Bob Kaplan's 2010 Presidential Address to the AAA membership:
Accounting Scholarship that Advances Professional Knowledge and Practice
 Robert
S. Kaplan
Robert
S. Kaplan
The Accounting Review 86 (2), 367 (2011) Full Text: [ PDF (166
kB) ] Order
Document
In October 2011 correspondence on the AECM, Steve Kachelmeier wrote the
following in response to Bob Jensen's contention that case method research is
virtually not acceptable to this generation of TAR referees:
A "recent TAR editor's" reply:
Ah, here we go again -- inferring what a journal
will publish from its table of contents. Please understand that this is
inferring a ratio by looking at the numerator. One would hope that academics
would be sensitive to base rates, but c'est la vie.
To be sure, The Accounting Review receives (and
publishes) very few studies in the "case and field research" category. Such
researchers may well sense that TAR is not the most suitable home for their
work and hence do not submit to TAR, despite my efforts to signal otherwise
by appointing Shannon Anderson as a coeditor and current Senior Editor Harry
Evans' similar efforts in appointing Ken Merchant as a coeditor. Moreover,
we send all such submissions to case and field based experts as reviewers.
So if they get rejected, it is because those who do that style of research
recommend rejection.
That said, to state that "the few cases that are
submitted to TAR tend to be rejected" is just plain erroneous. Our Annual
Report data consistently show that TAR's percentage of field and case-based
research acceptances (relative to total acceptances) consistently exceeds
TAR's percentage of field and case submissions (relative to total
submissions). To find a recent example, I grabbed the latest issue
(September 2011) and noted the case study on multiperiod outsourcing
arrangements by Phua, Abernethy, and Lillis. They conduct and report the
results of "semi-structured interviews across multiple field sites" (quoted
from their abstract). Insofar as they also report some quantitative data
from these same field sites, you might quibble with whether this is a "pure"
study in this genre, but the authors themselves characterize their work as
adopting "the multiple case study method" (p. 1802).
Does Phua et al. (2011) qualify? My guess is that
Bob would probably answer that question with some reference to replications,
as that seems to be his common refrain when all else fails, but I would hope
for a more substantive consideration of TAR's supposed bias. Now that I
think about it, though my reference to replications was sarcastic (couldn't
help myself), it just struck me that site-specific case studies are perhaps
the least replicable form of resaerch in terms of the "exacting" replication
that Bob Jensen demands of other forms of scientific inquiry. What gives?
Another interesting case/field study is coming up
in the November 2011 issue. It is by Campbell, Epstein, and Martinez-Jerez,
and it uses case- based resaerch techniques to explore the tradeoffs between
monitoring and employee discretion in a Las Vegas casino that agreed to
cooperate with the researchers. Stay tuned.
Best,
Steve
Firstly, I could not find evidence to support Steve's claim that " field and
case-based research acceptances (relative to total acceptances) consistently
exceeds TAR's percentage of field and case submissions (relative to total
submissions). " Perhaps he can enlighten us on this claim.
The Phua et al. (2011) paper says that it is a "multiple case study," but I
view it as an survey study of Australian companies. I would probably call it
more of a field survey using interviews. More importantly, what the authors call
"cases" do not meet what I consider cases method research cases. No "case" is
analyzed in depth beyond questions about internal controls leading to the
switching of suppliers. The fact that that statistical inferences could not be
drawn does not turn a study automatically into a case research study. For more
details about what constitutes case method research and teaching go to
http://faculty.trinity.edu/rjensen/000aaa/thetools.htm#Cases
As to replications, I'm referring to accountics science studies of the
empirical-archival and experimental variety where the general inference that
these are "scientific studies." There are very few accountics science research
studies are replicated according to The IAPUC Gold Book standards.
Presumably a successful replication "reproduces" exactly the same outcomes
and authenticates/verifies the original research. In scientific research, such
authentication is considered extremely important. The IAPUC Gold Book
makes a distinction between reproducibility and repeatability at
http://www.iupac.org/goldbook/R05305.pdf
For purposes of this message, replication, reproducibility, and repeatability
will be viewed as synonyms.
This message does not make an allowance for "conceptual replications" apart
from "exact replications," although such refinements should be duly noted ---
http://www.jasnh.com/pdf/Vol6-No2.pdf
This message does have a very long quotation from a study by Watson et al.
(2008) that does elaborate on quasi-replication and partial-replication. That
quotation also elaborates on concepts of
external versus
internal validity grounded in the book:
Cook, T. D., & Campbell, D. T. (1979).
Quasi-experimentation: Design & analysis
issues for field settings. Boston:
Houghton Mifflin Company.
I define an "extended study" as one which may have similar hypotheses but
uses non-similar data sets and/or non-similar models. For example, study of
female in place of male test subjects is an extended study with different data
sets. An extended study may vary the variables under investigation or change the
testing model structure such as changing to a logit model as an extension of a
more traditional regression model.
Extended studies that create knew knowledge are not replications in terms of
the above definitions, although an extended study my start with an exact
replication.
Case and Field Studies
Replication is not a major issue in studies that do not claim to be scientific.
This includes case studies that are generally a sample of one that can hardly be
deemed scientific.
ROBERT S. KAPLAN and DAVID P. NORTON , The Execution Premium: Linking
Strategyto Operations for Competitive Advantage �Boston, MA: Harvard Business
Press, 2008,ISBN 13: 978-1-4221-2116-0, pp. xiii, 320.
If you are an academician who believes in empirical
data and rigorous statistical analysis, you will find very little of it in
this book. Most of the data in this book comes from Harvard Business School
teaching cases or from the consulting practice of Kaplan and Norton. From an
empirical perspective, the flaws in the data are obvious. The sample is
nonscientific; it comes mostly from opportunistic interventions. It is a bit
paradoxical that a book which is selling a rational-scientific methodology
for strategy development and execution uses cases as opposed to a matched or
paired sample methodology to show that the group with tight linkage between
strategy execution and operational improvement has better results than one
that does not. Even the data for firms that have performed well with a
balanced scorecard and other mechanisms for sound strategy execution must be
taken with a grain of salt.
Bob Jensen has a knee jerk, broken record reaction to accountics scientists
who praise their own "empirical data and rigorous statistical analysis." My
reaction to them is to show me the validation/replication of their "empirical
data and rigorous statistical analysis." that is replete with missing variables
and assumptions of stationarity and equilibrium conditions that are often
dubious at best. Most of their work is so uninteresting that even they don't
bother to validate/replicate each others' research ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
In fairness to Steve and previous TAR editors over the past three decades, I
think it is not usually the editors themselves that are rejecting the case
submissions. Instead we've created a generation of "accountics scientist"
referees who just do not view case method research as legitimate research for
TAR. These referees fail to recognize that the purpose of case method research
is more one of discovery than hypothesis testing.
The following is a quote from the 1993 American Accounting
Association President’s Message by Gary Sundem,
Although empirical
scientific method has made many positive contributions to accounting
research, it is not the method that is likely to generate new theories,
though it will be useful in testing them. For example, Einstein’s theories
were not developed empirically, but they relied on understanding the
empirical evidence and they were tested empirically. Both the development
and testing of theories should be recognized as acceptable accounting
research.
"President’s Message," Accounting Education News 21 (3). Page 3.
Case method research is one of the non-scientific research methods intended
for discovery of new theories. Years ago case method research was published in
TAR, but any cases appearing in the past 30 years are mere tokens that slipped
through the refereeing cracks.
My bigger concern is that accountics scientists (including most TAR referees)
are simply ignoring their scholarly critics like Joni Young, Greg Waymire,
Anthony Hopwood, Bob Kaplan, Steve Zeff, Mike Granof, Al Arens,
Bob Anthony, Paul Williams, Tony Tinker, Dan Stone, Bob Jensen, and probably
hundreds of other accounting professors and students who agree with the claim
that "There's an absence of dissent in the publication of TAR articles?"
We
fervently hope that the research pendulum will soon swing back from the narrow
lines of inquiry that dominate today's leading journals to a rediscovery of the
richness of what accounting research can be.
For that to occur, deans and the current generation of academic accountants must
give it a push.
"Research
on Accounting Should Learn From the Past"
by Michael H. Granof and Stephen A. Zeff
Chronicle of Higher Education, March 21, 2008
I will not attribute the above conclusion to Mike Granof since Steve Kachelmeier
contends this is not really the sentiment of his colleague Mike Granof. Thus we
must assume that the above conclusion to the above publication is only the
sentiment of coauthor Steve Zeff.
October 17. 2011 reply
from Steve Kachelmeier
Bob said that TAR stopped reporting case and field
study data in 2010, but that is not accurate. For 2010, please see Table 3,
Panel B of TAR's Annual Report, on p. 2183 of the November 2010 issue. The
2011 Report to be published in the November 2011 issue (stay tuned) also
reports comprehensive data for the three-year period from June 1, 2008 to
May 31, 2011. Over this period, TAR evaluated 16 unique files that I
categorized as "case or field studies," comprising 1.0% of the 1,631 unique
files we considered over this period. TAR published (or accepted for future
publication) 5 of the 16. As a percentage of the 222 total acceptances over
this period, 5 case/field studies comprise 2.3% of the accepted articles. So
this variety of research comprises 1.0% of our submissions and 2.3% of our
acceptances. The five acceptances over my editorial term are as follows:
Hunton and Gold, May 2010 (a field experiment)
Bol, Keune, Matsumura, and Shin, November 2010
Huelsbeck, Merchant, and Sandino, September 2011
Phua, Abernethy, and Lillis, September 2011
Campbell, Epstein, and Martinez-Jerez, forthcoming November 2011
I categorized these five as case/field studies
because they are each characterized by in-depth analysis of particular
entities, including interviews and inductive analysis. Bob will likely
counter (correctly) that these numbers are very small, consistent with his
assertion that many field and case researchers likely do not view TAR as a
viable research outlet. However, my coeditor Shannon Anderson's name (an
accomplished field researcher) has been on the inside cover of each issue
over the course of my editorial term, and current Senior Editor Harry Evans
has similarly appointed Ken Merchant as a coeditor. I am not sure how much
more explicit one can be in providing a signal of openness, save for
commissioning studies that bypass the regular review process, which I do not
believe is appropriate. That is, a "fair game" across all submissions does
not imply a free ride for any submission.
I must also reiterate my sense that there is a
double standard in Bob's lament of the lack of case and field studies while
he simultaneously demands "exacting" (not just conceptual) replications of
all other studies. It is a cop out, in my opinion, to observe that case and
field studies are not "scientific" and hence should not be subject to
scientific scrutiny. The field researchers I know, including those of the
qualitative variety, seem very much to think of themselves as scientists. I
have no problem viewing case and field research as science. What I have a
problem with is insisting on exact replications for some kinds of studies
but tolerating the absence of replicability for others.
Best,
Steve
October 18, 2011 reply from Bob Jensen
Thank you Steve,
It appears that in the forthcoming November 2011 where the next TAR
Annual Report written by you will appear there will be marked improvement in
publishing five case and field studies relative to the virtual zero
published in recent decades. Thanks for this in the spirit of the Granof and Zeff appeal:
We fervently hope that the research pendulum will soon
swing back from the narrow lines of inquiry that dominate today's
leading journals to a rediscovery of the richness of what accounting
research can be. For that to occur,
deans and the current generation of academic accountants must give it a
push.
Research on Accounting Should Learn From the Past"
by Michael H. Granof and Stephen A. Zeff
Chronicle of Higher Education, March 21, 2008
Thank you for making TAR "swing back from the narrow lines of inquiry" that
dominated its research publications in the past four decades ---
http://www.trinity.edu/rjensen/395wpTAR/Web/TAR395wp.htm
Leading accounting
professors lamented TAR’s preference for rigor over relevancy [Zeff, 1978;
Lee, 1997; and Williams, 1985 and 2003]. Sundem [1987] provides revealing
information about the changed perceptions of authors, almost entirely from
academe, who submitted manuscripts for review between June 1982 and May
1986. Among the 1,148 submissions, only 39 used archival (history) methods;
34 of those submissions were rejected. Another 34 submissions used survey
methods; 33 of those were rejected. And 100 submissions used traditional
normative (deductive) methods with 85 of those being rejected. Except for a
small set of 28 manuscripts classified as using “other” methods (mainly
descriptive empirical according to Sundem), the remaining larger subset of
submitted manuscripts used methods that Sundem [1987, p. 199] classified
these as follows:
292 General Empirical
172 Behavioral
135 Analytical modeling
119 Capital Market
97 Economic modeling
40 Statistical modeling
29 Simulation
It is clear that by 1982,
accounting researchers realized that having mathematical or statistical
analysis in TAR submissions made accountics virtually a necessary, albeit
not sufficient, condition for acceptance for publication. It became
increasingly difficult for a single editor to have expertise in all of the
above methods. In the late 1960s, editorial decisions on publication shifted
from the TAR editor alone to the TAR editor in conjunction with specialized
referees and eventually associate editors [Flesher, 1991, p. 167]. Fleming
et al. [2000, p. 45] wrote the following:
The big change was in
research methods. Modeling and empirical methods became prominent
during 1966-1985, with analytical modeling and general empirical
methods leading the way. Although used to a surprising extent,
deductive-type methods declined in popularity, especially in the
second half of the 1966-1985 period.
Hi again Steve on October 18, 2011,
As to replication, there's more to my criticisms of accountics science
than replications as defined in the natural and social sciences. I view
the lack of exacting replication as a signal of both lack of interest
and lack of dissent in accountics science harvests relative to the
intense interest and dissent that motivates exacting replications in
real science ---
http://www.trinity.edu/rjensen/TheoryTAR.htm
And there's one piece of evidence
about accountics science that stands out like a beacon of disgrace if
you can call lack of scandal a disgrace. Since reputations,
tenure, and performance evaluations are so dependent in real science
upon research and publication, there is an intense effort to test the
validity of scientific research harvests and relatively frequent
discovery of researcher scandal and/or error. This is a mark of
interest in the harvests of real science.
Over the entire history of accountics science, I cannot think of one
genuine scandal. And discovery of error by independent accountics
scientist is a rare event. Is it just that accountics scientists are
more accurate and more honest than real scientists? Or is it that
accountics science harvests are just not put through the same validity
testing in a timely manner that we find in real science?
Of course I do not expect small sample studies, particularly case
studies, to be put through the same rigorous scientific testing.
Particularly troublesome in case studies is that they are cherry picked
and suffer the same limitations as any anecdotal evidence when it comes
to validity checking.
The purpose of case studies is often limited to education and training,
which is why case writers sometimes even add fiction with some type of
warning that these are fictional or based only loosely on real world
happenings.
The purpose of case studies deemed research (meaning contributing to new
knowledge) is often discovery. The following is a quote from an earlier
1993 President’s Message by Gary Sundem,
Although empirical scientific method
has made many positive contributions to accounting research,
it is not the method that is likely to generate new theories,
though it will be useful in testing them. For example,
Einstein’s theories were not developed empirically, but they
relied on understanding the empirical evidence and they were
tested empirically. Both the development and testing of theories
should be recognized as acceptable accounting research.
"President’s Message," Accounting Education
News 21 (3). Page 3.
TAR, JAR, and JAE need to encourage more
replication and open dissent regarding the findings they publish. I
provide some examples of how to go about this, particularly the
following approach ---
http://www.trinity.edu/rjensen/TheoryTAR.htm#TARversusAMR
TAR currently does not
solicit or publish commentaries and abstracts of replications, although
to do so is not outside its operational guidelines. It is sad that TAR
does not publish such guidelines or give consideration to needs of the
practicing profession.
Happily, the Academy of Management Review has a Dialogue Section
---
http://www.aom.pace.edu/AMR/info.html
Dialogue
Dialogue is a forum for readers who wish to comment briefly on material
recently published in AMR. Readers who wish to submit material
for publication in the Dialogue section should address only AMR
articles or dialogues. Dialogue comments must be timely, typically
submitted within three months of the publication date of the material on
which the dialogue author is commenting. When the dialogue comments
pertain to an article, note, or book review, the author(s) will be asked
to comment as well. Dialogue submissions should not exceed five
double-spaced manuscript pages including references. Also, an Abstract
should not be included in a Dialogue. The Editor will make publishing
decisions regarding them, typically without outside review.
My good friend Jason Xiao
[xiao@Cardiff.ac.uk]
pointed out that the Academy of Management Review (AMR) is a
theory journal and the Academy of Management Journal (AMJ) is the
empirical-article Academy of Management.
He’s correct, and I would like to now
point out a more technical distinction. The Dialogue section of the AMR
invites reader comments challenging validity of assumptions in theory
and, where applicable, the assumptions of an analytics paper. The AMJ
takes a slightly different tack for challenging validity in what is
called an “Editors’ Forum,” examples of which are listed in the index at
http://journals.aomonline.org/amj/amj_index_2007.pdf
One index had some academic vs. practice
Editors' Forum articles that especially caught my eye as it might be
extrapolated to the schism between academic accounting research versus
practitioner needs for applied research:
Bartunek, Jean M. Editors’ forum (AMJ
turns 50! Looking back and looking ahead)—Academic-practitioner
collaboration need not require joint or relevant research: Toward a
relational
Cohen, Debra J. Editors’ forum
(Research-practice gap in human resource management)—The very
separate worlds of academic and practitioner publications in human
resource management: Reasons for the divide and concrete solutions
for bridging the gap. 50(5): 1013–10
Guest, David E. Editors’ forum
(Research-practice gap in human resource management)—Don’t shoot the
messenger: A wake-up call for academics. 50(5): 1020–1026.
Hambrick, Donald C. Editors’ forum (AMJ
turns 50! Looking back and looking ahead)—The field of management’s
devotion to theory: Too much of a good thing? 50(6): 1346–1352.
Latham, Gary P. Editors’ forum
(Research-practice gap in human resource management)—A speculative
perspective on the transfer of behavioral science findings to the
workplace: “The times they are a-changin’.” 50(5): 1027–1032.
Lawler, Edward E, III. Editors’
forum (Research-practice gap in human resource management)—Why HR
practices are not evidence-based. 50(5): 1033–1036.
Markides, Costas. Editors’ forum
(Research with relevance to practice)—In search of ambidextrous
professors. 50(4): 762–768.
McGahan, Anita M. Editors’ forum
(Research with relevance to practice)—Academic research that matters
to managers: On zebras, dogs, lemmings,
Rousseau, Denise M. Editors’ forum
(Research-practice gap in human resource management)—A sticky,
leveraging, and scalable strategy for high-quality connections
between organizational practice and science. 50(5): 1037–1042.
Rynes, Sara L. Editors’ forum
(Research with relevance to practice)—Editor’s foreword—Carrying
Sumantra Ghoshal’s torch: Creating more positive, relevant, and
ecologically valid research. 50(4): 745–747.
Rynes, Sara L. Editors’ forum
(Research-practice gap in human resource management)—Editor’s
afterword— Let’s create a tipping point: What academics and
practitioners can do, alone and together. 50(5): 1046–1054.
Rynes, Sara L., Tamara L. Giluk, and
Kenneth G. Brown. Editors’ forum (Research-practice gap in human
resource management)—The very separate worlds of academic and
practitioner periodicals in human resource management: Implications
More at
http://journals.aomonline.org/amj/amj_index_2007.pdf
Also see the index sites for earlier years ---
http://journals.aomonline.org/amj/article_index.htm
Jensen Added Comment
I think it is misleading to imply that there's been enough validity
checking in accountics science and that further validity checking is
either not possible or could not possibly have more benefit than cost.
Conclusion
But I do thank you and your 500+ TAR referees for going from virtually
zero to five case and field study publications in fiscal 2011. That's
marked progress. Perhaps Harry will even publish some dialog about
previously-published accountics science articles.
Respectfully,
Bob Jensen
Equity Valuation for the Real World Versus the Fantasy Land of Accountics
Researchers and Teachers in Academe
Equity Valuation
TAR book reviews are free online. I found the September 2010 reviews quite
interesting, especially Professor Zhang's review of
PETER O. CHRISTENSEN and GERALD A. FELTHAM,
Equity Valuation, Hanover,
MA:Foundations and Trends® in Accounting, 2009,
ISBN 978-1-60198-272-8 ---
Click Here
This book is an advanced accountics research book
and the reviewer leaves many doubts about the theory and practicality of
adjusting for risk by adjusting the discount rate in equity valuation. The
models are analytical mathematical models subject to the usual limitations of
assumed equilibrium conditions that are often not applicable to the changing
dynamics of the real world.
The authors develop an equilibrium asset-pricing
model with risk adjustments depending on the time-series properties of cash
flows and the accounting policy. They show that operating characters such as
the growth and persistence of earnings can affect the risk adjustment.
What are the highlights of this book? The book
contains five chapters and three appendices. Chapters 2 to 5 each contain
separate yet closely related topics. Chapter 2 reviews and identifies
problems with the implementation of the classical model. In Chapters 3 to 5,
the authors develop an accounting-based, multi-period asset-pricing model
with HARA utility. My preferences are Chapters 2 and 5. Chapter 2 contains a
critical review of the classical valuation approach with a constant
risk-adjusted discount rate. As noted above, the authors highlight several
problems in estimating these models. Many of these issues are not properly
acknowledged and/or dealt with in many of the textbooks. The authors provide
a nice step-by-step analysis of the problems and possible solutions.
Chapter 5 contains the punch line. The authors push
ahead with the idea of adjusting risk in the numerator, and deal with the
thorny issue of identifying and simplifying the so-called “pricing kernel.”
Although the final model involves a rather simplifying assumption of a
simple VAR model of the stochastic processes of residual income and for the
consumption index, it provides striking and promising ideas of how to
estimate and adjust for risk based on fundamentals, as opposed to stock
return. It provides a nice illustration of how to incorporate time-change
risk characteristics of firms with the change in firms’ operations captured
by the change in residual income. This is very encouraging.
There are some unsettling issues in this book. Not
surprisingly, I find the authors’ review of the classical valuation approach
to be somewhat tilted toward the negative side. For instance, many of the
problems cited arise from the practice of estimating a single, constant
risk-adjusted discount rate for all future periods. This seems to be based
on the assumption that firms’ risk characteristics do not change materially
over future periods. Of course, this is a grossly simplified approach in
dealing with the issues of time-changing interest rates and inflation. To
me, errors introduced by such an approach reflect more the shortcomings in
the empirical or practical implementation, rather than the shortcomings in
the valuation approach per se. As noted by the authors, using date-specific
discount rates can avoid many of the problems. After all, under most
circumstances in a neo-classical framework, putting the risk adjustment in
the numerator or in the denominator may simply be an easy mathematical
transformation. In some cases, of course, adjusting risk in the denominator
does not lead to any solution to the problem. In that sense, adjusting in
the numerator is more flexible.
After finishing the book, I asked myself the
following question: Am I convinced that the practice of adjusting risk in
the discount rate should be abolished? The answer seems unclear, for a
couple of reasons. First, despite the authors’ admirable effort in bringing
context to it, the concept of “consumption index” still seems rather
elusive. As a result, it lacks the appeal of the traditional CAPM, namely, a
clear and intuitive idea of risk adjustment.
Professor Zhang seems to favor CAPM risk adjustment without delving
into the many controversies of using CAPM for risk adjustment in the real world
---
http://faculty.trinity.edu/rjensen/theory01.htm#AccentuateTheObvious
It would be interesting to see how these sophisticated analytical models are
really used by real-world equity valuation analysts.
Update on April 12, 2012
Leading Accountics researchers like Bill Beaver and Steve Penman have a hard
time owning up to CAPM's discovered limitations that trace back to their own
research built on CAPM. Steve Penman owns up to this somewhat in his own latest
book Accounting for Value that seems to run counter to his earlier
book Financial Statement Analysis and Security Valuation.
Bill Beaver's review of Accounting for Value makes an
interesting proposition:
Since Accounting for Value admits to limitations of CAPM and lack of
capital market efficiency it should be of interest to investors, security
analysts, and practicing accountants consulting on valuation. However, Penman's
Accounting for Value is not of much interest to accounting professors and
students who, at least according to Bill, should continue to dance in the
Fantasy Land of assumed efficient markets and relevance of CAPM in accountics
research.
Accounting for Value
by Stephan Penman
(New York, NY: Columbia Business School Publishing, 2011, ISBN
978-0-231-15118-4, pp. xviii, 244).
Reviewed by William H. Beaver
The Accounting Review, March 2012, pp. 706-709
http://aaajournals.org/doi/full/10.2308/accr-10208
Jensen Note: Since TAR book reviews are free to the public, I quoted
Bill's entire review
When I was asked by Steve Zeff to review Accounting
for Value, my initial reaction was that I was not sure I was the
appropriate reviewer, given my priors on market efficiency. As I shall
discuss below, a central premise of the book is that there are substantial
inefficiencies in the pricing of common stock securities with respect to
published financial statement information. At one point, the book suggests
that most, if not all, of the motivation for reading the book disappears if
one believes that markets are efficient with respect to financial statement
information (page 3). I disagree with this statement and found the book
to be of value even if one assumes market efficiency is a reasonable
approximation of the behavior of security prices.
It is unclear who is the intended audience—academic
or nonacademic. This is an important issue, because it determines the basis
against which the book should be judged. For an academic audience, the book
would be good as a supplemental text for an investments or financial
statement analysis course. However, for an academic audience, it is
not a replacement for his previous, impressive text, Financial
Statement Analysis and Security Valuation (2009). The earlier text goes into
much more detail, both in terms of how to proceed and what the evidence or
research basis is for the security valuation proposed. The previous book is
excellent as the prime source for a course, and the current effort is not a
substitute for the earlier text.
However, as clearly stated, the primary audience is
not academic and is certainly not the passive investor. The book was written
for investors, and for those to whom they trust their savings (page 1).
Moreover, as stated on pages 3–4, the intended audience is the investor who
is skeptical of the efficient market, who is one of Graham's “defensive
investors,” who thinks they can beat the market, and who perceives they can
gain by trading at “irrational” prices.1 For this reason, the book can be
compared with the plethora of “how to beat the market” books that fill the
“Investments” section of most popular bookstores. By this standard,
Accounting for Value is well above the competition. It is much more
conceptually based and includes references to the research that underlies
the basic philosophy. By this standard, the book is a clear winner.
Another standard is to judge the effort, not by the
average quality of the competition, but by one of the best, Benjamin
Graham's The Intelligent Investor (1949). This, indeed, is a high standard.
The Intelligent Investor is the text I was assigned in my first investments
course. My son is currently in an M.B.A. program, taking an investments
course, so for his birthday I gave him a copy of Graham's book. However,
markets and our knowledge of how markets work have changed enormously since
Graham's book was written.
The comparison with The Intelligent Investor is
natural in part because the text itself explicitly invites such comparisons
with the many references to Graham and by suggesting that it follows the
heritage of Graham's book. It also invites comparisons because, like
Graham's book, it is essentially about investing based on fundamentals and
tackles the subject at a conceptual level with simple examples, without
getting bogged down in extreme details of a “how to” book. I conclude that
Accounting for Value measures up very well against this high standard and is
one of the best efforts written on fundamental investing that incorporates
what we have learned in the intervening years since the first publication of
The Intelligent Investor in 1949. I have reached this conclusion for several
reasons.
One of the major points eloquently made is that
modern finance theory (e.g., CAPM and option pricing models) consists of
models of the relationship among endogenous variables (prices or returns).
These models derive certain relative relationships among securities traded
in a market that must be preserved in order to avoid arbitrage
opportunities. However, as the text points out, these models are devoid of
what exogenous informational variables (i.e., fundamentals) cause the model
parameters to be what they are. For example, in the context of the CAPM,
beta is a driving force that produces differential expected returns among
securities. However, the CAPM is silent on what fundamental variables would
cause one company's beta to be different from another's. One of major themes
developed in the text is that accounting data can be viewed as a primary set
of variables through which one can gain an understanding of the underlying
fundamentals of the value of a firm and its securities.2 This is extremely
important to understand, regardless of one's priors about market efficiency.
A central issue is the identification of informational variables that aid in
our understanding of security prices and returns. As accounting scholars, we
have an interest in the “macro” (or equilibrium) role of accounting data
beyond or independent of the “micro” role of determining whether it is
helpful to an individual in identifying “mispriced” securities.
Another major contribution is the development of a
valuation model of fundamentals through the lens of accounting data based on
accrual accounting. In doing so, the text makes another important
point—namely the role of accrual accounting in bringing the future forward
into the present (e.g., revenue recognition).3 In other words, accrual
accounting contains implicit (or explicit) predictions of the future. It is
argued that, since the future is difficult to predict, accrual accounting
permits the investor to make judgments over a shorter time horizon and to
base those judgments on “what we know.” The text develops the position that,
in general, forecasts and hence valuation analysis based on accrual
accounting numbers will be “better” than cash flow-based valuations. It is
important to understand that the predictive role is a basic feature of
accrual accounting, even if one disagrees about how well accrual accounting
performs that role. Penman believes it performs that function very well and
dominates explicit future cash flow prediction, based on the intuitive
assumption that the investor does not have to forecast accrual accounting
numbers as far into the future as would be required by cash flow
forecasting. The implicit assumption is that the prediction embedded in
accrual numbers is at least as good, if not better, than attempts to
forecast future cash flows explicitly.
A third major point is that book-value-only or
earnings-only models are inherently underspecified and fundamentally
incomplete, except in special cases. Instead, a more complete valuation
approach contains both a book value and a (residual) earnings term. A point
effectively made is that measurement of one term can be compensated for by
the inclusion of the other variable by virtue of the over-time compensating
mechanism of accrual accounting.
A major implication of the model is the myopic
nature of two of the most popular methods for selecting securities:
market-to-book ratios and price-to-earnings ratios. Stocks may appear to be
over- or underpriced when partitioning on only one these two variables.
Using a double partitioning can help alleviate this myopia.
The book is positioned almost exclusively from the
perspective of the purchaser of securities. For example, one of the ten
principles of fundamental analysis (page 6) is “Beware of paying too much
for growth.” Presumably, a fundamental investor of an existing portfolio is
a potential seller as well as a buyer. As a potential seller, the investor
has an analogous interest in selling overpriced securities, but this is not
the perspective explicitly taken. In spite of the apparent asymmetry of
perspective, the concepts of the valuation model would appear to have
important implications for the evaluation of existing securities held.
In the basic valuation model, value is equal to
current book value, residual earnings for the next two years, and a terminal
value term based on the present value of residual earnings stream beyond two
years.4 The model bears some resemblance to the modeling of Feltham and
Ohlson (1995) but adds context of its own. A central feature of the approach
is to understand what you know and separate it from speculation.5 In this
context, book value is “what you know,” and everything else involves some
degree of speculation. The degree of speculation increases as the time
horizon increases (e.g., long-term growth estimates).
A key feature is that it is residual earnings
growth, not simply earnings growth, that is the driver in valuation.
Price-earnings-only models are incomplete because of a failure to make this
distinction. The nature of the long-term residual earnings growth is highly
speculative, which leads to one of the investment principles—beware of
paying too much for growth. The text provides some benchmarks in terms of
the empirical behavior of long-term residual growth rates and reasons why
abnormal earnings might be expected to decay rapidly. A higher expected
residual growth is also likely to be associated with higher risk and hence a
higher discount rate. All of these factors mitigate against long-term growth
playing a large role in the fundamental value (i.e., do not pay too much for
growth). A similar point is made with respect to the effect of leverage upon
growth rates (Chapter 4).
A remarkable feature of the book is how far it is
able to develop its basic perspective without specifying the nature of the
accounting system upon which it is anchoring valuation other than to say
that it is based on accrual accounting. Chapter 5 begins to address the
nature of the accrual accounting system. A central point is that accounting
treatments that lower current book value (e.g., write-offs and the expensing
of intangible assets) will increase future residual earnings (Accounting
Principle 4). In particular, conservative accounting with investment growth
induces growth in residual income (Accounting Principle 5). However,
conservatism does not increase value. Hence, valuations that focus only on
earnings to the exclusion of book value can lead to erroneous valuation
conclusions. An investor must consider both (Valuation Principle 6).
Chapter 6 addresses the estimation of the discount
rate. A central theme is how little we know about estimating the discount
rate (cost of capital), and we can provide, at best, very imprecise
estimates. The proposed solution is to “reverse engineer” the discount rate
implied by the current market price and ask yourself if you consider this to
be a rate of return at which you are willing to invest, which is viewed as a
personal attribute. Several examples and sensitivity analyses are provided.
Chapter 7 synthesizes points made in earlier
chapters about how the investor can gain insights into distinguishing growth
that does not add to value from growth that does, through a joint analysis
of market-to-book and price-to-earnings partitions. The joint analysis is
clever and is likely to be informative to an investor familiar with these
popular partitioning variables, but is perhaps not yet ready to use the
explicit accounting-based valuation models recommended.
Chapter 8 addresses the attributes of fair value
and historical cost accounting and is the chapter that is the most
surprising. The chapter is essentially an attack on fair value accounting.
Up until this point, the text has been free of policy recommendations. The
strength lies in taking the accounting rules as you find them, which is a
very practical suggestion and has great potential readership appeal. The
flexibility of the framework to accommodate a variety of accounting systems
is one of its strengths. As a result, the conceptual framework is relatively
simple. It does not attempt to tediously examine accounting standards in
detail, nor does it attempt to adjust accounting earnings or assets to
conform to a concept of “better” earnings or assets, in contrast to other
valuation approaches. I found the one-sided treatment of fair value
accounting to be disruptive of the overall theme of taking accounting rules
as you find them.
The text provides an important caveat. The
framework is a starting point rather than the final answer. A number of
issues are not explicitly addressed. It can also be important to understand
the specific effects of complex accounting standards on the numbers they
produce. Further, there is ample evidence that the market does price
disclosures supplemental to the accounting numbers. Discretionary use of
accounting numbers also can raise a number of important issues.
In sum, the text provides an excellent framework
for investors to think about the role that accounting numbers can play in
valuation. In doing so, it provides a number of important insights that make
it worthwhile for a wide readership, including those who may have stronger
priors in favor of market efficiency.
Bob Jensen's threads on valuation are at
http://faculty.trinity.edu/rjensen/roi.htm
Bob Jensen's critical threads on the Efficient Market Hypothesis (EMH) are
at
http://faculty.trinity.edu/rjensen/theory01.htm#EMH
Can the 2008 investment banking failure be traced to a math error?
Recipe for Disaster: The Formula That Killed Wall Street ---
http://www.wired.com/techbiz/it/magazine/17-03/wp_quant?currentPage=all
Link forwarded by Jim Mahar ---
http://financeprofessorblog.blogspot.com/2009/03/recipe-for-disaster-formula-that-killed.html
Some highlights:
"For five years, Li's formula, known as a
Gaussian copula function, looked like an unambiguously positive
breakthrough, a piece of financial technology that allowed hugely
complex risks to be modeled with more ease and accuracy than ever
before. With his brilliant spark of mathematical legerdemain, Li made it
possible for traders to sell vast quantities of new securities,
expanding financial markets to unimaginable levels.
His method was adopted by everybody from bond
investors and Wall Street banks to ratings agencies and regulators. And
it became so deeply entrenched—and was making people so much money—that
warnings about its limitations were largely ignored.
Then the model fell apart." The article goes on to show that correlations
are at the heart of the problem.
"The reason that ratings agencies and investors
felt so safe with the triple-A tranches was that they believed there was
no way hundreds of homeowners would all default on their loans at the
same time. One person might lose his job, another might fall ill. But
those are individual calamities that don't affect the mortgage pool much
as a whole: Everybody else is still making their payments on time.
But not all calamities are individual, and
tranching still hadn't solved all the problems of mortgage-pool risk.
Some things, like falling house prices, affect a large number of people
at once. If home values in your neighborhood decline and you lose some
of your equity, there's a good chance your neighbors will lose theirs as
well. If, as a result, you default on your mortgage, there's a higher
probability they will default, too. That's called correlation—the degree
to which one variable moves in line with another—and measuring it is an
important part of determining how risky mortgage bonds are."
I would highly recommend reading the entire thing that gets much more
involved with the
actual formula etc.
The
“math error” might truly be have been an error or it might have simply been a
gamble with what was perceived as miniscule odds of total market failure.
Something similar happened in the case of the trillion-dollar disastrous 1993
collapse of Long Term Capital Management formed by Nobel Prize winning
economists and their doctoral students who took similar gambles that ignored the
“miniscule odds” of world market collapse -- -
http://faculty.trinity.edu/rjensen/FraudRotten.htm#LTCM
The rhetorical question is whether the failure is ignorance in model building or
risk taking using the model?
Also see
"In Plato's Cave: Mathematical models are a
powerful way of predicting financial markets. But they are fallible" The
Economist, January 24, 2009, pp. 10-14 ---
http://faculty.trinity.edu/rjensen/2008Bailout.htm#Bailout
Wall Street’s Math Wizards Forgot a Few Variables
What wasn’t recognized was the importance of a
different species of risk — liquidity risk,” Stephen Figlewski, a professor of
finance at the Leonard N. Stern School of Business at New York University, told
The Times. “When trust in counterparties is lost, and markets freeze up so there
are no prices,” he said, it “really showed how different the real world was from
our models.
DealBook, The New York Times, September 14, 2009 ---
http://dealbook.blogs.nytimes.com/2009/09/14/wall-streets-math-wizards-forgot-a-few-variables/
The Sad State of Doctoral Programs in North America
"Exploring Accounting Doctoral Program Decline: Variation and the
Search for Antecedents," by Timothy J. Fogarty and Anthony D. Holder,
Issues in Accounting Education, May 2012 ---
Not yet posted on June 18, 2012
ABSTRACT
The inadequate supply of new terminally qualified accounting faculty poses a
great concern for many accounting faculty and administrators. Although the
general downward trajectory has been well observed, more specific
information would offer potential insights about causes and continuation.
This paper examines change in accounting doctoral student production in the
U.S. since 1989 through the use of five-year moving verges. Aggregated on
this basis, the downward movement predominates, notwithstanding the schools
that began new programs or increased doctoral student production during this
time. The results show that larger declines occurred for middle prestige
schools, for larger universities, and for public schools. Schools that
periodically successfully compete in M.B.A.. program rankings also more
likely have diminished in size. of their accounting Ph.D. programs. Despite
a recent increase in graduations, data on the population of current doctoral
students suggest the continuation of the problems associated with the supply
and demand imbalance that exists in this sector of the U.S. academy.
Jensen Comment
This is a useful update on the doctoral program shortages relative to demand for
new tenure-track faculty in North American universities. However, it does not
suggest any reasons or remedies for this phenomenon. The accounting
doctoral program in many ways defies laws of supply and demand. Accounting
faculty are the among the highest paid faculty in rank (except possibly in
unionized colleges and universities that are not wage competitive). For
suggested causes and remedies of this problem see ---
http://faculty.trinity.edu/rjensen/Theory01.htm#DoctoralPrograms
Accountancy Doctoral Program Information from Jim Hasselback ---
http://www.jrhasselback.com/AtgDoctInfo.html
Especially note the table of the entire history of accounting doctoral
graduates for all AACSB universities in the U.S. ---
http://www.jrhasselback.com/AtgDoct/XDocChrt.pdf
In that table you can note the rise or decline (almost all declines) for each
university.
Links to 91 AACSB University Doctoral Programs ---
http://www.jrhasselback.com/AtgDoct/AtgDoctProg.html
October 8, 2008 message from Amelia Balwin
These are the slides from today's presentations.
This is a work on progress. Your comments are welcome, particularly on the
design of the surveys.
I am very grateful for the support of this research
provided by an Ernst & Young Diversity Grant Award!
"So you want to get a Ph.D.?" by David Wood, BYU ---
http://www.byuaccounting.net/mediawiki/index.php?title=So_you_want_to_get_a_Ph.D.%3F
"The Accounting Doctoral Shortage: Time for a New Model," by Jerry E.
Trapnell, Neal Mero, Jan R. Williams and George W. Krull, Issues in
Accounting Education, November 2009 ---
http://aaajournals.org/doi/abs/10.2308/iace.2009.24.4.427
ABSTRACT:
The crisis in supply versus demand for doctorally qualified faculty members
in accounting is well documented (Association to Advance Collegiate Schools
of Business [AACSB] 2003a, 2003b; Plumlee et al. 2005; Leslie 2008). Little
progress has been made in addressing this serious challenge facing the
accounting academic community and the accounting profession. Faculty time,
institutional incentives, the doctoral model itself, and research diversity
are noted as major challenges to making progress on this issue. The authors
propose six recommendations, including a new, extramurally funded research
program aimed at supporting doctoral students that functions similar to
research programs supported by such organizations as the National Science
Foundation and other science‐based funding sources. The goal is to create
capacity, improve structures for doctoral programs, and provide incentives
to enhance doctoral enrollments. This should lead to an increased supply of
graduates while also enhancing and supporting broad‐based research outcomes
across the accounting landscape, including auditing and tax.
Accounting Doctoral Programs
PQ = Professionally Qualified under AACSB standards
AQ = Academically Qualified under AACSB standards
May 3, 2011 message to Barry Rice from Bob Jensen
Hi Barry,
Faculty without doctoral degrees who meet the AACSB PQ standards are
still pretty much second class citizens and will find the tenure track
hurdles to eventual full professorship very difficult except in colleges
that pay poorly at all levels.
There are a number of alternatives for a CPA/CMA looking into AACSB AQ
alternatives in in accounting in North American universities:
The best alternative is to enter into a traditional accounting doctoral
program at an AACSB university. Virtually all of these in North America are
accountics doctoral programs requiring 4-6 years of full time onsite study
and research beyond the masters degree. The good news is that these programs
generally have free tuition, room, and board allowances. The bad news is
that students who have little interest in becoming mathematicians and
statisticians and social scientists need not apply ---
http://faculty.trinity.edu/rjensen/Theory01.htm#DoctoralPrograms
As a second alternative Central Florida University has an onsite doctoral
program that is stronger in the accounting and lighter in the accountics.
Kennesaw State University has a three-year executive DBA program that has
quant-lite alternatives, but this is only available in accounting to older
executives who enter with PQ-accounting qualifications. It also costs nearly
$100,000 plus room and board even for Georgia residents. The DBA is also not
likely to get the graduate into a R1 research university tenure track.
As a third alternative there are now some online accounting doctoral
programs that are quant-lite and only take three years, but these diplomas
aren't worth the paper they're written on ---
http://faculty.trinity.edu/rjensen/Crossborder.htm#CommercialPrograms
Cappella University is a very good online university, but its online
accounting doctoral program is nothing more than a glorified online MBA
degree that has, to my knowledge, no known accounting researchers teaching
in the program. Capella will not reveal its doctoral program faculty to
prospective students. I don't think the North American academic job market
yet recognizes Capella-type and Nova-type doctorates except in universities
that would probably accept the graduates as PQ faculty without a doctorate.
As a fourth alternative there are some of the executive accounting
doctoral programs in Europe, especially England, that really don't count for
much in the North American job market.
As a fifth alternative, a student can get a three-year non-accounting PhD
degree from a quality doctoral program such as an economics or computer
science PhD from any of the 100+ top flagship state/provincial universities
in North America. Then if the student also has PQ credentials to teach in an
accounting program, the PhD graduate can enroll in an accounting part-time
"Bridge Program" anointed by the AACSB ---
http://www.aacsb.edu/conferences_seminars/seminars/bp.asp
As a sixth alternative, a student can get a three-year law degree in
addition to getting PQ credentials in some areas where lawyers often get
into accounting program tenure tracks. The most common specialty for lawyers
is tax accounting. Some accounting departments also teach business law and
ethics using lawyers.
Hope this helps.
Bob Jensen
PS
Case Western has a very respected accounting history track in its PhD
program, but I'm not certain how many of the accountics hurdles are relaxed
except at the dissertation stage.
Advice and Bibliography for Accounting Ph.D. Students and New Faculty by
James Martin ---
http://maaw.info/AdviceforAccountingPhDstudentsMain.htm
The Sad State of North American Accountancy Doctoral Programs ---
http://faculty.trinity.edu/rjensen/Theory01.htm#DoctoralPrograms
Simpson's Paradox and Cross-Validation
Simpson's Paradox ---
http://en.wikipedia.org/wiki/Simpson%27s_paradox
"Simpson’s Paradox: A Cautionary Tale in Advanced Analytics," by Steve
Berman, Leandro DalleMule, Michael Greene, and John Lucker, Significance:
Statistics Making Sense, October 2012 ---
http://www.significancemagazine.org/details/webexclusive/2671151/Simpsons-Paradox-A-Cautionary-Tale-in-Advanced-Analytics.html
Analytics projects often present us with situations
in which common sense tells us one thing, while the numbers seem to tell us
something much different. Such situations are often opportunities to learn
something new by taking a deeper look at the data. Failure to perform a
sufficiently nuanced analysis, however, can lead to misunderstandings and
decision traps. To illustrate this danger, we present several instances of
Simpson’s Paradox in business and non-business environments. As we
demonstrate below, statistical tests and analysis can be confounded by a
simple misunderstanding of the data. Often taught in elementary probability
classes, Simpson’s Paradox refers to situations in which a trend or
relationship that is observed within multiple groups reverses when the
groups are combined. Our first example describes how Simpson’s Paradox
accounts for a highly surprising observation in a healthcare study. Our
second example involves an apparent violation of the law of supply and
demand: we describe a situation in which price changes seem to bear no
relationship with quantity purchased. This counterintuitive relationship,
however, disappears once we break the data into finer time periods. Our
final example illustrates how a naive analysis of marginal profit
improvements resulting from a price optimization project can potentially
mislead senior business management, leading to incorrect conclusions and
inappropriate decisions. Mathematically, Simpson’s Paradox is a fairly
simple—if counterintuitive—arithmetic phenomenon. Yet its significance for
business analytics is quite far-reaching. Simpson’s Paradox vividly
illustrates why business analytics must not be viewed as a purely technical
subject appropriate for mechanization or automation. Tacit knowledge, domain
expertise, common sense, and above all critical thinking, are necessary if
analytics projects are to reliably lead to appropriate evidence-based
decision making.
The past several years have seen decision making in
many areas of business steadily evolve from judgment-driven domains into
scientific domains in which the analysis of data and careful consideration
of evidence are more prominent than ever before. Additionally, mainstream
books, movies, alternative media and newspapers have covered many topics
describing how fact and metric driven analysis and subsequent action can
exceed results previously achieved through less rigorous methods. This trend
has been driven in part by the explosive growth of data availability
resulting from Enterprise Resource Planning (ERP) and Customer Relationship
Management (CRM) applications and the Internet and eCommerce more generally.
There are estimates that predict that more data will be created in the next
four years than in the history of the planet. For example, Wal-Mart handles
over one million customer transactions every hour, feeding databases
estimated at more than 2.5 petabytes in size - the equivalent of 167 times
the books in the United States Library of Congress.
Additionally, computing power has increased
exponentially over the past 30 years and this trend is expected to continue.
In 1969, astronauts landed on the moon with a 32-kilobyte memory computer.
Today, the average personal computer has more computing power than the
entire U.S. space program at that time. Decoding the human genome took 10
years when it was first done in 2003; now the same task can be performed in
a week or less. Finally, a large consumer credit card issuer crunched two
years of data (73 billion transactions) in 13 minutes, which not long ago
took over one month.
This explosion of data availability and the
advances in computing power and processing tools and software have paved the
way for statistical modeling to be at the front and center of decision
making not just in business, but everywhere. Statistics is the means to
interpret data and transform vast amounts of raw data into meaningful
information.
However, paradoxes and fallacies lurk behind even
elementary statistical exercises, with the important implication that
exercises in business analytics can produce deceptive results if not
performed properly. This point can be neatly illustrated by pointing to
instances of Simpson’s Paradox. The phenomenon is named after Edward
Simpson, who described it in a technical paper in the 1950s, though the
prominent statisticians Karl Pearson and Udney Yule noticed the phenomenon
over a century ago. Simpson’s Paradox, which regularly crops up in
statistical research, business analytics, and public policy, is a prime
example of why statistical analysis is useful as a corrective for the many
ways in which humans intuit false patterns in complex datasets.
Simpson’s Paradox is in a sense an arithmetic
trick: weighted averages can lead to reversals of meaningful
relationships—i.e., a trend or relationship that is observed within each of
several groups reverses when the groups are combined. Simpson’s Paradox can
arise in any number of marketing and pricing scenarios; we present here case
studies describing three such examples. These case studies serve as
cautionary tales: there is no comprehensive mechanical way to detect or
guard against instances of Simpson’s Paradox leading us astray. To be
effective, analytics projects should be informed by both a nuanced
understanding of statistical methodology as well as a pragmatic
understanding of the business being analyzed.
The first case study, from the medical field,
presents a surface indication on the effects of smoking that is at odds with
common sense. Only when the data are viewed at a more refined level of
analysis does one see the true effects of smoking on mortality. In the
second case study, decreasing prices appear to be associated with decreasing
sales and increasing prices appear to be associated with increasing sales.
On the surface, this makes no sense. A fundamental tenet of economics is
that of the demand curve: as the price of a good or service increases,
consumers demand less of it. Simpson’s Paradox is responsible for an
apparent—though illusory—violation of this fundamental law of economics. Our
final case study shows how marginal improvements in profitability in each of
the sales channels of a given manufacturer may result in an apparent
marginal reduction in the overall profitability the business. This seemingly
contradictory conclusion can also lead to serious decision traps if not
properly understood.
Case Study 1: Are those warning labels
really necessary?
We start with a simple example from the healthcare
world. This example both illustrates the phenomenon and serves as a reminder
that it can appear in any domain.
The data are taken from a 1996 follow-up study from
Appleton, French, and Vanderpump on the effects of smoking. The follow-up
catalogued women from the original study, categorizing based on the age
groups in the original study, as well as whether the women were smokers or
not. The study measured the deaths of smokers and non-smokers during the 20
year period.
Continued in article
What happened to cross-validation in
accountics science research?
Over time I've become increasingly critical of
the lack of validation in accountics science, and I've focused mainly upon lack
of replication by independent researchers and lack of commentaries published in
accountics science journals ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
Another type of validation that seems to be on
the decline in accountics science are the so-called cross-validations.
Accountics scientists seem to be content with their statistical inference tests
on Z-Scores, F-Tests, and correlation significance testing. Cross-validation
seems to be less common, at least I'm having troubles finding examples of
cross-validation. Cross-validation entails comparing sample findings with
findings in holdout samples.
Cross Validation ---
http://en.wikipedia.org/wiki/Cross-validation_%28statistics%29
When reading the following paper using logit
regression to to predict audit firm changes, it struck me that this would've
been an ideal candidate for the authors to have performed cross-validation using
holdout samples.
"Audit Quality and Auditor Reputation: Evidence from Japan," by Douglas J.
Skinner and Suraj Srinivasan, The Accounting Review, September 2012, Vol.
87, No. 5, pp. 1737-1765.
We study events surrounding
ChuoAoyama's failed audit of Kanebo, a large Japanese cosmetics company
whose management engaged in a massive accounting fraud. ChuoAoyama was PwC's
Japanese affiliate and one of Japan's largest audit firms. In May 2006, the
Japanese Financial Services Agency (FSA) suspended ChuoAoyama for two months
for its role in the Kanebo fraud. This unprecedented action followed a
series of events that seriously damaged ChuoAoyama's reputation. We use
these events to provide evidence on the importance of auditors' reputation
for quality in a setting where litigation plays essentially no role. Around
one quarter of ChuoAoyama's clients defected from the firm after its
suspension, consistent with the importance of reputation. Larger firms and
those with greater growth options were more likely to leave, also consistent
with the reputation argument.
Rather than just use statistical inference tests
on logit model Z-statistics, it struck me that in statistics journals the
referees might've requested cross-validation tests on holdout samples of firms
that changed auditors and firms that did not change auditors.
I do find somewhat more frequent
cross-validation studies in finance, particularly in the areas of discriminant
analysis in bankruptcy prediction modes.
Instances of cross-validation in accounting
research journals seem to have died out in the past 20 years. There are earlier
examples of cross-validation in accounting research journals. Several examples
are cited below:
"A field study examination of budgetary
participation and locus of control," by Peter Brownell, The Accounting
Review, October 1982 ---
http://www.jstor.org/discover/10.2307/247411?uid=3739712&uid=2&uid=4&uid=3739256&sid=21101146090203
"Information choice and utilization in an
experiment on default prediction," Abdel-Khalik and KM El-Sheshai -
Journal of Accounting Research, 1980 ---
http://www.jstor.org/discover/10.2307/2490581?uid=3739712&uid=2&uid=4&uid=3739256&sid=21101146090203
"Accounting ratios and the prediction of
failure: Some behavioral evidence," by Robert Libby, Journal of
Accounting Research, Spring 1975 ---
http://www.jstor.org/discover/10.2307/2490653?uid=3739712&uid=2&uid=4&uid=3739256&sid=21101146090203
There are other examples of cross-validation
in the 1970s and 1980s, particularly in bankruptcy prediction.
I have trouble finding illustrations of
cross-validation in the accounting research literature in more recent years. Has
the interest in cross-validating waned along with interest in validating
accountics research? Or am I just being careless in my search for illustrations?
Question
Why are accountics science journal articles cited in other accountics science
research papers so often?
Answer
It works like this. A prestigious accountics science research journal "suggests"
that you cite some of its previously-published articles before making a decision
to accept your submission. Scroll down deep to find out how it works.
"Journals Inflate Their Prestige by
Coercing Authors to Cite Them," Chronicle of Higher Education,
February 3, 2012 ---
http://chronicle.com/blogs/ticker/journals-inflate-rankings-by-coercing-authors-to-cite-them/40233?sid=wc&utm_source=wc&utm_medium=en
A
survey published today in Science shows
that journal editors often ask prospective authors to add
superfluous citations of the journal to articles, and authors feel
they can’t refuse. (The Science paper is for subscribers only, but
you can read a summary here.) The extra citations artificially
inflate a journal’s impact and prestige. About 6,600 academics
responded to the survey, and about 20 percent said they had been
asked to add such citations even though no editor or reviewer had
said their article was deficient without them. About 60 percent of
those surveyed said they would comply with such a request, which was
most often aimed at junior faculty members.
|
Commercial Scholarly and Academic Journals and Oligopoly Textbook
Publishers Are Ripping Off Libraries, Scholars, and Students ---
http://www.trinity.edu/rjensen/FraudReporting.htm#ScholarlyJournals
The AAA's Pathways Commission Accounting Education Initiatives Make
National News
Accountics Scientists Should Especially Note the First Recommendation
"Accounting for Innovation," by Elise Young, Inside Higher Ed,
July 31, 2012 ---
http://www.insidehighered.com/news/2012/07/31/updating-accounting-curriculums-expanding-and-diversifying-field
Accounting programs should promote curricular
flexibility to capture a new generation of students who are more
technologically savvy, less patient with traditional teaching methods, and
more wary of the career opportunities in accounting, according to a report
released today by the
Pathways Commission, which studies the future of
higher education for accounting.
In 2008, the U.S. Treasury Department's Advisory
Committee on the Auditing Profession recommended that the American
Accounting Association and the American Institute of Certified Public
Accountants form a commission to study the future structure and content of
accounting education, and the Pathways Commission was formed to fulfill this
recommendation and establish a national higher education strategy for
accounting.
In the report, the commission acknowledges that
some sporadic changes have been adopted, but it seeks to put in place a
structure for much more regular and ambitious changes.
The report includes seven recommendations:
The Pathways Commission
Implementing Recommendations for the Future of Accounting Education: The
First Year Update
American Accounting Association
August 2013
http://commons.aaahq.org/files/3026eae0b3/Pathways_Update_FIN.pdf
- Integrate accounting research, education
and practice for students, practitioners and educators by bringing
professionally oriented faculty more fully into education programs.
- Promote accessibility of doctoral
education by allowing for flexible content and structure in doctoral
programs and developing multiple pathways for degrees. The current path
to an accounting Ph.D. includes lengthy, full-time residential programs
and research training that is for the most part confined to quantitative
rather than qualitative methods. More flexible programs -- that might be
part-time, focus on applied research and emphasize training in teaching
methods and curriculum development -- would appeal to graduate students
with professional experience and candidates with families, according to
the report.
- Increase recognition and support for
high-quality teaching and connect faculty review, promotion and tenure
processes with teaching quality so that teaching is respected as a
critical component in achieving each institution's mission. According to
the report, accounting programs must balance recognition for work and
accomplishments -- fed by increasing competition among institutions and
programs -- along with recognition for teaching excellence.
- Develop curriculum models, engaging learning
resources and mechanisms to easily share them, as well as enhancing
faculty development opportunities to sustain a robust curriculum that
addresses a new generation of students who are more at home with
technology and less patient with traditional teaching methods.
- Improve the ability to attract high-potential,
diverse entrants into the profession.
- Create mechanisms for collecting, analyzing
and disseminating information about the market needs by establishing a
national committee on information needs, projecting future supply and
demand for accounting professionals and faculty, and enhancing the
benefits of a high school accounting education.
- Establish an implementation process to address
these and future recommendations by creating structures and mechanisms
to support a continuous, sustainable change process.
According to the report, its two sponsoring
organizations -- the American Accounting Association and the American
Institute of Certified Public Accountants -- will support the effort to
carry out the report's recommendations, and they are finalizing a strategy
for conducting this effort.
Hsihui Chang, a professor and head of Drexel
University’s accounting department, said colleges must prepare students for
the accounting field by encouraging three qualities: integrity, analytical
skills and a global viewpoint.
“You need to look at things in a global scope,” he
said. “One thing we’re always thinking about is how can we attract students
from diverse groups?” Chang said the department’s faculty comprises members
from several different countries, and the university also has four student
organizations dedicated to accounting -- including one for Asian students
and one for Hispanic students.
He said the university hosts guest speakers and
accounting career days to provide information to prospective accounting
students about career options: “They find out, ‘Hey, this seems to be quite
exciting.’ ”
Jimmy Ye, a professor and chair of the accounting
department at Baruch College of the City University of New York, wrote in an
email to Inside Higher Ed that his department is already fulfilling
some of the report’s recommendations by inviting professionals from
accounting firms into classrooms and bringing in research staff from
accounting firms to interact with faculty members and Ph.D. students.
Ye also said the AICPA should collect and analyze
supply and demand trends in the accounting profession -- but not just in the
short term. “Higher education does not just train students for getting their
first jobs,” he wrote. “I would like to see some study on the career tracks
of college accounting graduates.”
Mohamed Hussein, a professor and head of the
accounting department at the University of Connecticut, also offered ways
for the commission to expand its recommendations. He said the
recommendations can’t be fully put into practice with the current structure
of accounting education.
“There are two parts to this: one part is being
able to have an innovative curriculum that will include changes in
technology, changes in the economics of the firm, including risk,
international issues and regulation,” he said. “And the other part is making
sure that the students will take advantage of all this innovation.”
The university offers courses on some of these
issues as electives, but it can’t fit all of the information in those
courses into the major’s required courses, he said.
Continued in article
Bob Jensen's threads on Higher Education Controversies and Need for Change
---
http://faculty.trinity.edu/rjensen/HigherEdControversies.htm
The sad state of accountancy doctoral programs ---
http://faculty.trinity.edu/rjensen/Theory01.htm#DoctoralPrograms
How Accountics Scientists Should Change:
"Frankly, Scarlett, after I get a hit for my resume in The Accounting Review
I just don't give a damn"
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
One more mission in what's left of my life will be to try to change this
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
Conclusion and Recommendation for a Journal Named Supplemental Commentaries
and Replication Abstracts
The bottom line is that Steve says he wants "integrity" in TAR's published
papers, but at the same time he and previous TAR editors gave us zero in terms
of encouraging accounting researchers to conduct replication research on
experiments. As a result, we've no assurance about the accuracy and/or
integrity of any published experiment in TAR! Only in some isolated
instances has the accuracy been challenged in other (non-experimental) extended
research articles published in TAR.
My answer to the problem of replication of TAR research and lack of
commentaries about articles published in TAR (not necessarily replications) is
to create a electronic journal Supplement called Supplemental Commentaries
and Replication Abstracts About AAA Articles. The journal supplement is to be a refereed
journal and is not to compete for hard copy pages in TAR itself or other AAA
hard copy publications. The purpose
of the Supplemental Commentaries and Replication Abstracts is to expand
on findings reported in AAA research journals and to encourage
independent researchers to verify the accuracy and integrity of the original
articles.
This electronic Supplemental Commentaries and Replication Abstracts might also publish short pieces about hypotheses tested that
were not deemed significant for publication. Psychology has such a refereed
journal:
Refereed Electronic Journal
The Journal of Articles in Support
of the Null Hypothesis ---
http://www.jasnh.com/index.htm
Welcome to the Journal of Articles in
Support of the Null Hypothesis. In the past other journals and reviewers
have exhibited a bias against articles that did not reject the null
hypothesis. We seek to change that by offering an outlet for experiments
that do not reach the traditional significance levels (p < .05). Thus,
reducing the file drawer problem, and reducing the bias in psychological
literature. Without such a resource researchers could be wasting their time
examining empirical questions that have already been examined. We collect
these articles and provide them to the scientific community free of cost.
As an externality here, I think that the mere existence of Supplemental
Commentaries and Replication Abstracts will make future authors more careful and discourage ethics violations in
the original submissions. Ideally, most replications will be positive and most
commentaries thought provoking regarding how to improve the original studies.
Nominations are now being sought for a new Senior Editor of TAR. Hopefully, a
new Senior Editor will take my proposals seriously.
In no way do I want to distract from the quality and quantity of effort of
Steve Kachelmeier. The job of TAR's Senior Editor is overwhelming given
the greatly increased number of submissions to TAR while he's been our Senior
Editor. Steve's worked long and hard assembling a superb team of associate
editors and reviewers for over 600 annual submissions. He's had to resolve many
conflicts between reviewers and deal personally with often angry and frustrated
authors. He's helped to re-write a lot of badly written papers reporting solid
research. He's also suggested countless ways to improve the research itself. And
in terms of communications with me (I can be a pain in the butt), Steve has been
willing to take time from his busy schedule to debate with me in private email
conversations.
I think the AAA electronic Supplement should have a Senior Editor reporting
to but trying to avoid overburdening the TAR Senior Editor or Senior Editors of
other AAA research journals.
The electronic Supplemental Commentaries and Replication Abstracts
could be integrated somehow into the new AAA Commons. But submissions to the AAA
Commons are more or less random, uncoordinated, and not refereed. The
Senior Editor of the Supplement should actively promote the Supplement and
invite readers to submit commentaries and abstracts of replication research.
Also submissions to the Supplement should be refereed for a number of reasons in
terms of quality control and in terms of authors getting refereed publication
credits.
Nearly all the articles published in TAR over the past several decades are
limited to accountics studies that, in my viewpoint, have questionable internal
and external validity due to missing variables, measurement errors, and
simplistic mathematical structures. If accountants grounded in the real world
were allowed to challenge the external validity of accountics studies it is
possible that accountics researchers would pay greater attention to
external validity ---
http://en.wikipedia.org/wiki/External_Validity
Similarly if accountants grounded in the real world were allowed to
challenge the external validity of accountics studies it is possible that
accountics researchers would pay greater attention to
internal validity ---
http://en.wikipedia.org/wiki/Internal_Validity
Hopefully the new Senior Editor of TAR will not only want integrity,
accuracy, internal validity, and external validity of TAR articles but will take
some significant steps to making TAR research more respectable in the academy.
Steve's 2010 Update on TAR ---
http://www.cs.trinity.edu/~rjensen/temp/TheoryAnnual
ReportTAR_2010.pdf
Here’s the speech and slides Francine used for the AAA Public Interest
Conference on April 1-2 and Top X list of possible research topics for
accounting and audit academics ---
http://retheauditors.com/2011/04/18/mckenna-speaks-at-american-accounting-assn-public-interest-conference/
Bob Jensen lists some research ideas at
http://faculty.trinity.edu/rjensen/theory01.htm#ResearchVersusProfession
The quick and dirty answer to your question Marc is that the present
dominance of accountics scientists behind a wall of silence on our Commons is
just not sustainable. They cannot continue to monopolize AACSB accounting
doctoral programs by limiting supply so drastically in the face of rising demand
for accounting faculty ---
http://faculty.trinity.edu/rjensen/Theory01.htm#DoctoralPrograms
They cannot continue to monopolize the selection of editors of their favored
journals (especially TAR and AH) in the face of increasing democracy in the AAA.
The Emperor cannot continue to parade without any clothes in the presence of
increasing criticism from AAA Presidents, including criticisms raised by
President Waymire (
who's an accountics
scientist ) in the 2011 Annual Meetings ---
Watch the Video:
http://commons.aaahq.org/posts/b60c7234c6
What we cannot do is expect change to happen overnight. For the past four
decades our doctoral programs have cranked out virtually nothing but accountics
scientists. Something similar happened in the Pentagon in the 1920s when West
Point and Naval Academy graduates dominated the higher command until the 1940s.
We began to see the value of air power, but it took decades to split the Air
Force out from under the Army and to create an Air Force Academy. More
importantly Pentagon budgets began to shift more and more to air power in both
the Air Force and the Naval Air Force.
It's been a long and frustrating fight in the AAA dating back to Bob Anthony
when it was beginning to dawn on genuine accountants that we had created an
accountics scientist monster.
I don't know if you were present when Bob Anthony gave his 1989 Outstanding
Educator Award Address to the American Accounting Association. It was one of the
harshest indictments I've ever heard concerning the sad state of academic
research in serving the accounting profession. Bob never held back on his
punches.
We built the most formidable military in the world by adapting to changes and
innovations. Eventually the Luddite accountics scientists will own up to the
fact they never did become real scientists and that their research methods and
models are just too limited and out of date. His colleague at Harvard, Bob
Kaplan, now carries on the laments of Bob Anthony.
Now that Kaplan’s video is available I cannot overstress the importance that
accounting educators and researchers watch the video of Bob Kaplan's August 4,
2010 plenary presentation
http://commons.aaahq.org/hives/531d5280c3/posts?postTypeName=session+video
Don’t miss the history map of Africa analogy to academic accounting
research!!!!!
The accountics scientist monopoly of our doctoral programs is just not a
sustainable model. But don't expect miracles overnight. For 40 years our
accounting doctoral graduates have never learned any research methods other than
those analytical and inference models favored by accountics scientists.
Respectfully,
Bob Jensen
Appendix 1
Business Firms and Business School Teachers Largely Ignore
TAR Research Articles
Accounting Scholarship that Advances Professional Knowledge and Practice
Robert S. Kaplan
The Accounting Review, March 2011, Volume 86, Issue 2,
Recent accounting scholarship has
used statistical analysis on asset prices, financial reports and
disclosures, laboratory experiments, and surveys of practice. The research
has studied the interface among accounting information, capital markets,
standard setters, and financial analysts and how managers make accounting
choices. But as accounting scholars have focused on understanding how
markets and users process accounting data, they have distanced themselves
from the accounting process itself. Accounting scholarship has failed to
address important measurement and valuation issues that have arisen in the
past 40 years of practice. This gap is illustrated with missed opportunities
in risk measurement and management and the estimation of the fair value of
complex financial securities. This commentary encourages accounting scholars
to devote more resources to obtaining a fundamental understanding of
contemporary and future practice and how analytic tools and contemporary
advances in accounting and related disciplines can be deployed to improve
the professional practice of accounting. ©2010 AAA
Although all three speakers
provided inspirational presentations, Steve Zeff and I both concluded that Bob
Kaplan’s presentation was possibly the best that we had ever viewed among all
past AAA plenary sessions. And we’ve seen a lot of plenary sessions in our long
professional careers.
Now that Kaplan’s video is
available I cannot overstress the importance that accounting educators and
researchers watch the video of Bob Kaplan's August 4, 2010 plenary presentation
Note that to watch the entire Kaplan video ---
http://commons.aaahq.org/hives/531d5280c3/posts?postTypeName=session+video
I think the video is only available to AAA members.
Don’t miss the history map of Africa analogy to academic accounting
research!!!!!
This dovetails with my Web document at
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
Also see (slow loading)
http://faculty.trinity.edu/rjensen/theory01.htm#WhatWentWrong
Trivia Questions
1. Why did Bob wish he’d worn a different color suit?
2. What does JAE stand for
besides the Journal of Accounting and Economics?
PS
I think Bob Kaplan overstates the value of the academic valuation models in
leading accounting research journals, at least he overvalues their importance to
our practicing profession.
September 9, 2011 reply from Paul Williams
Bob,
I have avoided chiming in on this thread; have gone down this same road and
it is a cul-de-sac. But I want to say that this line of argument is a
clever one. The answer to your rhetorical question is, No, they aren't
more ethical than other "scientists." As you tout the Kaplan
speech I would add the caution that before he raised the issue of practice,
he still had to praise the accomplishments of "accountics" research by
claiming numerous times that this research has led us to greater
understanding about analysts, markets, info. content, contracting, etc.
However, none of that is actually true. As a panelist at the AAA
meeting I juxtaposed Kaplan's praise for what accountics research has taught
us with Paul Krugman's observations about Larry Summer's 1999 observation
that GAAP is what makes US capital markets so stable and efficient. Of
course, as Krugman noted, none of that turned out to be true. And if
that isn't true, then Kaplan's assessment of accountics research isn't
credible, either. If we actually did understand what he claimed we now
understand much better than we did before, the financial crisis of 2008
(still ongoing) would not have happened. The title of my talk was (the
panel was organized by Cheryl McWatters) "The Epistemology of
Ignorance." An obsessive preoccupation with method could be a choice not to
understand certain things-- a choice to rigorously understand things as you
already think they are or want so desperately to continue to believe for
reasons other than scientific ones.
Paul
A Pair of Grumpy Old Accountants Ask a Question About Accounting Leadership
Where Are the Accounting Profession's Leaders?
By: Anthony H. Catanach Jr. and J. Edward Ketz
SmartPros, May 2011
http://accounting.smartpros.com/x71917.xml
These are the concluding remarks by Tony and Ed:
Tom Selling has gone so far
as to suggest that part of the audit model problem might be that:
…auditors might be
good at verification of things which are capable of being verified, and
very little else.
If Tom is right, then we may
be closer to the edge of the fall than we realized, and too late for even
credible leadership to help.
Jensen Comment
I still don't see why financial statements cannot have multiple columns with the
first column devoted to measurement that auditors can verify such as amortized
historical costs. Then we can add more columns as verification drifts off into
the foggy ether of fair value accounting and changes in earnings that may or may
not ever be realized (e.g., not ever for held-to-maturity assets and liabilities
that will not be liquidated until maturity).
As to leadership, don't look to our academy for
leaders in the profession. Academe was overtaken decades by accountics faculty
who really do not make many if any significant contributions to practitioner
journals, the AICPA, the IMA, and other professional bodies except in certain
specialized subtopics like AIS, history, and tax ---
http://faculty.trinity.edu/rjensen/Theory01.htm#WhatWentWrong
Accounting Scholarship that Advances Professional
Knowledge and Practice
Robert S. Kaplan
The Accounting Review, March 2011, Volume 86, Issue 2,
Recent accounting scholarship has used statistical analysis on asset prices,
financial reports and disclosures, laboratory experiments, and surveys of
practice. The research has studied the interface among accounting
information, capital markets, standard setters, and financial analysts and
how managers make accounting choices. But as accounting scholars have
focused on understanding how markets and users process accounting data, they
have distanced themselves from the accounting process itself. Accounting
scholarship has failed to address important measurement and valuation issues
that have arisen in the past 40 years of practice. This gap is illustrated
with missed opportunities in risk measurement and management and the
estimation of the fair value of complex financial securities. This
commentary encourages accounting scholars to devote more resources to
obtaining a fundamental understanding of contemporary and future practice
and how analytic tools and contemporary advances in accounting and related
disciplines can be deployed to improve the professional practice of
accounting. ©2010 AAA
Although all three speakers provided inspirational presentations, Steve Zeff and
I both concluded that Bob Kaplan’s presentation was possibly the best that we
had ever viewed among all past AAA plenary sessions. And we’ve seen a lot of
plenary sessions in our long professional careers.
Now that Kaplan’s
video is available I cannot
overstress the importance that accounting educators and researchers watch the
video of Bob Kaplan's August 4, 2010 plenary presentation
Note
that to watch the entire Kaplan video ---
http://commons.aaahq.org/hives/531d5280c3/posts?postTypeName=session+video
I think the video is only available to AAA members.
Don’t miss the history map of Africa analogy to academic accounting
research!!!!!
If the AAA adopts my proposed electronic Supplemental Commentaries and
Replication Abstracts, the journal may fail for one nagging problem. There
is little interest in TAR articles among among accounting practitioners,
business firms, and business school teachers. If there is little interest in the
original studies, there will be even less interest in replicating those studies.
In her Presidential Message at the AAA annual meeting in San Francisco in
August, 2005, Judy Rayburn addressed the low citation rate of accounting
research when compared to citation rates for research in other fields. Rayburn
concluded that the low citation rate for accounting research was due to a lack
of diversity in topics and research methods:
Accounting research is different from other
business disciplines in the area of citations: Top-tier accounting journals
in total have fewer citations than top-tier journals in finance, management,
and marketing. Our journals are not widely cited outside our discipline. Our
top-tier journals as a group project too narrow a view of the breadth and
diversity of (what should count as) accounting research.
“President’s Message,” Accounting Education News
33 (1): Page 4.
The following is a quote from an
earlier 1993 President’s Message by Gary Sundem,
Although empirical scientific method has made many positive
contributions to accounting research, it is not the
method that is likely to generate new theories, though
it will be useful in testing them. For example,
Einstein’s theories were not developed empirically, but
they relied on understanding the empirical evidence and
they were tested empirically. Both the development and
testing of theories should be recognized as acceptable
accounting research.
"President’s Message," Accounting Education News 21
(3). Page 3.
“An Analysis of the Evolution of Research Contributions by The
Accounting Review: 1926-2005”
by Jean Heck and Robert E. Jensen, A
Accounting Historians Journal, Volume 34, No. 2, December 2007, pp.
109-142
http://faculty.trinity.edu/rjensen/395wpTAR/Web/TAR395wp.htm
|
In the first 40
years of TAR, an accounting “scholar” was first and foremost an
expert on accounting. After 1960, following the Gordon and Howell
Report, the perception of what it took to be a “scholar” changed to
quantitative modeling. It became advantageous for an “accounting”
researcher to have a degree in mathematics, management science,
mathematical economics, psychometrics, or econometrics. Being a mere
accountant no longer was sufficient credentials to be deemed a
scholarly researcher. Many doctoral programs stripped much of the
accounting content out of the curriculum and sent students to
mathematics and social science departments for courses. Scholarship
on accounting standards became too much of a time diversion for
faculty who were “leading scholars.” Particularly relevant in this
regard is Dennis Beresford’s address to the AAA membership at the
2005 Annual AAA Meetings in San Francisco:
In my eight years in
teaching I’ve concluded that way too many of us don’t stay
relatively up to date on professional issues. Most of us have some
experience as an auditor, corporate accountant, or in some similar
type of work. That’s great, but things change quickly these days.
Beresford [2005]
Jane Mutchler made
a similar appeal for accounting professors to become more involved
in the accounting profession when she was President of the AAA [Mutchler,
2004, p. 3].
In the last 40
years, TAR’s publication preferences shifted toward problems
amenable to scientific research, with esoteric models requiring
accountics skills in place of accounting expertise. When Professor
Beresford attempted to publish his remarks, an Accounting
Horizons referee’s report to him contained the following
revealing reply about “leading scholars” in accounting research:
1. The paper provides
specific recommendations for things that accounting academics should
be doing to make the accounting profession better. However (unless
the author believes that academics' time is a free good) this would
presumably take academics' time away from what they are currently
doing. While following the author's advice might make the accounting
profession better, what is being made worse? In other words, suppose
I stop reading current academic research and start reading news
about current developments in accounting standards. Who is made
better off and who is made worse off by this reallocation of my
time? Presumably my students are marginally better off, because I
can tell them some new stuff in class about current accounting
standards, and this might possibly have some limited benefit on
their careers. But haven't I made my colleagues in my department
worse off if they depend on me for research advice, and haven't I
made my university worse off if its academic reputation suffers
because I'm no longer considered a leading scholar? Why does
making the accounting profession better take precedence over
everything else an academic does with their time?
As quoted in Jensen [2006a]
The above quotation
illustrates the consequences of editorial policies of TAR and
several other leading accounting research journals. To be considered
a “leading scholar” in accountancy, one’s research must employ
mathematically-based economic/behavioral theory and quantitative
modeling. Most TAR articles published in the past two decades
support this contention. But according to AAA President Judy Rayburn
and other recent AAA presidents, this scientific focus may not be in
the best interests of accountancy academicians or the accountancy
profession.
In terms of
citations, TAR fails on two accounts. Citation rates are low in
practitioner journals because the scientific paradigm is too narrow,
thereby discouraging researchers from focusing on problems of great
interest to practitioners that seemingly just do not fit the
scientific paradigm due to lack of quality data, too many missing
variables, and suspected non-stationarities. TAR editors are loath
to open TAR up to non-scientific methods so that really interesting
accounting problems are neglected in TAR. Those non-scientific
methods include case method studies, traditional historical method
investigations, and normative deductions.
In the other
account, TAR citation rates are low in academic journals outside
accounting because the methods and techniques being used (like CAPM
and options pricing models) were discovered elsewhere and accounting
researchers are not sought out for discoveries of scientific methods
and models. The intersection of models and topics that do appear in
TAR seemingly are borrowed models and uninteresting topics outside
the academic discipline of accounting.
We close with a
quotation from Scott McLemee demonstrating that what happened among
accountancy academics over the past four decades is not unlike what
happened in other academic disciplines that developed “internal
dynamics of esoteric disciplines,” communicating among themselves in
loops detached from their underlying professions. McLemee’s [2006]
article stems from Bender [1993].
“Knowledge and
competence increasingly developed out of the internal dynamics of
esoteric disciplines rather than within the context of shared
perceptions of public needs,” writes Bender. “This is not to say
that professionalized disciplines or the modern service professions
that imitated them became socially irresponsible. But their
contributions to society began to flow from their own
self-definitions rather than from a reciprocal engagement with
general public discourse.”
Now, there is a definite note of sadness in Bender’s narrative – as
there always tends to be in accounts
of the
shift from Gemeinschaft to
Gesellschaft. Yet it is also
clear that the transformation from civic to disciplinary
professionalism was necessary.
“The new disciplines offered relatively precise subject matter and
procedures,” Bender concedes, “at a time when both were greatly
confused. The new professionalism also promised guarantees of
competence — certification — in an era when criteria of intellectual
authority were vague and professional performance was unreliable.”
But in the epilogue to Intellect and Public Life,
Bender suggests that the process eventually went too far. “The risk
now is precisely the opposite,” he writes. “Academe is threatened by
the twin dangers of fossilization and scholasticism (of three types:
tedium, high tech, and radical chic). The agenda for the next
decade, at least as I see it, ought to be the opening up of the
disciplines, the ventilating of professional communities that have
come to share too much and that have become too self-referential.”
For the good of the AAA membership and the profession of accountancy
in general, one hopes that the changes in publication and editorial
policies at TAR proposed by President Rayburn [2005, p. 4] will
result in the “opening up” of topics and research methods produced
by “leading scholars.”
The Two Faces of Accountics Scientists
Accountics scientists have almost a knee jerk, broken record reaction when
confronted with case method/small sample research as evidenced by SHAHID
ANSARI's review of the following book ---
Click Here
ROBERT S. KAPLAN and DAVID P. NORTON , The Execution Premium: Linking
Strategyto Operations for Competitive Advantage �Boston,
MA: Harvard Business Press, 2008,ISBN 13: 978-1-4221-2116-0, pp. xiii, 320.
If you are an academician who believes in empirical
data and rigorous statistical analysis, you will find very little of it in
this book. Most of the data in this book comes from Harvard Business School
teaching cases or from the consulting practice of Kaplan and Norton. From an
empirical perspective, the flaws in the data are obvious. The sample is
nonscientific; it comes mostly from opportunistic interventions. It is a bit
paradoxical that a book which is selling a rational-scientific methodology
for strategy development and execution uses cases as opposed to a matched or
paired sample methodology to show that the group with tight linkage between
strategy execution and operational improvement has better results than one
that does not. Even the data for firms that have performed well with a
balanced scorecard and other mechanisms for sound strategy execution must be
taken with a grain of salt.
Bob Jensen has a knee jerk, broken record reaction to accountics scientists
who praise their own "empirical data and rigorous statistical analysis." My
reaction to them is to show me the validation/replication of their
"empirical data and rigorous statistical analysis." that is replete with missing
variables and assumptions of stationarity and equilibrium conditions that are
often dubious at best. Most of their work is so uninteresting that even they
don't bother to validate/replicate each others' research ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
|
|
"Research
on Accounting Should Learn From the Past"
by Michael H. Granof and Stephen A. Zeff
Chronicle of Higher Education, March 21, 2008 |
|
Starting in the 1960s, academic research on accounting became
methodologically supercharged — far more quantitative and analytical
than in previous decades. The results, however, have been
paradoxical. The new paradigms have greatly increased our
understanding of how financial information affects the decisions of
investors as well as managers. At the same time, those models have
crowded out other forms of investigation. The result is that
professors of accounting have contributed little to the
establishment of new practices and standards, have failed to perform
a needed role as a watchdog of the profession, and have created a
disconnect between their teaching and their research.
Before the 1960s, accounting research was primarily descriptive.
Researchers described existing standards and practices and suggested
ways in which they could be improved. Their findings were taken
seriously by standard-setting boards, CPA's, and corporate officers.
A
confluence of developments in the 1960s
markedly changed the nature of research — and, as a
consequence, its impact on practice. First, computers emerged as a
means of collecting and analyzing vast amounts of information,
especially stock prices and data drawn from corporate financial
statements. Second, academic accountants themselves recognized the
limitations of their methodologies. Argument, they realized, was no
substitute for empirical evidence. Third, owing to criticism that
their research was decidedly second rate because it was
insufficiently analytical, business faculties sought academic
respectability by employing the methods of disciplines like
econometrics, psychology, statistics, and mathematics.
In response to those developments, professors of accounting not only
established new journals that were restricted to metric-based
research, but they limited existing academic publications to that
type of inquiry. The most influential of the new journals was the
Journal of Accounting Research, first published in 1963 and
sponsored by the University of Chicago Graduate School of Business.
Acknowledging the primacy of the journals, business-school chairmen
and deans increasingly confined the rewards of publication
exclusively to those publications' contributors. That policy was
applied initially at the business schools at private colleges that
had the strongest M.B.A. programs. Then ambitious business schools
at public institutions followed the lead of the private schools,
even when the public schools had strong undergraduate and master's
programs in accounting with successful traditions of
practice-oriented research.
The unintended consequence has been that interesting and
researchable questions in accounting are essentially being ignored.
By confining the major thrust in research to phenomena that can be
mathematically modeled or derived from electronic databases,
academic accountants have failed to advance the profession in ways
that are expected of them and of which they are capable.
Academic research has unquestionably broadened the views of
standards setters as to the role of accounting information and how
it affects the decisions of individual investors as well as the
capital markets. Nevertheless, it has had scant influence on the
standards themselves.
The research is hamstrung by restrictive and sometimes artificial
assumptions. For example, researchers may construct mathematical
models of optimum compensation contracts between an owner and a
manager. But contrary to all that we know about human behavior, the
models typically posit each of the parties to the arrangement as a
"rational" economic being — one devoid of motivations other than to
maximize pecuniary returns.
Moreover, research is limited to the homogenized content of
electronic databases, which tell us, for example, the prices at
which shares were traded but give no insight into the decision
processes of either the buyers or the sellers. The research is thus
unable to capture the essence of the human behavior that is of
interest to accountants and standard setters.
Further, accounting researchers usually look backward rather than
forward. They examine the impact of a standard only after it has
been issued. And once a rule-making authority issues a standard,
that authority seldom modifies it. Accounting is probably the only
profession in which academic journals will publish empirical studies
only if they have statistical validity. Medical journals, for
example, routinely report on promising new procedures that have not
yet withstood rigorous statistical scrutiny.
Floyd Norris, the chief financial correspondent of The New York
Times, titled a 2006 speech to the American Accounting Association
"Where Is the Next Abe Briloff?" Abe Briloff is a rare academic
accountant. He has devoted his career to examining the financial
statements of publicly traded companies and censuring firms that he
believes have engaged in abusive accounting practices. Most of his
work has been published in Barron's and in several books — almost
none in academic journals. An accounting gadfly in the mold of Ralph
Nader, he has criticized existing accounting practices in a way that
has not only embarrassed the miscreants but has caused the
rule-making authorities to issue new and more-rigorous standards. As
Norris correctly suggested in his talk, if the academic community
had produced more Abe Briloffs, there would have been fewer
corporate accounting meltdowns.
The narrow focus of today's research has also resulted in a
disconnect between research and teaching. Because of the difficulty
of conducting publishable research in certain areas — such as
taxation, managerial accounting, government accounting, and auditing
— Ph.D. candidates avoid choosing them as specialties. Thus, even
though those areas are central to any degree program in accounting,
there is a shortage of faculty members sufficiently knowledgeable to
teach them.
To be sure, some accounting research, particularly that pertaining
to the efficiency of capital markets, has found its way into both
the classroom and textbooks — but mainly in select M.B.A. programs
and the textbooks used in those courses. There is little evidence
that the research has had more than a marginal influence on what is
taught in mainstream accounting courses.
What needs to be done? First, and most significantly, journal
editors, department chairs, business-school deans, and
promotion-and-tenure committees need to rethink the criteria for
what constitutes appropriate accounting research. That is not to
suggest that they should diminish the importance of the currently
accepted modes or that they should lower their standards. But they
need to expand the set of research methods to encompass those that,
in other disciplines, are respected for their scientific standing.
The methods include historical and field studies, policy analysis,
surveys, and international comparisons when, as with empirical and
analytical research, they otherwise meet the tests of sound
scholarship.
Second, chairmen, deans, and promotion and merit-review committees
must expand the criteria they use in assessing the research
component of faculty performance. They must have the courage to
establish criteria for what constitutes meritorious research that
are consistent with their own institutions' unique characters and
comparative advantages, rather than imitating the norms believed to
be used in schools ranked higher in magazine and newspaper polls. In
this regard, they must acknowledge that accounting departments,
unlike other business disciplines such as finance and marketing, are
associated with a well-defined and recognized profession. Accounting
faculties, therefore, have a special obligation to conduct research
that is of interest and relevance to the profession. The current
accounting model was designed mainly for the industrial era, when
property, plant, and equipment were companies' major assets. Today,
intangibles such as brand values and intellectual capital are of
overwhelming importance as assets, yet they are largely absent from
company balance sheets. Academics must play a role in reforming the
accounting model to fit the new postindustrial environment.
Third, Ph.D. programs must ensure that young accounting researchers
are conversant with the fundamental issues that have arisen in the
accounting discipline and with a broad range of research
methodologies. The accounting literature did not begin in the second
half of the 1960s. The books and articles written by accounting
scholars from the 1920s through the 1960s can help to frame and put
into perspective the questions that researchers are now studying.
For example, W.A. Paton and A.C. Littleton's 1940 monograph, An
Introduction to Corporate Accounting Standards, profoundly shaped
the debates of the day and greatly influenced how accounting was
taught at universities. Today, however, many, if not most,
accounting academics are ignorant of that literature. What they know
of it is mainly from textbooks, which themselves evince little
knowledge of the path-breaking work of earlier years. All of that
leads to superficiality in teaching and to research without a
connection to the past.
We fervently hope that the research pendulum will soon swing back
from the narrow lines of inquiry that dominate today's leading
journals to a rediscovery of the richness of what accounting
research can be. For that to occur, deans and the current generation
of academic accountants must give it a push.
Michael H. Granof is a professor of accounting at the McCombs School
of Business at the University of Texas at Austin. Stephen A. Zeff is
a professor of accounting at the Jesse H. Jones Graduate School of
Management at Rice University.
March 18, 2008 reply from Paul Williams
[Paul_Williams@NCSU.EDU]
Steve Zeff has been saying this since
his stint as editor of The Accounting Review (TAR);
nobody has listened. Zeff famously wrote at least two editorials
published in TAR over 30 years ago that lamented the
colonization of the accounting academy by the intellectually
unwashed. He and Bill Cooper wrote a comment on Kinney's
tutorial on how to do accounting research and it was rudely
rejected by TAR. It gained a new life only when Tony Tinker
published it as part of an issue of Critical Perspectives in
Accounting devoted to the problem of dogma in accounting
research.
It has only been since less subdued
voices have been raised (outright rudeness has been the hallmark
of those who transformed accounting into the empirical
sub-discipline of a sub-discipline for which empirical work is
irrelevant) that any movement has occurred. Judy Rayburn's
diversity initiative and her invitation for Anthony Hopwood to
give the Presidential address at the D.C. AAA meeting came only
after many years of persistent unsubdued pointing out of things
that were uncomfortable for the comfortable to confront.
Paul Williams
paul_williams@ncsu.edu
(919)515-4436
|
"Top Business Schools Look to Social Scientists to Enhance Research,"
by Michael Stratford, Chronicle of Higher Education, May 13, 2012 ---
http://chronicle.com/article/Top-Business-Schools-Look-to/131850/
As a doctoral student at Yale University's
psychology department, George E. Newman became increasingly interested in
applying the theories he studied to people's business decisions.
He began exploring, for instance, why people prefer
buying original pieces of artwork over perfect duplicates and why they're
willing to pay a lot for celebrity possessions.
"What we found is that a lot of those decisions
have to do, importantly, with psychological essentialism," he said. "People
believe the objects contain some essence of their previous owners or
manufacturers."
Wanting to further pursue such application of his
psychology training, Mr. Newman accepted a postdoctoral appointment at
Yale's School of Management, and last year became an assistant professor
there.
The career path he has followed, as a social
scientist moving to a top-tier business school, is becoming relatively
common, particularly for Ph.D.'s in psychology, economics, and sociology. As
those institutions have sought to bolster and broaden their research,
they've been looking to hire faculty with strong scholarship in disciplines
outside of business. The prospect of teaching and researching at a business
school can be alluring to scholars, too. And a rough academic job market in
the social sciences has also helped push people with Ph.D.'s in that
direction.
Focus on
Research
Adam D. Galinsky, professor of ethics and decision
in management at the Kellogg School of Management at Northwestern
University, was trained as a social psychologist. Mr. Galinsky, who was
hired by Kellogg more than a decade ago, says he was among the first wave of
social scientists to join the faculties of top-tier business schools. The
push to hire more psychologists and sociologists, he says, was motivated by
the institutions' desire to improve the research they produced.
"There was a sense that the quality of research in
business schools was inadequate," he says. "The idea was to hire strong
discipline-based people and bring them into the business schools with their
strong foundation of research skills."
That trend may have started to slow recently, Mr.
Galinsky says, in part because of the improved training that business
schools can now offer because they have hired social scientists. As a
result, business-school graduates are more competitive when they apply for
faculty positions at business-schools that trained psychologists and other
social scientists are also seeking.
Many social scientists are attracted to business
schools because they provide an opportunity to approach fields of study from
more applied and interdisciplinary perspectives.
Victoria L. Brescoll, who completed her Ph.D. and
held a postdoctoral appointment at Yale's psychology department, is an
assistant professor of organizational behavior at Yale's School of
Management. She says that moving from a psychology department to a business
school was something she had always thought of doing, because her research
on how people are perceived at work is at the intersection of various
disciplines, including social psychology, women studies, communications, and
organizational studies.
"The distinctions between disciplines can be
somewhat artificial," she says. "Part of why I like being in the business
school is that I can do that kind of interdisciplinary work."
Ms. Brescoll says she enjoys the challenge of
considering an economic or business perspective to her work.
"You have to rethink what high-quality evidence is
because you have to think about it from the perspective of someone from a
totally different discipline," she says. "Things you might have taken for
granted, you just can't."
Job-Market
Pressures
For some Ph.D. candidates, the tight academic job
market can be an incentive to explore faculty positions at a business
school.
After completing his doctoral degree in social
psychology at Princeton University in 1999, Mr. Galinsky says he applied to
50 psychology departments and three business schools. He barely received any
responses from the psychology departments but heard back from two of the
business schools. He accepted a postdoctoral appointment at Kellogg. "It was
a path that was chosen for me," he says.
"For a lot of people interested in social
psychology, there are just not a lot of jobs in that field in general," says
Mr. Newman, the Yale professor who studies decision-making.
Moving from psychology to business is "not an
expected path at this point, but it is a common path," says Elanor F.
Williams, who completed her Ph.D. in social psychology at Cornell University
in 2008 and then accepted a postdoctoral appointment at the University of
Florida's Warrington College of Business. Her research focuses on how people
think in a social or realized context.
Though she applied to some psychology departments,
Ms. Williams says she focused her job search heavily on postdoctoral
positions at business schools because of the transition they can offer. In
her case, her postdoctoral appointment at Florida even paid for her to
participate in an eight-week program to train nonbusiness Ph.D.'s to teach
in business schools. The Post-Doctoral Bridge to Business Program was
started in 2007 by the Association to Advance Collegiate Schools of
Business, an accrediting agency, as business schools faced a shortage of
qualified professors to teach growing numbers of students.
Continued in article
Jensen Comment
It's not clear why business professors would "look to the social sciences for
research" since PhD programs focus mostly on graduating social scientists ---
http://faculty.trinity.edu/rjensen/Theory01.htm#DoctoralPrograms
"Business Education Under the Microscope:
Amid growing charges of irrelevancy, business schools launch a study of their
impact on business,"
Business Week, December 26, 2007 ---
http://www.businessweek.com/bschools/content/dec2007/bs20071223_173004.htm
The
business-school world has been besieged by criticism in the
past few months, with prominent professors and writers
taking bold swipes at management education. Authors such as
management expert Gary Hamel and
Harvard Business School Professor
Rakesh Khurana have published books this fall expressing
skepticism about the direction in which business schools are
headed and the purported value of an MBA degree. The
December/January issue of the Academy of Management
Journal includes a
special section in which 10 scholars question the value of
business-school research.
B-school
deans may soon be able to counter that criticism, following
the launch of an ambitious study that seeks to examine the
overall impact of business schools on society. A new Impact
of Business Schools task force convened by the Association
to Advance Collegiate Schools of Business (AACSB)—the main
organization of business schools—will mull over this
question next year, conducting research that will look at
management education through a variety of lenses, from
examining the link between business schools and economic
growth in the U.S. and other countries, to how management
ideas stemming from business-school research have affected
business practices. Most of the research will be new, though
it will build upon the work of past AACSB studies,
organizers said.
The
committee is being chaired by Robert Sullivan of the
University of California at San Diego's
Rady School of Management, and
includes a number of prominent business-school deans
including Robert Dolan of the University of Michigan's
Stephen M. Ross School of Business,
Linda Livingstone of Pepperdine University's
Graziado School of Business & Management, and
AACSB Chair Judy Olian, who is also the dean of UCLA's
Anderson School of Management.
Representatives from Google (GOOG)
and the Educational Testing Service will also participate.
The committee, which was formed this summer, expects to have
the report ready by January, 2009.
BusinessWeek.com reporter
Alison Damast recently spoke with Olian about the committee
and the potential impact of its findings on the
business-school community.
There has been a rising tide of
criticism against business schools recently, some of it from
within the B-school world. For example, Professor Rakesh
Khurana implied in his book
From Higher Aims to Hired Hands
(BusinessWeek.com, 11/5/07) that
management education needs to reinvent itself. Did this have
any effect on the AACSB's decision to create the Impact of
Business Schools committee?
I think that
is probably somewhere in the background, but I certainly
don't view that as in any way the primary driver or
particularly relevant to what we are thinking about here.
What we are looking at is a variety of ways of commenting on
what the impact of business schools is. The fact is, it
hasn't been documented and as a field we haven't really
asked those questions and we need to. I don't think a study
like this has ever been done before.
Continued in article
Bob Jensen's threads on the growing
irrelevance of academic accounting research are at
http://faculty.trinity.edu/rjensen/Theory01.htm#DoctoralPrograms
The dearth of research findings replications
---
http://faculty.trinity.edu/rjensen/Theory01.htm#Replication
Bob Jensen's threads on higher education
controversies are at
http://faculty.trinity.edu/rjensen/HigherEdControversies.htm
Hi Steve,
Thank you so much for providing such a detailed and permanent 2011 TAR fiscal
year annual report ended May 31, 2011 ---
http://aaajournals.org/
You are commended during your service as TAR Senior Editor for having to deal
with greatly increased numbers of submissions. This must've kept you up late
many nights in faithful service to the AAA. And writing letters of rejections to
friends and colleagues must've been a very painful chore at times. And having to
communicate repeatedly with so many associate editors and referees must've been
tough for so many years. I can understand why some TAR editors acquired health
problems. I'm grateful that you seem to still be healthy and vigorous.
I'm also grateful that you communicate with us on the AECM. This is more than
I can say for other former TAR editors and most AAA Executive Committee members
who not only ignore us on the AECM, but they also do not communicate very much
at all on the AAA Commons.
I'm really not replying to start another round of debate on the AECM using
your fine annual report. But I can't resist noting that I just do not see the
trend increasing for acceptance of papers that are not accountics science papers
appearing in TAR.
One of the tables of greatest interest to me is Panel D of Table 3 which is
shown below:
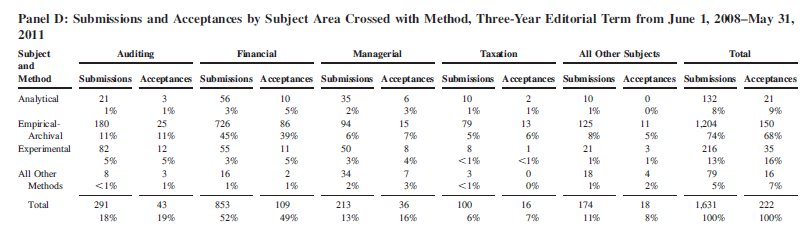
What you define as "All Other Methods" comprises 7% leaving 93% for
Analytical, Empirical Archival, and Experimental. However, this does not
necessarily mean that 7% of the acceptances did not contain mathematical
equations and statistical testing such that what I would define as accountics
science acceptances for 2011 constitute something far greater than 93%. For
example, you've already pointed out to us that case method and field study
papers published in TAR during 2011 contain statistical inference testing and
equations. They just do not meet the formal tests as having random samples.
Presidential scholar papers are published automatically (e.g., Kaplan's March
2011) paper, such that perhaps only 15 accepted Other Methods papers passed
through the refereeing process. Your July 2011 Editorial was possibly included
in the Other Methods such that possibly only 13 Other Methods papers passed
through the refereeing process. And over half of these were "Managerial" and
most of those contain equations such that 2011 was a typical year in which
nearly all the published TAR papers in 2011 meet my definition of accountics
science (some of which do not have scientific samples) ---
http://faculty.trinity.edu/rjensen/395wpTAR/Web/TAR395wp.htm
We can conclude that in 2011 that having equations in papers accepted by
referees was virtually a necessary condition for acceptance by referees in 2011
as has been the case for decades.
Whatever happened to accounting history publications in TAR? Did accounting
historians simply give up on getting a TAR hit?
Whatever happened to normative method papers if they do not meet the
mathematical tests of being Analytical?
Whatever happened to scholarly commentary?
November 22, 2011 reply from Steve Kachelmeier
First, Table 3 in the 2011 Annual Report
(submissions and acceptances by area) only includes manuscripts that went
through the regular blind reviewing process. That is, it excludes invited
presidential scholar lectures, editorials, book reviews, etc. So "other"
means "other regular submissions."
Second, you are correct Bob that "other" continues
to represent a small percentage of the total acceptances. But "other" is
also a very small percentage of the total submissions. As I state explicitly
in the report, Table 3 does not prove that TAR is sufficienty diverse. It
does, however, provide evidence that TAR acceptances by topical area (or by
method) are nearly identically proportional to TAR submissions by topical
area (or by method).
Third, for a great example of a recently published
TAR study with substantial historical content, see Madsen's analysis of the
historical development of standardization in accounting that we published in
in the September 2011 issue. I conditionally accepted Madsen's submission in
the first round, backed by favorable reports from two reviewers with
expertise in accounting history and standardization.
Take care,
Steve
November 23, 2011 reply from Bob Jensen
Hi Steve,
Thank you for the clarification.
Interestingly, Madsen's September 2011 historical study (which came out
after your report's May 2011 cutoff date) is a heavy accountics science
paper with a historical focus.
It would be interesting to whether such a paper would've been accepted by
TAR referees without the factor (actually principal components analysis).
Personally, I doubt any history paper would be accepted without equations
and quantitative analysis. In the case of Madsen's paper, if I were a
referee I would probably challenge the robustness of the principal
components and loadings ---
http://en.wikipedia.org/wiki/Principle_components_analysis
Actually factor analysis in general like nonlinear multiple regression and
adaptive versions thereof suffer greatly from lack of robustness. Sometimes
quantitative models gild the lily to a fault.
Bob Kaplan's Presidential Scholar historical study was published, but
this was not subjected to the usual TAR refereeing process.
The History of The Accounting Review paper written by Jean Heck and Bob
Jensen which won a best paper award from the Accounting Historians Journal
was initially flatly rejected by TAR. I was never quite certain if the main
reason was that it did not contain equations or if the main reason was that
it was critical of TAR editorship and refereeing. In any case it was flatly
rejected by TAR, including a rejection by one referee who refused to put
reasons in writing for feed\back to Jean and me.
“An Analysis of the Evolution of Research Contributions by The
Accounting Review: 1926-2005,” (with Jean Heck), Accounting
Historians Journal, Volume 34, No. 2, December 2007, pp. 109-142.
I would argue that accounting history papers, normative methods papers,
and scholarly commentary papers (like Bob Kaplan's plenary address) are not
submitted to TAR because of the general perception among the AAA membership
that such submissions do not have a snowball's chance in Hell of being
accepted unless they are also accountics science papers.
It's a waste of time and money to submit papers to TAR that are not
accountics science papers.
In spite of differences of opinion, I do thank you for the years of
blood, sweat, and tears that you gave us as Senior Editor of TAR.
And I wish you and all U.S. subscribers to the AECM a very Happy
Thanksgiving. Special thanks to Barry and Julie and the AAA staff for
keeping the AECM listserv up and running.
Respectfully,
Bob Jensen
Tribute to Bob Anthony from Jake Birnberg and Bob Jensen and Others
Bob Anthony is probably best known as an extremely successful accounting
textbook author ---
http://www.amazon.com/Robert-N.-Anthony/e/B001IGJT5W
But there were many other career highlights of the great professor and my
personal friend.
"Robert N. Anthony: A Pioneering Thinker in Management Accounting," by Jacob
G. Birnberg, Accounting Horizons, 2011, Vol. 25, No. 3, pp. 593–602 ---
http://aaapubs.aip.org/getpdf/servlet/GetPDFServlet?filetype=pdf&id=ACHXXX000025000003000593000001&idtype=cvips&prog=normal
(not a free article to non-subscribers)
By any measure, Robert Newton Anthony (1916–2006)
was a giant among 20th century academic accountants. After obtaining a
Bachelor’s degree from Colby College, he matriculated to the Harvard
Business School (HBS), where he earned his M.B.A. and D.B.A. degrees. Bob
spent his entire academic career at HBS, retiring in 1983. He is best known
as a prolific writer of articles, textbooks, and research reports. He was
inducted as a member of the Accounting Hall of Fame (1986), was a recipient
of the American Accounting Association’s (AAA) Outstanding Accounting
Educator Award (1989), and then was the second recipient of the AAA
Management Accounting Section’s Lifetime Contribution to Management
Accounting Award (2003), as well as serving as President of the American
Accounting Association (1973–1974). In addition, he was elected a Fellow of
the Academy of Management (1970). These honors indicate that he was, indeed,
a significant contributor to the development of his chosen field of
management accounting for over 50 years, and highly respected by his peers.
They do not indicate why. My intention is to answer that question.
Bob Anthony was the ideal person to be a leader in
the post-World War II movement that changed cost accounting into management
accounting. He possessed broad interests and not only was an academic, but
also was interested in solving problems found in the real world. He was
equally comfortable working as an academic and as a manager. He served as
Under Secretary (Comptroller) in the Department of Defense for his old
friend and fellow Harvard Business School graduate, Robert S. McNamara, from
1965 to 1968. While at the Department, Anthony earned the Defense Department
Award for Public Service for developing a system of cost management and
control for the Department (Harvard University Gazette 2006)...
Continued in article
Jensen Comment
The takeover of the academic accounting research by accountics scientists was
fought off in the 1920s but commenced again in earnest in the 1960s as
documented by Heck and Jensen along a timeline at
http://faculty.trinity.edu/rjensen/395wpTAR/Web/TAR395wp.htm
"We
fervently hope that the research pendulum will soon swing back from the narrow
lines of inquiry that dominate today's leading journals to a rediscovery of the
richness of what accounting research can be. For that to occur, deans and the
current generation of academic accountants must
give it a push."
"Research
on Accounting Should Learn From the Past," by Michael H. Granof and Stephen
A. Zeff , Chronicle of Higher Education, March 21, 2008
http://www.trinity.edu/rjensen/TheoryTAR.htm#Appendix01
Although it's common among various recent Presidents of the American
Accounting Association (e.g.,
Judy Rayburn and
Greg Waymire) and AAA Presidential Address Scholars, e.g., Tony Hopwood ("Whither
Accounting Research?" The Accounting Review 82(5), 2007, pp.1365-1374
)and Bob Kaplan (Accounting Scholarship that Advances
Professional Knowledge and Practice," The Accounting Review, March 2011,
Volume 86, Issue 2) , perhaps the earliest and most scathing lament
accountics scientist takeover of AACSB doctoral programs and the top tier
academic accounting research journals came from former AAA President Bob Anthony
in his1989 AAA membership as that years Outstanding Educator Award
recipient. This was an oral address, and I don't think there is any record of
Bob's scathing lament in front of the AAA membership. Nor is there a record to
my knowledge of the subsequent lament on the same matters by AAA's 1990
President Al Arens year later.
In some ways I was a guinea pig for Bob Anthony. In the late 1960s and into
the 1990s, Bob lacked the mathematical background to understand the exploding
interest by accounting researchers in accountics, particularly mathematical
programming, management science, decision science, and operations research in
the years that Herb Simon were achieving worldwide fame at Carnegie-Mellon
University that in some ways was leaving venerable old Harvard in the dust. Bob
Anthony followed my career as an accounting PhD graduate from Stanford who had
been teaching mathematical programming at Michigan State University and the
University of Maine. Bill Kinney and Bob May and other accounting doctoral
candidates at MSU in the late 1960s probably recall my mathematical programming
doctoral seminars.
Bob Anthony invited me to make accountics science presentations at the
Harvard Business School and at an alumni-day programs that he organized for his
Colby College alma mater following my seven TAR publications 1967-1979 ---
http://maaw.info/TheAccountingReview2.htm
I remember that he was particularly skeptical of my praise of shadow pricing
in linear programming, which was also at the core of a doctoral thesis by Joel
Demski in those days. I was always careful to point out the limitations of
mathematical programming when solutions spaces were not convex. But Bob Anthony
had a deeper suspicion, which he had trouble articulating in those days, that
accounting information played a vital role in systems that were too complex and
too non-stationary to model in the real world, especially model to a point where
we could declare solutions "optimal" for the real and ever-changing world of
complicated human beings and their organizations. Anthony Hopwood built upon
this same theme when he founded a successful journal called Accounting,
Organizations, and Society (AOS).
It's not that Bob Anthony opposed our accountics science research. What he
opposed is accountics science (read that positivism) takeover of the
doctoral programs and academic research journals. What he felt down deep that
accountics science was just too easy. We could build our analytical models and
devise "optimal" solutions without having to set foot from the campus into a
real world. We could build ever-increasingly sophisticated data analysis models
using the CRSP and Compustat database without having to sweat buckets collecting
financial data first-hand in the real world. We could conduct accounting
behavioral research models pretending that student subjects were adequate
surrogates making pretend that they were real-world managers and accountants.
I suspect that Bob Anthony followed Bob Kaplan's career with great interest.
In those early years, Bob Kaplan was an accountics faculty member and eventually
Dean at Carnie-Mellon in the years that Professor and Dean Kaplan was heavy into
mathematics and decision science. Then Bob Kaplan became more interested in the
real world and eventually traveled between Harvard and Carnegie as a joint
accounting professor. I suspect Bob Anthony influenced Bob Kaplan into taking up
more and more case-method research and the eventual decision of Kaplan to become
a full-time accounting professor at Harvard (the case method school in those
days) in place of Carnegie-Mellon (the quantitative-methods school in those
days). Of course in recent years the difference between the Harvard versus
Carnegie schools is not demarked so clearly as it was in the 1970s.
In any case Bob Anthony and I corresponded intermittently throughout most of
my career. He was particularly pleased when I became more and more skeptical of
the accountics science takeover of accounting doctoral programs and top-tier
academic accounting research journals. Once again, however, I stress that it was
not so much that we were disappointed in accountics science that was becoming
increasingly sophisticated and respectable. Rather Bob Anthony, Bob Kaplan, and
Bob Jensen along with Bob Sterling, Paul Williams, Anthony Hopwood, and others
became increasingly disturbed about the takeover by Zimmerman and Watts and
their positivism disciples. In those same years Demski and Feltham were
rewriting the quantitative information economics standards of what constitutes
scholarly research in accounting.
On January 3, 2007 I wrote a Tidbit that reads as follows:
http://faculty.trinity.edu/rjensen/tidbits/2007/tidbits070103.htm
We will greatly miss Bob Anthony
December 20, 2006
message from Bill McCarthy
[mccarthy@bus.msu.edu]
The following appeared
on Boston.com:
Headline: Robert Anthony; reshaped Pentagon budget process
Date: December 20, 2006
"At the behest of Robert
S. McNamara, his longtime friend, Robert N.Anthony set aside scholarly
pursuits at Harvard Business School in the mid-1960s to take a key role
reshaping the budget process for the Defense Department."
____________________________________________________________
To see this
recommendation, click on the link below or cut and paste it into a Web
browser:
http://www.boston.com/news/globe/obituaries/articles/2006/12/20/robert_anthony_reshaped_pentagon_budget_process?p1=email_to_a_friend
December 20, 2006 reply
from Bob Jensen
Hi Bill,
Thank you! Bob has
been a longtime great friend. His obituary is at
http://www.hbs.edu/news/120506_anthonyobit.html
What is really amazing is the wide range of long-time service to at very
high levels, including serving on the FASB as well as being Defense
Department's Assistant Secretary (Comptroller) during the Viet Nam War.
He also received the Defense Department's Medal for Distinguished Public
Service. The FASB requested that Bob focus on accounting for nonprofit
organizations. He also served as President of the American Accounting
Association.
Bob was one of the
most distinguished professors of the Harvard Business School It saddens
me greatly to see him pass on. His Hall of Fame link is at
http://fisher.osu.edu/Departments/Accounting-and-MIS/Hall-of-Fame/Membership-in-Hall/Robert-Newton-Anthony/
Or
Click Here
I
don't know if you were present when Bob Anthony gave his 1989
Outstanding Educator Award Address to the American Accounting
Association. It was one of the harshest indictments I've ever heard
concerning the sad state of academic research in serving the accounting
profession.
Bob never held back on his punches.
Bob Jensen
December 20, 2006 reply from Denny Beresford
[DBeresfo@TERRY.UGA.EDU]
(Denny was Chairman of the FASB when Bob was a special consultant to the
FASB)
Bob,
Yesterday's New York Times also included an
obituary for Bob Anthony . . . Bob wasn't the easiest person to get
along with, but I considered him to be one of the very brightest people
I ever associated with. He was a wonderful writer and I always enjoyed
the letters and other things he sent me at the FASB and later - even
when I disagreed completely with his ideas. His work with the government
made him one of the most generally influential accountants of the 20th
century, I believe.
Denny
His accounting concepts ranged from the global
to the provincial. In a 1970 letter to The New York Times, he proposed that
the United States create a tax surcharge to cover damages to the Soviet
Union in the event of an accidental American nuclear strike. The tax burden
would be “the smallest consequence of maintaining a nuclear arsenal,” he
wrote. “An all-out nuclear exchange would probably mean the end of
civilization.” In the late 1980s, Professor Anthony moved to Waterville
Valley, N.H., where for 10 years he was the town’s elected auditor. “I got
24 votes last year; that’s all there were,” he once said.
<http://www.nytimes.com/pages/business/index.html>
Added Jensen Comment
I often suspected that Bob Anthony's 1980s move to New Hampshire (that created
an extremely long commute to Cambridge, Taxachusetts) was motivated in large
part by the huge financial successes of his book royalties. I would not blame
him for this move since there's nothing criminal or immoral about taking
advantage of tax law opportunities. Then again he may simply wanted to be closer
to our mountains and forests ---
http://faculty.trinity.edu/rjensen/Pictures.htm
"Why Business Ignores the
Business Schools"
by Michael Skapinker
Financial Times, January 7, 2008
Chief executives, on the other hand, pay little
attention to what business schools do or say. As long ago as 1993, Donald
Hambrick, then president of the US-based Academy of Management, described
the business academics' summer conference as "an incestuous closed loop", at
which professors "come to talk with each other". Not much has changed. In
the current edition of
The Academy of Management Journal.
. . .
They have chosen an auspicious occasion on which to
beat themselves up: this year is The Academy of Management Journal's 50th
anniversary. A scroll through the most recent issues demonstrates why
managers may be giving the Journal a miss. "A multi-level investigation of
antecedents and consequences of team member boundary spanning behaviour" is
the title of one article.
Why do business academics write like this? The
academics themselves offer several reasons. First, to win tenure in a US
university, you need to publish in prestigious peer-reviewed journals.
Accessibility is not the key to academic advancement.
Similar pressures apply elsewhere. In France and
Australia, academics receive bonuses for placing articles in the top
academic publications. The UK's Research Assessment Exercise, which
evaluates university research and ties funding to the outcome, encourages
similarly arcane work.
But even without these incentives, many business
school faculty prefer to adorn their work with scholarly tables, statistics
and jargon because it makes them feel like real academics. Within the
university world, business schools suffer from a long-standing inferiority
complex.
The professors offer several remedies. Academic
business journals should accept fact-based articles, without demanding that
they propound a new theory. Professor Hambrick says that academics in other
fields "don't feel the need to sprinkle mentions of theory on every page,
like so much aromatic incense or holy water".
Others talk of the need for academics to spend more
time talking to managers about the kind of research they would find useful.
As well-meaning as these suggestions are, I suspect
the business school academics are missing something. Law, medical and
engineering schools are subject to the same academic pressures as business
schools - to publish in prestigious peer-reviewed journals and to buttress
their work with the expected academic vocabulary.
The Two Faces of Accountics Scientists
Accountics scientists have almost a knee jerk, broken record
reaction when confronted with case method/small sample research as
evidenced by SHAHID ANSARI's review of the following book ---
Click Here
ROBERT S. KAPLAN and DAVID P. NORTON
, The Execution Premium: Linking
Strategyto Operations for Competitive Advantage
�Boston,
MA: Harvard Business Press, 2008,ISBN 13: 978-1-4221-2116-0, pp. xiii, 320.
If you are an academician who believes in empirical
data and rigorous statistical analysis, you will find very little of it in
this book. Most of the data in this book comes from Harvard Business School
teaching cases or from the consulting practice of Kaplan and Norton. From an
empirical perspective, the flaws in the data are obvious. The sample is
nonscientific; it comes mostly from opportunistic interventions. It is a bit
paradoxical that a book which is selling a rational-scientific methodology
for strategy development and execution uses cases as opposed to a matched or
paired sample methodology to show that the group with tight linkage between
strategy execution and operational improvement has better results than one
that does not. Even the data for firms that have performed well with a
balanced scorecard and other mechanisms for sound strategy execution must be
taken with a grain of salt.
Bob Jensen has a knee jerk, broken record reaction to accountics scientists
who praise their own "empirical data and rigorous statistical analysis." My
reaction to them is to show me the validation/replication of their
"empirical data and rigorous statistical analysis." that is replete with missing
variables and assumptions of stationarity and equilibrium conditions that are
often dubious at best. Most of their work is so uninteresting that even they
don't bother to validate/replicate each others' research ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
|
"Where Business Meets Philosophy: the Matter of Ethics"
by Julian Friedland,
Chronicle of Higher Education, November 8, 2009
http://chronicle.com/article/Where-Business-Meets/49053/
| While the public clamors for the
return of managerial leadership in ethics and social responsibility,
surprisingly little research on the subject exists, and what does
get published doesn't appear in the top journals. The reasons are
varied, but perhaps more than anything it's that those journals are
exclusively empirical: Take The Academy of Management Review, the
only top journal devoted to management theory.
Its mission statement says it publishes only
"testable knowledge-based claims."
Unfortunately, that excludes most of what
counts as ethics, which is primarily a conceptual, a priori
discipline akin to law and philosophy. We wouldn't require, for
example, that theses on the nature of justice or logic be
empirically testable, although we still consider them "knowledge
based."
It remains to be seen if many business
professors will achieve tenure by doing ethics properly speaking.
Most of what now gets published in top business journals under the
rubric of "ethics" is limited to empirical studies of the success of
various policies presumed as ethical ("the effects of management
consistency on employee loyalty and efficiency," perhaps). Although
valuable, such research does precious little to hone the mission of
business itself.
While the public clamors for the
return of managerial leadership in ethics and social responsibility,
surprisingly little research on the subject exists, and what does
get published doesn't appear in the top journals. The reasons are
varied, but perhaps more than anything it's that those journals are
exclusively empirical: Take The Academy of Management Review, the
only top journal devoted to management theory. Its mission statement
says it publishes only "testable knowledge-based claims."
Unfortunately, that excludes most of what counts as ethics, which is
primarily a conceptual, a priori discipline akin to law and
philosophy. We wouldn't require, for example, that theses on the
nature of justice or logic be empirically testable, although we
still consider them "knowledge based."
The major business journals have a
responsibility to open the ivory-tower gates to a priori arguments
on the ethical nature and mission of business. After all, the top
business schools, which are a model for the rest, are naturally
interested in hiring academics who publish in the top journals. One
solution is for at least one or two of the top journals to rewrite
their mission statements to expressly include articles applying
ethical theory to business. They could start by creating special
ethics sections in the same way that some have already created
critical-essay sections. Another solution is for academics to do
more reading and referencing of existing business-ethics journals.
Through more references in the wider literature, those journals can
rise to the top. Until such changes occur, business ethics will
largely remain a second-class area of research, primarily concerned
with teaching.
Meanwhile, although I seem to notice
more tenure-track positions in business ethics appearing every
year—a step in the right direction—many required business-ethics
courses are taught by relative outsiders. They are usually
non-tenure-track hires from the private sector or, like me, from
various other academic disciplines, such as psychology, law, and
philosophy. In my years as a philosopher in business schools, I've
often held a place at once exalted and reviled. It's provocative and
alluring. But it can also be about as fitting as a pony in a pack of
wolves. During my three years at a previous college I became
accepted—even a valued colleague of many. But deans sometimes
treated me with the kind of suspicion normally suited to a double
agent behind enemy lines.
For a business-ethics curriculum to
succeed, it must be at least somewhat philosophical. And that is
difficult to establish in the university context, in which
departments are loath to give up turf. Not surprisingly, few
business Ph.D. programs offer any real training in ethical theory.
Naturally, dissertations in applied ethics are generally written in
philosophy departments, and those addressing business are rare,
since few philosophers are schooled in business practices. Business
schools should begin collaborating with centers for applied ethics,
which seem to be cropping up almost everywhere in philosophy
departments. Conversely, philosophers in applied ethics should reach
out to business and law professors interested in ethics. With that
kind of academic infrastructure, real prog ress can be made.
Perhaps then fewer business students
will view their major mainly as a means to gainful employment, and
might instead see it as a force of social progress. Colleges like
mine, which root their students in ethics and liberal arts, are
training them to think for themselves. Business schools that fail to
do so are clinging to the past.
Continued in article
Julian Friedland is an assistant professor of business ethics
at Eastern Connecticut State University and editor of "Doing Well
and Good: The Human Face of the New Capitalism" (Information Age
Publishing, 2009). The Two Faces of Accountics Scientists
Accountics scientists have almost a knee jerk, broken record
reaction when confronted with case method/small sample research as
evidenced by SHAHID ANSARI's review of the following book ---
Click Here
ROBERT S. KAPLAN and DAVID P. NORTON
, The Execution Premium:
Linking Strategyto Operations for Competitive Advantage
�Boston,
MA: Harvard Business Press, 2008,ISBN 13: 978-1-4221-2116-0, pp.
xiii, 320.
If you are an academician who believes
in empirical data and rigorous statistical analysis, you will
find very little of it in this book. Most of the data in this
book comes from Harvard Business School teaching cases or from
the consulting practice of Kaplan and Norton. From an empirical
perspective, the flaws in the data are obvious. The sample is
nonscientific; it comes mostly from opportunistic interventions.
It is a bit paradoxical that a book which is selling a
rational-scientific methodology for strategy development and
execution uses cases as opposed to a matched or paired sample
methodology to show that the group with tight linkage between
strategy execution and operational improvement has better
results than one that does not. Even the data for firms that
have performed well with a balanced scorecard and other
mechanisms for sound strategy execution must be taken with a
grain of salt.
Bob Jensen has a knee jerk, broken record reaction to accountics
scientists who praise their own "empirical data and rigorous
statistical analysis." My reaction to them is to show me the
validation/replication of their "empirical data and rigorous
statistical analysis." that is replete with missing variables and
assumptions of stationarity and equilibrium conditions that are
often dubious at best. Most of their work is so uninteresting that
even they don't bother to validate/replicate each others' research
---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
|
"The Financial Crisis as a Symbol of the
Failure of Academic Finance? (A Methodological Digression)"
by Hans J. Blommestein
SSRN, September 23, 2009
http://papers.ssrn.com/sol3/papers.cfm?abstract_id=1477399
The failure of academic finance can be
considered one of the symbols of the financial crisis. Two
important underlying reasons why academic finance models
systematically fail to account for real-world phenomena follow
directly from two conventions: (a) treating economics not as a
'true' social science (but as a branch of applied mathematics
inspired by the methodology of classical physics); and (b) using
economic models as if the empirical content of economic theories
is not very low. Failure to understand and appreciate the
inherent weaknesses of these 'conventions' had fatal
consequences for the use and interpretation of key academic
finance concepts and models by market practitioners and
policymakers. Theoretical constructs such as the efficient
markets hypothesis, rational expectations, and market
completeness were too often treated as intellectual dogmas
instead of (parts of) falsifiable hypotheses. The situation of
capture via dominant intellectual dogmas of policymakers,
investors, and business managers was made worse by sins of
omission - the failure of academics to communicate the
limitations of their models and to warn against (potential)
misuses of their research - and sins of commission - introducing
(often implicitly) ideological or biased features in research
programs Hence, the deeper problem with finance concepts such as
the 'efficient markets hypothesis' and 'ratex theory' is not
that they are based on assumptions that are considered as not
being 'realistic'. The real issue at stake with academic finance
is not a quarrel about the validity of the assumption of
rational behavior but the inherent semantical insufficiency of
economic theories that implies a low empirical content (and a
high degree of specification uncertainty). This perspective
makes the scientific approach advocated by Friedman and others
less straightforward. In addition, there is wide-spread failure
to incorporate the key implications of economics as a social
science. As response to these 'weaknesses' and challenges, five
suggested principles or guidelines for future research
programmes are outlined.
The Two Faces of Accountics Scientists
Accountics scientists have almost a knee jerk, broken record
reaction when confronted with case method/small sample research as
evidenced by SHAHID ANSARI's review of the following book ---
Click Here
ROBERT S. KAPLAN and DAVID P. NORTON
, The Execution Premium:
Linking Strategyto Operations for Competitive Advantage
�Boston,
MA: Harvard Business Press, 2008,ISBN 13: 978-1-4221-2116-0, pp.
xiii, 320.
If you are an academician who believes
in empirical data and rigorous statistical analysis, you will
find very little of it in this book. Most of the data in this
book comes from Harvard Business School teaching cases or from
the consulting practice of Kaplan and Norton. From an empirical
perspective, the flaws in the data are obvious. The sample is
nonscientific; it comes mostly from opportunistic interventions.
It is a bit paradoxical that a book which is selling a
rational-scientific methodology for strategy development and
execution uses cases as opposed to a matched or paired sample
methodology to show that the group with tight linkage between
strategy execution and operational improvement has better
results than one that does not. Even the data for firms that
have performed well with a balanced scorecard and other
mechanisms for sound strategy execution must be taken with a
grain of salt.
Bob Jensen has a knee jerk, broken record reaction to accountics
scientists who praise their own "empirical data and rigorous
statistical analysis." My reaction to them is to show me the
validation/replication of their "empirical data and rigorous
statistical analysis." that is replete with missing variables and
assumptions of stationarity and equilibrium conditions that are
often dubious at best. Most of their work is so uninteresting that
even they don't bother to validate/replicate each others' research
---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
|
"Reshaping accounting research: Living in the world in which we
live"
by Paul F. Williams
Science Direct, February 28. 2009
Click Here
| This paper is derived from my
participation as a faculty guest of the University of Wollongong's
Faculty of Commerce 20th Annual Doctoral Consortium. Consistent with
the theme of “paradigm, paradox, and paralysis?”, I argue in this
paper that accounting practice and scholarship suffer from paralysis
created by the imposition of a neoclassical economic paradigm.
Starting from the premise that accounting is foremost a practice, I
argue that accounting cannot be limited by any one type of
understanding. A human practice like accounting is simply to multi-
faceted and complex to be sensibly “modeled” in any one particular
way. The “flight from reality” (Shapiro, 2005), that occurred
because of the empirical revolution in accounting, should be
abandoned in favor of a more problem driven approach to accounting
research and practice.
The Two Faces of Accountics Scientists
Accountics scientists have almost a knee jerk, broken record
reaction when confronted with case method/small sample research as
evidenced by SHAHID ANSARI's review of the following book ---
Click Here
ROBERT S. KAPLAN and DAVID P. NORTON
, The Execution Premium:
Linking Strategyto Operations for Competitive Advantage
�Boston,
MA: Harvard Business Press, 2008,ISBN 13: 978-1-4221-2116-0, pp.
xiii, 320.
If you are an academician who believes
in empirical data and rigorous statistical analysis, you will
find very little of it in this book. Most of the data in this
book comes from Harvard Business School teaching cases or from
the consulting practice of Kaplan and Norton. From an empirical
perspective, the flaws in the data are obvious. The sample is
nonscientific; it comes mostly from opportunistic interventions.
It is a bit paradoxical that a book which is selling a
rational-scientific methodology for strategy development and
execution uses cases as opposed to a matched or paired sample
methodology to show that the group with tight linkage between
strategy execution and operational improvement has better
results than one that does not. Even the data for firms that
have performed well with a balanced scorecard and other
mechanisms for sound strategy execution must be taken with a
grain of salt.
Bob Jensen has a knee jerk, broken record reaction to accountics
scientists who praise their own "empirical data and rigorous
statistical analysis." My reaction to them is to show me the
validation/replication of their "empirical data and rigorous
statistical analysis." that is replete with missing variables and
assumptions of stationarity and equilibrium conditions that are
often dubious at best. Most of their work is so uninteresting that
even they don't bother to validate/replicate each others' research
---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
|
"If Only There were Simple
Solutions, but there Aren't:
Some Reflections on Zimmerman's Critique of Empirical Management
Accounting Research"
by Anthony G. Hopwood
European Accounting Review, Vol. 11, No. 4, 2002
http://papers.ssrn.com/sol3/papers.cfm?abstract_id=360740
| Although
having some sympathies with Zimmerman's critique of Ittner and
Larcker's review of the empirical management accounting research
literature, this analysis points out how Zimmerman has too easily
allowed his own prejudices to influence both his assessment of the
empirical management accounting literature and his recommendations
for improvement. Particular emphasis is put on analysing Zimmerman's
classification of the accounting research literature and his
unproblematic optimism in the potential of economic modes of
understanding.
The Two Faces of Accountics Scientists
Accountics scientists have almost a knee jerk, broken record
reaction when confronted with case method/small sample research as
evidenced by SHAHID ANSARI's review of the following book ---
Click Here
ROBERT S. KAPLAN and DAVID P. NORTON
, The Execution Premium:
Linking Strategyto Operations for Competitive Advantage
�Boston,
MA: Harvard Business Press, 2008,ISBN 13: 978-1-4221-2116-0, pp.
xiii, 320.
If you are an academician who believes
in empirical data and rigorous statistical analysis, you will
find very little of it in this book. Most of the data in this
book comes from Harvard Business School teaching cases or from
the consulting practice of Kaplan and Norton. From an empirical
perspective, the flaws in the data are obvious. The sample is
nonscientific; it comes mostly from opportunistic interventions.
It is a bit paradoxical that a book which is selling a
rational-scientific methodology for strategy development and
execution uses cases as opposed to a matched or paired sample
methodology to show that the group with tight linkage between
strategy execution and operational improvement has better
results than one that does not. Even the data for firms that
have performed well with a balanced scorecard and other
mechanisms for sound strategy execution must be taken with a
grain of salt.
Bob Jensen has a knee jerk, broken record reaction to accountics
scientists who praise their own "empirical data and rigorous
statistical analysis." My reaction to them is to show me the
validation/replication of their "empirical data and rigorous
statistical analysis." that is replete with missing variables and
assumptions of stationarity and equilibrium conditions that are
often dubious at best. Most of their work is so uninteresting that
even they don't bother to validate/replicate each others' research
---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
|
"Why Good Spreadsheets Make Bad Strategies"
by Roger Martin
Harvard Business Review Blog, January 11, 2010 ---
Click Here
http://blogs.hbr.org/cs/2010/01/why_good_spreadsheets_make_bad.html?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+harvardbusiness+%28HBR.org%29&utm_content=Google+Reader
|
We live in a world
obsessed with science, preoccupied with predictability and control, and
enraptured with quantitative analysis. Economic forecasters crank out precision
predictions of economic growth with their massive econometric models. CEOs give
to-the-penny guidance to capital markets on next quarter's predicted earnings.
We live by adages like: "Show me the numbers" and truisms such as "If you can't
measure it, it doesn't count."
What has this obsession
gotten us?
The economists have gotten it consistently wrong.
As late as the first half of 2008, no prominent macroeconomist or important
economic forecasting organization predicted that the economy would not grow in
2008 (or 2009), let alone that it would crater as disastrously as it did. But,
undaunted, the same economists who totally missed the recession turned back to
the same quantitative, scientific models to predict how the economy would
recover, only to be mainly wrong again. CEOs keep on giving quarterly guidance
based on their sophisticated financial planning systems and keep on being wrong
— and then get slammed not for bad performance but for their failure to predict
performance exactly as they promised mere months earlier.
In this
oh-so-modern life, we have deep-seated desire to quantify the world around us so
that we can understand it and control it. But the world isn't behaving.
Instead, it is showing its modern,
scientific inhabitants that quantity doesn't tell us as much as we would wish.
While the macroeconomists would dearly love to add up all the loans to provide a
total for "credit outstanding" and then plug this quantity into their economic
models to be able to predict next year's Gross Domestic Product, they found out
in 2008 that all of those loans weren't the same — some, especially the
sub-prime mortgages, weren't worth the proverbial paper on which they were
written.
And CEOs and their CFOs
would love to be able to extrapolate last month's sales quantity and predict
next quarter's sales, but sometimes they find out that those sales weren't as
solid a base for growth as they might have thought — especially if some of the
customer relationships underpinning them weren't as strong as they might have
imagined.
The fundamental
shortcoming is that all of these scientific methods depended entirely on
quantities to produce the answers they were meant to generate. They were all
blissfully ignorant of qualities. My colleague
Hilary Austen, who is writing a fantastic book on
the importance of artistry, describes the difference between qualities and
quantities in the latest draft:
Qualities cannot be objectively measured, as a quantity like temperature can be
measured with a thermometer. We can count the number of people in a room, but
that tells us little about the mood — upbeat, flat, intense, contentious — of
the group's interaction.
Why are qualities so
important? We need to understand the role of qualities in dealing with the
complex, ambiguous and uncertain world in which we live because understanding,
measuring, modeling and manipulating the quantities just won't cut it. Adding up
the quantity of credit outstanding won't tell us nearly enough about what role
it will play in our economy. Adding up sales won't tell us what kind of a
company we really have. We need to have a much deeper understanding of their
qualities — the ambiguous, hard-to-measure aspects of all of these features.
To obtain that
understanding, we need to supplement the quantitative techniques brought to us
through the march of science with the artistic understanding of and facility
with qualities that our obsession with science has brushed aside. We must stop
obsessing about measurement so much that we exclude essential but un-measurable
qualities from our understanding of any given situation. We must also consider
the possibility that if we can't measure something, it might be the very most
important aspect of the problem on which we're working.
Roger Martin is the Dean of the Rotman School of Management at the
University of Toronto in Canada and the author of
The Design of Business: Why Design Thinking is the Next Competitive Advantage
(Harvard Business Press, 2009).
The Two Faces of Accountics Scientists
Accountics scientists have almost a knee jerk, broken record
reaction when confronted with case method/small sample research as
evidenced by SHAHID ANSARI's review of the following book ---
Click Here
ROBERT S. KAPLAN and DAVID P. NORTON
, The Execution Premium: Linking
Strategyto Operations for Competitive Advantage
�Boston,
MA: Harvard Business Press, 2008,ISBN 13: 978-1-4221-2116-0, pp. xiii, 320.
If you are an academician who believes in empirical
data and rigorous statistical analysis, you will find very little of it in
this book. Most of the data in this book comes from Harvard Business School
teaching cases or from the consulting practice of Kaplan and Norton. From an
empirical perspective, the flaws in the data are obvious. The sample is
nonscientific; it comes mostly from opportunistic interventions. It is a bit
paradoxical that a book which is selling a rational-scientific methodology
for strategy development and execution uses cases as opposed to a matched or
paired sample methodology to show that the group with tight linkage between
strategy execution and operational improvement has better results than one
that does not. Even the data for firms that have performed well with a
balanced scorecard and other mechanisms for sound strategy execution must be
taken with a grain of salt.
Bob Jensen has a knee jerk, broken record reaction to accountics scientists
who praise their own "empirical data and rigorous statistical analysis." My
reaction to them is to show me the validation/replication of their
"empirical data and rigorous statistical analysis." that is replete with missing
variables and assumptions of stationarity and equilibrium conditions that are
often dubious at best. Most of their work is so uninteresting that even they
don't bother to validate/replicate each others' research ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
|
This Appendix is continued at the following links:
http://faculty.trinity.edu/rjensen/Theory01.htm#AcademicsVersusProfession
http://faculty.trinity.edu/rjensen/Theory01.htm#DoctoralPrograms
http://faculty.trinity.edu/rjensen/Theory01.htm#Replication
“An
Analysis of the Evolution of Research Contributions by The Accounting Review:
1926-2005,” by Jean Heck and Robert E. Jensen, Accounting Historians Journal,
Volume 34, No. 2, December 2007, pp. 109-142
http://faculty.trinity.edu/rjensen/395wpTAR/Web/TAR395wp.htm
Appendix 2
Integrating Academic Research Into
Undergraduate Accounting Courses
James Irving's Working Paper entitled "Integrating Academic Research into
an Undergraduate Accounting Course"
College of William and Mary, January 2010
ABSTRACT:
This paper describes my experience incorporating academic research into the
curriculum of an undergraduate accounting course. This research-focused
curriculum was developed in response to a series of reports published
earlier in the decade which expressed significant concern over the expected
future shortage of doctoral faculty in accounting. It was also motivated by
prior research studies which find that students engaging in undergraduate
research are more likely to pursue graduate study and to achieve graduate
school success. The research-focused curriculum is divided into two
complementary phases. First, throughout the semester, students read and
critique excerpts from accounting journal articles related to the course
topics. Second, students acquire and use specific research skills to
complete a formal academic paper and present their results in a setting
intended to simulate a research workshop. Results from a survey created to
assess the research experience show that 96 percent of students responded
that it substantially improved their level of knowledge, skill, and
abilities related to conducting research. Individual cases of students who
follow this initial research opportunity with a deeper research experience
are also discussed. Finally, I supply instructional tools for faculty who
might desire to implement a similar program.
January 17, 2010 message (two messages combined) from Irving, James
[James.Irving@mason.wm.edu]
Hi Bob,
I recently completed the first draft of a paper
which describes my experience integrating research into an undergraduate
accounting course. Given your prolific and insightful contributions to
accounting scholarship, education, etc. -- I am a loyal follower of your
website and your commentary within the AAA Commons -- I am wondering if you
might have an interest in reading it (I also cite a 1992 paper published in
Critical Perspectives in Accounting for which you were a coauthor).
The paper is attached with this note. Any thoughts
you have about it would be greatly appreciated.
I posted the paper to my SSRN page and it is
available at the following link:
http://ssrn.com/abstract=1537682 . I appreciate your willingness to read
and think about the paper.
Jim
January 18, 2010 reply from Bob Jensen
Hi Jim,
I’ve given
your paper a cursory overview and have a few comments that might be of interest.
You’ve
overcome much of the negativism about why accounting students tend not to
participate in the National Conferences on Undergraduate Research (NCUR).
Thank you for citing our old paper.
French, P., R.
Jensen, and K. Robertson. 1992. Undergraduate student research programs:re they
as viable for accounting as they are in science and humanities?"
Critical Perspectives
on Accounting
3 (December): 337-357.
---
Click Here
Abstract
This paper reviews a recent thrust in academia to stimulate more
undergraduate research in the USA, including a rapidly growing annual
conference. The paper also describes programs in which significant
foundation grants have been received to fund undergraduate research projects
in the sciences and humanities. In particular, selected humanities students
working in teams in a new “Philosophy Lab” are allowed to embark on
long-term research projects of their own choosing. Several completed
projects are briefly reviewed in this paper.
In April 1989, Trinity University hosted the Third
National Conference on Undergraduate Research (NCUR) and purposely expanded
the scope of the conference to include a broad range of disciplines. At this
conference, 632 papers and posters were presented representing the research
activities of 873 undergraduate students from 163 institutions. About 40% of
the papers were outside the natural sciences and included research in music
and literature. Only 13 of those papers were in the area of business
administration; none were even submitted by accounting students. In 1990 at
Union College, 791 papers were presented; none were submitted by
accountants. In 1991 at Cal Tech, the first accounting paper appeared as one
of 853 papers presented.
This paper suggests a number of obstacles to
stimulating and encouraging accounting undergraduates to embark on research
endeavours. These impediments are somewhat unique to accounting, and it
appears that accounting education programs are lagging in what is being done
to break down obstacles in science, pre-med, engineering, humanities, etc.
This paper proposes how to overcome these obstacles in accounting. One of
the anticipated benefits of accounting student research, apart from the
educational and creative value, is the attraction of more and better
students seeking creativity opportunities in addition to rote learning of
CPA exam requirements. This, in part, might help to counter industry
complaints that top students are being turned away from accounting careers
nationwide.
In particular you seem to have picked up on our suggestions in the third
paragraph above and seemed to be breaking new ground in undergraduate accounting
education.
I am truly amazed by you're having success when forcing
undergraduate students to actually conduct research in new knowledge.
Please keep up the good work and maintain your enthusiasm.
1
Firstly, I would suggest that you focus on the topic of replication as well when
you have your students write commentaries on published academic accounting
research ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
I certainly would not expect intermediate accounting students to attempt a
replication effort. But it should be very worthwhile to introduce them to the
problem of lack of replication and authentication of accountancy analytic and
empirical research.
2
Secondly, the two papers you focus on are very old and were never replicated..
Challenges to both papers are private and in some cases failed replication
attempts, but those challenges were not published and came to me only by word of
mouth. It is very difficult to find replications of empirical research in
accounting, but I suggest that you at least focus on some papers that have some
controversy and are extended in some way.
For example, consider the controversial paper:
"Costs of Equity and Earnings Attributes," by Jennifer Francis, Ryan LaFond, Per
M. Olsson and Katherine Schipper ,The Accounting Review, Vol. 79, No. 4
2004 pp. 967–1010.
Also see
http://www.entrepreneur.com/tradejournals/article/179269527.html
Then consider
"Is Accruals Quality a Priced Risk Factor?" by John E. Core, Wayne R. Guay, and
Rodrigo S. Verdi, SSRN, December 2007 ---
http://papers.ssrn.com/sol3/papers.cfm?abstract_id=911587
This paper was also published in JAE in 2007 or 2008.
Thanks to Steve Kachelmeier for pointing this controversy (on whether
information quality (measured as the noise in accounting accruals) is priced in
the cost of equity capital) out to me.
It might be better for your students to see how accounting researchers should
attempt replications as illustrated above than to merely accepted published
accounting research papers as truth unchallenged.
3.
Have your students attempt critical thinking with regards to mathematical
analytics in "Plato's Cave" ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm#Analytics
This is a great exercise that attempts to make them focus on underlying
assumptions.
4.
In Exhibit 1 I recommend adding a section on critical thinking about underlying
assumptions in the study. In particular, have your students focus on internal
versus external validity ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm#SocialScience .
You might look into some of the research ideas for students
listed at
http://faculty.trinity.edu/rjensen/theory01.htm#ResearchVersusProfession
5.
I suggest that you set up a hive at the AAA Commons for Undergraduate Research
Projects and Commentaries. Then post your own items in this hive and repeatedly
invite professors and students from around the world to add to this hive.
Appendix 3
Audit Pricing in the Real
World
"Defending Koss And Their Auditors: Just Loopy Distorted Feedback," by
Francine McKenna, re: TheAuditors, January 16, 2010 ---
http://retheauditors.com/2010/01/16/defending-koss-and-their-auditors-just-loopy-distorted-feedback/
My objective in writing this story was to handily
contradict Grant Thornton’s self-serving
defense to the Koss fraud.
The defense supported
by some commentators:
Audits are not designed to uncover fraud and
Koss did not pay for a separate opinion on internal controls because they
are exempt from that Sarbanes-Oxley requirement.
But punching holes in that Swiss-cheese defense is
like shooting fish in a barrel. Leading that horse to water is like feeding
him candy taken from a baby. The reasons why someone other than American
Express should have caught this sooner are as numerous as the
acorns you can steal from a blind pig…
Ok, you get the gist.
Listing standards for the NYSE require an internal
audit function. NASDAQ, where Koss was listed, does not. Back in 2003, the
Institute of Internal Auditors (IIA) made recommendations
post- Sarbanes-Oxley that were adopted for the most
part by NYSE, but not completely by NASDAQ. And both the NYSE and NASD left
a few key recommendations hanging.
In addition, the IIA has never mandated, under its
own standards for the internal audit profession, a
direct reporting of the internal audit function to
the independent Audit Committee. The
SEC did not adopt this requirement in their
final rules, either.
However, Generally Accepted Auditing Standards (GAAS),
the standards an external auditor such as Grant Thornton operates under when
preparing an opinion on a company’s financial statements – whether a public
company or not, listed on NYSE or NASDAQ, whether exempt or not from
Sarbanes-Oxley – do require the assessment of the internal audit function
when planning an audit.
Grant Thornton was required to adjust their
substantive testing given the number of
risk factors
presented by Koss, based on
SAS 109 (AU 314), Understanding the Entity and
Its Environment and Assessing the Risks of
Material Misstatement. If they had understood the entity and assessed the
risk of material misstatement fully, they would have been all over those
transactions like _______. (Fill in the blank)
If they had performed a proper
SAS 99 review (AU 316), Consideration of Fraud
in a Financial Statement Audit, it would have hit’em smack in the face
like a _______ . (Fill in the blank.) Management oversight of the financial
reporting process is severely limited by Mr. Koss Jr.’s lack of interest,
aptitude, and appreciation for accounting and finance. Koss Jr., the CEO and
son of the founder,
held the titles
of COO and CFO, also. Ms. Sachdeva, the Vice
President of Finance and Corporate Secretary who is accused of the fraud,
has been in the
same job since 1992
and during one ten year period
worked remotely from Houston!
When they finished their review according to
SAS 65 (AU 322), The Auditor’s Consideration
of the Internal Audit Function in an Audit of Financial Statements, it
should have dawned on them: There is no internal audit function and the
flunky-filled Audit Committee is a sham. I can see it now. The Grant
Thornton Milwaukee OMP smacks head with open palm in a “I could have had a
V-8,” moment but more like, “Holy cheesehead, we’re indigestible
gristle-laden, greasy bratwurst here! We’ll never be able issue an opinion
on these financial statements unless we take these journal entries apart,
one-by-one, and re-verify every stinkin’ last number.”
But I dug in and did some additional research – at
first I was just working the “no internal auditors” line – and I found a few
more interesting things. And now I have no sympathy for Koss management
and, therefore, its largest shareholder, the Koss family. Granted there is
plenty of basis, in my opinion, for any and all enforcement actions against
Grant Thornton and its audit partners. And depending on how far back the
acts of deliciously deceptive defalcation go, PricewaterhouseCoopers may
also be dragged through the mud.
Yes.
I can not make this stuff up and have it come out
more music to my ears. PricewaterhouseCoopers was Koss’s auditor prior to
Grant Thornton. In March of 2004, the
Milwaukee Business Journal reported, “Koss
Corp. has fired the certified
public accounting firm of PricewaterhouseCoopers L.L.P. as its independent
auditors March 15 and retained Grant Thornton L.L.P. in its place.”
The article was short with the standard disclaimer of no disputes about
accounting policies and practices. But it pointedly pointed out that PwC’s
fees for the audit had increased by almost 50% from 2001 to 2003, to $90,000
and the selection of the new auditor was made after a competitive bidding
process.
PwC had been Koss’s auditor since 1992!
The focus on audit fees by Koss’s CEO should have
been no surprise to PwC. Post-Sarbanes-Oxley, Michael J. Koss the son of
the founder, was quoted extensively as part of the very vocal cadre of CEOs
who complained vociferously about paying their auditors one more red cent.
Koss Jr. minced no words regarding PwC in the
Wall Street Journal in August 2002, a month after
the law was passed:
“…Sure, analysts had predicted a modest fee
increase from the smaller pool of accounting firms left after Arthur
Andersen LLP’s collapse following its June conviction on a
criminal-obstruction charge. But a range of other factors are helping to
drive auditing fees higher — to as much as 25% — with smaller companies
bearing the brunt of the rise.
“The auditors are making money hand
over fist,” says Koss Corp. Chief Executive Officer Michael Koss. “It’s
going to cost shareholders in the long run.”
He should know. Auditing fees are up nearly
10% in the past two years at his Milwaukee-based maker of headphones.
The increase has come primarily from auditors spending more time combing
over financial statements as part of compliance with new disclosure
requirements by the Securities and Exchange Commission. Koss’s
accounting firm, PricewaterhouseCoopers LLP, now shows up at corporate
offices for “mini audits” every quarter, rather than just once at
year-end.”
A year later, still irate, Mr. Koss Jr. was quoted
in
USA Today:
“Jeffrey Sonnenfeld, associate dean of the
Yale School of Management, said he recently spoke to six CEO conferences
over 10 days. When he asked for a show of hands, 80% said they thought
the law was bad for the U.S. economy.
When pressed individually, CEOs don’t
object to the law or its intentions, such as forcing executives to
refund ill-gotten gains. But confusion over what the law requires has
left companies vulnerable to experts and consultants, who “frighten
boards and managers” into spending unnecessarily, Sonnenfeld says.
Michael Koss, CEO of stereo
headphones maker Koss, says it’s all but impossible to know what the law
requires, so it has become a black hole where frightened companies throw
endless amounts of money.
Companies are spending way too much to
comply, but the cost is due to “bad advice,
not a bad law,” Sonnenfeld says.”
It’s interesting that Koss Jr. has such
minimal appreciation for the work of the external auditor or an internal
audit function. By virtue, I suppose, of his esteemed status as CEO, COO and
CFO of Koss and notwithstanding an undergraduate
degree in anthropology, according to
Business Week, Mr. Koss Jr. has twice served other
Boards as their “financial expert” and Chairman of their Audit Committees.
At
Genius Products,
founded by the Baby Genius DVDs creator, Mr. Koss served in this capacity
from 2004 to 2005. Mr. Koss Jr. has also been a Director, Chairman of Audit
Committee, Member of Compensation Committee and Member of Nominating &
Corporate Governance Committee at
Strattec Security Corp. since 1995.
If I were the SEC, I might take a look at those two
companies…Because
I warned you about the CEOs and CFOs who are
pushing back on Sarbanes-Oxley and every other regulation intended to shine
a light on them as public company executives.
No good will come of this.
I don’t want you to shed crocodile tears or pity
poor PwC for their long-term, close relationship with
another blockbuster Indian fraudster. Nor should
you pat them on the back for not being the auditor now. PwC never really
left Koss after they were “fired” as auditor in 2004. They continued until
today to be the trusted “Tax and All Other” advisor,
making good money filing Koss’s now totally bogus
tax returns.
Continued in article
Bob Jensen's threads on Grant Thornton litigation ---
http://faculty.trinity.edu/rjensen/fraud001.htm#GrantThornton
Bob Jensen's threads on PwC and other large auditing firms
http://faculty.trinity.edu/rjensen/fraud001.htm
Jensen Comment
You may want to compare Francine's above discussion of audit fees with the
following analytical research study:
In most instances the defense of underlying assumptions is based upon
assumptions passed down from previous analytical studies rather than empirical
or even case study evidence. An example is the following conclusion:
We find that audit quality and audit fees both
increase with the auditor’s expected litigation losses from audit failures.
However, when considering the auditor’s acceptance decision, we show that it
is important to carefully identify the component of the litigation
environment that is being investigated. We decompose the liability
environment into three components: (1) the strictness of the legal regime,
defined as the probability that the auditor is sued and found liable in case
of an audit failure, (2) potential damage payments from the auditor to
investors and (3) other litigation costs incurred by the auditor, labeled
litigation frictions, such as attorneys’ fees or loss of reputation. We show
that, in equilibrium, an increase in the potential damage payment actually
leads to a reduction in the client rejection rate. This effect arises
because the resulting higher audit quality increases the value of the
entrepreneur’s investment opportunity, which makes it optimal for the
entrepreneur to increase the audit fee by an amount that is larger than the
increase in the auditor’s expected damage payment. However, for this result
to hold, it is crucial that damage payments be fully recovered by the
investors. We show that an increase in litigation frictions leads to the
opposite result—client rejection rates increase. Finally, since a shift in
the strength of the legal regime affects both the expected damage payments
to investors as well as litigation frictions, the relationship between the
legal regime and rejection rates is nonmonotonic. Specifically, we show that
the relationship is U-shaped, which implies that for both weak and strong
legal liability regimes, rejection rates are higher than those
characterizing more moderate legal liability regimes.
Volker Laux and D. Paul Newman, "Auditor Liability and Client Acceptance
Decisions," The Accounting Review, Vol. 85, No. 1, 2010 pp. 261–285
http://faculty.trinity.edu/rjensen/TheoryTAR.htm#Analytics
Before reading this May 4, 2009 article you may want to read some
introductory modules about Overstock.com at
http://en.wikipedia.org/wiki/Overstock.com
"Overstock.com and PricewaterhouseCoopers: Errors in Submissions to
SEC Division of Corporation Finance," White Collar Fraud, May 19,
2008 ---
http://whitecollarfraud.blogspot.com/2008/05/overstockcom-and-pricewaterhousecoopers.html
"To Grant Thornton, New Auditors for Overstock.com," White Collar
Fraud, March 30, 2009 ---
http://whitecollarfraud.blogspot.com/2009/03/to-grant-thornton-new-auditors-for.html
"Overstock.com's First Quarter Financial Performance Aided by GAAP
Violations," White Collar Fraud, May 4, 2009 ---
http://whitecollarfraud.blogspot.com/2009/05/overstockcoms-first-quarter-financial.html
Overstock.com (NASDAQ: OSTK) and its
management team led by its CEO and masquerading stock market
reformer Patrick Byrne (pictured on right) continued its pattern of
false and misleading disclosures and departures from Generally
Accepted Accounting Principles (GAAP) in its latest Q1 2009
financial report.
In Q1 2009, Overstock.com reported a net
loss of $2.1 million compared to $4.7 million in Q1 2008 and claimed
an earnings improvement of $2.6 million. However, the company's
reported $2.6 reduction in net losses was aided by a violation of
GAAP (described in more detail below) that reduced losses by $1.9
million and buybacks of Senior Notes issued in 2004 under false
pretenses that reduced losses by another $1.9 million.
After the issuance of the Senior Notes in
November 2004, Overstock.com has twice restated financial reports
for Q1 2003 to Q3 2004 (the accounting periods immediately preceding
the issuance of such notes) because of reported accounting errors
and material weaknesses in internal controls.
While new CFO Steve Chestnut hyped that
"It's been a great Q1," the reality is that Overstock.com’s reported
losses actually widened by $1.2 million after considering violations
of GAAP ($1.9 million) and buying back notes issued under false
pretenses ($1.9 million).
How Overstock.com improperly reported of an
accounting error and created a “cookie jar reserve” to manage future
earnings by improperly deferring recognition of an income
Before we begin, let’s review certain
events starting in January 2008.
In January 2008, the Securities and
Exchange Commission discovered that Overstock.com's revenue
accounting failed to comply with GAAP and SEC disclosure rules, from
the company's inception. This blog detailed how the company provided
the SEC with a flawed and misleading materiality analysis to
convince them that its revenue accounting error was not material.
The company wanted to avoid a restatement of prior affected
financial reports arising from intentional revenue accounting errors
uncovered by the SEC.
Instead, the company used a one-time
cumulative adjustment in its Q4 2007 financial report, apparently to
hide the material impact of such errors on previous affected
individual financial reports. In Q4 2007, Overstock.com reduced
revenues by $13.7 million and increased net losses by $2.1 million
resulting from the one-time cumulative adjustment to correct its
revenue accounting errors.
Q3 2008
On October 24, 2008, Overstock.com's Q3
2008 press release disclosed new customer refund and credit errors
and the company warned investors that all previous financial reports
issued from 2003 to Q2 2008 “should no longer be relied upon.” This
time, Overstock.com restated all financial reports dating back to
2003. In addition, Overstock.com reversed its one-time cumulative
adjustment in Q4 2007 used to correct its revenue accounting errors
and also restated all financial statements to correct those errors,
as I previously recommended.
The company reported that the combined
amount of revenue accounting errors and customer refund and credit
accounting errors resulted in a cumulative reduction in previously
reported revenues of $12.9 million and an increase in accumulated
losses of $10.3 million.
Q4 2008
On January 30, 2009, Overstock.com reported
a $1 million profit and $.04 earnings per share for Q4 2008, after
15 consecutive quarterly losses and it beat mean analysts’ consensus
expectations of negative $0.04 earnings per share. CEO Patrick Byrne
gloated, "After a tough three years, returning to GAAP profitability
is a relief." However, Overstock.com's press release failed to
disclose that its $1 million reported profit resulted from a
one-time gain of $1.8 million relating to payments received from
fulfillment partners for amounts previously underbilled them.
During the earnings call that followed the
press release, CFO Steve Chesnut finally revealed to investors that:
Gross profit dollars were $43.6 million, a
6% decrease. This included a one-time gain of $1.8 million relating
to payments from partners who were under-billed earlier in the year.
Before Q3 2008, Overstock.com failed to
bill its fulfillment partners for offsetting cost reimbursements and
fees resulting from its customer refund and credit errors. After
discovering foul up, Overstock.com
improperly corrected the billing errors by recognizing income in
future periods when such amounts were recovered or on a cash basis
(non-GAAP).
In a blog post, I explained why Statement
of Financial Accounting Standards No. 154 required Overstock.com to
restate affected prior period financial reports to reflect when the
underbilled cost reimbursements and fees were actually earned by the
company (accrual basis or GAAP). In other words, Overstock.com
should have corrected prior financial reports to accurately reflect
when the income was earned from fulfillment partners who were
previously underbilled for cost reimbursements and fees.
If Overstock.com properly followed
accounting rules, it would have reported an $800,000 loss instead of
a $1 million profit, it would have reported sixteen consecutive
losses instead of 15 consecutive losses, and it would have failed to
meet mean analysts’ consensus expectation for earnings per share
(anyone of three materiality yardsticks under SEC Staff Accounting
Bulletin No. 99 that would have triggered a restatement of prior
year’s effected financial reports).
Patrick Byrne responds on a stock market
chat board
In my next blog post, I described how CEO
Patrick M. Byrne tried to explain away Overstock.com’s treatment of
the “one-time gain” in an unsigned post, using an alias, on an
internet stock market chat board. Byrne’s chat board post was later
removed and re-posted with his name attached to it, after I
complained to the SEC. Here is what Patrick Byrne told readers on
the chat board:
Antar's ramblings are gibberish. Show them
to any accountant and they will confirm. He has no clue what he is
talking about.
For example: when one discovers that one
underpaid some suppliers $1 million and overpaid others $1 million.
For those whom one underpaid, one immediately recognizes a $1
million liability, and cleans it up by paying. For those one
overpaid, one does not immediately book an asset of a $1 million
receivable: instead, one books that as the monies flow in. Simple
conservatism demands this (If we went to book the asset the moment
we found it, how much should we book? The whole $1 million? An
estimate of the portion of it we think we'll be able to collect?)
The result is asymmetric treatment. Yet Antar is screaming his head
off about this, while never once addressing this simple principle.
Of course, if we had booked the found asset the moment we found it,
he would have screamed his head off about that. Behind everything
this guy writes, there is a gross obfuscation like this. His purpose
is just to get as much noise out there as he can.
Note: Bold print and italics added by me.
In other words, Overstock.com improperly
used cash basis accounting (non-GAAP) rather than accrual basis
accounting (GAAP) to correct its accounting error. I criticized
Byrne’s response noting that:
… Overstock.com recognized the "one-time of
$1.8 million" using cash-basis accounting when it "received payments
from partners who were under-billed earlier in the year" instead of
accrual basis accounting, which requires income to be recognized
when earned. A public company is not permitted to correct any
accounting error using cash-basis accounting.
Overstock.com tries to justify improper
cash basis accounting in Q4 2008 to correct an accounting error
Overstock.com needed to justify Patrick
Byrne’s stock chat board ramblings. About two weeks later,
Overstock.com filed its fiscal year 2008 10-K report with the SEC
and the company concocted a new excuse to justify using cash basis
accounting to correct its accounting error and avoid restating prior
affected financial reports:
In addition, during Q4 2008, we reduced
Cost of Goods Sold by $1.8 million for billing recoveries from
partners who were underbilled earlier in the year for certain fees
and charges that they were contractually obligated to pay. When the
underbilling was originally discovered, we determined that the
recovery of such amounts was not assured, and that consequently the
potential recoveries constituted a gain contingency. Accordingly, we
determined that the appropriate accounting treatment for the
potential recoveries was to record their benefit only when such
amounts became realizable (i.e., an agreement had been reached with
the partner and the partner had the wherewithal to pay).
Note: Bold print and italics added by me.
Overstock.com improperly claimed that a
"gain contingency" existed by using the rationale that the
collection of all "underbilled...fees and charges...was not
assured....”
Why Overstock.com's accounting for
underbilled "fees and charges" violated GAAP
Overstock.com already earned those "fees
and charges" and its fulfillment partners were "contractually
obligated to pay" such underbilled amounts. There was no question
that Overstock.com was owed money from its fulfillment partners and
that such income was earned in prior periods.
If there was any question as to the
recovery of any amounts owed the company, management should have
made a reasonable estimate of uncollectible amounts (loss
contingency) and booked an appropriate reserve against amounts due
from fulfillment partners to reduce accrued income (See SFAS No. 5
paragraph 1, 2, 8, 22, and 23). It didn’t. Instead, Overstock.com
claimed that the all amounts due the company from underbilling its
fulfillment partners was "not assured" and improperly called such
potential recoveries a "gain contingency" (SFAS No. 5 paragraph 1,
2, and 17).
The only way that Overstock.com could
recognize income from underbilling its fulfillment partners in
future accounting periods is if there was a “significant uncertainty
as to collection” of all underbilled amounts (See SFAS No. 5
paragraph 23)
As it turns out, a large portion of the
underbilled amounts to fulfillment partners was easily recoverable
within a brief period of time. In fact, within 68 days of announcing
underbilling errors, the company already collected a total of “$1.8
million relating to payments from partners who were underbilled
earlier in the year.” Therefore, Overstock.com cannot claim that
there was a "significant uncertainty as to collection" or that
recovery was "not assured."
No gain contingency existed. Overstock.com
already earned "fees and charges" from underbilled fulfillment
partners in prior periods. Rather, a loss contingency existed for a
reasonably estimated amount of uncollectible "fees and charges."
Overstock.com should have restated prior affected financial reports
to properly reflect income earned from fulfillment partners instead
of reflecting such income when amounts were collected in future
quarters. Management should have made a reasonable estimate for
unrecoverable amounts and booked an appropriate reserve against
"fees and charges" owed to it (See SFAS No. 5 Paragraph 22 and 23).
Therefore, Overstock.com overstated its
customer refund and credit accounting error by failing to accrue
fees and charges due from its fulfillment partners as income in the
appropriate accounting periods, less a reasonable reserve for
unrecoverable amounts. By deferring recognition of income until
underbilled amounts were collected, the company effectively created
a "cookie jar" reserve to increase future earnings.
In addition, Overstock.com failed to
disclose any potential “gain contingency” in its Q3 2008 10-Q
report, when it disclosed that it underbilled its fulfillment
partners (See SFAS No. 5 Paragraph 17b). Apparently, Overstock.com
used a backdated rationale for using cash basis accounting to
correct its accounting error in response to my blog posts (here and
here) detailing its violation of GAAP.
PricewaterhouseCoopers warns against using
"conservatism to manage future earnings"
As I detailed above, Patrick Byrne claimed
on an internet chat board that “conservatism demands" waiting until
"monies flow in" from under-billed fulfillment partners to recognize
income, after such an error is discovered by the company. However, a
document from PricewaterhouseCoopers (Overstock.com’s auditors thru
2008) web site cautions against using “conservatism” to manage
future earnings by deferring gains to future accounting periods:
SFAS No. 5 Technical Notes cautions about
using “conservatism” to manage future earnings by deferring gains to
future accounting periods:
"Conservatism...should no[t] connote
deliberate, consistent understatement of net assets and profits."
Emphasis added] CON 5 describes realization in terms of recognition
criteria for revenues and gains, as:"Revenue and gains generally are
not recognized until realized or realizable... when products (goods
or services), merchandise or other assets are exchanged for cash or
claims to cash...[and] when related assets received or held are
readily convertible to known amounts of cash or claims to
cash....Revenues are not recognized until earned ...when the entity
has substantially accomplished what it must do to be entitled to the
benefits represented by the revenues." Almost invariably, gain
contingencies do not meet these revenue recognition criteria.
Note: Bold print and italics added by me.
Overstock.com "substantially accomplished
what it must do to be entitled to the benefits represented by the
revenues" since the fulfillment partners were "contractually
obligated" to pay underbilled amounts. Those underbilled "fees and
charges" were "realizable" as evidenced by the fact that the company
already collected a total of “$1.8 million relating to payments from
partners who were underbilled earlier in the year" within a mere 68
days of announcing its billing errors.
If we follow guidance by Overstock.com's
fiscal year 2008 auditors, the amounts due from underbilling
fulfillment partners cannot be considered a gain contingency, as
claimed by the company. PricewaterhouseCoopers was subsequently
terminated as Overstock.com's auditors and replaced by Grant
Thornton.
Q1 2009
In Q1 2009, even more amounts from
underbilling fulfillment partners were recovered. In addition, the
company disclosed a new accounting error by failing to book a
“refund due of overbillings by a freight carrier for charges from Q4
2008.” See quote from 10-Q report below:
In the first quarter of 2009, we reduced
total cost of goods sold by $1.9 million for billing recoveries from
partners who were underbilled in 2008 for certain fees and charges
that they were contractually obligated to pay, and a refund due of
overbillings by a freight carrier for charges from the fourth
quarter of 2008. When the underbilling and overbillings were
originally discovered, we determined that the recovery of such
amounts was not assured, and that consequently the potential
recoveries constituted a gain contingency. Accordingly, we
determined that the appropriate accounting treatment for the
potential recoveries was to record their benefit only when such
amounts became realizable (i.e., an agreement had been reached with
the other party and the other party had the wherewithal to pay).
Note: Bold print and italics added by me.
Overstock.com continued to improperly
recognize deferred income from previously underbilling fulfillment
partners. The new auditors, Grant Thornton, would be wise to review
Overstock.com's accounting treatment of billing errors and recommend
that its clients restate affected financial reports to comply with
GAAP. Otherwise, they should not give the company a clean audit
opinion for 2009.
Using accounting errors to previous
quarters to boost profits in future quarters
Lee Webb from Stockwatch sums up
Overstock.com's accounting latest trickery:
… Overstock.com managed to turn a
controversial fourth-quarter profit last year after discovering that
it had underbilled its fulfillment partners to the tune of
$1.8-million earlier in the year. Rather than backing that amount
out into the appropriate periods, Overstock.com reported it as
one-time gain and reduced the cost of goods sold for the quarter by
$1.8-million. That bit of accounting turned what would have been an
$800,000 fourth-quarter loss into a $1-million profit.
As it turns out, Overstock.com managed to
find some more money that it used to reduce the cost of goods sold
for the first quarter of 2009, too.
"In Q1 2009, we reduced total cost of goods
sold by $1.9-million for recoveries from partners who were
underbilled in 2008 for certain fees and charges that they were
contractually obligated to pay and a refund due of overbillings by a
freight carrier for charges from Q4 2008," the company disclosed.
"We just keep squeezing the tube of
toothpaste thinner and thinner and finding new stuff to come out,"
Mr. Byrne remarked during the conference call after chief financial
officer Steve Chesnut said that the underbilling and overbilling had
been found "as part of good corporate diligence and governance."
In addition, Overstock.com managed to
record a $1.9-million gain, reported as part of "other income," by
extinguishing $4.9-million worth of its senior convertible notes,
which it bought back at rather hefty discount. If not for the
fortuitous 2008 underbilling recoveries, fourth-quarter overbillings
refund and the paper gain from extinguishing some of its debt,
Overstock.com would have tallied a first-quarter loss of
$5.9-million or approximately 26 cents per share.
So, while Overstock.com did not manage to
conjure up a first-quarter profit by using the same accounting
abracadabra employed in the fourth quarter, it did succeed in
trimming its net loss to $2.1-million.
Bad corporate diligence and governance
During the Q1 2009 earnings conference
call, CFO Steve Chesnut boasted about finding accounting errors:
So just as part of good corporate diligence
and governance we've found these items.
Note: Bold print and italics added by me.
Actually, it was bad corporate diligence
and governance by CEO Patrick Byrne that caused the accounting
errors to happen by focusing on a vicious retaliatory smear campaign
against critics, while he runs his company into the ground with $267
million in accumulated losses to date and never reporting a
profitable year.
Memo to Grant Thornton (Overstock.com's new
auditors)
Overstock.com is a company that has not
produced a single financial report prior to Q3 2008 in compliance
with Generally Accepted Accounting Principles and Securities and
Exchange Commission disclosure rules from its inception, without
having to later correct them, unless such reports were too old to
correct. Two more financial reports (Q4 2008 and Q1 2009) don't
comply with GAAP and need to be restated, too.
To be continued in part 2.
In the mean time, please read:
William K. Wolfrum: "Sam E. Antar: From
Crazy Eddie to Patrick Byrne's Worst Nightmare."
Gary Weiss: "The Whisper Campaign Against
an Overstock.com Whistleblower"
Written by:
Sam E. Antar (former Crazy Eddie CFO and a
convicted felon)
Blog Update:
Investigative journalist and author Gary
Weiss commented on Overstock.com's history of GAAP violations in his
blog:
There are few certainties in this world:
gravity, the speed of light, and, more obviously every quarter, the
utter unreliability of Overstock.com financial statements.
Acclaimed forensic accountant and author
Tracy Coenen notes in her blog:
Don’t laugh too hard at Patrick Byrne’s
explanation of the repeated accounting errors and improper treatment
of those errors, as reported by Lee Webb of Stockwatch:
“We just keep squeezing the tube of
toothpaste thinner and thinner and finding new stuff to come out,”
Mr. Byrne remarked during the conference call after chief financial
officer Steve Chesnut said that the underbilling and overbilling had
been found “as part of good corporate diligence and governance.”
Good corporate diligence and governance? Is
this guy for real? How about having an accounting system that
prevents errors from occurring every quarter?
Of course, Overstock.com management has to
explain away why Sam Antar is finding all these manipulations and
irregularities in their financial reporting. They can stalk and
harass him all they want, call him a criminal all they want, but
there is no explaining it away. The numbers don’t lie. Overstock.com
just always counted on no one being as thorough as Sam.
"Auditor Merry Go Round at Overstock.com," Big Four Blog,
January 8, 2010 ---
http://www.bigfouralumni.blogspot.com/
We were intrigued by a recent quote from
Overstock.com's President.
On December 29, 2009,we saw, "It is nice to be back
with a Big Four accounting firm," said Jonathan Johnson, President of
Overstock.com. "We are pleased to have the resources and professionalism
that KPMG brings as our auditors. We will work closely with them to timely
file our 2009 Form 10-K. In the meantime, we remain in discussions with the
SEC to answer the staff's questions on the accounting matters that lead to
our filing an unreviewed Form 10-Q for Q3."
As we dug further into this, we found an
interesting situation between client and auditors; and between the opinions
of two different auditors, as you'll see below.
And what makes it curioser is that Overstock.com
has engaged three separate auditors in a space of just nine months.
From 2001 to 2008, PricewaterhouseCoopers were the
statutory auditors to Overstock.com, but this changed when the company
decided to engage a replacement through a RFP process, and Grant Thornton
was selected in March 2009. Subsequently, Overstock.com received a letter
from the SEC in October 2009 questioning the accounting for a "fulfillment
partner overpayment" (which Overstock.com recovered and recognized $785,000
as income in 2009 as it was received). Apparently earlier
PricewaterhouseCoopers had determined that this amount should not be
recognized in fiscal year 2008, but in 2009. However, the new auditor, Grant
Thornton after further investigation on the receipt of the SEC note,
determined that the amount should have been booked in 2008 and not in 2009,
and that Overstock.com should restate its 2008 financials to reflect this as
an asset
This put Overstock.com in a difficult spot, with a
severe disagreement between two audit opinions. In the appropriate words of
Patrick Byrne, the company's Chairman and CEO, "Thus, we are in a quandary:
one auditing firm won't sign-off on our Q3 Form 10-Q unless we restate our
2008 Form 10-K, while our previous auditing firm believes that it is not
proper to restate our 2008 Form 10-K. Unfortunately, Grant Thornton's
decision-making could not have been more ill-timed as we ran into SEC filing
deadlines."
In general, Overstock.com agreed with PwC's
recommendation not to account for the amount in 2008 and not with Grant
Thornton's opinion of booking it in 2008.
While all this was going on, Overstock.com had a
make a choice on its Q3-2009 quarterly financials, which they proceeded to
file without required review by an auditor (in violation of SAS 100). This
unusual filing brought on a censure by NASDAQ, who then finally agreed to
grant the company time till May 2010 to refile the earnings.
Meanwhile, Grant Thornton wrote separately to the
SEC outlining its position, and Overstock.com responded to GT's points in a
letter from the President directly to the shareholders.
Eventually, in November 2009, Overstock.com
dismissed Grant Thornton as its auditor, and Grant Thornton immediately
severed its relationship with the company through a letter to the SEC.
After a search, on December 29, 2009, Overstock.com
finally hired KPMG to review all its financials, accounting procedures and
determine the final disposition of the timing for accounting of this issue.
Other bloggers with more knowledge of the stock and
history, are taking a more aggressive position on Overstock.com's actions,
here's a recent post from SeekingAlpha.com:
http://seekingalpha.com/article/180743-overstock-s-latest-accounting-and-disclosure-inconsistencies?source=yahoo
All this switching around of auditors in such a
short space of time does call into question the company's stance on
alignment with external auditors opinions. Typically, public companies do
try to stay with one acccounting firm over a long period of time and iron
out any differences at a professional level. This kind of merry-go-rounding
seems to suggest that Overstock.com is looking for the auditor who will
agree with the company's stance rather than an independent third party who
will provide an honest perspective in the best interest of investors, whose
interests they do represent as their fiduciary responsibility.
And that's where it apppears to stand today, with
KPMG having the unenviable task of sorting through all this confusion,
settling issues with the SEC and the NASDAQ, and putting Overstock.com back
in compliance and in some sense of settlement with previous auditors. GT and
PwC seem to have washed their hands off this, but that's not to say, that a
shareholder lawsuit may spring from the blue, as we have seen in many cases,
that such messy audits have the potential for long tail litigations.
Meanwhile, on the stock market, Overstock.com ($OSTK)hit
a high of $17.65 on October 20, 2009 and then has been steadily drifting
downwards to $13.24 per share today. At 22.84 million shares outstanding,
this is a loss of market capitalization of $110 million. Other online
retailers have had generally better stock performance during this period, so
clearly the accounting issue is having some level of overhang on stock
performance.
In another very interesting use of philosophy from
the Chairman's letter:
"All things are subject to interpretation;
whichever interpretation prevails at a given time is a function of power and
not truth." - Friedrich Nietzsche
And we hope that in due course, we find the real
truth, and not the interpretation that is biased towards the powerful.
Now, none of this would be apparent to the average
online shopper who is seeking a real retail bargain on the "O, O, O, The Big
Big O, Overstock.com", but there is always more to be had beyond the skin
than is evident on the surface.
Clearly, this is not going away soon, and more news
is sure to emerge as the company files its audited financials, and we'll
blog as we hear of developments.
"Auditor Musical Chairs," by Francine McKenna, re: The Auditors,
February 12, 2007 ---
http://retheauditors.com/2007/02/12/auditor-musical-chairs/
Bob Jensen's threads on multiple auditing firms ---
http://faculty.trinity.edu/rjensen/fraud001.htm#BigFirms
Appendix 4
Replies from Jagdish Gangolly
and Paul Williams
January 21, 2010 reply from Jagdish Gangolly
[gangolly@gmail.com]
I have two basic comments. The first has to do with
the competence of accounting reviewers with minimal statistical (and
econometrics) training passing judgment on what is essentially econometric
work. The second has to do with Vernon Smith cite in Steve's letter. I state
these two with no pernicious intent, but in a friendly spirit of
intellectual inquiry. In what follows, I'll concentrate on the Vernon Smith
cite.
IF I know Vernon personally and can vouch his
integrity, then if Vernon says 11:03 I would take it at its face value,
heavily discounting possibilities such as his doctoring his watch because he
is hungry and we had a 11am lunch appointment, or that he wants to get rid
of me for some reason and his 11am appointment with some one else is his
alibi. In case of journal submissions withy blind reviews, one can not
discount such possibilities if Pond-Fleishman situation is to be avoided at
all costs.
The point I am making is that with time we all can
agree with the US time server as the arbiter, and so avoid calibration isues.
On the other hand, with most empirical social sciences, the sampling problem
is somewhat like the Turing's Halting problem in computation; it is
undecidable. That being the case, in case of most "empirical" work in
accounting replication with more, different, or different regime data must
be encouraged. Ignorance is no bliss, and we do not know how many
Pons-Fleishman situations exist in accounting.
Laws in the social sciences hold only in a
probabilistic sense, the reviewers' acceptance decisions are point estimates
of such probabilities. In no science do you accept probability numbers based
on a single (or two) estimate. If Steve thinks so he must provide arguments.
His communitarian argument holds no water in this context. In the social
science, truth is socially constructed, but truth values are physically
obtained.
Regards,
Jagdish S. Gangolly
Department of Informatics
College of Computing & Information
State University of New York at Albany
Harriman Campus, Building 7A, Suite 220
Albany, NY 12222 Phone: 518-956-8251, Fax: 518-956-8247
January 22, 2010 reply from Paul Williams
[Paul_Williams@ncsu.edu]
Bob and Jagdish,
I pretty much exhausted myself
debating with Steve before. Talking to a wall is productive only for someone
who is insane and, believing I'm not there yet, I have given up on him.
Steve simply doesn't hear you.
Jagdish, your observation about
accountants' pretensions to econometric rectitude are well said. In this
vein I would suggest that Bob add to the list of references an excellent
article by Jon Elster, "Excessive Ambitions," Capitalism and Society, 4(2),
2009, Article 1. The article takes to takes to task the "excessive
ambitions" of the social sciences as quantitative sciences. One section is
devoted to data analysis. He observes about social science empirical work:
"In the absence of substantive knowledge -- whether mathematical or causal
-- the mechanical search for correlations can produce nonsense. I suggest
that a non-negligible part of empirical social science consists of
half-understood statistical theory applied to half- assimilated empirical
material (emphasis in the original)."
He goes on to describe a study
done by David Freedman, a statistician who selected six research papers from
among the American Political Science Review, Quarterly Journal of
Economics, and American Sociological Review and analyzed them for
statistical errors of all kinds. Needless to say they were loaded with them
to the point of being meaningless.
This is reminiscent of our days
at Florida State University when Ron Woan (with a masters in stat and 11
years at U of Ill. as a statistics consultant) would conclude every seminar
with a devastating deconstruction of the statistical flaws in every paper.
The issue goes well beyond simply replication -- what point is there to
replication of studies that are nonsense to start with.
This kind of academic community,
as Elster concludes, doesn't just produce useless research, but harmful
research. In 40 years of "rigorous" empirical accounting research we have
not produced anything that meets even minimal standards of "evidence." One
comment Elster made that would really piss of Steve: "Let me conclude on
this point by exploring a conjecture alluded to earlier: we may learn more
about the world by reading medium- prestige journals than by reading
high-prestige and low-prestige journals."
Amen to that.
Paul Williams
North Carolina State University
Jensen Comment
I think that above Paul Williams used "Steve" in the generic sense to depict
virtually all accountics researchers over three decades that have generally
ignored their critics while truly trying to build elegant mathematical sand
castles in Plato's Cave, including Professors Zimmerman, Watts, Ball, Beaver,
Kinney, and Demski.
Joel Demski probably said it best in a 2006 Plenary Speech
at the Annual American Accounting Association Meetings:
Statistically there are a few youngsters who came to academia for the joy of
learning, who are yet relatively untainted by the
vocational virus.
I urge you to nurture your taste for learning, to follow your joy. That is
the path of scholarship, and it is the only one with any possibility of
turning us back toward the academy.
Joel
Demski,
"Is Accounting an Academic Discipline? American Accounting Association
Plenary Session" August 9, 2006 ---
http://bear.cba.ufl.edu/demski/Is_Accounting_an_Academic_Discipline.pdf
It's wonderful that some brilliant accounting professors became immune to vocational viruses and played among themselves in their fantasy
worlds in Plato's Cave. In Plato's cave researchers don't have to worry about
replications and reality of underlying assumptions. Sadly, however, they're just
gaming the system until they can point to results that have relevance in the
real world outside Plato's Cave where viruses are deadly.
What's unfortunate is that accountics researchers put a
lock on the accountancy doctoral programs and the tenure gates at major research
universities such that a vocational virus is lethal to tenure and promotion ---
http://faculty.trinity.edu/rjensen/395wpTAR/Web/TAR395wp.htm
Nearly all the articles published in TAR over the past several decades are
limited to accountics studies that, in my viewpoint, have questionable internal
and external validity due to missing variables, measurement errors, and
simplistic mathematical structures. If accountants grounded in the real world
were allowed to challenge the external validity of accountics studies it is
possible that accountics researchers would pay greater attention to
external validity ---
http://en.wikipedia.org/wiki/External_Validity
Similarly if accountants grounded in the real world were allowed to
challenge the external validity of accountics studies it is possible that
accountics researchers would pay greater attention to
internal validity ---
http://en.wikipedia.org/wiki/Internal_Validity
Steve replied by stating that during his term as editor he rejected one
commentary but later accepted it after the author conducted empirical research
and extended the original study in a significant way. However, he and I differ
with respect to what I call a "commentary." I consider a commentary on a
research paper to be more like a discussant's comments when the paper is
presented at a conference. Without actually conducting additional empirical
research a discussant can criticize or praise a paper and suggest ways that the
research can be improved. The discussant does not actually have to conduct the
suggested research extensions that Steve tells me is a requisite for his
allowing TAR to publish a comment.
Hi Marc,
Paul Williams has addressed your accountics scientists power questions much
better than me in both an AOS article and in AECM messaging ---
http://www.trinity.edu/rjensen/TheoryTAR.htm#Comments
Williams, P. F., Gregory, J. J., I. L. (2006). The Winnowing Away of Behavioral
Accounting Research in the U.S.:The Process of Anointing Academic Elites.
Accounting, Organizations and Society/Elsevier, 31, 783-818.
Williams, P.F. “Reshaping Accounting Research: Living in the World in Which We
Live,” Accounting Forum, 33, 2009: 274 – 279.
Schwartz, B., Williams, S. and Williams, P.F., “U.S. Doctoral Students
Familiarity with Accounting Journals: Insights into the Structure of the U.S.
Academy,” Critical Perspectives on Accounting, 16(2),April 2005: 327-348.
Williams, Paul F., “A Reply to the Commentaries on: Recovering Accounting as a
Worthy Endeavor,” Critical Perspectives on Accounting, 15(4/5), 2004: 551-556.
Jensen Note: This journal prints
Commentaries on previous published articles, something that TAR referees just
will not allow.
Williams, Paul and Lee, Tom, “Accounting from the Inside: Legitimizing the
Accounting Academic Elite,” Critical Perspectives on Accounting (forthcoming).
Jensen Comment
As far as accountics science power in the AAA is concerned, I think that in year
2010 we will look back at years 2011-12 as monumental shifts in power, not the
least of which is the democratization of the AAA. Changes will take time in both
the AAA and in the AACSB's accountancy doctoral programs where accountics
scientists are still firmly entrenched.
But accountics scientist political power will wane, Changes will begin with the
AAA Publications Committee and then with key editorships, notably the editorship
of TAR.
If I have any influence in any of this it will be to motivate our leading
accountics scientists to at last start making contributions to the AAA Commons.
I know that making accountics scientists feel guilty of negligence on the AAA
Commons is not the best motivator as a rule, but what other choice have I got at
this juncture?
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
Respectfully,
Bob Jensen
Steve Supports My Idea and Then Douses it in
Cold Water
I wish academic accounting researchers would work harder to weed out bad
research reported in top academic accounting research journals.
I can't recall a single accounting research study in history being judged so
harshly.
Academic accountics researchers rarely examine whether other accountics
researchers broke the rules or made innocent mistakes.
"Study Linking Vaccine to Autism Broke Research Rules, U.K. Regulators Say
MMR/Autism Doctor Acted 'Dishonestly,' 'Irresponsibly'," by Nicky Broyd,
WebMD, January 29, 2010 ---
http://children.webmd.com/news/20100129/mmr-autism-doctor-acted-dishonestly-irresponsibly
The British doctor who
led a study suggesting a link between the
measles/
mumps/rubella (MMR) vaccine and
autism acted "dishonestly and irresponsibly," a
U.K. regulatory panel has ruled.
The panel represents the U.K. General Medical Council
(GMC), which regulates the medical profession. It ruled only on whether
Andrew Wakefield, MD, and two colleagues acted properly in carrying out
their research, and not on whether
MMR vaccine has anything to do with autism.
In the ruling, the GMC used strong language to
condemn the methods used by Wakefield in conducting the study.
In the study, published
12 years ago, Wakefield and colleagues suggested there was a
link between the MMR vaccine and autism. Their
study included only 12 children, but wide media coverage set off a panic
among parents. Vaccinations plummeted; there was a subsequent increase in
U.K. measles cases.
In 2004, 10 of the study's 13 authors disavowed the
findings. The Lancet, which originally published the paper, retracted
it after learning that Wakefield -- prior to designing the study -- had
accepted payment from lawyers suing vaccine manufacturers for causing
autism.
Fitness to Practice
The GMC's Fitness to Practise panel heard evidence
and submissions for 148 days over two and a half years, hearing from 36
witnesses. It then spent 45 days deciding the outcome of the hearing.
Besides Wakefield, two former colleagues went before the panel -John
Walker-Smith and Simon Murch. They were all found to have broken guidelines.
The disciplinary hearing found Wakefield showed a
"callous disregard" for the suffering of children and abused his position of
trust. He'd also "failed in his duties as a responsible consultant."
He'd taken blood samples from children attending
his son's birthday party in return for money, and was later filmed joking
about it at a conference.
He'd also failed to disclose he'd received money
for advising lawyers acting for parents who claimed their children had been
harmed by the triple vaccine
Continued in article
"U.S. Finds Scientific Misconduct by Former Nursing Professor,"
Inside Higher Ed, January 29, 2010 ---
http://www.insidehighered.com/news/2010/01/29/qt#218825
A former nursing professor at Tennessee State
University falsified data and results in federally sponsored research on
sexual risk behaviors among mentally ill homeless men, the Office of
Research Integrity at the U.S. Department of Health and Human Services
announced Thursday. The agency, in a statement in
the Federal Register, said that James Gary Linn, who was a professor
of nursing at Tennessee State, had provided falsified data to the university
and to a journal that published an article on his research in Cellular
and Molecular Biology. He will be barred from involvement in any federal
studies for three years.
Professors Who Cheat ---
http://faculty.trinity.edu/rjensen/plagiarism.htm#ProfessorsWhoPlagiarize
Bob Jensen's threads on the absence of replication and validity studies in
accountics research are at
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
Epilogue
Jensen Question to Steve Kachelmeier
Have you ever considered an AMR-type (“Dialogue”) invitation to comment?
These are commentaries that do not have to extend the research findings but may
question the research assumptions.
Steve's Reply
I have not considered openly soliciting comments on a particular article
any more than I have considered openly soliciting research on “X” (you pick the
X). I let the community decide, and I try to run a fair game. By the way, your
idea regarding an online journal of accounting replications may have merit – I
suggest that you direct that suggestion to the AAA Publications Committee.
My guess, however, is that such a journal would receive few submissions, and
that it would be difficult to find a willing editor.
Jensen Comment
In other words, the accounting research academy purportedly has little interest
in discussing and debating the external validity of the accountics research
papers published in TAR. Most likely it's too much of a bother for accountics
researchers to be forced to debate external validity of their findings.
The :"Shields Against Validity Challenges in Plato's Cave" will remain in
place long after Bob Jensen has departed from this earth.
That's truly sad!
Steven J. Kachelmeier's July 2011 Editorial as Departing Senior Editor of
The Accounting Review (TAR)
"Introduction to a Forum on Internal Control Reporting and Corporate Debt,"
by Steven J. Kachelmeier, The Accounting Review, Vol. 86, No. 4, July
2011 pp. 1129–113 (not free online) ---
http://aaapubs.aip.org/getpdf/servlet/GetPDFServlet?filetype=pdf&id=ACRVAS000086000004001129000001&idtype=cvips&prog=normal
One of the more surprising things I
have learned from my experience as Senior Editor of
The Accounting Review
is just how often a
‘‘hot
topic’’
generates multiple
submissions that pursue similar research objectives. Though one might view
such situations as enhancing the credibility of research findings through
the independent efforts of multiple research teams, they often result in
unfavorable reactions from reviewers who question the incremental
contribution of a subsequent study that does not materially advance the
findings already documented in a previous study, even if the two (or more)
efforts were initiated independently and pursued more or less concurrently.
I understand the reason for a high incremental contribution standard in a
top-tier journal that faces capacity constraints and deals with about 500
new submissions per year. Nevertheless, I must admit that I sometimes feel
bad writing a rejection letter on a good study, just because some other
research team beat the authors to press with similar conclusions documented
a few months earlier. Research, it seems, operates in a highly competitive
arena.
Fortunately, from time to time, we
receive related but still distinct submissions that, in combination, capture
synergies (and reviewer support) by viewing a broad research question from
different perspectives. The two articles comprising this issue’s forum are a
classic case in point. Though both studies reach the same basic conclusion
that material weaknesses in internal controls over financial reporting
result in negative repercussions for the cost of debt financing, Dhaliwal et
al. (2011) do so by examining the public market for corporate debt
instruments, whereas Kim et al. (2011) examine private debt contracting with
financial institutions. These different perspectives enable the two research
teams to pursue different secondary analyses, such as Dhaliwal et al.’s
examination of the sensitivity of the reported findings to bank monitoring
and Kim et al.’s examination of debt covenants.
Both studies also overlap with yet a
third recent effort in this arena, recently published in the
Journal of Accounting
Research by Costello and
Wittenberg-Moerman (2011). Although the overall
‘‘punch
line’’
is similar in all three studies (material
internal control weaknesses result in a higher cost of debt), I am intrigued
by a ‘‘mini-debate’’
of sorts on the different conclusions
reache by Costello and Wittenberg-Moerman (2011) and by Kim et al.
(2011) for the effect of material weaknesses on debt covenants.
Specifically, Costello and Wittenberg-Moerman (2011, 116) find that
‘‘serious,
fraud-related weaknesses result in a significant decrease in financial
covenants,’’
presumably because banks substitute more
direct protections in such instances, whereas Kim et al.
Published Online: July 2011
(2011) assert from their cross-sectional
design that company-level material weaknesses are associated with
more
financial covenants in
debt contracting.
In reconciling these conflicting
findings, Costello and Wittenberg-Moerman (2011, 116) attribute the Kim et
al. (2011) result to underlying
‘‘differences
in more fundamental firm characteristics, such as riskiness and information
opacity,’’
given that, cross-sectionally, material
weakness firms have a greater number of financial covenants than do
non-material weakness firms even
before the disclosure of the material
weakness in internal controls. Kim et al. (2011) counter that they control
for risk and opacity characteristics, and that advance leakage of internal
control problems could still result in a debt covenant effect due to
internal controls rather than underlying firm characteristics. Kim et al.
(2011) also report from a supplemental change analysis that, comparing the
pre- and post-SOX 404 periods, the number of debt covenants falls for
companies both with and without
material
weaknesses in internal controls, raising the question of whether the
Costello and Wittenberg-Moerman (2011)
finding reflects a reaction to the disclosures or simply a more general
trend of a declining number of debt covenants affecting all firms around
that time period. I urge readers to take a look at both articles, along with
Dhaliwal et al. (2011), and draw their own conclusions. Indeed, I believe
that these sorts . . .
Continued in article
Jensen Comment
Without admitting to it, I think Steve has been embarrassed, along with many
other accountics researchers, about the virtual absence of validation and
replication of accounting science (accountics) research studies over the past
five decades. For the most part, accountics articles are either ignored or
accepted as truth without validation. Behavioral and capital markets empirical
studies are rarely (ever?) replicated. Analytical studies make tremendous leaps
of faith in terms of underlying assumptions that are rarely challenged (such as
the assumption of equations depicting utility functions of corporations).
Accounting science thereby has become a pseudo
science where highly paid accountics professor referees are protecting each
others' butts ---
"574 Shields Against Validity Challenges in Plato's Cave" ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
The above link contains Steve's rejoinders on the replication debate.
In the above editorial he's telling us that there is a middle ground for
validation of accountics studies. When researchers independently come to similar
conclusions using different data sets and different quantitative analyses they
are in a sense validating each others' work without truly replicating each
others' work.
I agree with Steve on this, but I would also argue that these types of
"validation" is too little to late relative to genuine science where replication
and true validation are essential to the very definition of science. The types
independent but related research that Steve is discussing above is too
infrequent and haphazard to fall into the realm of validation and replication.
When's the last time you witnesses a TAR author criticizing the research of
another TAR author (TAR does not publish critical commentaries)?
Are TAR articles really all that above criticism?
Even though I admire Steve's scholarship, dedication,
and sacrifice, I hope future TAR editors will work harder at turning accountics
research into real science!
What Went Wrong With Accountics Research? ---
http://faculty.trinity.edu/rjensen/theory01.htm#WhatWentWrong
"574 Shields Against Validity Challenges in Plato's Cave" ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
Steve's 2010 Update on TAR ---
http://www.cs.trinity.edu/~rjensen/temp/TheoryAnnual
ReportTAR_2010.pdf
Shielding Against Validity Challenges in Plato's Cave ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
-
With a Rejoinder from the 2010 Senior Editor of The Accounting Review
(TAR), Steven J. Kachelmeier
- With Replies in Appendix 4 to Professor Kachemeier by Professors
Jagdish Gangolly and Paul Williams
- With Added Conjectures in Appendix 1 as to Why the Profession of
Accountancy Ignores TAR
- With Suggestions in Appendix 2 for Incorporating Accounting Research
into Undergraduate Accounting Courses
What went wrong in accounting/accountics research?
---
http://faculty.trinity.edu/rjensen/theory01.htm#WhatWentWrong
The Sad State of Accountancy Doctoral
Programs That Do Not Appeal to Most Accountants ---
http://faculty.trinity.edu/rjensen/theory01.htm#DoctoralPrograms
AN ANALYSIS OF THE EVOLUTION OF RESEARCH
CONTRIBUTIONS BY THE ACCOUNTING REVIEW: 1926-2005 ---
http://faculty.trinity.edu/rjensen/395wpTAR/Web/TAR395wp.htm#_msocom_1
Bob Jensen's threads on accounting theory
---
http://faculty.trinity.edu/rjensen/theory01.htm
Tom Lehrer on Mathematical Models and
Statistics ---
http://www.youtube.com/watch?v=gfZWyUXn3So
Systemic problems of accountancy (especially the
vegetable nutrition paradox) that probably will never be solved ---
http://faculty.trinity.edu/rjensen/FraudConclusion.htm#BadNews
Appendix 6
And to Captain John Harry
Evans III, I salute and say “Welcome Aboard.”
Most of you probably received Jean’s message below.
Now I will have to begin bugging an entirely new TAR Editor
after I, a long last, had Steve trained:
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
All joking aside, I look forward to a new era for TAR and
truly want to thank Steve Kachelmeier for the immense sacrifices he made in his
personal and professional life to be on the deck of the USS Accounting
Review.
And to Captain John Harry Evans III, I salute and say
“Welcome Aboard.”
(his actual rank may have been higher than a Captain)
Robert E. (Bob) Jensen
Trinity University Accounting Professor (Emeritus)
190 Sunset Hill Road
Sugar Hill, NH 03586
Tel. 603-823-8482
www.trinity.edu/rjensen
From:
Jean Bedard [mailto:JBedard@bentley.edu]
Sent: Tuesday, March 23, 2010 1:35 PM
To: Jensen, Robert
Subject: John Harry Evans III Named Next Editor of "The Accounting
Review"
Dear
Robert Jensen,
John
Harry Evans III, Alumni Professor of Accounting at the Katz Graduate School
of Business, University of Pittsburgh, has been named the next senior editor
of The Accounting Review.
Professor Evans' research has addressed a wide variety of issues in
managerial accounting, auditing, tax compliance and governmental accounting,
using analytical, empirical archival and experimental research methods. His
scholarly work has been published in The Accounting Review, Journal of
Accounting Research, Journal of Accounting and Economics, Accounting,
Organizations and Society, Journal of Management Accounting Research,
Journal of Accounting and Public Policy, Journal of Accounting, Auditing and
Finance, Medical Care, The Milbank Quarterly, and other journals.
Professor Evans has served as an editor of The Accounting Review
(2008-2010), editor of Journal of Management Accounting Research
(2002-2004), associate editor of Management Science (2008-2010), and
Journal of Accounting Literature (1995-present).
He
has been selected for excellence-in-teaching awards several times in MBA and
executive MBA programs. Professor Evans received an undergraduate degree in
economics from the United States Air Force Academy, a masters degree in
economics from UCLA and a doctorate in accounting from Carnegie-Mellon
University. Prior to his doctoral study, he worked as a research analyst for
the Air Force and for the Assistant Secretary of Defense. He will assume the
duties of "TAR" senior editor in late spring 2011 when Professor Steve
Kachelmeier completes his three-year term.
Jean
Bedard
Vice President for Publications
Steve's 2010 Update on TAR ---
http://www.cs.trinity.edu/~rjensen/temp/TheoryAnnual
ReportTAR_2010.pdf
Postscript Notes
The major problem in
accountics research using statistical inference is the underlying assumption of
stationary-state is the real world where probabilities on constantly in
transition. The major problem in accountics mathematical analytics is the
assumption that the modeled systems are in equilibrium, which is essentially the
same as the dubious assumption of stationary systems.
In real world games such as
poker tournaments, however, the assumption of stationary states is more
relevant. An example is given below.
"Universal statistical
properties of poker tournaments," by Clement Sire, Physics and Society ---
http://arxiv.org/abs/physics/0703122
We present a simple model of
Texas hold'em poker tournaments which retains the two main aspects of the
game: i. the minimal bet grows exponentially with time; ii. players have a
finite probability to bet all their money. The distribution of the fortunes
of players not yet eliminated is found to be independent of time during most
of the tournament, and reproduces accurately data obtained from Internet
tournaments and world championship events. This model also makes the
connection between poker and the persistence problem widely studied in
physics, as well as some recent physical models of biological evolution, and
extreme value statistics.
Turing Test (a test for the degree of machine "intelligence") ---
http://en.wikipedia.org/wiki/Turing_Test
Can humans distinguish between sequences of real and randomly generated
financial data?
Scientist have developed a new test to find out.
"Scientists Develop Financial Turing Test," MIT's Technology Review,
February 26, 2010 ---
http://www.technologyreview.com/blog/arxiv/24861/?nlid=2780
Bob Jensen's threads on financial reporting theory are at
http://faculty.trinity.edu/rjensen/theory01.htm
Steve's 2010 Update on TAR ---
http://www.cs.trinity.edu/~rjensen/temp/TheoryAnnual
ReportTAR_2010.pdf
Appendix 7
Science Warriors' Ego Trips
It is the mark of an educated mind to be able to
entertain a thought without accepting it.
Aristotle
"Science Warriors' Ego Trips," by Carlin Romano, Chronicle of Higher
Education's The Chronicle Review, April 25, 2010 ---
http://chronicle.com/article/Science-Warriors-Ego-Trips/65186/
Standing up for science excites some intellectuals
the way beautiful actresses arouse Warren Beatty, or career liberals boil
the blood of Glenn Beck and Rush Limbaugh. It's visceral. The thinker of
this ilk looks in the mirror and sees Galileo bravely muttering "Eppure si
muove!" ("And yet, it moves!") while Vatican guards drag him away. Sometimes
the hero in the reflection is Voltaire sticking it to the clerics, or Darwin
triumphing against both Church and Church-going wife. A brave champion of
beleaguered science in the modern age of pseudoscience, this Ayn Rand
protagonist sarcastically derides the benighted irrationalists and glows
with a self-anointed superiority. Who wouldn't want to feel that sense of
power and rightness?
You hear the voice regularly—along with far more
sensible stuff—in the latest of a now common genre of science patriotism,
Nonsense on Stilts: How to Tell Science From Bunk (University of Chicago
Press), by Massimo Pigliucci, a philosophy professor at the City University
of New York. Like such not-so-distant books as Idiot America, by Charles P.
Pierce (Doubleday, 2009), The Age of American Unreason, by Susan Jacoby
(Pantheon, 2008), and Denialism, by Michael Specter (Penguin Press, 2009),
it mixes eminent common sense and frequent good reporting with a cocksure
hubris utterly inappropriate to the practice it apotheosizes.
According to Pigliucci, both Freudian
psychoanalysis and Marxist theory of history "are too broad, too flexible
with regard to observations, to actually tell us anything interesting."
(That's right—not one "interesting" thing.) The idea of intelligent design
in biology "has made no progress since its last serious articulation by
natural theologian William Paley in 1802," and the empirical evidence for
evolution is like that for "an open-and-shut murder case."
Pigliucci offers more hero sandwiches spiced with
derision and certainty. Media coverage of science is "characterized by
allegedly serious journalists who behave like comedians." Commenting on the
highly publicized Dover, Pa., court case in which U.S. District Judge John
E. Jones III ruled that intelligent-design theory is not science, Pigliucci
labels the need for that judgment a "bizarre" consequence of the local
school board's "inane" resolution. Noting the complaint of
intelligent-design advocate William Buckingham that an approved science
textbook didn't give creationism a fair shake, Pigliucci writes, "This is
like complaining that a textbook in astronomy is too focused on the
Copernican theory of the structure of the solar system and unfairly neglects
the possibility that the Flying Spaghetti Monster is really pulling each
planet's strings, unseen by the deluded scientists."
Is it really? Or is it possible that the alternate
view unfairly neglected could be more like that of Harvard scientist Owen
Gingerich, who contends in God's Universe (Harvard University Press, 2006)
that it is partly statistical arguments—the extraordinary unlikelihood eons
ago of the physical conditions necessary for self-conscious life—that
support his belief in a universe "congenially designed for the existence of
intelligent, self-reflective life"? Even if we agree that capital "I" and
"D" intelligent-design of the scriptural sort—what Gingerich himself calls
"primitive scriptural literalism"—is not scientifically credible, does that
make Gingerich's assertion, "I believe in intelligent design, lowercase i
and lowercase d," equivalent to Flying-Spaghetti-Monsterism?
Tone matters. And sarcasm is not science.
The problem with polemicists like Pigliucci is that
a chasm has opened up between two groups that might loosely be distinguished
as "philosophers of science" and "science warriors." Philosophers of
science, often operating under the aegis of Thomas Kuhn, recognize that
science is a diverse, social enterprise that has changed over time,
developed different methodologies in different subsciences, and often
advanced by taking putative pseudoscience seriously, as in debunking cold
fusion. The science warriors, by contrast, often write as if our science of
the moment is isomorphic with knowledge of an objective world-in-itself—Kant
be damned!—and any form of inquiry that doesn't fit the writer's criteria of
proper science must be banished as "bunk." Pigliucci, typically, hasn't much
sympathy for radical philosophies of science. He calls the work of Paul
Feyerabend "lunacy," deems Bruno Latour "a fool," and observes that "the
great pronouncements of feminist science have fallen as flat as the
similarly empty utterances of supporters of intelligent design."
It doesn't have to be this way. The noble
enterprise of submitting nonscientific knowledge claims to critical
scrutiny—an activity continuous with both philosophy and science—took off in
an admirable way in the late 20th century when Paul Kurtz, of the University
at Buffalo, established the Committee for the Scientific Investigation of
Claims of the Paranormal (Csicop) in May 1976. Csicop soon after launched
the marvelous journal Skeptical Inquirer, edited for more than 30 years by
Kendrick Frazier.
Although Pigliucci himself publishes in Skeptical
Inquirer, his contributions there exhibit his signature smugness. For an
antidote to Pigliucci's overweening scientism 'tude, it's refreshing to
consult Kurtz's curtain-raising essay, "Science and the Public," in Science
Under Siege (Prometheus Books, 2009, edited by Frazier), which gathers 30
years of the best of Skeptical Inquirer.
Kurtz's commandment might be stated, "Don't mock or
ridicule—investigate and explain." He writes: "We attempted to make it clear
that we were interested in fair and impartial inquiry, that we were not
dogmatic or closed-minded, and that skepticism did not imply a priori
rejection of any reasonable claim. Indeed, I insisted that our skepticism
was not totalistic or nihilistic about paranormal claims."
Kurtz combines the ethos of both critical
investigator and philosopher of science. Describing modern science as a
practice in which "hypotheses and theories are based upon rigorous methods
of empirical investigation, experimental confirmation, and replication," he
notes: "One must be prepared to overthrow an entire theoretical
framework—and this has happened often in the history of science ...
skeptical doubt is an integral part of the method of science, and scientists
should be prepared to question received scientific doctrines and reject them
in the light of new evidence."
Considering the dodgy matters Skeptical Inquirer
specializes in, Kurtz's methodological fairness looks even more impressive.
Here's part of his own wonderful, detailed list: "Psychic claims and
predictions; parapsychology (psi, ESP, clairvoyance, telepathy,
precognition, psychokinesis); UFO visitations and abductions by
extraterrestrials (Roswell, cattle mutilations, crop circles); monsters of
the deep (the Loch Ness monster) and of the forests and mountains
(Sasquatch, or Bigfoot); mysteries of the oceans (the Bermuda Triangle,
Atlantis); cryptozoology (the search for unknown species); ghosts,
apparitions, and haunted houses (the Amityville horror); astrology and
horoscopes (Jeanne Dixon, the "Mars effect," the "Jupiter effect"); spoon
bending (Uri Geller). ... "
Even when investigating miracles, Kurtz explains,
Csicop's intrepid senior researcher Joe Nickell "refuses to declare a priori
that any miracle claim is false." Instead, he conducts "an on-site inquest
into the facts surrounding the case." That is, instead of declaring,
"Nonsense on stilts!" he gets cracking.
Pigliucci, alas, allows his animus against the
nonscientific to pull him away from sensitive distinctions among various
sciences to sloppy arguments one didn't see in such earlier works of science
patriotism as Carl Sagan's The Demon-Haunted World: Science as a Candle in
the Dark (Random House, 1995). Indeed, he probably sets a world record for
misuse of the word "fallacy."
To his credit, Pigliucci at times acknowledges the
nondogmatic spine of science. He concedes that "science is characterized by
a fuzzy borderline with other types of inquiry that may or may not one day
become sciences." Science, he admits, "actually refers to a rather
heterogeneous family of activities, not to a single and universal method."
He rightly warns that some pseudoscience—for example, denial of HIV-AIDS
causation—is dangerous and terrible.
But at other points, Pigliucci ferociously attacks
opponents like the most unreflective science fanatic, as if he belongs to
some Tea Party offshoot of the Royal Society. He dismisses Feyerabend's view
that "science is a religion" as simply "preposterous," even though he
elsewhere admits that "methodological naturalism"—the commitment of all
scientists to reject "supernatural" explanations—is itself not an
empirically verifiable principle or fact, but rather an almost Kantian
precondition of scientific knowledge. An article of faith, some cold-eyed
Feyerabend fans might say.
In an even greater disservice, Pigliucci repeatedly
suggests that intelligent-design thinkers must want "supernatural
explanations reintroduced into science," when that's not logically required.
He writes, "ID is not a scientific theory at all because there is no
empirical observation that can possibly contradict it. Anything we observe
in nature could, in principle, be attributed to an unspecified intelligent
designer who works in mysterious ways." But earlier in the book, he
correctly argues against Karl Popper that susceptibility to falsification
cannot be the sole criterion of science, because science also confirms. It
is, in principle, possible that an empirical observation could confirm
intelligent design—i.e., that magic moment when the ultimate UFO lands with
representatives of the intergalactic society that planted early life here,
and we accept their evidence that they did it. The point is not that this is
remotely likely. It's that the possibility is not irrational, just as
provocative science fiction is not irrational.
Pigliucci similarly derides religious explanations
on logical grounds when he should be content with rejecting such
explanations as unproven. "As long as we do not venture to make hypotheses
about who the designer is and why and how she operates," he writes, "there
are no empirical constraints on the 'theory' at all. Anything goes, and
therefore nothing holds, because a theory that 'explains' everything really
explains nothing."
Here, Pigliucci again mixes up what's likely or
provable with what's logically possible or rational. The creation stories of
traditional religions and scriptures do, in effect, offer hypotheses, or
claims, about who the designer is—e.g., see the Bible. And believers
sometimes put forth the existence of scriptures (think of them as "reports")
and a centuries-long chain of believers in them as a form of empirical
evidence. Far from explaining nothing because it explains everything, such
an explanation explains a lot by explaining everything. It just doesn't
explain it convincingly to a scientist with other evidentiary standards.
A sensible person can side with scientists on
what's true, but not with Pigliucci on what's rational and possible.
Pigliucci occasionally recognizes that. Late in his book, he concedes that
"nonscientific claims may be true and still not qualify as science." But if
that's so, and we care about truth, why exalt science to the degree he does?
If there's really a heaven, and science can't (yet?) detect it, so much the
worse for science.
As an epigram to his chapter titled "From
Superstition to Natural Philosophy," Pigliucci quotes a line from Aristotle:
"It is the mark of an educated mind to be able to entertain a thought
without accepting it." Science warriors such as Pigliucci, or Michael Ruse
in his recent clash with other philosophers in these pages, should reflect
on a related modern sense of "entertain." One does not entertain a guest by
mocking, deriding, and abusing the guest. Similarly, one does not entertain
a thought or approach to knowledge by ridiculing it.
Long live Skeptical Inquirer! But can we deep-six
the egomania and unearned arrogance of the science patriots? As Descartes,
that immortal hero of scientists and skeptics everywhere, pointed out, true
skepticism, like true charity, begins at home.
Carlin Romano, critic at large for The Chronicle Review, teaches
philosophy and media theory at the University of Pennsylvania.
Jensen Comment
One way to distinguish my conceptualization of science from pseudo science is
that science relentlessly seeks to replicate and validate purported discoveries,
especially after the discoveries have been made public in scientific journals
---
http://faculty.trinity.edu/rjensen/TheoryTar.htm
Science encourages conjecture but doggedly seeks truth about that conjecture.
Pseudo science is less concerned about validating purported discoveries than it
is about publishing new conjectures that are largely ignored by other pseudo
scientists.
"Modern Science and Ancient Wisdom," Simoleon Sense,
February 15, 2010 ---
http://www.simoleonsense.com/modern-science-and-ancient-wisdom/
Pure Munger……must read!!!!!!
This is by Mortimier Adler the author of How to read abook, which as profiled in
Robert Hagstrom’s Investing The Last Liberal Art and Latticework of Mental
Models.
Full Excerpt (Via Mortimier Adler)
The outstanding achievement and
intellectual glory of modern times has been empirical science and the
mathematics that it has put to such good use. The progress is has made in
the last three centuries, together with the technological advances that have
resulted therefrom, are breathtaking.
The equally great achievement and
intellectual glory of Greek antiquity and of the Middle Ages was philosophy.
We have inherited from those epochs a fund of accumulated wisdom. That, too,
is breathtaking, especially when one considers how little philosophical
progress has been made in modern times.
This is not say that no advances in
philosophical thought have occurred in the last three hundred years. They
are mainly in logic, in the philosophy of science, and in political theory,
not in metaphysics, in the philosophy of nature, or in the philosophy of
mind, and least of all in moral philosophy. Nor is it true to say that, in
Greek antiquity and in the later Middle Ages, from the fourteenth century
on, science did not prosper at all. On the contrary, the foundations were
laid in mathematics, in mathematical physics, in biology, and in medicine.
It is in metaphysics, the philosophy of
nature, the philosophy of mind, and moral philosophy that the ancients and
their mediaeval successors did more than lay the foundations for the sound
understanding and the modicum of wisdom we possess. They did not make the
philosophical mistakes that have been the ruination of modern thought. On
the contrary, they had the insights and made the indispensable distinctions
that provide us with the means for correcting these mistakes.
At its best, investigative science gives
us knowledge of reality. As I have argued elsewhere, philosophy is, at the
very least, also knowledge of reality, not mere opinion. Much better than
that, it is knowledge illuminated by understanding. At its best, it
approaches wisdom, both speculative and practical.
Precisely because science is investigative
and philosophy is not, one should not be surprised by the remarkable
progress in science and by the equally remarkable lack of it in philosophy.
Precisely because philosophy is based upon the common experience of mankind
and is a refinement and elaboration of the common-sense knowledge and
understanding that derives from reflection on that common experience,
philosophy came to maturity early and developed beyond that point only
slightly and slowly.
Science knowledge changes, grows,
improves, expands, as a result of refinements in and accretions to the
special experience — the observational data — on which science as an
investigative mode of inquiry must rely. Philosophical knowledge is not
subject to the same conditions of change or growth. Common experience, or
more precisely, the general lineaments or common core of that experience,
which suffices for the philosopher, remains relatively constant over the
ages.
Descartes and Hobbes in the seventeenth
century, Locke, Hume, and Kant in the eighteenth century, and Alfred North
Whitehead and Bertrand Russell in the twentieth century enjoy no greater
advantages in this respect than Plato and Aristotle in antiquity or than
Thomas Aquinas, Duns Scotus, and Roger Bacon in the Middle Ages.
How might modern thinkers have avoided the
philosophical mistakes that have been so disastrous in their consequences?
In earlier works I have suggested the answer. Finding a prior philosopher’s
conclusions untenable, the thing to do is to go back to his starting point
and see if he has made a little error in the beginning.
A striking example of the failure to
follow this rule is to be found in Kant’s response to Hume. Hume’s skeptical
conclusions and his phenomenalism were unacceptable to Kant, even though
they awoke him from his own dogmatic slumbers. But instead of looking for
little errors in the beginning that were made by Hume and then dismissing
them as the cause of Humean conclusions that he found unacceptable, Kant
thought it necessary to construct a vast piece of philosophical machinery
designed to produce conclusions of an opposite tenor.
The intricacy of the apparatus and the
ingenuity of the design cannot help but evoke admiration, even from those
who are suspicious of the sanity of the whole enterprise and who find it
necessary to reject Kant’s conclusions as well as Hume’s. Though they are
opposite in tenor, they do not help us to get at the truth, which can only
be found by correcting Hume’s little errors in the beginning, and the little
errors made by Locke and Descartes before that. To do that one must be in
the possession of insights and distinctions with which these modern thinkers
were unacquainted. Why they were, I will try to explain presently.
What I have just said about Kant in
relation to Hume applies also to the whole tradition of British empirical
philosophy from Hobbes, Locke, and Hume on. All of the philosophical
puzzlements, paradoxes, and pseudo-problems that linguistic and analytical
philosophy and therapeutic positivism in our own century have tried to
eliminate would never have arisen in the first place if the little errors in
the beginning made by Locke and Hume had been explicitly rejected instead of
going unnoticed.
How did those little errors in the
beginning arise in the first place? One answer is that something which
needed to be known or understood had not yet been discovered or learned.
Such mistakes are excusable, however regrettable they may be.
The second answer is that the errors are
made as a result of culpable ignorance — ignorance of an essential point, an
indispensable insight or distinction, that has already been discovered and
expounded.
It is mainly in the second way that modern
philosophers have made their little errors in the beginning. They are ugly
monuments to the failures of education — failures due, on the one hand, to
corruptions in the tradition of learning and, on the other hand, to an
antagonistic attitude toward or even contempt for the past, for the
achievements of those who have come before.
Ten years ago, in 1974-1975, I wrote my
autobiography, and intellectual biography entitled Philosopher at Large. As
I now reread its concluding chapter, I can see the substance of this work
emerging from what I wrote there.
I frankly confessed my commitment to
Aristotle’s philosophical wisdom, both speculative and practical, and to
that of his great disciple Thomas Aquinas. The essential insights and the
indispensable distinctions needed to correct the philosophical mistakes made
in modern times are to be found in their thought.
Some things said in the concluding chapter
of that book bear repetition here in this work. Since I cannot improve upon
what I wrote ten years ago, I shall excerpt and paraphrase what I said then.
In the eyes of my contemporaries the label
“Aristotelian” has dyslogistic connotations. It has had such connotations
since the beginning of modern times. To call a man an Aristotelian carries
with it highly derogatory implications. It suggests that his is a closed
mind, in such slavish subjection to the thought of one philosopher as to be
impervious to the insights or arguments of others.
However, it is certainly possible to be an
Aristotelian — or the devoted disciple of some other philosopher — without
also being a blind and slavish adherent of his views, declaring with
misplaced piety that he is right in everything he says, never in error, or
that he has cornered the market on truth and is in no respect deficient or
defective. Such a declaration would be so preposterous that only a fool
would affirm it. Foolish Aristotelians there must have been among the
decadent scholastics who taught philosophy in the universities of the
sixteenth and seventeenth centuries. They probably account for the vehemence
of the reaction against Aristotle, as well as the flagrant misapprehension
or ignorance of his thought, that is to be found in Thomas Hobbes and
Francis Bacon, in Descartes, Spinoza, and Leibniz.
The folly is not the peculiar affliction
of Aristotelians. Cases of it can certainly be found, in the last century,
among those who gladly called themselves Kantians or Hegelians; and in our
own day, among those who take pride in being disciples of John Dewey or
Ludwig Wittgenstein. But if it is possible to be a follower of one of the
modern thinkers without going to an extreme that is foolish, it is no less
possible to be an Aristotelian who rejects Aristotle’s error and
deficiencies while embracing the truths he is able to teach.
Even granting that it is possible to be an
Aristotelian without being doctrinaire about it, it remains the case that
being an Aristotelian is somehow less respectable in recent centuries and in
our time than being a Kantian or a Hegelian, an existentialist, a
utilitarian, a pragmatist, or some other “ist” or “ian.” I know, for
example, that many of my contemporaries were outraged by my statement that
Aristotle’s Ethics is a unique book in the Western tradition of moral
philosophy, the only ethics that is sound, practical, and undogmatic.
If a similar statement were made by a
disciple of Kant or John Stuart Mill in a book that expounded and defended
the Kantian or utilitarian position in moral philosophy, it would be
received without raised eyebrows or shaking heads. For example, in this
century it has been said again and again, and gone unchallenged, that
Bertrand Russell’s theory of descriptions has been crucially pivotal in the
philosophy of language; but it simply will not do for me to make exactly the
same statement about the Aristotelian and Thomistic theory of signs (adding
that it puts Russell’s theory of descriptions into better perspective than
the current view of it does).
Why is this so? My only answer is that it
must be believed that, because Aristotle and Aquinas did their thinking so
long ago, they cannot reasonable be supposed to have been right in matters
about which those who came later were wrong. Much must have happened in the
realm of philosophical thought during the last three or four hundred years
that requires an open-minded person to abandon their teachings for something
more recent and, therefore, supposedly better.
My response to that view is negative. I
have found faults in the writings of Aristotle and Aquinas, but it has not
been my reading of modern philosophical works that has called my attention
to these faults, nor helped me to correct them. On the contrary, it has been
my understanding of the underlying principles and the formative insights
that govern the thought of Aristotle and Aquinas that has provided the basis
for amending or amplifying their views where they are fallacious or
defective.
I must say one more that in philosophy,
both speculative and practical, few if any advances have been made in modern
times. On the contrary, must has been lost as the result of errors that
might have been avoided if ancient truths had been preserved in the modern
period instead of being ignored.
Modern philosophy, as I see it, got off to
a very bad start — with Hobbes and Locke in England, and with Descartes,
Spinoza, and Leibniz on the Continent. Each of these thinkers acted as if he
had no predecessors worth consulting, as if he were starting with a clean
slate to construct for the first time the whole of philosophical knowledge.
We cannot find in their writings the
slightest evidence of their sharing Aristotle’s insight that no man by
himself is able to attain the truth adequately, although collectively men do
not fail to amass a considerable amount; nor do they ever manifest the
slightest trace of a willingness to call into council the views of their
predecessors in order to profit from whatever is sound in their thought and
to avoid their errors. On the contrary, without anything like a careful,
critical examination of the views of their predecessors, these modern
thinkers issue blanket repudiations of the past as a repository of errors.
The discovery of philosophical truth begins with themselves.
Proceeding, therefore, in ignorance or
misunderstanding of truths that could have been found in the funded
tradition of almost two thousand years of Western though, these modern
philosophers made crucial mistakes in their points of departure and in their
initial postulates. The commission of these errors can be explained in part
by antagonism toward the past, and even contempt for it.
The explanation of the antagonism lies in
the character of the teachers under whom these modern philosophers studied
in their youth. These teachers did not pass on the philosophical tradition
as a living thing by recourse to the writings of the great philosophers of
the past. They did not read and comment on the works of Aristotle, for
example, as the great teachers of the thirteenth century did.
Instead, the decadent scholastics who
occupied teaching posts in the universities of the sixteenth and seventeenth
centuries fossilized the tradition by presenting it in a deadly, dogmatic
fashion, using a jargon that concealed, rather than conveyed, the insights
it contained. Their lectures must have been as wooden and uninspiring as
most textbooks or manuals are; their examinations must have called for a
verbal parroting of the letter of ancient doctrines rather than for an
understanding of their spirit.
It is no wonder that early modern
thinkers, thus mistaught, recoiled. Their repugnance, though certainly
explicable, may not be wholly pardonable, for they could have repaired the
damage by turning to the texts or Aristotle or Aquinas in their mature years
and by reading them perceptively and critically.
That they did not do this can be
ascertained from an examination of their major works and from their
intellectual biographies. When they reject certain points of doctrine
inherited from the past, it is perfectly clear that they do not properly
understand them; in addition, they make mistakes that arise from ignorance
of distinctions and insights highly relevant to problems they attempt to
solve.
With very few exceptions, such
misunderstanding and ignorance of philosophical achievements made prior to
the sixteenth century have been the besetting sin of modern thought. Its
effects are not confined to philosophers of the seventeenth and eighteenth
centuries. They are evident in the work of nineteenth-century philosophers
and in the writings of our day. We can find them, for example, in the works
of Ludwig Wittgenstein, who, for all his native brilliance and philosophical
fervor, stumbles in the dark in dealing with problems on which premodern
predecessors, unknown to him, have thrown great light.
Modern philosophy has never recovered from
its false starts. Like men floundering in quicksand who compound their
difficulties by struggling to extricate themselves, Kant and his successors
have multiplied the difficulties and perplexities of modern philosophy by
the very strenuousness — and even ingenuity — of their efforts to extricate
themselves from the muddle left in their path by Descartes, Locke, and Hume.
To make a fresh start, it is only
necessary to open the great philosophical books of the past (especially
those written by Aristotle and in his tradition) and to read them with the
effort of understanding that they deserve. The recovery of basic truths,
long hidden from view, would eradicate errors that have had such disastrous
consequences in modern times.
"Peer review highly sensitive to poor refereeing, claim researchers,"
Physics World, September 9, 2010 ---
http://physicsworld.com/cws/article/news/43691
Thank you Roger Collins for the heads up.
Daniel Kennefick, a cosmologist at the University
of Arkansas with a special interest in sociology, believes that the study
exposes the vulnerability of peer review when referees are not accountable
for their decisions. "The system provides an opportunity for referees to try
to avoid embarrassment for themselves, which is not the goal at all," he
says.
Kennefick feels that the current system also
encourages scientists to publish findings that may not offer much of an
advance. "Many authors are nowadays determined to achieve publication for
publication's sake, in an effort to secure an academic position and are not
particularly swayed by the argument that it is in their own interests not to
publish an incorrect article."
Continued in article
Jensen Comment
Especially take note of the many and varied comments on this article.
Bob Jensen's threads on the peer review process are as follows:
http://faculty.trinity.edu/rjensen/HigherEdControversies.htm#PeerReview
http://faculty.trinity.edu/rjensen/HigherEdControversies.htm#PeerReviewFlaws
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
When Preconceived Notions Stand in the Way of Academic Scholarship and
Research
I think the article below extends well beyond the realm of traditional politics
and extends into other worlds of academe
"In the Teeth of the Evidence," by Barbara Fister, Inside Higher Ed,
February 22, 2011 ---
http://www.insidehighered.com/blogs/library_babel_fish
So I was intrigued to read
a news story in the Boston Globe about research in political behavior.
It turns out that people who have made up their minds
are not receptive to information that doesn't support their beliefs. I
tracked down some of the research mentioned in the article to see how the
studies were conducted. (I'm nerdy that way.) Essentially, James Kuklinski
and others
found that people who held strong beliefs wouldn't
let facts stand in their way. Those who were the least well informed were
also the group that were the most confident in their mistaken beliefs. (I
use "mistaken" here because they were factually wrong, and those
misperceptions of fact conspired with their opinions about what policies
should be taken.) Brendan Nyhan and Jason Reifler recently
devised several experimental procedures to see how
people respond to corrections in information. Not well, apparently. When
people read false information and then a correction to it, they tend to dig
in their heels and become even more convinced of the wrong information, a
"back fire" effect that increases their insistence on misinformation being
correct.
This is all very depressing. We have enough of a
challenge giving students the knowhow to locate good information. I am
reminded of
James
Elbow's notion of the "believing game." Rather
than teach students the art of taking a text apart and arguing with it, like
a dog worrying a dead squirrel, he thought there was some value in entering
into ideas and doing our best to understand them from the inside rather than
take a defensive position and try to disprove them as a means of
understanding. I am also reminded of
research done by Keith Oatley (and
discussed by him here) that suggests that those
who read fiction engage in a kind of simulation of reality that leads them
to become more empathetic - and more open to experiences that they haven't
had.
Continued in article
A PS to this little paper chase of mine - this
exercise of tracing sources mentioned in a news story convinces me we need
to do a much better job of making research findings accessible in every
sense of the word. When you are engaged in a debate online, the links that
are easily found to support your position tend to come from in the form of
opinion pieces and news stories. So much of our scholarly work is locked up
behind paywalls that even finding research referred to in these opinion and
news sources takes a lot of detective skill and patience, and when you find
them you can't provide links that work. If we want our work to matter, if we
want the evidence we gather to make a difference, we need to think about
making it more accessible, not just in terms of readability, but findabilty.
Kudos to the authors who have made their work open access, and kudos to
those publishers and libraries who help.
Publish Poop or Perish
"We Must Stop the Avalanche of Low-Quality Research," by Mark Bauerlein,
Mohamed Gad-el-Hak, Wayne Grody, Bill McKelvey, and Stanley W. Trimble,
Chronicle of Higher Education, June 13, 2010 ---
http://chronicle.com/article/We-Must-Stop-the-Avalanche-of/65890/
Everybody agrees that scientific research is
indispensable to the nation's health, prosperity, and security. In the many
discussions of the value of research, however, one rarely hears any mention
of how much publication of the results is best. Indeed, for all the regrets
one hears in these hard times of research suffering from financing problems,
we shouldn't forget the fact that the last few decades have seen astounding
growth in the sheer output of research findings and conclusions. Just
consider the raw increase in the number of journals. Using Ulrich's
Periodicals Directory, Michael Mabe shows that the number of "refereed
academic/scholarly" publications grows at a rate of 3.26 percent per year
(i.e., doubles about every 20 years). The main cause: the growth in the
number of researchers.
Many people regard this upsurge as a sign of
health. They emphasize the remarkable discoveries and breakthroughs of
scientific research over the years; they note that in the Times Higher
Education's ranking of research universities around the world, campuses in
the United States fill six of the top 10 spots. More published output means
more discovery, more knowledge, ever-improving enterprise.
If only that were true.
While brilliant and progressive research continues
apace here and there, the amount of redundant, inconsequential, and outright
poor research has swelled in recent decades, filling countless pages in
journals and monographs. Consider this tally from Science two decades ago:
Only 45 percent of the articles published in the 4,500 top scientific
journals were cited within the first five years after publication. In recent
years, the figure seems to have dropped further. In a 2009 article in Online
Information Review, Péter Jacsó found that 40.6 percent of the articles
published in the top science and social-science journals (the figures do not
include the humanities) were cited in the period 2002 to 2006.
As a result, instead of contributing to knowledge
in various disciplines, the increasing number of low-cited publications only
adds to the bulk of words and numbers to be reviewed. Even if read, many
articles that are not cited by anyone would seem to contain little useful
information. The avalanche of ignored research has a profoundly damaging
effect on the enterprise as a whole. Not only does the uncited work itself
require years of field and library or laboratory research. It also requires
colleagues to read it and provide feedback, as well as reviewers to evaluate
it formally for publication. Then, once it is published, it joins the
multitudes of other, related publications that researchers must read and
evaluate for relevance to their own work. Reviewer time and energy
requirements multiply by the year. The impact strikes at the heart of
academe.
Among the primary effects:
Too much publication raises the refereeing load on
leading practitioners—often beyond their capacity to cope. Recognized
figures are besieged by journal and press editors who need authoritative
judgments to take to their editorial boards. Foundations and government
agencies need more and more people to serve on panels to review grant
applications whose cumulative page counts keep rising. Departments need
distinguished figures in a field to evaluate candidates for promotion whose
research files have likewise swelled.
The productivity climate raises the demand on
younger researchers. Once one graduate student in the sciences publishes
three first-author papers before filing a dissertation, the bar rises for
all the other graduate students.
The pace of publication accelerates, encouraging
projects that don't require extensive, time-consuming inquiry and evidence
gathering. For example, instead of efficiently combining multiple results
into one paper, professors often put all their students' names on multiple
papers, each of which contains part of the findings of just one of the
students. One famous physicist has some 450 articles using such a strategy.
In addition, as more and more journals are
initiated, especially the many new "international" journals created to serve
the rapidly increasing number of English-language articles produced by
academics in China, India, and Eastern Europe, libraries struggle to pay the
notoriously high subscription costs. The financial strain has reached a
critical point. From 1978 to 2001, libraries at the University of California
at Los Angeles, for example, saw their subscription costs alone climb by
1,300 percent.
The amount of material one must read to conduct a
reasonable review of a topic keeps growing. Younger scholars can't ignore
any of it—they never know when a reviewer or an interviewer might have
written something disregarded—and so they waste precious months reviewing a
pool of articles that may lead nowhere.
Finally, the output of hard copy, not only print
journals but also articles in electronic format downloaded and printed,
requires enormous amounts of paper, energy, and space to produce, transport,
handle, and store—an environmentally irresponsible practice.
Let us go on.
Experts asked to evaluate manuscripts, results, and
promotion files give them less-careful scrutiny or pass the burden along to
other, less-competent peers. We all know busy professors who ask Ph.D.
students to do their reviewing for them. Questionable work finds its way
more easily through the review process and enters into the domain of
knowledge. Because of the accelerated pace, the impression spreads that
anything more than a few years old is obsolete. Older literature isn't
properly appreciated, or is needlessly rehashed in a newer, publishable
version. Aspiring researchers are turned into publish-or-perish
entrepreneurs, often becoming more or less cynical about the higher ideals
of the pursuit of knowledge. They fashion pathways to speedier publication,
cutting corners on methodology and turning to politicking and fawning
strategies for acceptance.
Such outcomes run squarely against the goals of
scientific inquiry. The surest guarantee of integrity, peer review, falls
under a debilitating crush of findings, for peer review can handle only so
much material without breaking down. More isn't better. At some point,
quality gives way to quantity.
Academic publication has passed that point in most,
if not all, disciplines—in some fields by a long shot. For example, Physica
A publishes some 3,000 pages each year. Why? Senior physics professors have
well-financed labs with five to 10 Ph.D.-student researchers. Since the
latter increasingly need more publications to compete for academic jobs, the
number of published pages keeps climbing. While publication rates are going
up throughout academe, with unfortunate consequences, the productivity
mandate hits especially hard in the sciences.
Only if the system of rewards is changed will the
avalanche stop. We need policy makers and grant makers to focus not on money
for current levels of publication, but rather on finding ways to increase
high-quality work and curtail publication of low-quality work. If only some
forward-looking university administrators initiated changes in hiring and
promotion criteria and ordered their libraries to stop paying for low-cited
journals, they would perform a national service. We need to get rid of
administrators who reward faculty members on printed pages and downloads
alone, deans and provosts "who can't read but can count," as the saying
goes. Most of all, we need to understand that there is such a thing as
overpublication, and that pushing thousands of researchers to issue
mediocre, forgettable arguments and findings is a terrible misuse of human,
as well as fiscal, capital.
Several fixes come to mind:
First, limit the number of papers to the best
three, four, or five that a job or promotion candidate can submit. That
would encourage more comprehensive and focused publishing.
Second, make more use of citation and journal
"impact factors," from Thomson ISI. The scores measure the citation
visibility of established journals and of researchers who publish in them.
By that index, Nature and Science score about 30. Most major disciplinary
journals, though, score 1 to 2, the vast majority score below 1, and some
are hardly visible at all. If we add those scores to a researcher's
publication record, the publications on a CV might look considerably
different than a mere list does.
Third, change the length of papers published in
print: Limit manuscripts to five to six journal-length pages, as Nature and
Science do, and put a longer version up on a journal's Web site. The two
versions would work as a package. That approach could be enhanced if
university and other research libraries formed buying consortia, which would
pressure publishers of journals more quickly and aggressively to pursue this
third route. Some are already beginning to do so, but a nationally
coordinated effort is needed.
Continued in article
June 17. 2010 message from Bob Jensen
Hi David,
In answer to your question, David, I think that
concerns over media rankings of their colleges have led university
administrators and faculties to be more concerned about research rankings of
their institutions. This has exacerbated the already high premium placed
upon publishing in research journals. That, in turn, has led to more
research journals of dubious quality.
Even worse is the pressure to get articles published
quickly and regularly in a staccato beat of a metronome.
And there are other strategies that dilute quality ---
http://faculty.trinity.edu/rjensen/TheoryTenure.htm
What we no longer appreciate is superb scholarship
regarding knowledge that is already known and available for deep study.
Instead we treasure new knowledge that, due to time management, often leads
to shallow scholarship or scholarship that is very, very narrow.
And I think that we prize frequency of research
publication for promotion and tenure because we do not have the guts to
evaluate scholarship internally (by friends and colleagues). Instead we take
the easy way out with point systems like Linda Kidwell discusses at
http://faculty.trinity.edu/rjensen/TheoryTenure.htm
I greatly admired Linda’s candid reply, and given the
name of the “game” today, I think her university has devised a clever and
relatively fair system that warns new faculty how to earn tenure “points.”
My complaint, however, is that an outstanding scholar (with no publication
points) is thrown under the bus.
And even among our tenured faculty we encourage them to
send out uninteresting surveys or silly regressions rather than dig deep
into library study (including the online world libraries). The best sign to
me of poor scholarship is how little our published researchers know about
history. A practitioner named Robert Bruce Walker in New Zealand is far more
curious about the past than most of the so-called researchers pumping out
their next submissions to our journals.
A College President Changes the Tenure Rules of the
Road
at
http://faculty.trinity.edu/rjensen/TheoryTenure.htm
In the above context I received the following (slightly
edited) disturbing message from a good friend at a college that has a very
small accounting education program (less than 25 masters program graduates
in accounting annually). The college is not in the Top 50 business schools
as ranked by US News or Business Week or the WSJ. Nor
does the program have a doctoral program and is not even mentioned as having
a an accounting research program ---
http://papers.ssrn.com/sol3/papers.cfm?abstract_id=1337755
The message reads as follows (slightly edited):
Bob,
Our College's President just contacted our non-tenured accounting faculty.
He gave them a short list of “Accountics” journals that they have to publish
in order to get tenure. The list consists of the usual (A-Level) suspects –
JAR, TAR, JAE, AOS, JATA, CAR, Auditing – A Journal of Practice and
Theory, and a handful more. He categorically told them that they
need to have at least 4 articles in those journals to be successful in
getting tenure.
Just thought you should know!
I hope you and Erika are doing well. I always look forward to you Tidbits
and photos that accompany them. Of course, I also follow you on the AECM
listserve.
Best Regards
XXXXX
Bob Jensen
Even back in the old days (1970s and
1980s), publishing one article per year in an A-level or B-Level accounting
research journal for more than five years running would’ve made you the leading
accounting researcher of the world. Even Joel Demski in his prime could not keep
up that pace year in and year out. The typical pattern, apart from a few Demski
types, is for a researcher to fade out quickly after obtaining tenure or
promotion to full professor.
There are both A-Level and B-Level journals
in the following studies:
"An Analysis of Contributors to Accounting Journals Part II: The
Individual Academic Journals," by Louis Heck, Philip L. Cooley, and
Bob Jensen, The International Journal of Accounting, Vol.26, 1991,
pp. 1-17.
"An Analysis of Contributors to Accounting Journals. Part I: The
Aggregate Performances," by Louis Heck, Philip L. Cooley, and Bob Jensen,
The International Journal of Accounting, Vol.25, 1990, pp. 202-217.
Released in 1991.
"Why Most Published Research Findings Are False," by
John P. A. Ioannidis, PLoS Medicine, August 30, 2005 ---
http://www.plosmedicine.org/article/info:doi/10.1371/journal.pmed.0020124
Thanks for the heads up John P. Wendell
And those that have a brief
blast for several years running generally burn out in terms of pace of
publication in A-Level accounting research journals ---
AN ANALYSIS OF THE EVOLUTION OF RESEARCH
CONTRIBUTIONS BY THE ACCOUNTING REVIEW: 1926-2005 (Accounting Historians
Journal)---
http://faculty.trinity.edu/rjensen/395wpTAR/Web/TAR395wp.htm#_msocom_1
Also see
http://www.johnson.cornell.edu/news/Prolificauthors.html
For those of you
who want to examine the publishing frequencies of our leading accounting
researchers in the Academy, Jean Heck maintains an outstanding database of
publishing history in accounting, finance, economics and business.
Jean will inform you of how to gain access to this outstanding and meticulous
piece of work ---
jheck@sju.edu
It would be
interesting for somebody to update the above Heck, Cooley, and Jensen accounting
journal studies using Jean Heck’s current database.
Bob Jensen
June 17, 2010 reply from Alexander Robin A
[alexande.robi@UWLAX.EDU]
This all, and a number of other threads, I find
quite depressing. I entered academia under the false notion that academics
were in the field because they liked it and they did research because it
interested them. Being stubbornly idealistic it took me some years to
realize that, at least in business schools, published paper were the product
that most faculty are interested in and I encountered a number of very
successful (in terms defined for tenure and promotion) actually cared little
for the advancement of scholarship and viewed the publishing game as just
that - a game where the goal was tenure and promotion.
My background may have contributed to my illusion.
I spent quite a few years as a student at UW - Madison's math department
where the faculty were very interested in their work and animated discussion
on math and other subjects took place in the math lounge and nearby taverns.
Now UW's math department was huge (80 or so faculty and over 200 graduate
students) and at the time was rated in the top 10 in the nation. Entering
business schools as doctoral student and then faculty was a culture shock.
The general lack of interest in the "deep" questions and extreme interest in
publishing was an anathema to me and I did not do particularly well in that
environment. But I am a slow learner and it took me many years before I
finally just quit.
The problem with counting publications and
factoring in student evaluations is the same with any measure: the measure
becomes more important than the more fundamental goal of knowledge and
imparting learning. I find that most still don't get the connection with
this and the frustration that most of us had at students who were more
interested in their grade than in what they were learning. The students'
preoccupation with grades is similar with faculty preoccupation with number
of published papers. As long as the measure is treated with more importance
than that which they attempt to measure I believe that the results will be
the same: mediocre research and mediocre learning on the part of students.
There is no easy solution to this conundrum that I
can see. Some way will have to be found to really encourage learning on the
part of the students and meaningful academic work on the part of faculty.
Extrinsic motivation (grades, number of published papers) will never be
effective in my opinion. We need to tap into people's intrinsic curiosity
and desire to learn. I believe it's there but academia very effectively
crushes it in many cases. I was lucky. I was floundering as an undergraduate
until a wonderful soul inspired me to really delve into mathematics and then
I was able to appreciate its beauty and was internally motivated to study
it. The grades followed as a secondary outcome as I went from a C to an A
average. Had I continued to worry about grades primarily, I'm sure that
would not have happened.
Robin Alexander
Do financial incentives improve manuscript quality and manuscript reviews?
December 12, 2011 message from Dan Stone
There seems to be a "natural experiment" in
progress at accounting journals. Two "top" journals (JAE, JAR) have
substantial fees for submission, a portion of which is paid to reviewers.
Many other journals have low or no submission fee (e.g., AOS = $0).
Research questions:
1. Do submission fees improve the quality of
manuscript submissions?
Theory - Ho yes: because authors with more
financial resources produce better work. Ho no: because submission fees are,
in relation to accounting professor salaries, still trivial.
2. Do submission fees improve the quality of
manuscript reviews?
Theory - Ho yes: because $ increases effort and the
quality of reviews is primarily a function of reviewer effort.
Ho no: because financial motivation is of "low
quality" (according to self-determination theory) and reviews require
insight and creativity. Money doesn't buy insight or creativity, it only
buys effort.
Dan's remaining questions: 1. any existing papers
on this topic? (here's a paper that argues that financial incentives will
decrease cases of reviewer's declining to review, which could improve
reviewer quality (http://jech.bmj.com/content/61/1/9.full) 2. if not, any
volunteers to get this data and run this study? :)
Thanks,
Dan Stone
December 13, 2011 reply from Zane Swanson
Consider a control variable(s):
What is the key metric(s) in an
acceptable quality review?
The reason for the
aforementioned is that some informal convention discussions have occurred
that editors preselect the acceptance by who becomes a reviewer.
Alternatively, some reviewers may reject about everything. If an editor
does not want a paper (too far off the current “research frontier”?), then
the editor selects a reviewer who will just say no.
Stone wrote:
There seems to be a "natural
experiment" in progress at accounting journals. Two "top" journals (JAE,
JAR) have substantial fees for submission, a portion of which is paid to
reviewers. Many other journals have low or no submission fee (e.g., AOS =
$0).
Research questions:
1. Do submission fees improve the
quality of manuscript submissions?
Theory -
Ho yes: because authors with more
financial resources produce better work.
Ho no: because submission fees
are, in relation to accounting professor salaries, still trivial.
2. Do submission fees improve the
quality of manuscript reviews?
Theory -
Ho yes: because $ increases
effort and the quality of reviews is primarily a function of reviewer
effort.
Ho no: because financial
motivation is of "low quality" (according to self-determination theory) and
reviews require insight and creativity.
Money doesn't buy insight or
creativity, it only buys effort.
Dan's remaining questions:
1. any existing papers on this
topic? (here's a paper that argues that financial incentives will decrease
cases of reviewer's declining to review, which could improve reviewer
quality
(http://jech.bmj.com/content/61/1/9.full)
2. if not, any volunteers to get
this data and run this study? :)
Zane Swanson
December 12, 2011 reply from Bob Jensen
Since many of the TAR, JAR, and JAE top referees are used by all three
journals, it seems unlikely that variations in remuneration for the
refereeing is going to affect the quality of the reviews. What remuneration
might affect in a particular instance is a referee's acceptance of taking on
the refereeing assignment in the first place. This might be something some
referees (certainly not all) will admit to in interviews and surveys.
Regarding the question of whether journal editors predetermine refereeing
outcomes of some manuscripts, by choice of referees, probably can only be
answered by journal editors, but they're not likely to admit to such
unethical game playing.
Certainly with respect to submissions using advanced mathematics in what are
classified as analytical submissions, there are referees who are known to
be much tougher about the realism of the foundational assumptions. Some
referees don't get hung up on assumptions and are more interested in the
quality of the mathematical derivations. Other referees are likely to be
more critical of the lack of realism in the assumptions and/or questions
about whether the resulting outcomes are truly relevant to accounting. My
suspicion is that TAR, JAR, and JAE editors are going to shy away from the
latter referees unless they themselves don't don't think in advance that the
paper should have much of a shot. But that is an unproven suspicion.
With respect to "quality of a review," much depends upon the what
constitutes "quality." To me the highest quality review demonstrates that
the referee knows as much or more about the manuscript content and research
as the authors themselves.
A high quality rejection in one sense is a rejection that lists reasons so
convincing that even the authors agree that the paper should've been
rejected. I've had some memorable rejections in this category. You won't
find them at my Website.
A low quality rejection in a sense is a terse one word "reject" or an
editor's terse note that "this piece of garbage is not worth sending to our
referees." One of the best-known editors of JAR was known for the latter
type of rejection in those words. What such rejection feedback fails to tell
us is how much time time and effort the referee/editor really put in
studying the manuscript before writing a terse and useless reply to the
authors.
A high quality acceptance or re-submit outcome is one that lists tremendous
ideas for improving the manuscript before final publication or resubmission.
It's nice if a referee really suggests helpful ways to improve the way the
paper is written (apart from content), but we should not expect referees to
rewrite papers and it's unfair to downgrade a reviewer for not doing so.
But referees can get carried away to a fault in suggesting ways to improve a
paper. I was one of two referees of a submission published a short time ago
by IAE. We both had resubmit suggestions, but mine were quite modest. The
other referee submitted about 10 pages of "conditions" that if taken
literally would've increased the size of the paper to over 200 pages and
required that the authors completely re-run the field study with more
questions to be asked in the field. As we sometimes say about some referee
reports, "the road to hell is paved with good intentions."
Fortunately the referee who really got carried away with "conditions" did
not insist upon meeting most of the original conditions after the authors
resubmitted the paper three times.
Also it was fortunate that the authors did not simply throw up their hands
in utter discouragement over all that the referee wanted in his/her first
review.
When Steve Zeff was editor of TAR, I was given the task of adjudicating
conflicting referee recommendations. I had the feeling that the adjudication
cases Steve sent to me were those where he wanted to publish the manuscripts
but needed some additional backup for his decisions. Or put another way, he
really wanted to publish some manuscripts that did not contain the requisite
equations demanded by nearly all TAR referees.
Of course when doing research on the refereeing process, it's risky to
survey authors themselves. Most of us have had referees we thought were
idiots and are likely to say so in surveys. We could easily be wrong of
course. In my case the my three "big ones" that were flatly turned down are
linked at
http://www.trinity.edu/rjensen/default4.htm
Please keep the dates of my three "big ones" in mind if you take the time
and trouble to examine my big ones that got away. Also my secretary
translated my original doc files into html files (before the MS word would
do such conversions automatically). Hence the tables and exhibits and some
other sections of the papers were degraded badly.
Only one of the papers was submitted to an accounting research journal.
Actually it was rejected by both TAR and JAR even after I took on co-authors
to improve the paper. That was Working Paper 153.
Respectfully,
Bob Jensen
December 13, 2011 reply from Bob Jensen
Bob,
That was a breath of fresh air on a touchy academic subject. There is an
endless supply of material in guides to writing and examples of award
winning publications, but little about reviewing. I do suggest that your
post is a keeper on your web site.
Regards,
Zane
Illustration of Replication Research Efforts
IS AFFIRMATIVE ACTION RESPONSIBLE FOR THE ACHIEVEMENT GAP BETWEEN BLACK
AND WHITE LAW STUDENTS?
Northwestern University School of Law
2007
This was called to my attention by Paul Caron on December 26, 2011 who then
links to some "updates"
The current issue of the Northwestern
University Law Review contains a remarkable "clarification" regarding
Katherine Y. Barnes (Arizona),
Is Affirmative Action Responsible for the Achievement Gap Between Black and
White Law Students, 101 Nw. U. L. Rev. 1759 (2007), which disputed the
"mismatch" theory proposed by Richard H. Sander (UCLA) in A
Systemic Analysis of Affirmative Action in American Law Schools, 57
Stan. L. Rev. 367 (2004):
Katherine Barnes concludes the following:
The revised results present a different picture of
student outcomes. The data do not support either the antimismatch effect or
the mismatch hypothesis: mismatched students do not explain the racial gap
in student outcomes. The weakest students do not have systematically
different outcomes at HBS, low-range schools, or mid-range schools. Black
students have lower bar passage rates at HBS schools than at other
institutions. Thus, the results suggest that there remain other factors,
which I term race-based barriers, that adversely affect minority law student
performance. Professors Williams, Sander, Luppino, and Bolus write that my
conclusions are “exactly opposite” to the conclusions in my 2007 essay,
suggesting that my revised results support mismatch.36 This is incorrect.
Their first argument is that ending affirmative action would increase the
percentage of black law students who pass the bar by 27%.This is irrelevant
to mismatch. Their second argument is that I have miscoded bar passage in
this Revision.38 I fixed this coding but was not permitted to publish it
here.
Doug Williams, Richard Sander, Marc Luppino and Roger Bolus conclude the
following:
In the conclusion of her original essay, Barnes
stated: “Although I am cautious about drawing conclusions from the results
due to significant data limitations, the results suggest that mismatch does
not occur. Instead, the data suggest that reverse mismatch—lower
credentialed students learn more when challenged by classmates who outmatch
them—may be occurring.” As we have shown,
this conclusion cannot be supported by either our replication or Barnes’s
revision. To the extent that her model
tells us anything about the issues at hand, it is exactly opposite to the
conclusions of her original essay. Low-credential students have better, not
worse, outcomes at schools where their credentials are closer to their
peers; white students are affected by mismatch as much as black students;
and Barnes’s corrected simulation suggests that, in the absence of any
affirmative action, the number of black and Hispanic lawyers would not
change whereas the number of unsuccessful minority students would drop
precipitously.
Bob Jensen's threads on replication research are at
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
Bob Jensen's threads on affirmative action in academe are at
http://faculty.trinity.edu/rjensen/HigherEdControversies.htm#AffirmativeAction
"Case Study Research in Accounting," by David J. Cooper and Wayne
Morgan, Accounting Horizons 22 (2), 159 (2008) ---
http://link.aip.org/link/ACHXXX/v22/i2/p159/s1
SYNOPSIS: We describe case study research and
explain its value for developing theory and informing practice. While
recognizing the complementary nature of many research methods, we stress the
benefits of case studies for understanding situations of uncertainty,
instability, uniqueness, and value conflict. We introduce the concept of
phronesis—the analysis of what actions are practical and rational in a
specific context—and indicate the value of case studies for developing, and
reflecting on, professional knowledge. Examples of case study research in
managerial accounting, auditing, and financial accounting illustrate the
strengths of case studies for theory development and their potential for
generating new knowledge. We conclude by disputing common misconceptions
about case study research and suggesting how barriers to case study research
may be overcome, which we believe is an important step in making accounting
research more relevant. ©2008 American Accounting Association
References citing The Accounting Review (3 references out of 89)
---
http://aaapubs.aip.org/getabs/servlet/GetabsServlet?prog=normal&id=ACHXXX000022000002000159000001&idtype=cvips&gifs=yes
Case
Chow, C. W. 1983. The impacts of accounting
regulation on bondholder and shareholder wealth: The case of the securities
acts. The Accounting Review 58 (3): 485–520.
Critical Comments About Accountics Science Dominance of Accounting
Research (not a case)
Hopwood, A. G. 2007. Whither accounting
research?
The Accounting Review 82 (5): 1365–1374.
Field Study
Merchant, K., and J-F. Manzoni. 1989. The
achievability of budget targets in profit centers: A field study. The
Accounting Review 64 (3): 539–558.
Jensen Comment
Firstly, I think this article is living proof of how slow the process can be in
accounting research between the submission of an article and its eventual
publication:
Submitted January 2005; accepted January 2008; published 12 June 2008
Of course delays can be caused by the authors as well as the referees.
Secondly, the above article demonstrates that case researchers must be very
discouraged about submitting case research to The Accounting Review
(TAR). The 89 references to the Cooper and Morgan article are mostly to
published accounting cases and occasional field studies. From TAR they cite only
one 1983 case and one 1989 field study. There have been some cases and field
studies published in TAR since the Cooper and Morgan paper was published by
Accounting Horizons in 2008. The following outcomes are reported by TAR
Senior Editor Steve Kachelmeier 2009-2010:
2009: Seven cases and field studies were submitted to TAR and Zero were
published by TAR
2010: Steve stopped reporting on cases and field study submissions, but he did
report that 95% accepted submissions were analytical, empirical-archival, and
experimental. The other 5% are called "Other" and presumably include accounting
history, normative, editorial, death tributes, cases, field studies, and
everything else.
I think it is safe to conclude that there's epsilon incentive for case
researchers to submit their cases for publication in TAR, a sentiment that seems
to run throughout Bob Kaplan's 2010 Presidential Address to the AAA membership:
Accounting Scholarship that Advances Professional Knowledge and Practice
Robert
S. Kaplan
The Accounting Review 86 (2), 367 (2011) Full Text: [ PDF (166
kB) ] Order
Document
In October 2011 correspondence on the AECM, Steve Kachelmeier wrote the
following in response to Bob Jensen's contention that case method research is
virtually not acceptable to this generation of TAR referees:
A "recent TAR editor's" reply:
Ah, here we go again -- inferring what a journal
will publish from its table of contents. Please understand that this is
inferring a ratio by looking at the numerator. One would hope that academics
would be sensitive to base rates, but c'est la vie.
To be sure, The Accounting Review receives (and
publishes) very few studies in the "case and field research" category. Such
researchers may well sense that TAR is not the most suitable home for their
work and hence do not submit to TAR, despite my efforts to signal otherwise
by appointing Shannon Anderson as a coeditor and current Senior Editor Harry
Evans' similar efforts in appointing Ken Merchant as a coeditor. Moreover,
we send all such submissions to case and field based experts as reviewers.
So if they get rejected, it is because those who do that style of research
recommend rejection.
That said, to state that "the few cases that are
submitted to TAR tend to be rejected" is just plain erroneous. Our Annual
Report data consistently show that TAR's percentage of field and case-based
research acceptances (relative to total acceptances) consistently exceeds
TAR's percentage of field and case submissions (relative to total
submissions). To find a recent example, I grabbed the latest issue
(September 2011) and noted the case study on multiperiod outsourcing
arrangements by Phua, Abernethy, and Lillis. They conduct and report the
results of "semi-structured interviews across multiple field sites" (quoted
from their abstract). Insofar as they also report some quantitative data
from these same field sites, you might quibble with whether this is a "pure"
study in this genre, but the authors themselves characterize their work as
adopting "the multiple case study method" (p. 1802).
Does Phua et al. (2011) qualify? My guess is that
Bob would probably answer that question with some reference to replications,
as that seems to be his common refrain when all else fails, but I would hope
for a more substantive consideration of TAR's supposed bias. Now that I
think about it, though my reference to replications was sarcastic (couldn't
help myself), it just struck me that site-specific case studies are perhaps
the least replicable form of resaerch in terms of the "exacting" replication
that Bob Jensen demands of other forms of scientific inquiry. What gives?
Another interesting case/field study is coming up
in the November 2011 issue. It is by Campbell, Epstein, and Martinez-Jerez,
and it uses case- based resaerch techniques to explore the tradeoffs between
monitoring and employee discretion in a Las Vegas casino that agreed to
cooperate with the researchers. Stay tuned.
Best,
Steve
Firstly, I could not find evidence to support Steve's claim that " field and
case-based research acceptances (relative to total acceptances) consistently
exceeds TAR's percentage of field and case submissions (relative to total
submissions). " Perhaps he can enlighten us on this claim.
The Phua et al. (2011) paper says that it is a "multiple case study," but I
view it as an survey study of Australian companies. I would probably call it
more of a field survey using interviews. More importantly, what the authors call
"cases" do not meet what I consider cases method research cases. No "case" is
analyzed in depth beyond questions about internal controls leading to the
switching of suppliers. The fact that that statistical inferences could not be
drawn does not turn a study automatically into a case research study. For more
details about what constitutes case method research and teaching go to
http://faculty.trinity.edu/rjensen/000aaa/thetools.htm#Cases
As to replications, I'm referring to accountics science studies of the
empirical-archival and experimental variety where the general inference that
these are "scientific studies." There are very few accountics science research
studies are replicated according to The IAPUC Gold Book standards.
Presumably a successful replication "reproduces" exactly the same outcomes
and authenticates/verifies the original research. In scientific research, such
authentication is considered extremely important. The IAPUC Gold Book
makes a distinction between reproducibility and repeatability at
http://www.iupac.org/goldbook/R05305.pdf
For purposes of this message, replication, reproducibility, and repeatability
will be viewed as synonyms.
This message does not make an allowance for "conceptual replications" apart
from "exact replications," although such refinements should be duly noted ---
http://www.jasnh.com/pdf/Vol6-No2.pdf
This message does have a very long quotation from a study by Watson et al.
(2008) that does elaborate on quasi-replication and partial-replication. That
quotation also elaborates on concepts of
external versus
internal validity grounded in the book:
Cook, T. D., & Campbell, D. T. (1979).
Quasi-experimentation: Design & analysis
issues for field settings. Boston:
Houghton Mifflin Company.
I define an "extended study" as one which may have similar hypotheses but
uses non-similar data sets and/or non-similar models. For example, study of
female in place of male test subjects is an extended study with different data
sets. An extended study may vary the variables under investigation or change the
testing model structure such as changing to a logit model as an extension of a
more traditional regression model.
Extended studies that create knew knowledge are not replications in terms of
the above definitions, although an extended study my start with an exact
replication.
Case and Field Studies
Replication is not a major issue in studies that do not claim to be scientific.
This includes case studies that are generally a sample of one that can hardly be
deemed scientific.
ROBERT S. KAPLAN and DAVID P. NORTON , The Execution Premium: Linking
Strategyto Operations for Competitive Advantage �Boston, MA: Harvard Business
Press, 2008,ISBN 13: 978-1-4221-2116-0, pp. xiii, 320.
If you are an academician who believes in empirical
data and rigorous statistical analysis, you will find very little of it in
this book. Most of the data in this book comes from Harvard Business School
teaching cases or from the consulting practice of Kaplan and Norton. From an
empirical perspective, the flaws in the data are obvious. The sample is
nonscientific; it comes mostly from opportunistic interventions. It is a bit
paradoxical that a book which is selling a rational-scientific methodology
for strategy development and execution uses cases as opposed to a matched or
paired sample methodology to show that the group with tight linkage between
strategy execution and operational improvement has better results than one
that does not. Even the data for firms that have performed well with a
balanced scorecard and other mechanisms for sound strategy execution must be
taken with a grain of salt.
Bob Jensen has a knee jerk, broken record reaction to accountics scientists
who praise their own "empirical data and rigorous statistical analysis." My
reaction to them is to show me the validation/replication of their "empirical
data and rigorous statistical analysis." that is replete with missing variables
and assumptions of stationarity and equilibrium conditions that are often
dubious at best. Most of their work is so uninteresting that even they don't
bother to validate/replicate each others' research ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
In fairness to Steve and previous TAR editors over the past three decades, I
think it is not usually the editors themselves that are rejecting the case
submissions. Instead we've created a generation of "accountics scientist"
referees who just do not view case method research as legitimate research for
TAR. These referees fail to recognize that the purpose of case method research
is more one of discovery than hypothesis testing.
The following is a quote from the 1993 American Accounting
Association President’s Message by Gary Sundem,
Although empirical
scientific method has made many positive contributions to accounting
research, it is not the method that is likely to generate new theories,
though it will be useful in testing them. For example, Einstein’s theories
were not developed empirically, but they relied on understanding the
empirical evidence and they were tested empirically. Both the development
and testing of theories should be recognized as acceptable accounting
research.
"President’s Message," Accounting Education News 21 (3). Page 3.
Case method research is one of the non-scientific research methods intended
for discovery of new theories. Years ago case method research was published in
TAR, but any cases appearing in the past 30 years are mere tokens that slipped
through the refereeing cracks.
My bigger concern is that accountics scientists (including most TAR referees)
are simply ignoring their scholarly critics like Joni Young, Greg Waymire,
Anthony Hopwood, Bob Kaplan, Steve Zeff, Mike Granof, Al Arens,
Bob Anthony, Paul Williams, Tony Tinker, Dan Stone, Bob Jensen, and probably
hundreds of other accounting professors and students who agree with the claim
that "There's an absence of dissent in the publication of TAR articles?"
We
fervently hope that the research pendulum will soon swing back from the narrow
lines of inquiry that dominate today's leading journals to a rediscovery of the
richness of what accounting research can be.
For that to occur, deans and the current generation of academic accountants must
give it a push.
"Research
on Accounting Should Learn From the Past"
by Michael H. Granof and Stephen A. Zeff
Chronicle of Higher Education, March 21, 2008
I will not attribute the above conclusion to Mike Granof since Steve Kachelmeier
contends this is not really the sentiment of his colleague Mike Granof. Thus we
must assume that the above conclusion to the above publication is only the
sentiment of coauthor Steve Zeff.
October 17. 2011 reply
from Steve Kachelmeier
Bob said that TAR stopped reporting case and field
study data in 2010, but that is not accurate. For 2010, please see Table 3,
Panel B of TAR's Annual Report, on p. 2183 of the November 2010 issue. The
2011 Report to be published in the November 2011 issue (stay tuned) also
reports comprehensive data for the three-year period from June 1, 2008 to
May 31, 2011. Over this period, TAR evaluated 16 unique files that I
categorized as "case or field studies," comprising 1.0% of the 1,631 unique
files we considered over this period. TAR published (or accepted for future
publication) 5 of the 16. As a percentage of the 222 total acceptances over
this period, 5 case/field studies comprise 2.3% of the accepted articles. So
this variety of research comprises 1.0% of our submissions and 2.3% of our
acceptances. The five acceptances over my editorial term are as follows:
Hunton and Gold, May 2010 (a field experiment)
Bol, Keune, Matsumura, and Shin, November 2010
Huelsbeck, Merchant, and Sandino, September 2011
Phua, Abernethy, and Lillis, September 2011
Campbell, Epstein, and Martinez-Jerez, forthcoming November 2011
I categorized these five as case/field studies
because they are each characterized by in-depth analysis of particular
entities, including interviews and inductive analysis. Bob will likely
counter (correctly) that these numbers are very small, consistent with his
assertion that many field and case researchers likely do not view TAR as a
viable research outlet. However, my coeditor Shannon Anderson's name (an
accomplished field researcher) has been on the inside cover of each issue
over the course of my editorial term, and current Senior Editor Harry Evans
has similarly appointed Ken Merchant as a coeditor. I am not sure how much
more explicit one can be in providing a signal of openness, save for
commissioning studies that bypass the regular review process, which I do not
believe is appropriate. That is, a "fair game" across all submissions does
not imply a free ride for any submission.
I must also reiterate my sense that there is a
double standard in Bob's lament of the lack of case and field studies while
he simultaneously demands "exacting" (not just conceptual) replications of
all other studies. It is a cop out, in my opinion, to observe that case and
field studies are not "scientific" and hence should not be subject to
scientific scrutiny. The field researchers I know, including those of the
qualitative variety, seem very much to think of themselves as scientists. I
have no problem viewing case and field research as science. What I have a
problem with is insisting on exact replications for some kinds of studies
but tolerating the absence of replicability for others.
Best,
Steve
October 18, 2011 reply from Bob Jensen
Thank you Steve,
It appears that in the forthcoming November 2011 where the next TAR
Annual Report written by you will appear there will be marked improvement in
publishing five case and field studies relative to the virtual zero
published in recent decades. Thanks for this in the spirit of the Granof and
Zeff appeal:
We fervently hope that the research pendulum will soon
swing back from the narrow lines of inquiry that dominate today's
leading journals to a rediscovery of the richness of what accounting
research can be. For that to occur,
deans and the current generation of academic accountants must give it a
push.
Research on
Accounting Should Learn From the Past"
by Michael H. Granof and Stephen A. Zeff
Chronicle of Higher Education, March 21, 2008
Thank you for making TAR "swing back from the narrow lines of inquiry" that
dominated its research publications in the past four decades ---
http://www.trinity.edu/rjensen/395wpTAR/Web/TAR395wp.htm
Leading accounting
professors lamented TAR’s preference for rigor over relevancy [Zeff, 1978;
Lee, 1997; and Williams, 1985 and 2003]. Sundem [1987] provides revealing
information about the changed perceptions of authors, almost entirely from
academe, who submitted manuscripts for review between June 1982 and May
1986. Among the 1,148 submissions, only 39 used archival (history) methods;
34 of those submissions were rejected. Another 34 submissions used survey
methods; 33 of those were rejected. And 100 submissions used traditional
normative (deductive) methods with 85 of those being rejected. Except for a
small set of 28 manuscripts classified as using “other” methods (mainly
descriptive empirical according to Sundem), the remaining larger subset of
submitted manuscripts used methods that Sundem [1987, p. 199] classified
these as follows:
292 General Empirical
172 Behavioral
135 Analytical modeling
119 Capital Market
97 Economic modeling
40 Statistical modeling
29 Simulation
It is clear that by 1982,
accounting researchers realized that having mathematical or statistical
analysis in TAR submissions made accountics virtually a necessary, albeit
not sufficient, condition for acceptance for publication. It became
increasingly difficult for a single editor to have expertise in all of the
above methods. In the late 1960s, editorial decisions on publication shifted
from the TAR editor alone to the TAR editor in conjunction with specialized
referees and eventually associate editors [Flesher, 1991, p. 167]. Fleming
et al. [2000, p. 45] wrote the following:
The big change was in
research methods. Modeling and empirical methods became prominent
during 1966-1985, with analytical modeling and general empirical
methods leading the way. Although used to a surprising extent,
deductive-type methods declined in popularity, especially in the
second half of the 1966-1985 period.
Hi again Steve on October 18, 2011,
As to replication, there's more to my criticisms of accountics science
than replications as defined in the natural and social sciences. I view
the lack of exacting replication as a signal of both lack of interest
and lack of dissent in accountics science harvests relative to the
intense interest and dissent that motivates exacting replications in
real science ---
http://www.trinity.edu/rjensen/TheoryTAR.htm
And there's one piece of evidence
about accountics science that stands out like a beacon of disgrace if
you can call lack of scandal a disgrace. Since reputations,
tenure, and performance evaluations are so dependent in real science
upon research and publication, there is an intense effort to test the
validity of scientific research harvests and relatively frequent
discovery of researcher scandal and/or error. This is a mark of
interest in the harvests of real science.
Over the entire history of accountics science, I cannot think of one
genuine scandal. And discovery of error by independent accountics
scientist is a rare event. Is it just that accountics scientists are
more accurate and more honest than real scientists? Or is it that
accountics science harvests are just not put through the same validity
testing in a timely manner that we find in real science?
Of course I do not expect small sample studies, particularly case
studies, to be put through the same rigorous scientific testing.
Particularly troublesome in case studies is that they are cherry picked
and suffer the same limitations as any anecdotal evidence when it comes
to validity checking.
The purpose of case studies is often limited to education and training,
which is why case writers sometimes even add fiction with some type of
warning that these are fictional or based only loosely on real world
happenings.
The purpose of case studies deemed research (meaning contributing to new
knowledge) is often discovery. The following is a quote from an earlier
1993 President’s Message by Gary Sundem,
Although empirical scientific method
has made many positive contributions to accounting research,
it is not the method that is likely to generate new theories,
though it will be useful in testing them. For example,
Einstein’s theories were not developed empirically, but they
relied on understanding the empirical evidence and they were
tested empirically. Both the development and testing of theories
should be recognized as acceptable accounting research.
"President’s Message," Accounting Education
News 21 (3). Page 3.
TAR, JAR, and JAE need to encourage more
replication and open dissent regarding the findings they publish. I
provide some examples of how to go about this, particularly the
following approach ---
http://www.trinity.edu/rjensen/TheoryTAR.htm#TARversusAMR
TAR currently does not
solicit or publish commentaries and abstracts of replications, although
to do so is not outside its operational guidelines. It is sad that TAR
does not publish such guidelines or give consideration to needs of the
practicing profession.
Happily, the Academy of Management Review has a Dialogue Section
---
http://www.aom.pace.edu/AMR/info.html
Dialogue
Dialogue is a forum for readers who wish to comment briefly on material
recently published in AMR. Readers who wish to submit material
for publication in the Dialogue section should address only AMR
articles or dialogues. Dialogue comments must be timely, typically
submitted within three months of the publication date of the material on
which the dialogue author is commenting. When the dialogue comments
pertain to an article, note, or book review, the author(s) will be asked
to comment as well. Dialogue submissions should not exceed five
double-spaced manuscript pages including references. Also, an Abstract
should not be included in a Dialogue. The Editor will make publishing
decisions regarding them, typically without outside review.
My good friend Jason Xiao
[xiao@Cardiff.ac.uk]
pointed out that the Academy of Management Review (AMR) is a
theory journal and the Academy of Management Journal (AMJ) is the
empirical-article Academy of Management.
He’s correct, and I would like to now
point out a more technical distinction. The Dialogue section of the AMR
invites reader comments challenging validity of assumptions in theory
and, where applicable, the assumptions of an analytics paper. The AMJ
takes a slightly different tack for challenging validity in what is
called an “Editors’ Forum,” examples of which are listed in the index at
http://journals.aomonline.org/amj/amj_index_2007.pdf
One index had some academic vs. practice
Editors' Forum articles that especially caught my eye as it might be
extrapolated to the schism between academic accounting research versus
practitioner needs for applied research:
Bartunek, Jean M. Editors’ forum (AMJ
turns 50! Looking back and looking ahead)—Academic-practitioner
collaboration need not require joint or relevant research: Toward a
relational
Cohen, Debra J. Editors’ forum
(Research-practice gap in human resource management)—The very
separate worlds of academic and practitioner publications in human
resource management: Reasons for the divide and concrete solutions
for bridging the gap. 50(5): 1013–10
Guest, David E. Editors’ forum
(Research-practice gap in human resource management)—Don’t shoot the
messenger: A wake-up call for academics. 50(5): 1020–1026.
Hambrick, Donald C. Editors’ forum (AMJ
turns 50! Looking back and looking ahead)—The field of management’s
devotion to theory: Too much of a good thing? 50(6): 1346–1352.
Latham, Gary P. Editors’ forum
(Research-practice gap in human resource management)—A speculative
perspective on the transfer of behavioral science findings to the
workplace: “The times they are a-changin’.” 50(5): 1027–1032.
Lawler, Edward E, III. Editors’
forum (Research-practice gap in human resource management)—Why HR
practices are not evidence-based. 50(5): 1033–1036.
Markides, Costas. Editors’ forum
(Research with relevance to practice)—In search of ambidextrous
professors. 50(4): 762–768.
McGahan, Anita M. Editors’ forum
(Research with relevance to practice)—Academic research that matters
to managers: On zebras, dogs, lemmings,
Rousseau, Denise M. Editors’ forum
(Research-practice gap in human resource management)—A sticky,
leveraging, and scalable strategy for high-quality connections
between organizational practice and science. 50(5): 1037–1042.
Rynes, Sara L. Editors’ forum
(Research with relevance to practice)—Editor’s foreword—Carrying
Sumantra Ghoshal’s torch: Creating more positive, relevant, and
ecologically valid research. 50(4): 745–747.
Rynes, Sara L. Editors’ forum
(Research-practice gap in human resource management)—Editor’s
afterword— Let’s create a tipping point: What academics and
practitioners can do, alone and together. 50(5): 1046–1054.
Rynes, Sara L., Tamara L. Giluk, and
Kenneth G. Brown. Editors’ forum (Research-practice gap in human
resource management)—The very separate worlds of academic and
practitioner periodicals in human resource management: Implications
More at
http://journals.aomonline.org/amj/amj_index_2007.pdf
Also see the index sites for earlier years ---
http://journals.aomonline.org/amj/article_index.htm
Jensen Added Comment
I think it is misleading to imply that there's been enough validity
checking in accountics science and that further validity checking is
either not possible or could not possibly have more benefit than cost.
Conclusion
But I do thank you and your 500+ TAR referees for going from virtually
zero to five case and field study publications in fiscal 2011. That's
marked progress. Perhaps Harry will even publish some dialog about
previously-published accountics science articles.
Respectfully,
Bob Jensen
More on Where Accountics Research Went Wrong
June 10, 2010 reply from Richard Sansing
Dan,
I'm confident that you can answer the question you
posed, but since you asked me I will answer.
The TAR article by Fellingham and Newman,
"Strategic considerations in auditing", The Accounting Review 60 (October):
634-50, is certainly a compression of the the audit process. I find it
insightful because it highlights the difference in alpha and beta risks when
auditors and clients are thought of as self-interested, maximizing agents.
Richard Sansing
June 11, 2011 reply from Bob Jensen
Hi Richard,
Has there ever been an audit that measured Type II (Beta) error?? Do you
have some great examples where Type II error is actually measured (or
specified) in TAR, JAR, or JAE articles?
There are only a few, very few, books that I keep beside my computer work
station inside the cottage. Most of my books are on shelves in my outside
studio that's now more of a library than an office. One of my prized
textbooks that I always keep close at hand is an old statistics textbook. I
keep it beside me because it's the best book I've ever studied regarding
Type tI error. It reminds me of how quality control engineers often measure
Type II error, whereas accounting researchers almost never measure Type II
error.
In one of my statistics courses (Stanford) years ago from Jerry
Lieberman, we used that fantastic Engineering Statistics textbook book
authored by Bowker and Lieberman that contained OC curves for Type II error.
In practice, Type II errors are seldom measured in statistical inference
due to lack of robustness regarding distributional assumption errors
(notably unknown standard deviations) , although quality control guys
sometimes know enough about the distributions and standard deviations to
test for Type II error using Operating Characteristic Curves. Also there are
trade offs since the Type I and Type II errors are not independent of one
another. Accounting researchers take the easy way out by testing Type I
error and ignoring Type II error even though in most instances Type II error
is the most interesting error in empirical research.
Of course increasing sample sizes solved many of these Type I and II
inference testing problems, but for very large sample sizes what's the point
of inference testing in the first place? I often chuckle at capital markets
studies that do inference testing on very large sample sizes. These seem to
be just window dressing to appease journal referees.
What might be more interesting in auditing are Type III and Type IV
errors discussed by Mitroff and Silvers in their 2009 book entitled Dirty
Rotten Strategies (ISBN 978-0-8047-5996-0). Type III errors arise from
skilled investigation of the wrong questions. Type IV errors are similar
except they entail deliberately selecting the wrong questions to
investigate.
I think Fred Mosteller in 1948 was the first to suggest Type III error
for correctly rejecting the null hypothesis for the wrong reasons ---
http://www2.sas.com/proceedings/sugi30/208-30.pdf
Has anybody ever tested Type III error in TAR, JAR, or JAE?
Bob Jensen
June 12, 2011 replies from Dan Stone and from Paul Williams
> Thanks Richard,
>
> Got it. Thanks for clarifying. Based
on your response, here's a draft
> letter from you, Professor Demski,
and Professor Zimmerman to parents,
> administrators, and legislators.
Dan Stone
Dan,
I have resisted entering this thread, but
your hypothetical letter compels me to provide a few anecdotes about the
10% of the insightful compression papers that do make it into print.
The first two are very public episodes. Watts and Zimmerman's Notable
Contribution prize winning paper that "verified" the believability of
P/A stories was replicated by McKee, Bell and Boatsman. The
significance of the replication was that it made more realistic
statistical assumptions and, voila, the significance went away. Of
course that didn't deter anyone from continuing to tell this story or at
least seek to tell richer, more insightful stories.
The second involves another notable
contribution paper published by W&Z, the famous Market for Excuses
paper. As Charles Christensen and later Tinker and Puxty demonstrated
the paper was incoherent from the start since it was self-contradictory
(among many other flaws). The paper may have been good libertarian
politics but it was not very good science.
My third anecdote involves a comment I
wrote for Advances in Public Interest Accounting many years ago.
It was a comment on a paper by Ed Arrington. In that comment I used a
widely cited P/A paper (one that made Larry Brown's list in his AOS
classic papers paper) as an example to illustrate the ideologicial
blinders that afflict too many accounting researchers; we always tend to
find what we are looking for -- perhaps because the insightful
compressions we are looking for have to be consistent with Demski and
Zimmerman's views on the way the world should be (it certainly isn't the
way the world is). One comment I made on this P/A paper pertained to the
statistical analysis and it was, basically, that the statistically
significant variables really explained nothing and that there was no
story there.
To seek assurance I was on some kind of
solid ground I took my comments and the paper to a colleague who was an
econometrician (a University of Chicago Ph.D). Back in those days there
was no college of management at NC State, only the department of
economics and business, which was comprised of all economists except one
finance prof and the folks in accounting. Three days after I gave him
the material he called me into to his office to assure me I was correct
in my interpretation and he made a gesture quite profound, given the
metaphor about waste baskets. He picked up the paper (published in one
of the premier journals) and threw it in his waste basket. He said,
"That is where this paper belongs." My issue with TAR, etc. is just
this -- even the 10% of papers we do publish aren't very good "science"
(which is not definitive of a "form" that scholarship must have).
Bob Jensen's threads on where accountics research went wrong ---
http://faculty.trinity.edu/rjensen/theory01.htm#WhatWentWrong
Appendix 9
Econtics: How Scientists Helped Cause Financial Crises
(across 800 years)
"How Scientists Helped Cause Our Financial Crisis," by John Carney,
ClusterStock, November 25, 2008
http://faculty.trinity.edu/rjensen/2008bailout.htm#Scientists
Can the 2008 investment banking failure be traced to a math error?
Recipe for Disaster: The Formula That Killed Wall Street ---
http://www.wired.com/techbiz/it/magazine/17-03/wp_quant?currentPage=all
Link forwarded by Jim Mahar ---
http://financeprofessorblog.blogspot.com/2009/03/recipe-for-disaster-formula-that-killed.html
Some highlights:
"For five years, Li's formula, known as a
Gaussian copula function, looked like an unambiguously positive
breakthrough, a piece of financial technology that allowed hugely
complex risks to be modeled with more ease and accuracy than ever
before. With his brilliant spark of mathematical legerdemain, Li made it
possible for traders to sell vast quantities of new securities,
expanding financial markets to unimaginable levels.
His method was adopted by everybody from bond
investors and Wall Street banks to ratings agencies and regulators. And
it became so deeply entrenched—and was making people so much money—that
warnings about its limitations were largely ignored.
Then the model fell apart." The article goes on to show that correlations
are at the heart of the problem.
"The reason that ratings agencies and investors
felt so safe with the triple-A tranches was that they believed there was
no way hundreds of homeowners would all default on their loans at the
same time. One person might lose his job, another might fall ill. But
those are individual calamities that don't affect the mortgage pool much
as a whole: Everybody else is still making their payments on time.
But not all calamities are individual, and
tranching still hadn't solved all the problems of mortgage-pool risk.
Some things, like falling house prices, affect a large number of people
at once. If home values in your neighborhood decline and you lose some
of your equity, there's a good chance your neighbors will lose theirs as
well. If, as a result, you default on your mortgage, there's a higher
probability they will default, too. That's called correlation—the degree
to which one variable moves in line with another—and measuring it is an
important part of determining how risky mortgage bonds are."
I would highly recommend reading the entire thing that gets much more
involved with the
actual formula etc.
The
“math error” might truly be have been an error or it might have simply been a
gamble with what was perceived as miniscule odds of total market failure.
Something similar happened in the case of the trillion-dollar disastrous 1993
collapse of Long Term Capital Management formed by Nobel Prize winning
economists and their doctoral students who took similar gambles that ignored the
“miniscule odds” of world market collapse -- -
http://faculty.trinity.edu/rjensen/FraudRotten.htm#LTCM
The rhetorical question is whether the failure is ignorance in model building or
risk taking using the model?
Also see
"In Plato's Cave: Mathematical models are a
powerful way of predicting financial markets. But they are fallible" The
Economist, January 24, 2009, pp. 10-14 ---
http://faculty.trinity.edu/rjensen/2008Bailout.htm#Bailout
Wall Street’s Math Wizards Forgot a Few Variables
What wasn’t recognized was the importance of a
different species of risk — liquidity risk,” Stephen Figlewski, a professor of
finance at the Leonard N. Stern School of Business at New York University, told
The Times. “When trust in counterparties is lost, and markets freeze up so there
are no prices,” he said, it “really showed how different the real world was from
our models.
DealBook, The New York Times, September 14, 2009 ---
http://dealbook.blogs.nytimes.com/2009/09/14/wall-streets-math-wizards-forgot-a-few-variables/
"They Did Their Homework (800 Years of It)," by Catherine Rampell,
The New York Times, July 2, 2010 ---
http://www.nytimes.com/2010/07/04/business/economy/04econ.html?_r=1&th&emc=th
Thank you Roger
Collins for the heads up.
The advertisement warns of speculative financial
bubbles. It mocks a group of gullible Frenchmen seduced into a silly,
18th-century investment scheme, noting that the modern shareholder, armed
with superior information, can avoid the pitfalls of the past. “How
different the position of the investor today!” the ad enthuses.
It ran in The Saturday Evening Post on Sept. 14,
1929. A month later, the stock market crashed.
“Everyone wants to think they’re smarter than the
poor souls in developing countries, and smarter than their predecessors,”
says
Carmen M. Reinhart,
an economist at the
University of Maryland. “They’re wrong. And we can
prove it.”
Like a pair of financial sleuths, Ms. Reinhart and
her collaborator from
Harvard,
Kenneth S. Rogoff, have spent years investigating
wreckage scattered across documents from nearly a millennium of economic
crises and collapses. They have wandered the basements of rare-book
libraries, riffled through monks’ yellowed journals and begged central banks
worldwide for centuries-old debt records. And they have manually entered
their findings, digit by digit, into one of the biggest spreadsheets you’ve
ever seen.
Their handiwork is contained in their recent best
seller, “This
Time Is Different,” a quantitative reconstruction
of hundreds of historical episodes in which perfectly smart people made
perfectly disastrous decisions. It is a panoramic opus, both geographically
and temporally, covering crises from 66 countries over the last 800 years.
The book, and Ms. Reinhart’s and Mr. Rogoff’s own
professional journeys as economists, zero in on some of the broader
shortcomings of their trade — thrown into harsh relief by economists’
widespread failure to anticipate or address the
financial crisis that began in 2007.
“The mainstream of academic research in
macroeconomics puts theoretical coherence and elegance first, and
investigating the data second,” says Mr. Rogoff. For that reason, he says,
much of the profession’s celebrated work “was not terribly useful in either
predicting the financial crisis, or in assessing how it would it play out
once it happened.”
“People almost pride themselves on not paying
attention to current events,” he says.
In the past, other economists often took the same
empirical approach as the Reinhart-Rogoff team. But this approach fell into
disfavor over the last few decades as economists glorified financial papers
that were theory-rich and data-poor.
Much of that theory-driven work, critics say, is
built on the same disassembled and reassembled sets of data points —
generally from just the last 25 years or so and from the same handful of
rich countries — that quants have whisked into ever more dazzling and
complicated mathematical formations.
But in the wake of the recent crisis, a few
economists — like Professors Reinhart and Rogoff, and other like-minded
colleagues like Barry Eichengreen and Alan Taylor — have been encouraging
others in their field to look beyond hermetically sealed theoretical models
and into the historical record.
“There is so much inbredness in this profession,”
says Ms. Reinhart. “They all read the same sources. They all use the same
data sets. They all talk to the same people. There is endless extrapolation
on extrapolation on extrapolation, and for years that is what has been
rewarded.”
ONE of Ken Rogoff’s favorite economics jokes — yes,
there are economics jokes — is “the one about the lamppost”: A drunk on his
way home from a bar one night realizes that he has dropped his keys. He gets
down on his hands and knees and starts groping around beneath a lamppost. A
policeman asks what he’s doing.
“I lost my keys in the park,” says the drunk.
“Then why are you looking for them under the
lamppost?” asks the puzzled cop.
“Because,” says the drunk, “that’s where the light
is.”
Mr. Rogoff, 57, has spent a lifetime exploring
places and ideas off the beaten track. Tall, thin and bespectacled, he grew
up in Rochester. There, he attended a “tough inner-city school,” where his
“true liberal parents” — a radiologist and a librarian — sent him so he
would be exposed to students from a variety of social and economic classes.
He received a chess set for his 13th birthday, and
he quickly discovered that he was something of a prodigy, a fact he decided
to hide so he wouldn’t get beaten up in the lunchroom.
“I think chess may be a relatively cool thing for
kids to do now, on par with soccer or other sports,” he says. “It really
wasn’t then.”
Soon, he began traveling alone to competitions
around the United States, paying his way with his prize winnings. He earned
the rank of American “master” by the age of 14, was a New York State Open
champion and soon became a “senior master,” the highest national title.
When he was 16, he left home against his parents’
wishes to become a professional chess player in Europe. He enrolled
fleetingly in high schools in London and Sarajevo, Yugoslavia, but rarely
attended. “I wasn’t quite sure what I was supposed to be doing,” he recalls.
He spent the next 18 months or so wandering to
competitions around Europe, supporting himself with winnings and by
participating in exhibitions in which he played dozens of opponents
simultaneously, sometimes while wearing a blindfold.
Occasionally, he slept in five-star hotels, but
other nights, when his prize winnings thinned, he crashed in grimy train
stations. He had few friends, and spent most of his time alone, studying
chess and analyzing previous games. Clean-cut and favoring a coat and tie
these days, he described himself as a ragged “hippie” during his time in
Europe. He also found life in Eastern Europe friendly but strained, he says,
throttled by black markets, scarcity and unmet government promises.
After much hand-wringing, he decided to return to
the United States to attend Yale, which overlooked his threadbare high
school transcript. He considered majoring in Russian until Jeremy Bulow, a
classmate who is now an economics professor at Stanford, began evangelizing
about economics.
Mr. Rogoff took an econometrics course, reveling in
its precision and rigor, and went on to focus on comparative economic
systems. He interrupted a brief stint in a graduate program in economics at
the Massachusetts Institute of Technology to prepare for the world chess
championships, which were held only every three years.
After becoming an “international grandmaster,” the
highest title awarded in chess, when he was 25, he decided to quit chess
entirely and to return to M.I.T. He did so because he had snared the
grandmaster title and because he realized that he would probably never be
ranked No. 1.
He says it took him a long time to get over the
game, and the euphoric, almost omnipotent highs of his past victories.
“To this day I get letters, maybe every two years,
from top players asking me: ‘How do I quit? I want to quit like you did, and
I can’t figure out how to do it,’ ” he says. “I tell them that it’s hard to
go from being at the top of a field, because you really feel that way when
you’re playing chess and winning, to being at the bottom — and they need to
prepare themselves for that.”
He returned to M.I.T., rushed through what he
acknowledges was a mediocre doctoral dissertation, and then became a
researcher at the Federal Reserve — where he said he had good role models
who taught him how to be, at last, “professional” and “serious.”
Teaching stints followed, before the International
Monetary Fund chose him as its chief economist in 2001. It was at the I.M.F.
that he began collaborating with a relatively unfamiliar economist named
Carmen Reinhart, whom he appointed as his deputy after admiring her work
from afar.
MS. REINHART, 54, is hardly a household name. And,
unlike Mr. Rogoff, she has never been hired by an Ivy League school. But
measured by how often her work is cited by colleagues and others, this woman
whom several colleagues describe as a “firecracker” is, by a long shot, the
most influential female economist in the world.
Like Mr. Rogoff, she took a circuitous route to her
present position.
Born in Havana as Carmen Castellanos, she is
quick-witted and favors bright, boldly printed blouses and blazers. As a
girl, she memorized the lore of pirates and their trade routes, which she
says was her first exposure to the idea that economic fortunes — and state
revenue in particular — “can suddenly disappear without warning.”
She also lived with more personal financial and
social instability. After her family fled Havana for the United States with
just three suitcases when she was 10, her father traded a comfortable living
as an accountant for long, less lucrative hours as a carpenter. Her mother,
who had never worked outside the home before, became a seamstress.
“Most kids don’t grow up with that kind of real
economic shock,” she says. “But I learned the value of scarcity, and even
the sort of tensions between East and West. And at a very early age that had
an imprint on me.”
With a passion for art and literature — even today,
her academic papers pun on the writings of Gabriel García Márquez — she
enrolled in a two-year college in Miami, intending to study fashion
merchandising. Then, on a whim, she took an economics course and got hooked.
When she went to Florida International University
to study economics, she met Peter Montiel, an M.I.T. graduate who was
teaching there. Recognizing her talent, he helped her apply to a top-tier
graduate program in economics, at Columbia University.
At Columbia, she met her future husband, Vincent
Reinhart, who is now an occasional co-author with her. They married while in
graduate school, and she quit school before writing her dissertation to try
to make some money on Wall Street.
“We were newlyweds, and neither of us had a penny
to our name,” she says. She left school so that they “could have nice things
and a house, the kind of things I imagined a family should have.”
She spent a few years at Bear Stearns, including
one as chief economist, before deciding to finish her graduate work at
Columbia and return to her true love: data mining. “I have a talent for
rounding up data like cattle, all over the plain,” she says.
After earning her doctorate in 1988, Ms. Reinhart
started work at the I.M.F.
“Carmen in many ways pioneered a bigger segment in
economics, this push to look at history more,” says Mr. Rogoff, explaining
why he chose her. “She was just so ahead of the curve.”
She honed her knack for economic archaeology at the
I.M.F., spending several years performing “checkups” on member countries to
make sure they were in good economic health.
While at the fund, she teamed up with Graciela
Kaminsky, another member of that exceptionally rare species — the female
economist — to write their seminal paper, “The Twin Crises.”
The article looked at the interaction between
banking and currency crises, and why contemporary theory couldn’t explain
why those ugly events usually happened together. The paper bore one of Ms.
Reinhart’s hallmarks: a vast web of data, compiled from 20 countries over
several decades.
In digging through old records and piecing together
a vast puzzle of disconnected data points, her ultimate goal, in that paper
and others, has always been “to see the forest,” she says, “and explain it.”
Ms. Reinhart has bounced back and forth across the
Beltway: she left the I.M.F. in Washington and began teaching in 1996 at the
University of Maryland, from which Mr. Rogoff recruited her when he needed a
deputy at the I.M.F. in 2001. When she left that post, she returned to the
university.
Despite the large following that her work has
drawn, she says she feels that the heavyweights of her profession have
looked down upon her research as useful but too simplistic.
“You know, everything is simple when it’s clearly
explained,” she contends. “It’s like with Sherlock Holmes. He goes through
this incredible deductive process from Point A to Point B, and by the time
he explains everything, it makes so much sense that it sounds obvious and
simple. It doesn’t sound clever anymore.”
But, she says, “economists love being clever.”
“THIS TIME IS DIFFERENT” was published last
September, just as the nation was coming to grips with a financial crisis
that had nearly spiraled out of control and a job market that lay in
tatters. Despite bailout after bailout, stimulus after stimulus, economic
armageddon still seemed nigh.
Given this backdrop, it’s perhaps not surprising
that a book arguing that the crisis was a rerun, and not a wholly novel
catastrophe, managed to become a best seller. So far, nearly 100,000 copies
have been sold, according to its publisher, the Princeton University Press.
Still, its authors laugh when asked about the
book’s opportune timing.
“We didn’t start the book thinking that, ‘Oh, in
exactly seven years there will be a housing bust leading to a global
financial crisis that will be the perfect environment in which to sell this
giant book,’ ” says Mr. Rogoff. “But I suppose the way things work, we
expected that whenever the book came out there would probably be some crisis
or other to peg it to.”
They began the book around 2003, not long after Mr.
Rogoff lured Ms. Reinhart back to the I.M.F. to serve as his deputy. The
pair had already been collaborating fruitfully, finding that her dogged
pursuit of data and his more theoretical public policy eye were well
matched.
Although their book is studiously nonideological,
and is more focused on patterns than on policy recommendations, it has
become fodder for the highly charged debate over the recent growth in
government debt.
Continued in article
Academic Worlds (TAR) vs. Practitioner Worlds (AH)
The Financial Management
Association (popular with finance professors) had it's 2010 annual
meeting in late October in NYC. Here are reviews of some of the FMA papers
that interest finance professors ---
http://www.fma.org/NY/NYProgram.htm
The FMA (and its main journals (Financial Management and the
Journal of Applied Finance) was formed at a time when the American
Finance Association (and its Journal of Finance) was deemed too
esoteric in mathematical economics and growing out of touch with the
industry of finance. Some would argue today that the quants are also taking
over the FMA, but that's a topic I will leave to the membership of the FMA.
Finance practitioners have generally been more respectful of their quants
than accounting practitioners are respectful of their quants in academia.
One simple test would be to ask some random practitioners to name ten quants
who have had an impact on industry. Finance practitioners could probably
name ten (e.g., Markowitz, Modigliani, Arrow, Sharp, Lintner, Merton,
Scholes, Fama, French, etc.). Accounting practitioners could probably only
name one or two from their alma maters at best and then not because of
awareness of anything practical that ever came out of accountics.
The FMA makes a concerted effort to motivate finance professors to do
research on topics of interest to practitioners ---
http://69.175.2.130/~finman/Practitioners/PDDARIpage.htm
I spent a year in a think tank with Phil Zimbardo and found him to be
really fascinating scholar. Aside from becoming a multimillionaire from his
highly successful psychology textbook, Phil is known for creativity in
psychological experiments --- before and after his infamous Stanford prison
guard experiments blew up in his face.
Phil Zimbardo ---
http://en.wikipedia.org/wiki/Phil_zimbardo
Stanford Prison Experiment ---
http://en.wikipedia.org/wiki/Stanford_prison_study
"Too Hard for Science? Philip Zimbardo--creating millions of heroes,"
by Charles Q. Cho, Scientific American, April 22, 2011 ---
http://www.scientificamerican.com/blog/post.cfm?id=too-hard-for-science-philip-zimbard-2011-04-22
If outside influences can make people
act badly, can they also be used to help people do good?
In "Too Hard for Science?" I interview
scientists about ideas they would love to explore that they don't think
could be investigated. For instance, they might involve machines beyond
the realm of possibility, such as particle accelerators as big as the
sun, or they might be completely unethical, such as lethal experiments
involving people. This feature aims to look at the impossible dreams,
the seemingly intractable problems in science. However, the question
mark at the end of "Too Hard for Science?" suggests that nothing might
be impossible.
The scientist:
Philip Zimbardo,
professor emeritus of psychology at Stanford University.
The idea: Zimbardo is likely
best known for the
Stanford
Prison Experiment, which revealed how even
good people can do evil, shedding light on how the subtle but powerful
influences of a situation can radically alter individual behavior. The
study randomly assigned two dozen normal, healthy young men as either
"prisoners" or "guards" in a mock jail in a basement in Stanford
University in 1971 to investigate the psychology of prison life. The
researchers discovered the volunteers quickly began acting out their
roles, with the guards becoming sadistic in only a few days, findings
recently detailed in Zimbardo's book, "The
Lucifer Effect."
After the Stanford Prison Experiment, Zimbardo
began exploring ways to create heroes instead of villains. "My idea is
sowing the earth with millions of everyday heroes trained to act wisely
and well when the opportunity presents itself," he says.
The problem: The greatest
challenge that Zimbardo thinks his idea of creating heroes en masse
faces is how "people think heroes are born, not made; that they can't be
heroes," he says. "The fact is that most heroes are ordinary people.
It's the heroic act that is extraordinary."
As an example, Zimbardo pointed out New York
construction worker
Wesley Autrey, who jumped onto subway tracks
and
threw himself over a seizure victim,
restraining him while a train hurtled an inch above their heads in 2007.
"We want to change the mentality of people away from the belief that
they're not the kind who do heroic deeds to one where they think
everyone has the potential to be heroic," he says. "Mentality plus
opportunity ideally equals heroic action."
The solution? Zimbardo and his
colleagues have created the
Heroic
Imagination Project, a nonprofit organization
devoted to advancing everyday heroism. By heroism, they do not simply
mean
altruism. "Heroism as we define it means
taking action on the behalf of others for a moral cause, aware of
possible risks and costs and without expectation of gain," he clarifies.
Their program has four sections. "First, we
want to fortify people against the dark side, to be aware of the
standard tactics used by perpetrators of evil, how they seduce good
people to doing bad things," Zimbardo says. "Using video clips, we'll
show how this happens — bystander inaction, diffusion of responsibility,
the power of the group, obedience to authority and the like."
"Once you learn these lessons, we then want to
inspire you to the bright side," he continues. "We want to give examples
of how people like you have done heroic things to inspire your heroic
imagination, and then train you to be a wise and effective hero. We want
you to think big and start small, giving tips on what to do each day on
this journey. We're saying, 'Here's how to be an agent of change, step
by step by step.'"
"For instance, heroes are sociocentric — they
come to others in need, make other people feel central — so a challenge
each day might be to make people feel special, give them a compliment,"
he explains. "It's not heroic, but it's focusing on the other, and once
you get used to it, you can develop other heroic habits. Also, heroes
are always deviants — in most group situations, the group does nothing,
so heroes have to learn how to break away from the pull of a group, be
positive deviants, dare to be different."
"We want people to think of themselves as
heroes-in-training, and make a public commitment to take on the hero
challenge, since research shows that making public commitments increases
the chances of intentions carried into action," Zimbardo says. "We also
want to invite people to sign up with one or two friends, make it a
social rather than a private event, since most heroes are effective in
networks. We're arguing that we can create a network of heroes, using
the power of the Web."
In the second part of the program, "we're
developing corporate initiatives, thinking about how to create cultures
of integrity," Zimbardo says. They are in talks with companies such as
Google, he notes. "Can you imagine avoiding disasters such as the
Deepwater oil spill if we had people in the right places willing to
speak up and act?" In the third, they will engage the public, sending
and receiving information through their Web site and promoting public
activities, such as Eco-Heroes, a program where young people work with
elders to save their environment; Health-Heroes, where one helps family
members exercise, quit smoking, eat responsibly, take medications and
the like; and the Heroic Disability Initiative, which aims to provide
the handicapped and disabled with examples of people like them who
performed heroic deeds, as well as ways to take part in community
programs.
In the last part of the program, "we're
research-centered," Zimbardo says. "We are
measuring changes in attitude, beliefs, values and critical behavior
with an education program in four different high schools in the San
Francisco Bay Area, from inner-city schools in Oakland to more
privileged ones in Palo Alto, trying out these strategies, seeing what
works, what doesn't. What does work we'll put on our Web site. We also
want to start a research scholar award program for graduate students to
do research on heroism. It's amazing that there's been research on evil
for years, but almost no research on heroism, and we want to do more of
that."
Continued in article
Bob Jensen's threads on theory are at
http://faculty.trinity.edu/rjensen/Theory01.htm
The videos of the three plenary speakers at the 2010 American Accounting
Association Annual Meetings in San
Francisco are now linked at
http://commons.aaahq.org/hives/1f77f8e656/summary
Although all three
speakers provided inspirational presentations, Steve Zeff and I both
concluded that Bob Kaplan’s presentation was possibly the best that we had
ever viewed among all past AAA plenary sessions. And we’ve seen a lot of
plenary sessions in our long professional careers.
Now that Kaplan’s video is
available I cannot overstress the importance that accounting educators and
researchers watch the video of Bob Kaplan's August 4, 2010 plenary
presentation
http://commons.aaahq.org/hives/1f77f8e656/summary
Don’t miss the history map of Africa analogy to academic accounting
research!!!!!
This dovetails with my Web document at
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
Also see (slow loading)
http://faculty.trinity.edu/rjensen/theory01.htm#WhatWentWrong
Trivia Questions
1. Why did Bob wish he’d worn a different color suit?
2. What does JAE stand
for besides the Journal of Accounting and Economics?
Hi Jerry,
Your mention of
Bob Mautz reminded me of Steve Zeff’s excellent presentation in San
Francisco on August 4, 2010 following the plenary session.
Steve compared
the missions of the Accounting Horizons with performances since AH
was inaugurated. Bob Mautz faced the daunting tasks of being the first
Senior Editor of AH and of setting the missions of that journal for the
future in the spirit dictated by the AAA Executive Committee at the time and
of Jerry Searfoss (Deloitte) and others providing seed funding for starting
up AH.
Steve Zeff
first put up a list of the AH missions as laid out by Bob Mautz in the
first issues of AH:
Mautz, R. K. 1987. Editorial.
Accounting Horizons (September): 109-111.
Mautz, R. K. 1987. Editorial:
Expectations: Reasonable or ridiculous? Accounting Horizons
(December): 117-120.
Steve Zeff then
discussed the early successes of AH in meeting these missions followed by
mostly years of failure in terms of meeting the original missions laid out
by Bob Mautz ---
http://fisher.osu.edu/departments/accounting-and-mis/the-accounting-hall-of-fame/membership-in-hall/robert-kuhn-mautz/
Steve's PowerPoint slides are at
http://www.cs.trinity.edu/~rjensen/temp/ZeffCommentOnAccountingHorizons.ppt
Steve’s
conclusion was that AH became more like TAR rather than the
practitioner-academy marriage journal that was originally intended. And yes,
Steve did analyze the AH Commentaries as well as the mainline articles in
reaching this conclusion.
Steve Kachelmeier
(current Senior Editor of TAR) followed Steve Zeff and made what I also
think was an excellent presentation making points that he’d mostly made
earlier this summer on the AECM. One comment that stands out that Steve K
will probably prefer that I do not repeat is that (paraphrased) “doing
academic research to creatively impact accounting and business practice is
harder than doing the kind of research published in TAR mostly for other
academic researchers.”
That is a point
that I’ve lamented repeatedly over the past two decades. One problem is that
academic accountants generally do not have noteworthy comparative advantage
over practitioners s in generating creative ideas for practitioners of
accounting (excluding AIS where the academy ties to the profession seem to
be closer). Most creative ideas impacting the profession (such as ABC
costing, balanced score card, and dollar-value LIFO) were invented by
practitioners rather than academics. And the investment analysis innovations
(such as CAPM or lattice option pricing models) that did flow from academe
to the profession tended to be created by finance and economics professors
rather than accounting professors.
I suspect that
Richard Sansing will quickly rebut my remarks with evidence that tax
accounting researchers in academe did create some clever innovations for
accounting practitioners and the IRS --- and I hope he does indeed provide
us with some examples.
However, apart
from AIS and tax, I don’t expect many replies to this thread that
demonstrate how seminal creative research in the accounting academy impacted
the practicing profession. It’s almost certain that practitioners cannot
name the accounting professors (other than Bob Kaplan and his Harvard
colleagues) that provided them with research that improved the profession
itself. I readily admit that I’m one of the failed accountics researchers in
this regard, including my original contributions to eigenvector scaling and
other priority weighting schema for the Analytic Hierarchy Process (AHP)
that pretty much failed in its real world experiments in helping decision
makers choose between alternatives ---
http://faculty.trinity.edu/rjensen/Resume.htm#Published
One of the main
missions of Accounting Horizons was to provide incentives for
academic accounting researchers to focus more closely on the needs of
practitioners. Steve Zeff concluded that AH is not doing a very good
job in this mission.
On a somewhat
related theme, Bob Kaplan alleged that noted fair value researchers like
MacNeal, Canning, Chambers, Sterling, Edwards, and Bell failed to do what he
(Bob Kaplan) has done with ABC costing and balanced scorecard. Simply
putting out textbook theory and textbook examples of fair value accounting
are bound for failure until researchers actually put the new ideas to work
in real-world companies and auditing firms.
Bob Kaplan’s
message to Tom Selling and Patricia Walters would be that it’s no longer of
much value to preach the theoretical virtues of exit value accounting or
entry value accounting for non-financial assets. Bob Kaplan would instead
tell them to put their favored theories to work in the real world and
attempt to demonstrate/measure the value added relative enormous costs and
risks of real world implementations.
For example, in
1929 John Canning outlined the theoretical virtues of entry value accounting
for all assets ---
http://www.ruf.rice.edu/~sazeff/PDF/Canning%20-%20View%20of%20His%20Academic%20Career.PDF
But nobody has
demonstrated, in the context of what Bob Kaplan did for ABC costing and
balanced scorecard, that entry value accounting really provides substantial
benefits relative to costs and risks in the real world. The FAS 33 effort
was deemed a failure as applied by FAS 33 rules, but FAS 33 should not be
the final word on why entry value accounting is doomed. FAS 33
implementation guidelines cut implementation costs to the bare bones such
that analysts had virtually no faith in the accuracy of replacement costs
generated in the financial statements.
Fair value
accounting for financial assets is having more success largely because real
world applications seem to be meeting the test of value added (although
bankers still disagree with dubious arguments). Aside from the FAS 33
failure, the jury has not even convened for almost non-existent fair value
implementations of exit value or entry value accounting implementations on
non-financial assets in going concerns.
Bob Jensen.
August 145, 2010 reply from Dennis R Beresford
[dberesfo@UGA.EDU]
Bob,
I’m very sorry I didn’t attend the AAA annual
meeting this year (first miss in about 15 years or so). I would have enjoyed
listening to Steve Zeff’s presentation. In fact, I always enjoy listening to
or reading Steve’s work.
I’m pleased to see that Steve pointed out the
original mission of Accounting Horizons and that that mission seems to have
been largely ignored over the past decade or more. When I received my latest
issue I thought they had put the wrong cover on it as the first two or three
articles had just as many formulas as The Accounting Review! Perhaps
Accounting Horizons is now the overflow publication for TAR or maybe it
should be labled TAR-Lite for articles that somehow are not quite as strong
in methodology.
Of course, it’s hard to know whether the problem is
that practitioners aren’t meeting their end of the bargain by submitting
pieces for consideration or whether the editors are not seeking pieces from
practitioners or discouraging them in other ways. As you know, I had enjoyed
a nice record of several articles in AH over my time at the FASB but was
rejected by the then editor for a similar paper based on a plenary
presentation I made to the AAA annual meeting at the end of my term at the
FASB. That effectively ended my interest in dealing with AH as a journal
that supposedly had some interest in views from practitioners. I have no way
of know whether other “practitioners” even try to submit articles to AH
these days but seeing the current contents my guess would be not.
Frankly, some of the dialogue on AECM, properly
edited, would make for great content in AH. It would certainly be a lot more
practical and relevant than much (most) of what is published in the AAA’s
official journals these days!
Denny Beresford
Free Book
Bridging the Gap between Academic Accounting Research and Professional
Practice
Edited by Elaine Evans, Roger Burritt and James Guthrie
Institute of Chartered Accountants in Australia's Academic Leadership Series
2011
http://www.charteredaccountants.com.au/academic
Why is academic accounting research still lacking
impact and relevance? Why is it considered so detached and worlds apart from
practice and society? These and many more questions are tackled in this new
publication commissioned by the Institute and the Centre for Accounting,
Governance and Sustainability (CAGS) in the School of Commerce at the
University of South Australia.
Each chapter provides fresh insights from leading
accounting academics, policy makers and practitioners. The book triggers a
call for action, with contributors unanimously agreeing more collaboration
is needed between all three elements that make up the accounting profession
- researchers, policy makers and practitioners.
Jensen Comment
The other day, following a message from Denny Beresford complaining about how
Accounting Horizons is failing it's original mission statement as clearly
outlined by its first editor years ago, the messaging on the AECM focused upon
the complete lack of practitioners on the AH Editorial Board and tendency to now
appoint an editor or pair of co-editors who are in the academy and are far
afield from the practicing world.
Steve Zeff
recently compared the missions of the Accounting Horizons with
performances since AH was inaugurated. Bob Mautz faced the daunting tasks of
being the first Senior Editor of AH and of setting the missions of that journal
for the future in the spirit dictated by the AAA Executive Committee at the time
and of Jerry Searfoss (Deloitte) and others providing seed funding for starting
up AH.
Steve Zeff first put up a list of
the AH missions as laid out by Bob Mautz in the first issues of AH:
Mautz, R. K. 1987. Editorial.
Accounting Horizons (September): 109-111.
Mautz, R. K. 1987. Editorial:
Expectations: Reasonable or ridiculous? Accounting Horizons
(December): 117-120.
Steve Zeff then
discussed the early successes of AH in meeting these missions followed by mostly
years of failure in terms of meeting the original missions laid out by Bob Mautz
---
http://fisher.osu.edu/departments/accounting-and-mis/the-accounting-hall-of-fame/membership-in-hall/robert-kuhn-mautz/
Steve's PowerPoint slides are at
http://www.cs.trinity.edu/~rjensen/temp/ZeffCommentOnAccountingHorizons.ppt
But as I think about it more, I'm inclined less and less to blame the editors
of Accounting Horizons or the referees. Most likely all of them would
like to see Accounting Horizons bridge the research gap between the esoteric
Accounting Review (TAR) and practitioner journals like the Journal of
Accountancy (JA) known less and less for publishing research.
The real reason Accounting Horizons has become so disappointing is
that there are so few submissions of research articles that bridge the gap
between the academic world and the practicing world. And practitioners
themselves are not submitting research articles.
It's like Pogo said years ago:
“WE HAVE MET THE ENEMY AND HE IS US.”
Pogo ---
http://www.igopogo.com/final_authority.htm
Since the 1960s accounting doctoral programs have produced decades of
graduates interested in accountics research that has little relevance to the
practicing profession of accountancy. Virtually all these graduates would like
to get articles accepted by TAR, but TAR virtually won't publish field studies
and case studies. Hence we have decades of accounting doctoral graduates seeking
publishing outlets that are clones of TAR, JAR, and JAE. Academic researchers
get little credit for publishing in practitioner journals and so the submit less
and less research to those journals. And their accountics submissions to
practitioner journals have little value to practitioners due to lack of
relevance to practitioners. This is due in great measure to the fact
accounting professors in R1 research universities, unlike their colleagues in
medical, law, and engineering schools, are so removed from the practice of
accountancy.
What Went Wrong With Accountics Research?
http://faculty.trinity.edu/rjensen/theory01.htm#WhatWentWrong
"Focusing the Balanced Scorecard (BSC) and Lean Accounting on Business
Process Using a Gratis (free) ISO 9000 Simulation,"
August 6, 2008 ---
http://commons.aaahq.org/posts/01be622074
Tom Klammer, University of North Texas
Sandra Richtermeyer, Xavier University
James Sorensen, University of Denver
Jensen Comment
What caught my attention is the claim: "Over eighty-five percent (85%) of
Corporate America uses or tries to use the Balanced Scorecard (BSC) according to
the Ernst & Young and IMA (2003) survey of tools used by practitioners."
Over
eighty-five percent (85%) of
Corporate America uses or tries to
use the Balanced Scorecard (BSC)
according to the Ernst & Young and
IMA (2003) survey of tools used by
practitioners. Using a gratis (free)
ISO 9000:2000 simulation (Cimlite),
you can focus your management
accounting classroom on business
process management--the most heavily
weighted perspective in the Balanced
Scorecard. Other accounting
innovations such as Lean Accounting
focus also on business process
objectives of cost reduction and
quality improvement (Huntzinger, IMA
88th (2007) Annual Conference &
Exposition).
A stimulating
and effective way to focus your
classroom on the business process is
through the use of ISO 9000:2000,
one of the major frameworks
available to businesses to reduce
costs and improve quality (
www.iso.org ).
Instructors or
students can download copies of the
simulation (Cimlite) free of charge
from John A. Keane and Associates,
Inc.
www.qmsprograms.com/LEGAL.HTM .
In addition
to the simulation at no cost, we
provide original essential teaching
support materials so you will be
able to introduce this exciting
material into your course with a
minimum of start-up effort. This
simulation has been demonstrated
with success in classes.
Question
What has the academy provided that's truly relevant to equity asset management
in practice?
"Economists’ Hubris – The Case of Equity Asset Management," Shahin Shojai,
George Feiger, and Rajesh Kumar, SSRN, April 29, 2010 ---
http://papers.ssrn.com/sol3/papers.cfm?abstract_id=1597685
Abstract:
In this, the fourth article in the economists’ hubris paper series we look
at the contributions of academic thought to the field of asset management.
We find that while the theoretical aspects of the modern portfolio theory
are valuable they offer little insight into how the asset management
industry actually operates, how its executives are compensated, and how
their performances are measured. We find that very few, if any, portfolio
managers look for the efficiency frontier in their asset allocation
processes, mainly because it is almost impossible to locate in reality, and
base their decisions on a combination of gut feelings and analyst
recommendations. We also find that the performance evaluation methodologies
used are simply unable to provide investors with the necessary tools to
compare portfolio managers’ performances in any meaningful way. We suggest a
novel way of evaluating manager performance which compares a manager against
himself, as suggested by Lord Myners. Using the concept of inertia, an asset
manager’s end of period performance is compared to the performance of their
portfolio assuming their initial portfolio had been held, without
transactions, during this period. We believe that this will provide clients
with a more reliable performance comparison tool and might prevent
unnecessary trading of portfolios. Finally, given that the performance
evaluation models simply fail in practice, we suggest that accusing
investors who look for raw returns when deciding who to invest their assets
with is simply unfair.
Jensen Comment
I repeatedly contend that if accountics research added any value to practice
then there would be more efforts to validate/replicate accountics research ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
At least in the economics academy, there are a greater number of validation
studies, especially validation studies of the Efficient Market Hypothesis ---
http://faculty.trinity.edu/rjensen/theory01.htm#EMH
Freakonomish and Simkinish processes in accounting research
and practice
Question
What are two of the most Freakonomish and Simkinish processes in
accounting research and practice?
Accounting researchers may want to track
Freakonomics
publications along with the works of
Mikhail Simkin at UCLA
Freakonomish and Simkinish processes in auditing pracice
The IASB and FASB are moving us ever closer into requiring subjective
evaluations of unique items for which CPA auditors have no comparative
advantages in evaluation. For example, CPAs have no comparative advantage in
estimating the value of unique parcels of real estate (every parcel of real
estate is unique). Another example would be the ERP system of Union Carbide that
has value to Union Carbide but cannot be dismantled and resold to any other
company.
The problem with many subjective evaluations is that the so-called experts on
those items are not consistent in their own evaluations. For example, real
estate appraisers are notoriously inconsistent, which is what led to many of the
subprime mortgage scandals when appraisers were placing enormous values on tract
housing as if the real estate bubble would never burst. And placing a fair value
on the ERP system of Union Carbide is more of an art than a science due to so
many unknowns in the future of that worldwide company.
Freakonomish and Simkinish processes in accounting research
Secondly, accounting researchers may want to track Freakonomics and the
related works of Mikhail Simkin at UCLA. Professor Simkin made quite a name for
himself evaluating subjective evaluators and in illustrating the art and science
of subjective and science evaluations ---
http://www.ee.ucla.edu/~simkin/
And the tendency of accounting researchers to accept their empirical and
analytical academic publications as truth that does not even need a single
independent and exacting replication if Freakonomish and Simkinish in and of
itself ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
"Measuring The Quality Of Abstract Art: Abstract artists are only 4 per
cent better than child artists, according to a controversial new way of
evaluating paintings," MIT's Technology Review, June 14, 2011 ---
http://www.technologyreview.com/blog/arxiv/26882/?nlid=4597
Here's a bit of mischief from Mikhail Simkin at the
the University of California, Los Angeles.
Simkin has a made a name for himself evaluating the
relative performance of various groups and individuals. On this blog, we've
looked at his work on the performance of
congress,
physicists and even
World War I
flying aces.
Today, he turns his attention to abstract artists.
For some time now, Simkin has a run an online quiz in which he asks people
to label abstract pictures either real art or fake. It's fun--give
it a go.
One average, people answer correctly about 66 per
cent of the time, which is significantly better than chance.
Various people have interpreted this result (and
others like it) as a challenge to the common claim that abstract art by
well-know artists is indistinguishable from art created by children or
animals.
Today, Simkin uses this 66 per cent figure as a way
of evaluating the work of well known artists. In particular, he asks how
much better these professional artists are than children.
First, he points out the results of another well
known experiment in which people are asked to evaluate weights by picking
them up. As the weights become more similar, it is harder to tell which is
heavier. In fact, people will say that a 100g weight is heavier than a 96g
weight only 72 per cent of the time.
"This means that there is less perceptible
difference between an abstractionist and child/animal than between 100 and
96g," says Simkin.
So on this basis, if you were to allocate artistic
'weight' to artists and gave an abstract artist 100g, you would have to give
a child or animal 96g. In other words, there is only a 4 per cent difference
between them.
That's not much!
Simkin goes on to say this is equivalent in chess
to the difference between a novice and the next ranking up, a D-class
amateur.
Continued in article
Bob Jensen's threads on what went wrong with accounting standard setting
and academic accounting research are at
http://faculty.trinity.edu/rjensen/Theory01.htm
"Psychology’s Treacherous Trio: Confirmation Bias,
Cognitive Dissonance, and Motivated Reasoning," by sammcnerney, Why We
Reason, September 7, 2011 ---
Click Here
http://whywereason.wordpress.com/2011/09/07/psychologys-treacherous-trio-confirmation-bias-cognitive-dissonance-and-motivated-reasoning/
What went wrong in accounting/accountics research?
http://faculty.trinity.edu/rjensen/theory01.htm#WhatWentWrong
574 Shields Against Validity Challenges in Plato's Cave
---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
- With a Rejoinder from the 2010 Senior Editor of The Accounting
Review (TAR), Steven J. Kachelmeier
- With Replies in Appendix 4 to Professor Kachemeier by Professors
Jagdish Gangolly and Paul Williams
- With Added Conjectures in Appendix 1 as to Why the Profession of
Accountancy Ignores TAR
- With Suggestions in Appendix 2 for Incorporating Accounting Research
into Undergraduate Accounting Courses
Gaming for Tenure as an Accounting Professor ---
http://faculty.trinity.edu/rjensen/TheoryTenure.htm
(with a reply about tenure publication point systems from Linda Kidwell)
Gaming for Tenure as an Accounting Professor ---
http://faculty.trinity.edu/rjensen/TheoryTenure.htm
574 Shields Against Validity Challenges in Plato's Cave ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
- With a Rejoinder from the 2010 Senior Editor of The
Accounting Review (TAR), Steven J. Kachelmeier
- With Replies in Appendix 4 to Professor Kachemeier by
Professors Jagdish Gangolly and Paul Williams
- With Added Conjectures in Appendix 1 as to Why the
Profession of Accountancy Ignores TAR
- With Suggestions in Appendix 2 for Incorporating
Accounting Research into Undergraduate Accounting Courses
What went wrong in accounting/accountics research?
http://faculty.trinity.edu/rjensen/theory01.htm#WhatWentWrong
Insignificance of Testing the Null
The Insignificance of Testing the Null
October 1, 2010 message from Amy Dunbar
Nick Cox posted a link to a statistics paper on
statalist:
2009. Statistics: reasoning on uncertainty, and the
insignificance of testing null. Annales Zoologici Fennici 46: 138-157.
http://www.sekj.org/PDF/anz46-free/anz46-138.pdf
Cox commented that the paper touches provocatively
on several topics often aired on statalist including the uselessness of
dynamite or detonator plots, displays for comparing group means and
especially the over-use of null hypothesis testing. The main target audience
is ecologists but most of the issues cut across statistical science.
Dunbar comment: The paper would be a great addition
to any PhD research seminar. The author also has some suggestions for
journal editors. I included some responses to Nick's original post below.
Jensen Comment
And to think Alpha (Type 1) error is the easy part. Does anybody ever test for
the more important Beta (Type 2) error? I think some engineers test for Type 2
error with Operating Characteristic (OC) curves, but these are generally applied
where controlled experiments are super controlled such as in quality control
testing.
Beta Error ---
http://en.wikipedia.org/wiki/Beta_error#Type_II_error
Appendix 12
The BYU Study of Accounting Programs Ranked by Research Publications
Updated BYU Study (especially David
Wood): Universities Ranked According to
Accounting Research ---
http://www.byuaccounting.net/rankings/univrank/rankings.php
The
rankings presented via the links . . .
are based on the research paper
Accounting Program Research Rankings By
Topic and Methodology, forthcoming in
Issues In Accounting Education . These
rankings are based on classifications of
peer reviewed articles in 11 accounting
journals since 1990. To see the set of
rankings that are of interest to you,
click on the appropriate title.
Each
cell contains the ranking and the
(number of graduates) participating in
that ranking. The colors correspond to a
heat map (see legend at bottom of table)
showing the research areas in which a
program excels. Move your mouse over the
cell to see the names of the graduates
that participated in that ranking
Jensen Comment
I'm impressed by the level of detail,
I repeat my cautions about rankings that
I mentioned previously about the earlier
study. Researchers sometimes change
affiliations two, three, or even more times
over the course of their careers. Joel
Demski is now at Florida. Should Florida get
credit for research published by Joel when
he was a tenured professor at Stanford and
at Yale before moving to Florida?
There is also a lot of subjectivity in
the choice of research journals and methods.
Even though the last cell in the table is
entitled "Other Topic, Other Material,"
there seems to me to be a bias against
historical research and philosophical
research and a bias for accountics research.
This of course always stirs me up ---
http://faculty.trinity.edu/rjensen/Theory01.htm#WhatWentWrong
In future updates I would like to see
more on accounting history and applied
accounting research. For example, I would
like to see more coverage of the Journal of
Accountancy. An example article that gets
overlooked research on why the lattice model
for valuing employee stock options has key
advantages over the Black-Scholes Model:
"How to “Excel” at Options Valuation,"
by Charles P. Baril, Luis Betancourt, and
John W. Briggs, Journal of Accountancy,
December 2005 ---
http://www.aicpa.org/pubs/jofa/dec2005/baril.htm
The Journal of Accountancy and
many other applied research/professional
journals are not included in this BYU study.
Hence professors who publish research
studies in those excluded journals are not
given credit for their research, and their
home universities are not given credit for
their research.
Having said all this, the BYU study is
the best effort to date in terms of
accounting research rankings of
international universities, accounting
researchers, and doctoral student research.
Impact Factors in Journal Article Rankings ---
http://en.wikipedia.org/wiki/Impact_factor
Especially note the criticisms.
"Citation-Based Benchmarks and Individual
Accounting Faculty Research Rankings by
Topical Area and Methodology," by
Garrison Lee Nuttall, Neal M. Snow, Scott L.
Summers, and David A. Wood,
SSRN, May 20,
2015 ---
http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2608491
Abstract
This paper provides citation rankings
and benchmarking data for individual
accounting researchers disaggregated by
topic and methodological area. The data
provides a unique contribution to
accounting research by providing a
current help for evaluating the quality
of accounting researchers’ work. We
gather citation data from Google Scholar
for papers published in respected
accounting journals to create rankings
of researchers based on the number of
citations crediting an individual’s
work. We also provide benchmarking data
that includes the average number of
citations a paper has received given the
year of its publication. Data are
disaggregated by accounting topic area
(accounting information systems, audit,
financial, managerial, tax, other) and
methodology (analytical, archival,
experimental, other) because of
significantly different citation
patterns by topic area and methodology.
This data will benefit accounting
researchers and those interested in
evaluating them by providing objective
information for identifying producers of
quality research.
"Deep Impact: Impact Factors and Accounting Research," SSRN, Wm.
Dennis Huber, May 23., 2014 ---
http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2441340
Jensen Comment
My main criticism in academic accounting is that citations become a closed loop
among accountics science researchers who sought articles on how to apply the
general linear model (GLM) without much if any concern on the relevance of the
findings
http://www.cs.trinity.edu/~rjensen/temp/AccounticsWorkingPaper450.06.pdf
Citations: Two Selected Papers About Academic
Accounting Research Subtopics (Topical Areas) and Research Methodologies
http://www.cs.trinity.edu/~rjensen/temp/AccounticsScienceCitations.htm
Accountics is the mathematical science of
values.
Charles Sprague [1887]
Accountics
Research History ---
http://www.trinity.edu/rjensen/395wpTAR/Web/TAR395wp.htm
"Individual
Accounting Faculty Research Rankings by
Topical Area and Methodology," by
Jeffrey Pickerd, Nathaniel M. Stephens,
Scott L. Summers, and David A. Wood,
Issues in Accounting Education, American
Accounting Association Vol. 26, No. 3,
August 2011, pp. 471–505 ---
http://aaapubs.aip.org/getpdf/servlet/GetPDFServlet?filetype=pdf&id=IAEXXX000026000003000471000001&idtype=cvips
(Access limited to paid subscribers)
Rankings
of Accountics Science Researchers
It's only slightly misleading to call the
Pickerd (2011) et al. accountics
science researcher rankings (see below).
There are a small percentage of
non-accountics research articles included in
the thousands of articles in the 11 journals
in this study's database, but these these
were apparently insignificant since Table 2
of the study is limited to three accountics
science research methods. In Table 2
only three research
methods are recognized in the study ---
Analytical, Archival, and Experimental.
Accounting Information Systems (AIS) does
not fit neatly into the realm of accountics
science. The authors mention that there are
"Other" occasional non-accountics and
non-AIS articles published in the 11
journals of the database, but these are
totally ignored as "research methods" in
Table 2 of the study.
The
top-ranked academic accounting researchers
listed in the tables of this study are all
noted for their mathematics and statistical
writings.
The articles
in the rankings database were published over
two recent decades in 11 leading academic
accounting research journals.
The "Top
Six" Journals
The Accounting Review (TAR),
Journal of Accounting Research (JAR),
Journal of Accounting and Economics
(JAE),
Contemporary Accounting Research (CAR),
Review of Accounting Studies (RAST),
Accounting, Organizations and Society (AOS).
Other
Journals in the Rankings Database
Auditing: A Journal of Practice &
Theory (Auditing),
Journal of the American Taxation
Association (JATA),
Journal of Management Accounting
Research (JMAR),
Journal of Information Systems (JIS),
Behavioral Research in Accounting
(BRIA).
Probably the
most telling bias of the study is the
bias against normative, case method, and
field study accountancy research.
In fact only three methods are recognized as
"research methods" in Table 2 ---
Analytical, Archival, and Experimental. For
example, the best known and most widely
published accounting case method researcher
is arguably Robert Kaplan of Harvard
University. Kaplan is not even listed among
the hundreds of accountics scientists ranked
in Table 1 (Topical Areas) of this this
study although he was, before 1990, a very
noted accountics researcher who shifted more
into case and field research. Nor is the
famous accounting case researcher Robin
Cooper mentioned in the study. For years
both Kaplan and Cooper have complained about
how the top accountics science journals like
TAR discourage non-accountics science
submissions
"Accounting Scholarship that Advances
Professional Knowledge and Practice," The
Accounting Review, March 2011, Volume
86, Issue 2,
Also see
http://www.trinity.edu/rjensen/TheoryTAR.htm
What is not
clear is what the Pickerd (2011) et al.
authors did with non-accountics articles
in Table 1 (Topics) versus Table 2
(Methods). These
articles were obviously not included in
Table 2 (Methods) . But were their
non-accountics study authors included in
Table 1 (Topics)? My guess is
that they were included in Table 1. Other
than for AIS, I could be wrong on this with
respect to Table 1. In any case, the number
of non-accountics articles available for the
database is extremely small relative to the
thousands of accountics science articles in
the database. Except in the area of AIS in
Table 1, this is an accountics scientist set
of rankings.
"Individual
Accounting Faculty Research Rankings by
Topical Area and Methodology," by
Jeffrey Pickerd, Nathaniel M. Stephens,
Scott L. Summers, and David A. Wood, Issues
in Accounting Education, American Accounting
Association Vol. 26, No. 3, August 2011, pp.
471–505 ---
http://aaapubs.aip.org/getpdf/servlet/GetPDFServlet?filetype=pdf&id=IAEXXX000026000003000471000001&idtype=cvips
(Access limited to paid subscribers)
ABSTRACT: This paper ranks individual accounting researchers based on their research productivity in the most recent six, 12, and 20 years. We extend
prior individual faculty rankings by providing separate individual faculty research rankings for each topical area commonly published in accounting journals
(accounting information systems [AIS], audit, financial, managerial, and tax). In addition, we provide individual faculty research rankings for each research
methodology commonly used by accounting researchers (analytical, archival, and experimental). These findings will be of interest to potential doctoral students
and current faculty, as well as accounting department, business school, and university administrators as they make decisions based on individual faculty members’ research productivity.
When reading
the rankings the following coding is used in
the cells:
Table 1 presents the top 100-ranked
accounting researchers by topical area
based on publication counts in the
selected accounting journals. In the
tables, the first number reported is the
ranking that does not take into account
coauthorship; the second reported number
(after the *) is the ranking if authors
receive only partial credit for
coauthored work. The table shows the
author rank based on article counts over
the entire sample period of the study
(20 years), as well as ranks based on
the number of articles published in
selected journals over the past 12-year
and six-year windows. Even though
specialization is common in accounting
research, it is interesting to note that
some professors publish widely in a
variety of topical areas.
In other
words, Jane Doe (3*32) means that Jane ranks
3 in terms of authorship of articles in a
category but has a lower rank of 32 if the
rankings are adjusted for joint authorship
partial credit.
It should
also be noted that authors are listed on the
basis of the 20-year window.
One of the
most noteworthy findings in this study, in
my viewpoint, is the tendency for most
(certainly not all) leading academic
researchers to publish research more
frequently in the earliest years of their
careers (especially before earning tenure)
relative to later years in their careers.
Here are the
top two winners in each category:
Table
1, Panel A: AIS
Author
6-Year (2004–2009) 12-Year
(1998–2009) 20-Year (1990–2009)
Hunton, James E., Bentley
University
1 *1
1 *1
1 *1
Murthy, Uday S., University of South
Florida 10
*35 8
*4 2
*3
Table
1, Panel B: Audit
Author
6-Year (2004–2009) 12-Year
(1998–2009) 20-Year (1990–2009)
Raghunandan, K., Florida International
U. 1
*4 1
*2
1 *3
Wright, Arnold M., Northeastern
University 7
*9 5
*5
1 *2
Table
1, Panel C: Financial
Author
6-Year (2004–2009) 12-Year
(1998–2009) 20-Year (1990–2009)
Barth, Mary E., Stanford
University
60 *159 2
*8
1 *2
Francis, Jennifer, Duke
University
6 *26
3 *13
2 *5
Table
1,Panel D: Managerial
Author
6-Year (2004–2009) 12-Year
(1998–2009) 20-Year (1990–2009)
Banker, Rajiv D., Temple
University
12 *30
3 *13
1 *3
Reichelstein, Stefan, Stanford
University 1
*2 1
*1 2
*1
Table
1,Panel E: Tax
Author
6-Year (2004–2009) 12-Year
(1998–2009) 20-Year (1990–2009)
Sansing, Richard C., Dartmouth
College 1
*1 1
*1 1
*1
Dhaliwal, Dan S., The University of
Arizona 1
*3 2
*3 2
*4
Table
2, Panel A: Analytical
Author
6-Year (2004–2009) 12-Year
(1998–2009) 20-Year (1990–2009)
Reichelstein, Stefan, Stanford
University 1
*1 1
*1 1
*2
Feltham, Gerald A.,
Retired
8 *26
4 *9
2 *7
Table
2, Panel B: Archival
Author
6-Year (2004–2009) 12-Year
(1998–2009) 20-Year (1990–2009)
Barth, Mary E., Stanford
University
107 *174
8 *15
1 *1
Francis, Jennifer, Duke
University
5
*23 3
*13 2
*3
Table
2, Panel C: Experimental
Author
6-Year (2004–2009) 12-Year
(1998–2009) 20-Year (1990–2009)
Libby, Robert, Cornell
University
4 *9
2 *3
1 *3
Tan, Hun-Tong, Nanyang Technological
U. 1
*1
1 *1
2 *1
Table
2, Panel D: Other
Author
6-Year (2004–2009) 12-Year
(1998–2009) 20-Year (1990–2009)
None listed
I call your
attention to a similar BYU study in which
accounting research programs in universities
are ranked ---
http://www.byuaccounting.net/rankings/univrank/rankings.php
Click
on the name of a university to learn
more about the research done by that
university.
What is
interesting is to note how poorly some of
these universities do in the Pickerd (2011)
rankings of their individual faculty
members. Some like Stanford and Duke do
quite well in the Pickerd rankings, but many
other highly ranked accountics science
programs in the above the list do much worse
than I would've expected. This suggests that
some programs are ranked high on the basis
of numbers of accountics scientists more
than the publishing frequency of any one
resident scientist. For example, the
individual faculty members at Chicago, the
University of Illinois, Wharton
(Pennsylvania), and Harvard don't tend to
rank highly in the Pickerd rankings.
Ignoring
the Accountics Science Controversies
Pickerd (2011) et al. make no mention
of the limitations and heated controversies
concerning accountics science and the fact
that one of the journals (AOS) among the 11
in the database (as well as AOS's founder
and long-time editor) is largely devoted to
criticism of accountics science.
"Whither Accounting Research?" by
Anthony G. Hopwood The Accounting Review
82(5), 2007, pp.1365-1374
Organizations like the American
Accounting Association also have a role
to play, not least with respect to their
presence in the field of scholarly
publication. For the American Accounting
Association, I would say that now is the
time for it to adopt a leadership role
in the publication of accounting
research. Not only should every effort
be made to encourage The Accounting
Review to embrace the new, the
innovative, what accounting research
might be in the process of becoming, and
new interdisciplinary perspectives, but
this should also be done in a way that
provides both a catalyst and a model for
other journals of influence. For they
need encouragement, too. While the
Association has done much to embrace the
need for a diversity of gender and race,
so far it has done relatively little to
invest in intellectual diversity, even
though this is not only of value in its
own terms, but also an important
generator of innovation and intellectual
progress. I, at least, would see this as
appropriate for a learned society in the
modern era. The American Accounting
Association should set itself the
objective of becoming an exemplar of
intellectual openness and thereby
innovation.
"The Absence of
Dissent," by Joni J. Young, Accounting
and the Public Interest 9 (1), 2009 ---
Click Here
ABSTRACT:
The persistent malaise in accounting
research continues to resist remedy.
Hopwood (2007) argues that revitalizing
academic accounting cannot be
accomplished by simply working more
diligently within current paradigms.
Based on an analysis of articles
published in Auditing: A Journal of
Practice & Theory, I show that this
paradigm block is not confined to
financial accounting research but
extends beyond the work appearing in the
so-called premier U.S. journals. Based
on this demonstration I argue that
accounting academics must tolerate (and
even encourage) dissent for accounting
to enjoy a vital research academy. ©2009
American Accounting Association
Also see the
following references critical of the
accountics science monopoly on academic
accounting research:
Shielding
Against Validity Challenges in Plato's Cave
---
http://www.trinity.edu/rjensen/TheoryTAR.htm
What went
wrong in accounting/accountics research?
http://www.trinity.edu/rjensen/theory01.htm#WhatWentWrong
Appendix 13
The Big Difference Between Medical Research and Accounting Research
Accountics Scientists Seeking Truth:
"Frankly, Scarlett, after I get a hit for my resume in The Accounting Review
I just don't give a damn"
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
One more mission in what's left of my life will be to try to change this
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
Question
What is "the" major difference between medical research and accounting research
published in top research journals?
Answer
Medical researchers publish a lot of research that is "misleading, exaggerated,
or flat-out wrong." The difference is that medical research eventually discovers
and corrects most published research errors. Accounting researchers rarely
discover their errors and leave these errors set in stone ad infinitum
because of a combination of factors that discourage replication and retesting of
hypotheses. To compound the problem, accounting researchers commonly purchase
their data from outfits like Audit Analytics and Compustat and make no effort to
check the validity of the data they have purchased. If some type of rare
research finding validation takes place, accounting researchers go on using the
same data. More commonly, once research using this data is initially published
in accounting research journals, independent accounting researchers do not even
replicate the research efforts to discover whether the original researchers made
errors ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
Nearly always published accounting research, accounting research findings are
deemed truth as long they are published in top accounting research journals.
Fortunately, this is not the case in medical research even though long delays in
discovering medical research truth may be very harmful and costly.
MUCH OF WHAT MEDICAL RESEARCHERS CONCLUDE IN THEIR
STUDIES IS MISLEADING, EXAGGERATED, OR FLAT-OUT WRONG. SO WHY ARE DOCTORS—TO A
STRIKING EXTENT—STILL DRAWING UPON MISINFORMATION IN THEIR EVERYDAY PRACTICE?
DR. JOHN IOANNIDIS HAS SPENT HIS CAREER CHALLENGING HIS PEERS BY EXPOSING THEIR
BAD SCIENCE.
""Lies, Damned Lies, and Medical Science," by David H. Freedman, Atlantic,
November 2010 ---
http://www.theatlantic.com/magazine/archive/2010/11/lies-damned-lies-and-medical-science/8269/
Thank you Chris Faye for the heads up.
. . .
But beyond the headlines, Ioannidis was shocked at
the range and reach of the reversals he was seeing in everyday medical
research. “Randomized controlled trials,” which compare how one group
responds to a treatment against how an identical group fares without the
treatment, had long been considered nearly unshakable evidence, but they,
too, ended up being wrong some of the time. “I realized even our
gold-standard research had a lot of problems,” he says. Baffled, he started
looking for the specific ways in which studies were going wrong. And before
long he discovered that the range of errors being committed was astonishing:
from what questions researchers posed, to how they set up the studies, to
which patients they recruited for the studies, to which measurements they
took, to how they analyzed the data, to how they presented their results, to
how particular studies came to be published in medical journals.
This array suggested a bigger, underlying
dysfunction, and Ioannidis thought he knew what it was. “The studies were
biased,” he says. “Sometimes they were overtly biased. Sometimes it was
difficult to see the bias, but it was there.” Researchers headed into their
studies wanting certain results—and, lo and behold, they were getting them.
We think of the scientific process as being objective, rigorous, and even
ruthless in separating out what is true from what we merely wish to be true,
but in fact it’s easy to manipulate results, even unintentionally or
unconsciously. “At every step in the process, there is room to distort
results, a way to make a stronger claim or to select what is going to be
concluded,” says Ioannidis. “There is an intellectual conflict of interest
that pressures researchers to find whatever it is that is most likely to get
them funded.”
Continued in article
Bob Jensen's threads on what went wrong with "accountics research" can be
found at
http://faculty.trinity.edu/rjensen/theory01.htm#WhatWentWrong
Possibly the Worst Academic Scandal in Past 100 Years: Deception
at Duke
The Loose Ethics of Co-authorship of Research in Academe
In general we don't allow faculty to have publications ghost written for
tenure and performance evaluations. However, the rules are very loose regarding
co-author division of duties. A faculty member can do all of the research but
pass along all the writing to a co-author except when co-authoring is not
allowed such as in the writing of dissertations.
In my opinion the rules are too loose regarding co-authorship. Probably the
most common abuse in the current "publish or perish" environment in academe is
the partnering of two or more researchers to share co-authorships when their
actual participation rate in the research and writing of most the manuscripts is
very small, maybe less than 10%. The typical partnering arrangement is for an
author to take the lead on one research project while playing only a small role
in the other research projects
Gaming for Tenure as an
Accounting Professor ---
http://faculty.trinity.edu/rjensen/TheoryTenure.htm
(with a reply about tenure publication point systems from Linda Kidwell)
Another common abuse, in my opinion, is where a senior faculty member with a
stellar reputation lends his/her name to an article written and researched
almost entirely by a lesser-known colleague or graduate student. The main author
may agree to this "co-authorship" when the senior co-author's name on the paper
improves the chances for publication in a prestigious book or journal.
This is what happened in a sense in what is becoming the most notorious
academic fraud in the history of the world. At Duke University a famous
cancer researcher co-authored research that was published in the most
prestigious science and medicine journals in the world. The senior faculty
member of high repute is now apologizing to the world for being a part of a
fraud where his colleague fabricated a significant portion of the data to make
it "come out right" instead of the way it actually turned out.
What is interesting is to learn about how super-knowledgeable researchers at
the Anderson Cancer Center in Houston detected this fraud and notified the Duke
University science researchers of their questions about the data. Duke appears
to have resisted coming out with the truth way to long by science ethics
standards and even continued to promise miraculous cures to 100 Stage Four
cancer patients who underwent the miraculous "Duke University" cancer cures that
turned out to not be miraculous at all. Now Duke University is exposed to quack
medicine lawsuit filed by families of the deceased cancer patients who were
promised phone 80% cure rates.
The above Duke University scandal was the headline module in the February 12,
2012 edition of CBS Sixty Minutes. What an eye-opening show about science
research standards and frauds ---
Deception at Duke (Sixty Minutes
Video) ---
http://www.cbsnews.com/8301-18560_162-57376073/deception-at-duke/
Next comes the question of whether college administrators operate under
different publishing and speaking ethics vis-à-vis their faculty
"Faking It for the Dean," by Carl Elliott, Chronicle of Higher Education,
February 7, 2012 ---
http://chronicle.com/blogs/brainstorm/says-who/43843?sid=cr&utm_source=cr&utm_medium=en
Added Jensen Comment
I've no objection to "ghost writing" of interview remarks as long as the ghost
writer is given full credit for doing the writing itself.
I also think there is a difference between speeches versus publications with
respect to citations. How awkward it would be if every commencement speaker had
to read the reference citation for each remark in the speech. On the other hand,
I think the speaker should announce at the beginning and end that some of the
points made in the speech originated from other sources and that references will
be provided in writing upon request.
Bob Jensen's threads on professors who let students cheat ---
http://faculty.trinity.edu/rjensen/Plagiarism.htm#RebeccaHoward
Bob Jensen's threads on professors who cheat
http://faculty.trinity.edu/rjensen/Plagiarism.htm#ProfessorsWhoPlagiarize
"Boston U. Scientists Retract Controversial Study," Inside Higher
Ed, July 22, 2011 ---
http://www.insidehighered.com/news/2011/07/22/qt#265897
Boston University researchers have retracted a
paper, originally published in Science, in which they claimed to have
identified a genetic signature for human longevity,
The Boston Globe reported. A new analysis
found that some of the data they used were incorrect. A statement from
Science said: "Although the authors remain confident about their
findings, Science has concluded on the basis of peer review that a
paper built on the corrected data would not meet the journal's standards for
genome-wide association studies. The researchers worked exhaustively to
correct the errors in the original paper and we regret the outcome of the
exhaustive revision and re-review process was not more favorable."
"Bad science: The psychology behind exaggerated & false research [infographic],"
Holykaw, December 21, 2011 ---
http://holykaw.alltop.com/bad-science-the-psychology-behind-exaggerated
One in three scientists admits to using shady research practices.
Bravo: Zero accountics scientists admit to using shady research practices.
One in 50 scientists admit to falsifying data outright.
Bravo: Zero accountics scientists admit to falsifying data in the history
of accountics science.
Reports of colleague misconduct are even more common.
Bravo: But not in accountics science
Misconduct rates are highest among clinical, medical, and phamacological
researchers
Bravo: Such reports are lowest (zero) among accountics scientists
Four ways to make research more honest
- Make all raw data available to other scientists
- Hold journalists accountable
- Introduce anonymous publication
- Change from real science into accountics science where research is
unlikely to be validated/replicated except on rare occasions where no errors
are ever found
574 Shields Against Validity Challenges in Plato's Cave ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
"A Wisdom 101 Course!" February 15, 2010 ---
http://www.simoleonsense.com/a-wisdom-101-course/
"Overview of Prior Research on Wisdom," Simoleon Sense,
February 15, 2010 ---
http://www.simoleonsense.com/overview-of-prior-research-on-wisdom/
"An Overview Of The Psychology Of Wisdom," Simoleon Sense,
February 15, 2010 ---
http://www.simoleonsense.com/an-overview-of-the-psychology-of-wisdom/
"Why Bayesian Rationality Is Empty, Perfect Rationality Doesn’t Exist,
Ecological Rationality Is Too Simple, and Critical Rationality Does the Job,"
Simoleon Sense, February 15, 2010 ---
Click Here
http://www.simoleonsense.com/why-bayesian-rationality-is-empty-perfect-rationality-doesn%e2%80%99t-exist-ecological-rationality-is-too-simple-and-critical-rationality-does-the-job/
Great Minds in Management: The Process of Theory Development ---
http://faculty.trinity.edu/rjensen//theory/00overview/GreatMinds.htm
Steve's 2010 Update on TAR ---
http://www.cs.trinity.edu/~rjensen/temp/TheoryAnnual ReportTAR_2010.pdf
"The Impact of Academic Accounting Research on Professional Practice: An
Analysis by the AAA Research Impact Task Force," by Stephen R. Moehrle,
Kirsten L. Anderson, Frances L. Ayres, Cynthia E. Bolt-Lee, Roger S. Debreceny,
Michael T. Dugan, Chris E. Hogan, Michael W. Maher, and Elizabeth Plummer,
Accounting Horizons, December 2009, pp. 411- 456.
SYNOPSIS:
The accounting academy has been long recognized as the premier developer of
entry-level talent for the accounting profession and the major provider of
executive education via master’s-level curricula and customized executive
education courses. However, the impact that the academy’s collective ideas
have had on the efficiency and effectiveness of practice has been less
recognized. In this paper, we summarize key contributions of academic
accounting research to practice in financial accounting, auditing, tax,
regulation, managerial accounting, and information systems. Our goal is to
increase awareness of the effects of academic accounting research. We
believe that if this impact is more fully recognized, the practitioner
community will be even more willing to invest in academe and help
universities address the escalating costs of training and retaining
doctoral-trained research faculty. Furthermore, we believe that this
knowledge will attract talented scholars into the profession. To this end,
we encourage our colleagues to refer liberally to research successes such as
those cited in this paper in their classes, in their textbooks, and in their
presentations to nonacademic audiences.
Jensen Comment
This paper received the AAA's 2010 Accounting Horizon's best paper award.
However, I don't find a whole lot of recognition of work in practitioner
journals. My general impression is one of disappointment. Some of my comments
are as follows:
Unsubstantiated Claims About the Importance of Accountics Event Studies on
Practitioners
The many citations of accounting event studies are more like a listing of
"should-have-been important to practitioners" rather than demonstrations that
these citations were "actually of great importance to practitioners." For
example, most practitioners for over 100 years have known that earnings numbers
and derived ratios like P/E ratios impact investment portfolio decisions and
acquisition-merger decisions. The findings of accountics researchers in these
areas simply proved the obvious to practitioners if they took the time and
trouble to understand the complicated mathematics of these event studies. My
guess is that most practitioners did not delve deeply into these academic
studies and perhaps do not pay any attention to complicated studies that prove
the obvious in their eyes. In any case, the authors of the above studies did not
contact practitioners to test out assumed importance of accountics research in
these events studies. In other words, this AAA Task Force did not really show,
at least to me, that these events studies had a great impact on practice beyond
what might've been used by standard setters to justify positions that they
probably would've taken with or without the accountics research findings.
Mention is made about how the FASB and government agencies included
accounting professors in some deliberations. This is well and good but the study
does not do a whole lot to document if and how these collaborations found
accountics research of great practical value.
Practitioner Journal Citations of Accountics Research
The AAA Task Force study above did not examine practitioner journal citations of
accountics research journals like TAR, JAR, and JAE. The mentions of
practitioner journals refer mostly to accounting professors who published in
practitioner journals such as when Kenney and Felix published a descriptive
piece in the 1980 Journal of Accountancy or Altman/McGough and Hicks
published 1974 pieces in the Journal of Accountancy. Some mentions of
practitioner journal citations have to go way back in time such as the mention
of the Mautz and Sharaf. piece in the 1961 Journal of Accountancy.
Accountics professors did have some impact of auditing practice, especially
in the areas of statistical sampling. The types of sampling used such as
stratified sampling were not invented by accounting academics, but auditing
professors did make some very practical suggestions on how to use these models
in both audit sampling and bad debt estimation.
Communication with Users
There is a very brief and disappointing section in the AAA Task Force report.
This section does not report any Task Force direct communications with
practitioners. Rather it cites two behavioral studies using real-world subjects
(rather than students) and vague mention studies related to SAS No. 58.
Unsubstantiated Claims About the Importance of Mathematical Models on
Management Accounting Practice
To the extent that mathematical models may or may not have had a significant
impact on managerial accounting is not traced back to accounting literature per
se. For example, accounting researchers did not make noteworthy advances of
linear programming shadow pricing or inventory decision models originating in
the literature of operations research and management science. Accounting
researcher advances in these applications are hardly noteworthy in the
literature of operations research and management science or in accounting
practitioner journal citations.
No mention is made by the AAA Task Force of how the AICPA funded the
mathematical information economics study Cost Determination:
A Conceptual Approach, and then the AICPA refused to publish and
distanced itself from this study that was eventually picked up by the
Iowa State University Press in1976. I've
seen no evidence that this research had an impact on practice even though it is
widely cited in the accountics literature. The AICPA apparently did not think it
would be of interest to practitioners.
The same can be said of regression models used in forecasting. Business firms
do make extensive applications of regression and time series models in
forecasting, but this usage can be traced back to the economics, finance, and
statistics professors who developed these forecasting models. Impacts of
accounting professors on forecasting are not very noteworthy in terms of
accounting practice.
Non-Accountics Research
The most valid claims of impact of accounting academic research on practice were
not accountics research studies. For example, the balanced score card research
of Kaplan and colleagues is probably the best cited example of accounting
professor research impacting practice, but Bob Kaplan himself is a long-time
critic of resistance to publishing his research in TAR, JAR, and JAE.
There are many areas where AIS professors interact closely with practitioners
who make use of their AIS professor software and systems contributions,
especially in the areas of internal control and systems security. But most of
this research is of the non-accountics and even non-mathematical sort.
One disappointment for me in the AIS area is the academic research on XBRL.
It seems that most of the noteworthy creative advances in XBRL theory and
practice have come from practitioners rather than academics.
Impact of Academic Accountants on Tax Practice
Probably the best section of the AAA Task Force report cites links between
academic tax research and tax practice. Much of this was not accountics
research, but credit must be given its due when the studies having an impact
were accountics studies.
Although many sections of the AAA Task force report disappointed me, the tax
sections were not at all disappointing. I only wish the other sections were of
the same quality.
For me the AAA Task Force report is a disappointment except where noted
above. If we had conducted field research over the past three years that focused
on the A,B,C,D, or F grades practitioners would've given to academic accounting
research, my guess is that most practitioners would not even know enough about
most of this research to even assign a grade. Some of them may have learned
about some of this research when they were still taking courses in college, but
their interest in this research, in my opinion, headed south immediately after
they received their diplomas (unless they returned to college for further
academic studies).
One exception might be limited exposure to academic accounting research given
by professors who also teach CEP courses such as CEP courses in audit sampling,
tax, audit scorecard, ABC costing, and AIS. I did extensive CEP teaching
on the complicated topics of FAS 133 on accounting for derivative financial
instruments and hedging activities. However, most of my academic research
citations were in the areas of finance and economics since there never has been
much noteworthy research on FAS 133 in the accountics literature.
Is there much demand for CEP courses on econometric modeling and capital
markets research?
Most practitioners who are really into valuation of business firms are
critical of the lack of relevance of Residual Income models and Free Cash Flow
models worshipped ad nauseum in the academic accounting research
literature.
The December 2012 issue of Accounting Horizons has four commentaries
under the heading
Essays on the State of Accounting Scholarship
These essays could not be published in The Accounting Review because they
do not contain the required equations for anything published in TAR.
I think we owe Accounting Horizons Editor Dana Hermanson an applause for
making "Commentaries" a major section in each issue of AH. Hopefully this
will be carried forward by new AH Editors Paul Griffin and Arnold Wright.
A huge disappointment to me was that none of the essay authors quoted or even
referenced the 2012 Pathways Commission Report, which once again illustrates how
the mere mention of the Pathways Commission Report sends accountics
scientists running for cover. Several of the Pathways Commission Report
are as follows:
"Accounting for Innovation," by Elise Young, Inside Higher Ed,
July 31, 2012 ---
http://www.insidehighered.com/news/2012/07/31/updating-accounting-curriculums-expanding-and-diversifying-field
Accounting programs should promote curricular
flexibility to capture a new generation of students who are more
technologically savvy, less patient with traditional teaching methods, and
more wary of the career opportunities in accounting, according to a report
released today by the
Pathways Commission, which studies the future of
higher education for accounting.
In 2008, the U.S. Treasury Department's Advisory
Committee on the Auditing Profession recommended that the American
Accounting Association and the American Institute of Certified Public
Accountants form a commission to study the future structure and content of
accounting education, and the Pathways Commission was formed to fulfill this
recommendation and establish a national higher education strategy for
accounting.
In the report, the commission acknowledges that
some sporadic changes have been adopted, but it seeks to put in place a
structure for much more regular and ambitious changes.
The report includes seven recommendations:
The Pathways Commission Implementing Recommendations for
the Future of Accounting Education: The First Year Update
American Accounting Association
August 2013
http://commons.aaahq.org/files/3026eae0b3/Pathways_Update_FIN.pdf
- Integrate accounting research, education
and practice for students, practitioners and educators by bringing
professionally oriented faculty more fully into education programs.
- Promote accessibility of doctoral
education by allowing for flexible content and structure in doctoral
programs and developing multiple pathways for degrees. The current path
to an accounting Ph.D. includes lengthy, full-time residential programs
and research training that is for the most part confined to quantitative
rather than qualitative methods. More flexible programs -- that might be
part-time, focus on applied research and emphasize training in teaching
methods and curriculum development -- would appeal to graduate students
with professional experience and candidates with families, according to
the report.
- Increase recognition and support for
high-quality teaching and connect faculty review, promotion and tenure
processes with teaching quality so that teaching is respected as a
critical component in achieving each institution's mission. According to
the report, accounting programs must balance recognition for work and
accomplishments -- fed by increasing competition among institutions and
programs -- along with recognition for teaching excellence.
- Develop curriculum models, engaging learning
resources and mechanisms to easily share them, as well as enhancing
faculty development opportunities to sustain a robust curriculum that
addresses a new generation of students who are more at home with
technology and less patient with traditional teaching methods.
- Improve the ability to attract high-potential,
diverse entrants into the profession.
- Create mechanisms for collecting, analyzing
and disseminating information about the market needs by establishing a
national committee on information needs, projecting future supply and
demand for accounting professionals and faculty, and enhancing the
benefits of a high school accounting education.
- Establish an implementation process to address
these and future recommendations by creating structures and mechanisms
to support a continuous, sustainable change process.
According to the report, its two sponsoring
organizations -- the American Accounting Association and the American
Institute of Certified Public Accountants -- will support the effort to
carry out the report's recommendations, and they are finalizing a strategy
for conducting this effort.
Continued in article
In spite of not acknowledging the Pathways Commission Report, however,
the various essay authors did in one way or another pick up on the major
resolutions of the Pathways Commission Report. In particular the essays
urge greater diversity of research methodology in academic accounting research.
Since the theme of the essays is "scholarship" rather than just research, I
would have hoped that the authors would have devoted more attention to the
following Pathways Commission Report resolutions:
The Pathways Commission
Implementing Recommendations for the Future of Accounting Education: The
First Year Update
American Accounting Association
August 2013
http://commons.aaahq.org/files/3026eae0b3/Pathways_Update_FIN.pdf
- Integrate accounting research, education
and practice for students, practitioners and educators by bringing
professionally oriented faculty more fully into education programs.
- Promote accessibility of doctoral
education by allowing for flexible content and structure in doctoral
programs and developing multiple pathways for degrees. The current path
to an accounting Ph.D. includes lengthy, full-time residential programs
and research training that is for the most part confined to quantitative
rather than qualitative methods. More flexible programs -- that might be
part-time, focus on applied research and emphasize training in teaching
methods and curriculum development -- would appeal to graduate students
with professional experience and candidates with families, according to
the report.
- Increase recognition and support for
high-quality teaching and connect faculty review, promotion and tenure
processes with teaching quality so that teaching is respected as a
critical component in achieving each institution's mission. According to
the report, accounting programs must balance recognition for work and
accomplishments -- fed by increasing competition among institutions and
programs -- along with recognition for teaching excellence.
But it's unfair on my part to dwell on what the essay authors do not do.
What's more important is to focus on what they accomplish, and I think they
accomplish a lot. It's very important that we keep the Pathways Commission
Report and these four essays momentum moving until we finally shake the bonds of
narrow minded chains of binding our faculty hiring, doctoral programs curricula,
and article acceptance practices of our leading academic research journals.
I particularly admire these essay authors for acknowledging the seeds of
change planted by earlier scholars.
Bob Jensen's threads on the needs for change are at the following links:
What
went wrong in accounting/accountics research?
How did academic accounting research
become a pseudo science?
http://faculty.trinity.edu/rjensen/theory01.htm#WhatWentWrong
Why must all accounting doctoral programs be social
science (particularly econometrics) "accountics" doctoral programs?
Why accountancy doctoral programs are drying up and
why accountancy is no longer required for admission or
graduation in an accountancy doctoral program
http://faculty.trinity.edu/rjensen/theory01.htm#DoctoralPrograms
574 Shields Against Validity Challenges in Plato's Cave ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
How Accountics Scientists
Should Change:
"Frankly, Scarlett, after I get a hit for my resume in The Accounting
Review I just don't give a damn"
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
One more mission in what's left of my life will be
to try to change this
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
Comments on the AECM on each of these four essays may help
further the cause of change in accounting academia.
"Introduction for Essays on the State of
Accounting Scholarship," Gregory B. Waymire, Accounting Horizons,
December 2012, Vol. 26, No. 4, pp. 817-819 ---
http://aaajournals.org/doi/full/10.2308/acch-50236
. . .
|
CHARGE GIVEN TO
PRESENTERS AND ATTENDEES AT THE 2011 AAA STRATEGIC RETREAT |
The presenters and
attendees at the retreat were asked to consider the following:
Assertion: Accounting research as of 2011 is stagnant and lacking in
significant innovation that introduces fresh ideas and insights into
our scholarly discipline.
Questions: Is this a correct statement? If not, why? If so, what
factors have led to this state of affairs, what can be done to
reverse it, and what role, if any, should AAA play in this process?
In terms of presenters,
I sought a variety of scholarly perspectives within the accounting
academy. I ended up asking the four scholars whose essays follow to
speak for 30 minutes on the assertion and questions given above. These
scholars represent different areas of accounting research and employ
different methodologies in their research. They also are thoughtful
people who consider issues of scholarship from long histories of
personal experience at different types of universities for their current
positions and their doctoral education.
Attendees at the retreat
also included members of the Executive Committee. In addition, incoming
co-chairs of the Annual Meeting (Anil Arya and Rick Young), Doctoral
Consortium (Sudipta Basu and Ilia Dichev), and New Faculty Consortium
(Kristy Towry and Mohan Venkatachalam) Committees of AAA were invited to
attend.
The primary
purpose of the May retreat was “idea generation.” That is, what can we
do together as scholars to increase the long-run viability of our
discipline? My view was that the retreat and the specific comments by
the presenters would provide a basis for a longer-term conversation
about the future of accounting scholarship and the role of AAA within
that future.
Several subsequent events have provided opportunities to continue the
conversation about scholarly innovation in accounting. First, I spoke at
the AAA Annual Meeting in Denver, August 2011, to update the membership
about the initiative now titled “Seeds of Innovation in Accounting
Scholarship.” That presentation and the related slides can now be found
on AAA Commons (http://commons.aaahq.org/hives/a3d1bee423/summary,
or simply
www.seedsofinnovation.org). Second, I have
written up my own views on these issues and integrated them with the
preliminary suggestions developed at the May 2011 retreat (Waymire
2012). Third, further discussion has taken
place in the AAA Board and, more importantly, in the new AAA Council.
The Council discussion will be ongoing this year, and I expect to form a
task force that will consist of Council members and others to develop
more specific proposals in January 2012. My hope is that these proposals
will cover a broad range of areas that involve AAA publications,
consortia, and meetings, and help guide AAA over the next several years
as we seek to improve the quality of the accounting discipline.
"Framing the Issue of Research Quality in a
Context of Research Diversity," by Christopher S. Chapman, Accounting
Horizons, December 2012, Vol. 26, No. 4, pp. 821-831 ---
http://aaajournals.org/doi/full/10.2308/acch-10314
The current editorial
policy of The Accounting Review states “The scope of acceptable
articles should embrace any research methodology and any
accounting-related subject, as long as the articles meet the standards
established for publication in the journal.” The policy concludes with
the statement “The journal is also open to all rigorous research
methods.” Private journals are rightly entitled to set as selective an
editorial policy as they think proper. An association journal, however,
should rightly be expected to maintain an open policy that does not
ex ante privilege one form of research over another. In that
respect, the clearly stated policy of The Accounting Review of
seeking “any” and “all” is admirable. However, the continuing need to
make the case for research diversity is disappointing given the
longstanding recognition of the dangers of narrowness:
Reinforcing the above [stagnation and decline
of accounting research] is a tendency for senior accounting
academics to judge and reward the performance of juniors on the
basis of a narrow definition of what constitutes academic
accounting. (Demski
et al. 1991, 4–5)
With regard to The
Accounting Review, recent years have seen considerable efforts to
enhance the diversity of research appearing in its pages. These efforts
have undoubtedly resulted in a higher level of research diversity than
that seen for most of the period since the current editorial policy was
published in 1989. In conference panels and other arenas of debate, the
case has been put that a journal can only publish as diverse sets of
papers as are submitted to it. Detailed reports of submissions and
acceptance rates are now prepared and published, demonstrating success
in this regard. The issue that continues to divide is that of the
requisite diversity of an editorial board to encourage the submission of
kinds of work that currently remain unsubmitted. Underlying the
continuing debates over this aspect of diversity is disagreement over
the implications of the caveat in the editorial policy, “as long as the
articles meet the standards established for publication in the journal.”
Debates around
this topic all too easily reduce to a false dichotomy between diversity
and quality, with diversity perceived as a threat to quality. Increased
diversity promises to increase the quality of the body of accounting
research, however. Accounting is a complex social phenomenon, and so our
understanding of it should be enhanced through the adoption of a diverse
set of research perspectives and approaches. Grasping accounting in all
its complexity is important from an intellectual perspective, but also
from the perspective of the ability of our research discipline to
contribute back to society (e.g.,
Flyvbjerg 2001). Diversity of research
approaches requires diversity in the proper estimation of quality and
validity of research, however (Ahrens
and Chapman 2006).
To help
structure my arguments around this central issue of the relationship
between research diversity and quality, I offer two frameworks in the
sections that follow. In doing so, I hope to help us to move toward a
situation in which research diversity in The Accounting Review
(and other journals) may become taken-for-granted practice, as well as
policy.
|
DIVERSITY FRAMED IN
U.S.-DOMINANT CATEGORIES |
The process of becoming
a published researcher is arduous and complex. Along the way, we pick up
a variety of tools and techniques. The expression “All-But-Dissertation”
reminds us that while tools and techniques are necessary for successful
research, they are not sufficient. Expertise and judgment are built up
over years of reading, observing the efforts of others, and trying
ourselves. Hopefully, as we go on, we become better able to make the
fine judgments required to distinguish between creative and fruitful
leeway in the application of established approaches, and their
misapplication. We become experts in assessing the validity of the kinds
of research with which we are familiar. Our hard-won understanding
naturally offers the starting point for our engagement with different
forms of research.
To illustrate this
point, let us look at an attempt to understand research diversity drawn
from outside the discipline of accounting.
Figure 1 is a
reproduction from the introduction from the editor to a special issue of
the Journal of Financial Economics entitled “Complementary
Research Methods.” This journal addresses a discipline that also has a
particularly strong tradition of a particular kind of research; namely,
economics-based capital markets research. The figure offers an
organizing framework for considering different research methods in
relation to this core audience. It distinguishes various kinds of
research methods in two dimensions: first, through their use of
privately or publicly available data, and second, through the large or
small size of their data sets.
Approaches to
research potentially vary in a vast number of ways. The point of the
figure is to distill these down to a manageable number. Simplification
is not per se a problem. Danger arises when the dimensions chosen
privilege the interests of one particular group of researchers over
those of another, however. Let us consider the designation of a case
study as having a small sample size, for example. This framing has been
seen also in accounting, with several journals in the past including
“small sample” sections that published such work. However, as clearly
put by
Anderson and Widener (2007), this is to assume
that the unit of analysis must always be company-level observations, and
this need not be the case.
This figure offers
a way for large sample, public data researchers to think about how other
forms of research might complement (contribute to) their own activities.
As such, this represents only a partial engagement in research
diversity. The framing of
Figure 1 adopts the interests of one subgroup.
In a U.S. context, it is commonly understood that in-depth field studies
might act as a precursor to subsequent testing through other methods
(e.g.,
Merchant 2008). While field studies sometimes
might play exactly this role, such work also has its own purposes that
are debated and developed within broad (frequently interdisciplinary)
communities of scholars. From the perspective of “complementarity,” as
seen in
Figure 1, these
other purposes might be considered irrelevant (e.g.,
Merchant 2008). From the perspective of
research diversity, and the building of a comprehensive understanding on
the nature and effects of accounting, these intentions need no scholarly
justification in relation to other forms of research.
In the next
section, I will offer a second framework for considering research
diversity from a perspective that is less overtly grounded in the
assumptions of any particular subgroup of researchers.
|
DIVERSITY FRAMED IN
TERMS OF DIFFERENT RESEARCH ASSUMPTIONS |
The framework
presented in
Figure 2 sets out a different way to
differentiate research based on its choices in two dimensions. The
language of the figure is couched in terms of the philosophy of science
and sociology; however, it is not new to the accounting literature (see,
for example,
Chua 1986). In its two dimensions,
Figure 2 offers summary labels for sets of
fundamental research choices, offering names for each possible
combination of these sets of choices.
This second
framework operates at a far higher level of abstraction than that seen
in
Figure 1. As previously noted, recent years
have seen increases in the diversity of research published in The
Accounting Review. That diversity notwithstanding, the entire
contents of The Accounting Review since the publication of its
current editorial statement (and the scope of research diversity
implicit in the categories of
Figure 1) fall within the bottom right-hand
cell in this second framework—Functionalist research.
Continued in Article
"Accounting Craftspeople versus Accounting
Seers: Exploring the Relevance and Innovation Gaps in Academic Accounting
Research," by William E. McCarthy, Accounting Horizons, December
2012, Vol. 26, No. 4, pp. 833-843 ---
http://aaajournals.org/doi/full/10.2308/acch-10313
Is accounting
research stuck in a rut of repetitiveness and irrelevancy? I would answer
yes, and I would even predict that both its gap in relevancy and its gap in
innovation are going to continue to get worse if the people and the
attitudes that govern inquiry in the American academy remain the same. From
my perspective in accounting information systems, mainstream accounting
research topics have changed very little in 30 years, except for the fact
that their scope now seems much more narrow and crowded. More and more
people seem to be studying the same topics in financial reporting and
managerial control in the same ways, over and over and over. My suggestions
to get out of this rut are simple. First, the profession should allow itself
to think a little bit normatively, so we can actually target practice
improvement as a real goal. And second, we need to allow new scholars a
wider berth in research topics and methods, so we can actually give the kind
of creativity and innovation that occurs naturally with young people a
chance to blossom.
The reasonable man adapts himself to
the world; the unreasonable one persists in trying to adapt the
world to himself. Therefore, all progress depends on the
unreasonable man —
George Bernard
Shaw (1903, Act IV)
Who provides you with
the best feedback on your current set of teaching materials and research
ideas? For me, at present, that ranked list would be: (1) knowledgeable
and creative practitioners who are seeking to improve their field of
practice, (2) young doctoral students and faculty from European or other
non-American programs in business informatics, (3) a few of my own
doctoral students from 15+ years ago, who teach and research in the same
areas of accounting systems that I do, and (4) my own undergraduate and
master's students. I do have systems, tax, and introductory colleagues
who provide accounting context for me, but my feedback list has notable
absences, like most of the mainstream Accounting and Information Systems
faculty at Michigan State University (MSU) and, indeed, faculty
throughout the U.S. accounting academy. Thirty years ago, those last two
forums tolerated widespread diversity in both teaching and research
ideas, but now those communities have coalesced into just a few approved
“areas,” none of which provide me with assistance on my methodological
and topical problems. Academic accounting most recently has been
developing more and more into an insular and myopic community with no
methodological and practice-oriented outsiders tolerated. Why is this?
Becoming
aware of how this narrowing of the accounting mind has hindered not just
accounting systems, but also academic accounting innovation in general,
American Accounting Association (AAA) president Gregory Waymire asked
for some “unreasonable” (in the Shavian sense quoted above) accounting
academics like me to address the low-innovation and low-relevance
problem in academic accounting. I promptly reframed this charge as a
question: “Is accounting research stuck in a rut of repetitiveness and
irrelevancy?” In the pages that follow, I intend to explore that
question from two perspectives: (1) methodological, and (2)
sociological. My inspiration for the first perspective is derived from
Buckminster Fuller plus Alan Newell and Herbert Simon. For the second,
my role model is Lee Smolin.
|
PUTTING A
(LIMITED) NORMATIVE MINDSET BACK INTO ACCOUNTING RESEARCH—THE
CASE FOR DESIGN SCIENCE AND BEYOND1 |
We should help create the future, not just
study the past. —
Paul Gray (Kock
et al. 2002, 339)
In March of 2008, two
very prominent and distinguished accounting academics—Michael H. Granof
of The University of Texas and Stephen A. Zeff of Rice University—noted
in The Chronicle of Higher Education that the research models
that were being produced by accounting academics were indeed rigorous by
the standards of statistical validity and logical positivism, but they
were also of very little practical import:
Starting in the 1960s, academic research on
accounting became methodologically supercharged … The results
however have been paradoxical … [as] those models have crowded out
other forms of investigation. The result is that professors of
accounting have contributed little to the establishment of new
practices and standards, have failed to perform a needed role as
watchdog of the profession, and have created a disconnect between
their teaching and research. (Granof
and Zeff 2008, A34)
Professors
Granof and Zeff (2008, A34) went on further to
note that “accounting researchers usually look backward rather than
forward” and that they, unlike medical researchers, seldom play a
significant role in the practicing profession. In general, the thrust of
the
Granof and Zeff (2008)
criticism was that the normative/positive pendulum in accounting
research had swung too far toward rear-view empiricism and
away from creation of promising new accounting methods, models, and
constructs. They appealed directly for expanding the set of acceptable
research methods to include those accepted in other disciplines well
respected for their scientific standing. Additionally,
Granof and Zeff (2008,
A34) noted that because accounting faculties “are associated with a
well-defined and recognized profession … [they] have a special
obligation to conduct research that is of interest and relevance to
[that] profession,” especially as the models of those practitioners
evolve to fit new postindustrial environments.
Similar concerns
were raised in the 1990s by the senior accounting scholar Richard
Mattessich (1995, 183) in his treatise
Critique of Accounting:
Academic accounting—like engineering, medicine, law, and so on—is
obliged to provide a range of tools for practitioners to choose
from, depending on preconceived and actual needs … The present gap
between practice and academia is bound to grow as an increasing
number of academics are being absorbed in either the modeling of
highly simplified (and thus unrealistic) situations or the testing
of empirical hypotheses (most of which are not even of instrumental
nature). Both of these tasks are legitimate academic concerns, and
this book must not be misinterpreted as opposing these efforts. What
must be opposed is the one-sidedness of this academic concern and,
even more so, the intolerance of the positive accounting theorists
toward attempts of incorporating norms (objectives) into the
theoretical accounting framework.
Mattessich, Zeff,
and Granof were followed most recently in the same vein by Robert
Kaplan (2011), who noted in the AAA 2010
Presidential Scholar Lecture that:
- most accounting
research for the past 40 years has been reactive in the sense
that it concentrates on studying existing practice, but does not
advance that practice; and
- accounting scholars
have missed opportunities to apply innovations from other
disciplines to important accounting issues—an especially noticeable
difference when compared with researchers from other professional
schools who understand gaps in practice and try to address them by
applying contemporary engineering and science.
In my opinion, these
weaknesses noted by Granof, Zeff, Mattessich, and Kaplan are
attributable primarily to the insularity and myopia of the American-led
accounting academy. Our research excludes practice and stifles
innovation because of the way our journals, doctoral programs, and
academic presentations are structured.
The Innovation Roadblock in
Accounting Systems
The rear-view
empiricism research malaise that all four of these scholars
attribute to accounting as a whole is especially present in its
technical subfield of accounting information systems (AIS). In fact,
it is even more exaggerated, because as time goes on, an
increasingly high percentage of AIS researchers aspire to develop
reputations not in the field they teach (i.e., accounting systems),
but in the accounting mainstream (i.e., financial reporting). Thus,
they follow many of the misdirected paths described above, and their
results are similarly disappointing. With some notable
exceptions—primarily in work that involves semantic modeling of
accounting phenomena or computerized monitoring and
auditing—university-driven modernization in accounting systems has
been virtually nonexistent since the 1970s, and what limited
improvements that have occurred can be primarily attributed to the
independent practice marketplace.
Continued in article
"Is Accounting Research Stagnant?" by
Donald V. Moser, Accounting Horizons, December 2012, Vol. 26, No. 4, pp.
845-850 ---
http://aaajournals.org/doi/full/10.2308/acch-10312
I accepted
the invitation to present my thoughts to the American Accounting
Association Executive Committee on whether accounting research has
become stagnant for several reasons. First, I believe the question is
important because the answer has widespread implications, one of which
is the extent to which accounting research will remain an important part
of the accounting academic profession in the years to come. In order to
maintain the current stature of accounting research or to increase its
importance, we need to ensure that we produce research that someone
cares about. Second, there appears to be a growing sentiment among some
accounting researchers that much of the research currently published in
the top accounting journals is too similar, with too much emphasis on
technique rather than on whether the research addresses an interesting
or important question. My final reason was more self-serving. I thought
this would provide a good opportunity to reflect on an important issue,
and that committing to share my thoughts in a public forum would force
me to give the issue the serious consideration it warrants. My comments
below describe some conclusions I reached based on what others have
written about this issue, discussions with colleagues, and my own
reflections.
|
HAS ACCOUNTING
RESEARCH STAGNATED? |
My answer to the
question of whether accounting research has become stagnant is a
qualified “yes.” I qualify my answer because I do not believe that our
research is entirely stagnant. Looking at the issue from a historical
perspective, accounting research has, in fact, evolved considerably over
time. In other words, as described quite eloquently recently by
Hopwood (2007),
Birnberg (2009), and
Kaplan (2011), accounting research has an
impressive history of change. While each of these scholars has their own
views on what type of accounting research we should focus on now and in
the future, each also describes a rich history of how we evolved to get
where we are today.
In addition to the
longer-term history of change, there has been substantial recent change
in the perspectives reflected in accounting research and the topics now
considered acceptable in accounting research. It was not that long ago
that accounting studies that hypothesized or documented behavior that
was inconsistent with the rational self-interest assumptions of
neoclassical economics had a difficult time finding a publication outlet
in the top accounting journals. Today, thanks mostly to the rise of
behavioral economics, we see more experimental, analytical, and archival
research that incorporates concepts from behavioral economics and
psychology published in most of the top accounting journals. Recently,
we have even seen work on neuroaccounting, which draws on findings from
neuroscience, make its way into accounting journals (Dickhaut
et al. 2010;
Birnberg and Ganguly 2012).
We also have seen new topics appear in published accounting research.
For example, while there is a history of work on corporate social
responsibility in Accounting, Organizations and Society, more
recently, we have seen increased interest in such work as evidenced by
articles published or forthcoming in The Accounting Review
(Simnett
et al. 2009;
Balakrishnan et al. 2011;
Dhaliwal et al. 2011;
Kim et al. 2011;
Dhaliwal et al. 2012;
Moser and Martin 2012). In addition, The
Harvard Business School, in collaboration with the Journal of
Accounting and Economics, recently announced that they will host a
conference on “Corporate Accountability Reporting” in 2013.1
However, despite
evidence of both historical and more recent change, there is also
considerable evidence of stagnation in accounting research. For example,
despite some new topics appearing in accounting journals, a considerable
amount of the published work still relates to a limited group of topics,
such as earnings management, analysts' or management forecasts,
compensation, regulation, governance, or budgeting. Researchers also
mostly use the same research methods, with archival studies being most
prevalent, and experimental studies running a distant second. The
underlying theories used in mainstream U.S. accounting research are also
quite limited, with conventional economic theory being the most commonly
employed theory, but, as noted above, behavioral economic and
psychological theories becoming more common in recent years. While the
top accounting journals have become more open to new perspectives in
recent years, the list of top journals has changed little, with the
exception of the rise of the Review of Accounting Studies.
Moreover, with the exception of some of the American Accounting
Association journals, the top private U.S. accounting journals have
mostly retained a somewhat narrow focus in terms of the type of research
they typically publish. Finally, many published studies represent minor
extensions of previous work, have limited or no tension in their
hypotheses (i.e., they test what almost certainly must be true), have
limited implications, and are metric or tool driven. Regarding the
second-to-last item, i.e., limited implications, many studies now only
claim to “extend the literature,” with no discussion of who, other than
a limited number of other researchers working in the same area, might be
interested in the study's findings. Regarding the last item, i.e.,
metric-driven research, some studies appear to be published simply
because they used all the latest and best research techniques, even
though the issue itself is of limited interest.
Of course,
as with most issues, there are opposing views. Some accounting
researchers disagree with the premise that our research is stagnant.
Specifically, they believe that the methods and theories currently used
are the best methods and theories, and that the top-ranked accounting
journals are the best journals because they publish the best research.
Under this view, there is little need for more innovative research.
Whether such views are correct or simply represent a preference for the
status quo is beyond the scope of this article. Suffice to say
that my personal views on these issues are mixed, but I agree somewhat
more with the view that accounting research is insufficiently
innovative.
|
DETERRENTS TO
INNOVATION IN ACCOUNTING RESEARCH |
To the extent that
accounting research lacks innovation, the question is what has brought
us to this point? There appears to be considerable blame to spread
around. One of the biggest culprits is the incentive system that
accounting researchers face (Swanson
2004). In order to earn tenure or promotion,
or even simply to receive an annual pay increase, researchers must
publish in the top accounting journals and be cited by other researchers
who publish in those same journals (Merchant
2010). Researchers' publication record and
related citations depend critically on the views of editors and
reviewers with status quo training and preferences, and the speed
with which manuscripts make their way through the review process. Not
surprisingly, this leads most researchers to limit the topics they study
and make their studies as acceptable to status quo editors and
reviewers as possible. This is the safest way to increase the number of
papers published in top journals, which, in turn, increases the
likelihood of citations by others who publish in those journals. Also,
the constant pressures to publish more articles in top journals, teach
more or new courses, improve teacher ratings, and provide administrative
service to the school leaves little time for innovative research. It is
easier to simply do more of the same because this increases the odds of
satisfying the requirements of the school's incentive system.
A second
impediment to innovative research is the way we train doctoral students.
Too often, faculty advisors clone themselves. While such mentor
relationships have many benefits, insisting that doctoral students view
the world in the same way a faculty advisor does perpetuates the
status quo. Also, most doctoral students take the same set of
courses in economics, statistics, etc., and usually before they take
accounting seminars. Again, while such methods training is essential, if
all doctoral students take virtually all of the same courses, they are
less likely to be exposed to alternative views of the world. Finally, in
recent years, more doctoral students enter their programs with strong
technical skills in economics, quantitative techniques, and statistical
analysis, but many now lack professional accounting experience.2
Because such students prefer to engage in research projects that apply
the skills they have, they tend to view research in terms of the
techniques they can apply rather than stepping back to consider whether
the research question is novel or important.
A third impediment to
innovative research may involve the types of individuals who are
attracted to accounting as a profession or research area. Accountants
tend to like clarity and focus. Indeed, we often train our undergraduate
or master's students to work toward a “right answer.” This raises the
possibility that accountants are less innovative by nature than
researchers in some other areas. Similarly, some accountants have a
narrow definition of accounting. Some think of it as only financial
accounting, and even those who define it more broadly as including
managerial accounting, auditing, and tax, still tend to rigidly
compartmentalize accounting into such functional areas. Such rigid
categories limit the areas that accounting researchers consider to be
appropriate for accounting research.
A final
reason why accounting research is less innovative than it could be is
that accounting researchers do not collaborate with researchers who
employ different research methods or with researchers outside of
accounting as often as they could. We tend to work with researchers who
use the same research methods we do. That is, archival researchers
typically collaborate with other archival researchers, and experimental
researchers typically collaborate with other experimentalists. Moreover,
only rarely do we branch out to work with researchers in other areas of
business (e.g., organizational behavior, strategy, ethics, economics, or
finance), and even less frequently with researchers from areas outside
of business (e.g., psychology, decision sciences, law, political
science, neuroscience, anthropology, or international studies).
|
WHAT CAN WE DO TO
FOSTER INNOVATION? |
To the extent that
accounting research is less innovative than it could be for some or all
of the reasons offered above, what can be done to change this? I divide
my discussion of this issue into two categories: (1) actions that we,
the broader research community, could take, and (2) actions that the
American Accounting Association could take. Accounting faculty members
at schools with doctoral programs could rethink how we recruit doctoral
students. Currently, we tend to recruit students who have a good fit
with research active faculty members who are likely to serve as the
students' faculty advisor. Of course, this makes perfect sense because a
mismatch tends to be very costly for both the student and the faculty
advisor. On the other hand, this approach tends to produce clones of the
faculty advisor. So, unless the faculty advisor values innovation, the
chances that the doctoral student will propose or be allowed to pursue a
new line of research are significantly reduced. Perhaps we need to
assess prospective doctoral students, at least partially, on the novelty
of their thinking. More importantly, we need to be more open to new
ideas our students propose and encourage and support such ideas, rather
than discourage novel thinking. Of course, a faculty advisor would be
remiss not to explain the risks of doing something different, but along
with explaining the risks, we could point out the potential rewards of
being first out of the gate on a new topic and the personal sense of
fulfillment that accompanies doing something you believe in and enjoy.
Faculty advisors could also lead by example. Senior faculty could take
some risks of their own to show junior faculty and doctoral students
that this is acceptable rather than frowned upon.
Continued in article
"How Can Accounting Researchers Become More
Innovative? by Sudipta Basu, Accounting Horizons, December 2012, Vol.
26, No. 4, pp. 851-87 ---
http://aaajournals.org/doi/full/10.2308/acch-10311
We fervently hope that the research
pendulum will soon swing back from the narrow lines of inquiry
that dominate today's leading journals to a rediscovery of the
richness of what accounting research can be. For that to occur,
deans and the current generation of academic accountants must
give it a push.—
Michael H. Granof and Stephen A. Zeff
(2008)
Rather
than clinging to the projects of the past, it is time to explore
questions and engage with ideas that transgress the current
accounting research boundaries. Allow your values to guide the
formation of your research agenda. The passion will inevitably
follow —
Joni J.
Young (2009)
Are most
accounting academics and professionals excited when they receive the
latest issue of The Accounting Review or an email of the Table of
Contents? When I was a doctoral student and later an assistant
professor, I looked forward to receiving new issues of top accounting
journals. But as my research horizons widened, I found myself less
interested in reading a recent issue of an accounting journal than one
in a nearby discipline (e.g., Journal of Law and Economics), or
even a discipline further away (e.g., Evolution and Human Behavior).
Many accountants find little insight into important accounting issues in
the top U.S. academic journals, which critics allege focus on arcane
issues that interest a narrowing readership (e.g.,
Sterling 1976;
Garcha et al. 1983;
Flesher 1991;
Heck and Jensen 2007).1
Several prominent
scholars raise concerns about recent accounting research. Joel
Demski's 2001 American Accounting Association
(AAA) Presidential Address acknowledges the excitement of the mid-20th
century advances in accounting research, but notes, “Of late, however, a
malaise appears to have settled in. Our progress has turned flat, our
tribal tendencies have taken hold, and our joy has diminished.” The
state of current U.S. accounting scholarship has been questioned
repeatedly by recent AAA presidents, including Judy
Rayburn (2006), Shyam
Sunder (2006), Sue
Haka (2008), and Greg
Waymire (2012).2
Assuming that when
there is smoke there is likely a fire, I adopt a “glass-half-empty”
lens.3
I diagnose the problems in our discipline after briefly outlining a few
long-term causes for the symptoms identified by critics. I seek remedies
for the more urgent symptoms, drawing upon examples from other
disciplines that are exploring ways to reinvigorate scholarship and
restore academic relevance. While a few of these can be implemented by
AAA, many others can be adopted by journal editors and authors. I hope
that these personal views stimulate conversations that lead to better
accounting scholarship.
My main
suggestion is to re-orient accounting researchers toward addressing
fundamental accounting questions, and to provide awards and incentives
for innovative leadership, rather than for passively following
accounting standard-setters. This will require educating young scholars
in accounting history as well as the history of accounting thought. In
addition, AAA annual meetings should feature a named lecture by an
eminent non-accounting scholar to expose us to new ideas and methods. We
should rely less on statistical significance for assessing importance
and instead emphasize practical significance in judging the value of a
research contribution. Accounting research should be made more
accessible to practitioners, interested laymen, and academic colleagues
in other disciplines by improving readability—for example by making
articles shorter and less jargon laden, and replacing tables with more
informative figures. Finally, we should more actively seek out and
explore accounting domains beyond those captured in machine-readable
databases.
|
WHAT ARE THE
SYMPTOMS? WHAT IS THE DIAGNOSIS? |
Demski (2007) and
Fellingham (2007) contend that accounting is
not an academic research discipline that contributes knowledge to the
rest of the university. This assertion is supported by predominantly
one-way citation flows between accounting journals and those of
neighboring disciplines (Lee
1995;
Pieters and Baumgartner 2002;
Bricker et al. 2003;
Rayburn 2006). Such sentiments imply low
status of the accounting professoriate within the academy, and echo
those of
Demski et al. (1991),
Zeff (1989),
Sterling (1973), and, from longer ago,
Hatfield (1924). Furthermore, and perhaps of
greater concern, accounting research has little impact on accounting
practice, and the divergence between accounting research and accounting
practice has been growing over the last half century (e.g.,
Langenderfer 1987;
Baxter 1988;
Bricker and Previts 1990).
What other
symptoms have critics identified?
Demski (2008) highlights the lack of passion
in many accounting researchers, while
Ball (2008) bemoans the “absence of a solidly
grounded worldview—a deep understanding of the functioning of financial
reporting in the economy” among accounting professors and doctoral
students alike.
Kaplan (2011) suggests that accounting
research is predominantly conducted in an ivory tower with little
connection to problems faced by practitioners, whereas
Sunder (2007) argues that mandatory uniform
standards suppress thinking among accounting researchers, echoing
Baxter (1953).
Kinney (2001) submits that accounting
researchers are not sure about which research domains are ours.
Demski et al. (1991)
raised all these concerns previously, implying that accounting research
has been stagnant for decades. No wonder I (and others) find too many
recent accounting papers to be tedious and uninteresting.
A simplistic
diagnosis is that U.S. accounting research mimics the concerns and mores
of the U.S. accounting profession. The accounting profession in the
middle of the 20th century searched for principles underlying accounting
practices, which provided a demand for normative academic theories.
These demands were met by accounting classics such as
Gilman (1939),
Paton and Littleton (1940), and
Edwards and Bell (1961). Although standards
were originally meant to guide accounting practice, standard-setters
soon slid down the slippery slope of enforceable rules (Baxter
1979). Consequently, ever more detailed rules
were written to make reported numbers more reliable. Bureaucrats wanted
to uniformly enforce explicit protocols, which lawyers creatively
interpreted and financial engineers circumvented with new contracts. In
parallel, accounting researchers abandoned normative debates and turned
to measuring and evaluating the effects of alternative accounting rules
and attempts to evade them (e.g.,
Zeff 1978). In sum, as U.S. GAAP moved from
norm based to rule based, or from emphasizing relevance to increasing
uniformity and reliability, accounting researchers began favoring formal
quantitative methods over informal qualitative arguments. As U.S. GAAP
and the Internal Revenue Code became ever more arcane, so did U.S.
accounting research.
Another diagnosis
is that our current state stems from accounting trying to become a more
scientific discipline. During 1956–1964, the Ford Foundation gave
Carnegie Mellon, Chicago, Columbia, Harvard, and Stanford $14.4 million
to try to make their business schools centers of excellence in research
and teaching (Khurana
et al. 2011). Contributions from other
foundations raised the total to $35 million (Jeuck
1986), which would be about $268 million in
2012 dollars.4
The Ford Foundation espoused quantitative methods and economics with a
goal of making business research more “scientific” and “professional” (Gordon
and Howell 1959). Business schools responded
by emphasizing statistical analyses and mathematical modeling, and
mathematical training rather than accounting knowledge became
increasingly required for publications in the top accounting journals
(e.g.,
Chua 1996;
Heck and Jensen 2007). While business
researchers had some notable successes in the 1960s and 1970s soon after
introducing these new techniques, the rate of innovation has allegedly
since fallen.
Concurrently, U.S.
business schools became credentialing machines guided by a “(student)
customer is always right” ethos, so there was also less demand for
accounting theory from accounting students and their employers (Demski
2007), and intermediate accounting textbooks
replaced theory with rote memorization of rules (Zeff
1989).5
In 1967, the American Assembly of Collegiate
Schools of Business (AACSB) increased the degree requirements for
accredited accounting faculty from a master's-CPA combination to a
Ph.D., effective in 1969. Many accounting doctoral programs were started
in the 1960s to meet the new demand for accounting doctorates (Rodgers
and Williams 1996), and these programs imitated the new elite
accounting programs. Statistics, economics, and econometrics screening
became requisite challenges (Zeff
1978), preceding accounting courses in many
doctoral programs. Unsurprisingly then, doctoral students came to infer
that accounting theory and institutional content are merely the icing on
the cake of quantitative economics or psychology.
In
summary, the forces that induced change in U.S. accounting academe in
the aftermath of World War II still prevail. The goals and methods of
accounting research have changed profoundly over the last half century
(e.g.,
Zeff 1978), leading accounting researchers to more Type III error
(e.g.,
Dyckman 1989): “giving the right answer to the
wrong problem” (Kimball
1957) or “solving the wrong problem precisely”
(Raiffa
1968). To the extent that accounting relevance
has been sacrificed for tractability and academic rigor, these changes
have slowed accounting-knowledge generation.
|
HOW CAN ACCOUNTING
RESEARCH BECOME MORE INNOVATIVE? |
Demski (2007) characterizes recent accounting
research thus: “Innovation is close to nonexistent. This, in fact, is
the basis for the current angst about the ‘diversity' of our major
publications. Deeper, though, is the mindset and factory-like mentality
that is driving this visible clustering in the journals.” He laments
further, “The vast bulk of our published work is insular, largely
derivative, and lacking in the variety that is essential for innovation.
Arguably, our published work is focusing increasingly on job placement
and retention.”
Demski et al. (1991) conjecture, “Accounting
researchers apparently suffer from insecurity about their field of
study, leading them to perturb fairly secure research paradigms (mostly
those that have been accepted by economists) within an ever-narrowing
circle of accounting academics isolated from the practice world. There
is very little reward in the current academic system for experimentation
and innovation that has the potential for impacting practice.” My sense
is that many accounting researchers (especially those who have not
practiced accounting) believe that the conceptual framework has resolved
all fundamental accounting issues and that accounting researchers should
help regulators fill in the technical details to implement their grand
plan. As blinkers keep horses focused on the road ahead, the current
conceptual framework blinds accounting academics to the important issues
in accounting (especially the many flaws in the conceptual framework
project).
Identifying the
major unsolved questions in a field can provide new directions for
research quests as well as a framework for teaching. For example,
Hilbert (1900) posed 23 unsolved problems for
mathematicians to test themselves against over the 20th century. His
ideas were so successful in directing subsequent mathematics research
that $1 million Millennium Prizes have been established for seven
unsolved mathematical questions for the current century.6
Many scientific disciplines compile lists of
unsolved questions for their fields in an attempt to imitate the success
of 20th century mathematics.7
There is even a new series of books titled, The Big Questions: xxx,
where xxx is philosophy (Blackburn
2009), physics (Brooks
2010), the universe (Clark
2010), etc. The series “is designed to let
renowned experts confront the 20 most fundamental and frequently asked
questions in a major branch of science or philosophy.” There is,
however, neither consensus nor much interest in addressing the big
unanswered questions in accounting, let alone exploring and refining
them, recent attempts notwithstanding (e.g.,
Ball 2008;
Basu 2008;
Robinson 2007).
Few accounting
professors can identify even a dozen of the 88 members of the Accounting
Hall of Fame, let alone why they were selected as “having made or are
making significant contributions to the advancement of accounting.”8
Since many doctoral syllabi concentrate on recent publications to
identify current research frontiers, most recent doctoral graduates have
read just a handful of papers published before 2000. This leaves new
professors with little clue to the “most fundamental and frequently
asked questions” of our discipline. The American Economic Association
recently celebrated the centenary of The American Economic Review
by appointing a Top 20 Committee to select the “top 20” articles
published in the journal over the previous 100 years (Arrow
et al. 2011). Similarly, the Financial
Analysts Journal picked the best articles over its first 50 years
(Harlow
1995). Accounting academics could similarly
identify the top 20 articles published in the first 100 years of The
Journal of Accountancy (1905–2004), the top 25 articles published in
Accountancy (1880–2005), or proportionately fewer papers for
The Accounting Review (1926–2011).
If accounting
researchers do not tackle the fundamental issues in accounting, we
collectively face obsolescence, irrelevance, and oblivion.9
Demski et al. (1991)
recommended identifying a “broad set of challenging, relevant research
questions” to be distributed to seasoned researchers to develop detailed
research proposals that would be presented at a “proposals conference,”
with the proceedings distributed widely among accounting academics. Lev
(1992) commissioned several veteran researchers, including Michael
Brennan (Finance) and Daniel Kahneman (Psychology), to write detailed
research proposals on “Why is there a conservatism bias in financial
reporting?” Eight proposals were presented at a plenary session of the
1993 AAA Annual Meeting in San Francisco, and copies of the research
proposals were included in the packets of all annual meeting attendees.
This initiative provided the impetus for conservatism research over the
last two decades (cf.
Basu 2009).
Continued in article
January 3, 2013 Reply from Bill McCarthy
Hi Bob:
In complaining about the lack of a connection between the Accounting
Horizons commentaries and the Pathways Commission, your timing is off. The
commentaries were based on presentations given in May of 2011. I certainly
updated my commentary earlier this year, but the final versions were all
submitted months before the release of Pathways at the AAA meeting January
in August. I certainly knew many involved people (especially Julie David,
Mark Nittler, and Brian Sommer), but the first time I saw the report was
when I picked up my AAA packet in Washington. If you want to see how to
connect my commentary to Pathways, I would recommend looking at the AAA
video from the annual meeting "The Pathways Commission -- Creating
Connections ...." It is available on AAA Commons. Julie, Cheryl Dunn, and
I relate our own work in semantic modeling of accounting phenomena (REA
modeling) to practice, teaching, and research as a good example of what
academics could be like if Pathways recommendations are taken seriously. I
think the whole video is worth watching, including the Q&A, but of course I
was a participant, so you can judge for yourself. Unfortunately, we could
not have Mark in Washington as a fourth participant, but his current ideas
were well summarized in the video that Julie showed. Alternatively, you
could look at:
http://blogs.workday.com/Blog/time_is_right_to_modernize_400_year_old_accounting_practices.html
I suspect that some of the other commentators might
have augmented their papers as well, if we were all aware of the full
Pathways set of recommendations. I certainly do not fear Pathways, I am an
ardent supporter. As I say on the video, my only misgivings are associated
with the realization that Pathways implementations might cause unreasonable
troublemakers (adopted AH terms) like me to prosper. I am not sure academic
accounting could accommodate such a deluge of deliberately wayward behavior
in such a short time.
Bill McCarthy
Michigan State
January 3, 2013 reply from Bob Jensen
I think the essays themselves deal very well with issues of
research/scholarship diversity and need for innovation. At the same time
they are weak with respect to promoting more integration between the
profession and researcher/scholars who rarely venture from the campus to
discover research most of interest to the profession.
Gasp! How could an accountics scientist question such things? This is
sacrilege!
Let me end my remarks with a question: Have Ball and
Brown (1968)—and Beaver (1968) for that matter, if I can bring Bill Beaver into
it—have we had too much influence on the research agenda to the point where
other questions and methods are being overlooked?
Phil Brown of Ball and Brown Fame
"How Can We Do Better?" by Phillip R. Brown (of Ball and Brown Fame),
Accounting Horizons (Forum on the State of Accounting Scholarship),
December 2013 ---
http://aaajournals.org/doi/full/10.2308/acch-10365
Not Free
Philip R. Brown AM is an Honorary Professor at The
University of New South Wales and Senior Honorary Research Fellow at The
University of Western Australia.
I acknowledge the thoughtful comments of Sudipta Basu,
who arranged and chaired this session at the 2012 American Accounting
Association (AAA) Annual Meeting, Washington, DC.
The video presentation can be accessed by clicking the
link in Appendix A.
Corresponding author: Philip R. Brown AM.
Email:
philip.brown@uwa.edu.au
When Sudipta Basu asked me whether I
would join this panel, he was kind enough to share with me the proposal
he put to the conference organizers. As background to his proposal,
Sudipta had written:
Analytical and
empirical researchers generate numerous results about accounting, as
do logicians reasoning from conceptual frameworks. However, there
are few definitive tests that permit us to negate propositions about
good accounting.
This panel aims to
identify a few “most wrong” beliefs held by accounting
experts—academics, regulators, practitioners—where a “most wrong”
belief is one that is widespread and fundamentally misguided about
practices and users in any accounting domain.
While Sudipta's proposal resonated
with me, I did wonder why he asked me to join the panel, and whether I
am seen these days as just another “grumpy old man.” Yes, I am no doubt
among the oldest here today, but grumpy? You can make your own mind on
that, after you have read what I have to say.
This essay begins with
several gripes about editors, reviewers, and authors, along with
suggestions for improving the publication process for all concerned. The
next section contains observations on financial accounting standard
setting. The essay concludes with a discussion of research myopia,
namely, the unfortunate tendency of researchers to confine their work to
familiar territory, much like the drunk who searches for his keys under
the street light because “that is where the light is.”
|
ON EDITORS AND REVIEWERS, AND
AUTHORS |
I have never been a regular editor,
although I have chaired a journal's board of management and been a guest
editor, and I appointed Ray Ball to his first editorship (Ray was the
inaugural editor of the Australian Journal of Management). I
have, however, reviewed many submissions for a whole raft of journals,
and written literally hundreds of papers, some of which have been
published. As I reflect on my involvement in the publications process
over more than 50 years, I do have a few suggestions on how we can do
things better. In the spirit of this panel session, I have put my
suggestions in the form of gripes about editors, reviewers, and authors.
One-eyed editors—and reviewers—who
define the subject matter as outside their journal's interests are my
first gripe; and of course I except journals with a mission that is
stated clearly and in unequivocal terms for all to see. The best editors
and the best reviewers are those who are open-minded who avoid
prejudging submissions by reference to some particular set of questions
or modes of thinking that have become popular over the last five years
or so. Graeme Dean, former editor of Abacus, and Nick Dopuch,
former editor of the Journal of Accounting Research, are fine
examples, from years gone by, of what it means to be an excellent
editor.
Editors who are reluctant to entertain
new ways of looking at old questions are a second gripe. Many years ago
I was asked to review a paper titled “The Last Word on …” (I will not
fill in the dots because the author may still be alive.) But at the time
I thought, what a strange title! Can any academic reasonably believe
they are about to have the last say on any important accounting issue?
We academics thrive on questioning previous works, and editors and their
reviewers do well when they nurture this mindset.
My third gripe concerns editors who,
perhaps unwittingly, send papers to reviewers with vested interests and
the reviewers do not just politely return the paper to the editor and
explain their conflict of interest. A fourth concerns editors and
reviewers who discourage replications: their actions signal a
disciplinary immaturity. I am referring to rejecting a paper that
repeats an experiment, perhaps in another country, purely because it has
been done before. There can be good reasons for replicating a study, for
example if the external validity of the earlier study legitimately can
be questioned (perhaps different outcomes are reasonably expected in
another institutional setting), or if methodological advances indicate a
likely design flaw. Last, there are editors and reviewers who do not
entertain papers that fail to reject the null hypothesis. If the
alternative is well-reasoned and the study is sound, and they can be big
“ifs,” then failure to reject the null can be informative, for it may
indicate where our knowledge is deficient and more work can be done.1
It is not only editors and reviewers
who test my emotional state. I do get a bit short when I review papers
that fail to appreciate that the ideas they are dealing with have long
yet uncited histories, sometimes in journals that are not based in North
America. I am particularly unimpressed when there is an
all-too-transparent and excessive citation of works by editors and
potential reviewers, as if the judgments of these folks could possibly
be influenced by that behavior. Other papers frustrate me when they are
technically correct but demonstrate the trivial or the obvious, and fail
to draw out the wider implications of their findings. Then there are
authors who rely on unnecessarily coarse “control” variables which, if
measured more finely, may well threaten their findings.2
Examples are dummy variables for common law/code law countries, for
“high” this and “low” that, for the presence or absence of an
audit/nomination/compensation committee, or the use of an industry or
sector variable without saying which features of that industry or sector
are likely to matter and why a binary representation is best. In a
nutshell, I fear there may be altogether too many dummies in financial
accounting research!
Finally, there are the
International Financial Reporting Standards (IFRS) papers that fit into
the category of what I describe as “before and after studies.” They
focus on changes following the adoption of IFRS promulgated by the
London-based International Accounting Standards Board (IASB). A major
concern, and I have been guilty too, is that these papers, by and large,
do not deal adequately with the dynamics of what has been for many
countries a period of profound change. In particular, there is a
trade-off between (1) experimental noise from including too long a
“before” and “after” history, and (2) not accommodating the process of
change, because the “before” and “after” periods are way too short.
Neither do they appear to control convincingly for other time-related
changes, such as the introduction of new accounting and auditing
standards, amendments to corporations laws and stock exchange listing
rules, the adoption of corporate governance codes of conduct, more
stringent compliance monitoring and enforcement mechanisms, or changes
in, say stock, market liquidity as a result of the introduction of new
trading platforms and protocols, amalgamations among market providers,
the explosion in algorithmic trading, and the increasing popularity
among financial institutions of trading in “dark pools.”
|
ON FINANCIAL ACCOUNTING STANDARD
SETTING |
I count a number of highly experienced
financial accounting standard setters among my friends and professional
acquaintances, and I have great regard for the difficulties they face in
what they do. Nonetheless, I do wonder
. . .
A not uncommon belief among academics
is that we have been or can be a help to accounting standard setters. We
may believe we can help by saying something important about whether a
new financial accounting standard, or set of standards, is an
improvement. Perhaps we feel this way because we have chosen some
predictive criterion and been able to demonstrate a statistically
reliable association between accounting information contained in some
database and outcomes that are consistent with that criterion. Ball and
Brown (1968, 160) explained the choice of criterion this way: “An
empirical evaluation of accounting income numbers requires agreement as
to what real-world outcome constitutes an appropriate test of
usefulness.” Note their reference to a requirement to agree on the test.
They were referring to the choice of criterion being important to the
persuasiveness of their tests, which were fundamental and related to the
“usefulness” of U.S. GAAP income numbers to stock market investors 50
years ago. As time went by and the financial accounting literature grew
accordingly, financial accounting researchers have looked in many
directions for capital market outcomes in their quest for publishable
results.
Research on IFRS can be used to
illustrate my point. Those who have looked at the consequences of IFRS
adoption have mostly studied outcomes they believed would interest
participants in equity markets and to a less extent parties to debt
contracts. Many beneficial outcomes have now been claimed,4
consistent with benefits asserted by advocates of IFRS. Examples are
more comparable accounting numbers; earnings that are higher “quality”
and less subject to managers' discretion; lower barriers to
international capital flows; improved analysts' forecasts; deeper and
more liquid equity markets; and a lower cost of capital. But the
evidence is typically coarse in nature; and so often the results are
inconsistent because of the different outcomes selected as tests of
“usefulness,” or differences in the samples studied (time periods,
countries, industries, firms, etc.) and in research methods (how models
are specified and variables measured, which estimators are used, etc.).
The upshot is that it can be difficult if not impossible to reconcile
the many inconsistencies, and for standard setters to relate reported
findings to the judgments they must make.
Despite the many largely capital
market outcomes that have been studied, some observers of our efforts
must be disappointed that other potentially beneficial outcomes of
adopting IFRS have largely been overlooked. Among them are the wider
benefits to an economy that flow from EU membership (IFRS are required),5
or access to funds provided by international agencies such as the World
Bank, or less time spent by CFOs of international companies when
comparing the financial performance of divisions operating in different
countries and on consolidating the financial statements of foreign
subsidiaries, or labor market benefits from more flexibility in the
supply of professionally qualified accountants, or “better” accounting
standards from pooling the skills of standard setters in different
jurisdictions, or less costly and more consistent professional advice
when accounting firms do not have to deal with as much cross-country
variation in standards and can concentrate their high-level technical
skills, or more effective compliance monitoring and enforcement as
regulators share their knowledge and experience, or the usage of IFRS by
“millions (of small and medium enterprises) in more than 80 countries” (Pacter
2012), or in some cases better education of tomorrow's accounting
professionals.6
I am sure you could easily add to this list if you wished.
In sum, we can help standard setters,
yes, but only in quite limited ways.7
Standard setting is inherently political in nature and will remain that
way as long as there are winners and losers when standards change. That
is one issue. Another is that the results of capital markets studies are
typically too coarse to be definitive when it comes to the detailed
issues that standard setters must consider. A third is that accounting
standards have ramifications extending far beyond public financial
markets and a much more expansive view needs to be taken before we can
even hope to understand the full range of benefits (and costs) of
adopting IFRS.
Let me end my remarks
with a question: Have Ball and Brown (1968)—and Beaver (1968) for that
matter, if I can bring Bill Beaver into it—have we had too much
influence on the research agenda to the point where other questions and
methods are being overlooked?
February 27, 2014 Reply from Paul Williams
Bob,
If you read that last Horizon's section provided by "thought leaders" you
realize the old guys are not saying anything they could not have realized 30
years ago. That they didn't realize it then (or did but was not in their
interest to say so), which led them to run journals whose singular purpose
seemed to be to enable they and their cohorts to create politically correct
academic reputations, is not something to ask forgiveness for at the end of
your career.
Like the sinner on his deathbed asking
for God's forgiveness , now is a hell of a time to suddenly get religion. If
you heard these fellows speak when they were young they certainly didn't
speak with voices that adumbrated any doubt that what they were doing was
rigorous research and anyone doing anything else was the intellectual hoi
polloi.
Oops, sorry we created an academy that
all of us now regret, but, hey, we got ours. It's our mess, but now we are
telling you its a mess you have to clean up. It isn't like no one was saying
these things 30 years ago (you were as well as others including yours truly)
and we have intimate knowledge of how we were treated by these geniuses
David Johnstone asked me to write a paper on the following:
"A Scrapbook on What's Wrong with the Past, Present and Future of Accountics
Science"
Bob Jensen
February 19, 2014
SSRN Download:
http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2398296
Abstract
For operational convenience I define accountics science as
research that features equations and/or statistical inference. Historically,
there was a heated debate in the 1920s as to whether the main research
journal of academic accounting, The Accounting Review (TAR) that
commenced in 1926, should be an accountics journal with articles that mostly
featured equations. Practitioners and teachers of college accounting won
that debate.
TAR articles and accountancy doctoral dissertations prior to
the 1970s seldom had equations. For reasons summarized below, doctoral
programs and TAR evolved to where in the 1990s there where having equations
became virtually a necessary condition for a doctoral dissertation and
acceptance of a TAR article. Qualitative normative and case method
methodologies disappeared from doctoral programs.
What’s really meant by “featured
equations” in doctoral programs is merely symbolic of the fact that North
American accounting doctoral programs pushed out most of the accounting to
make way for econometrics and statistics that are now keys to the kingdom
for promotion and tenure in accounting schools ---
http://faculty.trinity.edu/rjensen/Theory01.htm#DoctoralPrograms
The purpose of this paper is to make a case that the accountics science
monopoly of our doctoral programs and published research is seriously
flawed, especially its lack of concern about replication and focus on
simplified artificial worlds that differ too much from reality to creatively
discover findings of greater relevance to teachers of accounting and
practitioners of accounting. Accountics scientists themselves became a Cargo
Cult.
Shielding Against Validity Challenges in Plato's Cave ---
http://faculty.trinity.edu/rjensen/TheoryTAR.htm
Common Accountics Science and Econometric Science Statistical Mistakes ---
http://www.cs.trinity.edu/~rjensen/temp/AccounticsScienceStatisticalMistakes.htm
The Cult of Statistical Significance:
How Standard Error Costs Us Jobs, Justice, and Lives ---
http://www.cs.trinity.edu/~rjensen/temp/DeirdreMcCloskey/StatisticalSignificance01.htm
How Accountics Scientists Should Change:
"Frankly, Scarlett, after I get a hit for my resume in The Accounting Review
I just don't give a damn"
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
One more mission in what's left
of my life will be to try to change this
http://www.cs.trinity.edu/~rjensen/temp/AccounticsDamn.htm
What went wrong in accounting/accountics research? ---
http://faculty.trinity.edu/rjensen/theory01.htm#WhatWentWrong
The Sad State of Accountancy Doctoral
Programs That Do Not Appeal to Most Accountants ---
http://faculty.trinity.edu/rjensen/theory01.htm#DoctoralPrograms